この記事は ユニークビジョン株式会社 Advent Calendar 2020 の7日目の記事です。
1. はじめに
この記事ではAWS re:Invent 2020で発表された AWS Lambda の新機能 – コンテナイメージのサポート についてまとめます。
従来、AWS Lambdaの関数を作成するためには関数の実行に必要なものをZIP形式でパッケージ化する必要がありました。
個人的にはローカルで動作確認をする構成とZIP形式のパッケージを作る手順が存在しているのは好みではありませんでしたが、この新機能によって開発時・本番運用時の両方とも同じコンテナイメージを使用することが出来るようになりました。
また、従来のZIP形式ではデプロイパッケージのサイズが250MBに制限されており、例えばTensorFlowなどを使用した推論処理のためにAWS Lambdaを使用するのは困難でした。それがこの新機能では最大10GBのコンテナイメージに対応するということでAWS Lambdaの用途が広がったと感じています。
そこで、本記事では
- 最小限のコンテナイメージを使用した関数
- TensorFlowを使用して画像分類を行う関数
を作成しながら利用方法を確認します。
2. Hello, AWS Lambda with Conrtainer
まずは最小限の構成で動くLambda関数を作成します。
この章では
- 作成する関数を構成する要素の紹介
- ローカルでの動作確認
- デプロイ
について取り扱います。
2.1. 構成
ディレクトリ構成は以下の通りです。
(プロジェクトルートディレクトリ)/
├── Dockerfile
└── app.py
この章で作成する関数はDockerfileが肝になります。
「Create an image from an AWS base image for Lambda」の手順に従って、Lambda用のベースイメージに app.py をコピーするだけの簡単な内容になっています。
FROM public.ecr.aws/lambda/python:3.8
COPY app.py ${LAMBDA_TASK_ROOT}
CMD [ "app.handler" ]
app.py が実際に実行される関数になります。
今回は冒頭のAWS Lambda の新機能 – コンテナイメージのサポートに登場する、Pythonのバージョンを返すだけの処理としています。
import sys
def handler(event, context):
return 'Hello from AWS Lambda using Python' + sys.version + '!'
2.2. ローカルでの動作確認
ローカルでの動作確認は上で作成したDockerfileをビルドして実行するだけで良いです。
プロジェクトのルートディレクトリにて
$ docker build -t {イメージ名} .
を実行してイメージを作成し、
$ docker run --rm -p 9000:8080 {イメージ名}
で実行します。ポート番号は任意のもので良いです。
この時点で、/2015-03-31/functions/function/invocationsというパスで関数を実行することが出来るようになっているので
$ curl -d '{}' http://localhost:9000/2015-03-31/functions/function/invocations
"Hello from AWS Lambda using Python3.8.6 (default, Nov 26 2020, 14:33:53) \n[GCC 7.3.1 20180712 (Red Hat 7.3.1-9)]!"
のようにすることで動作確認を行うことが出来ます。
意図した通り、Pythonのバージョンが返っていることが分かります。
また、コンテナのログには以下の通り、本当にLambdaを実行した際のログに近い内容が出力されています。
START RequestId: 81e030ca-0657-40e5-a80f-c8eb23f522cd Version: $LATEST
END RequestId: 81e030ca-0657-40e5-a80f-c8eb23f522cd
REPORT RequestId: 81e030ca-0657-40e5-a80f-c8eb23f522cd Duration: 1.20 ms Billed Duration: 100 ms Memory Size: 3008 MB Max Memory Used: 3008 MB
2.3. デプロイ
デプロイの大まかな流れは以下の通りです。
- ECRに先ほど作成したイメージをプッシュ
- 関数を作成
2.3.1 イメージのプッシュ
本記事ではECRへのプッシュは主題ではないので手順を割愛します。以下のリンクの通りに進めれば困ることはないかと思います。
https://docs.aws.amazon.com/ja_jp/AmazonECR/latest/userguide/docker-push-ecr-image.html
2.3.2. 関数を作成
AWSマネジメントコンソールにて関数を作成すると以下の画面が表示されます。
関数の作成オプションで「コンテナイメージ」を選択し、関数名とコンテナイメージURIを入力すると関数が出来ます。
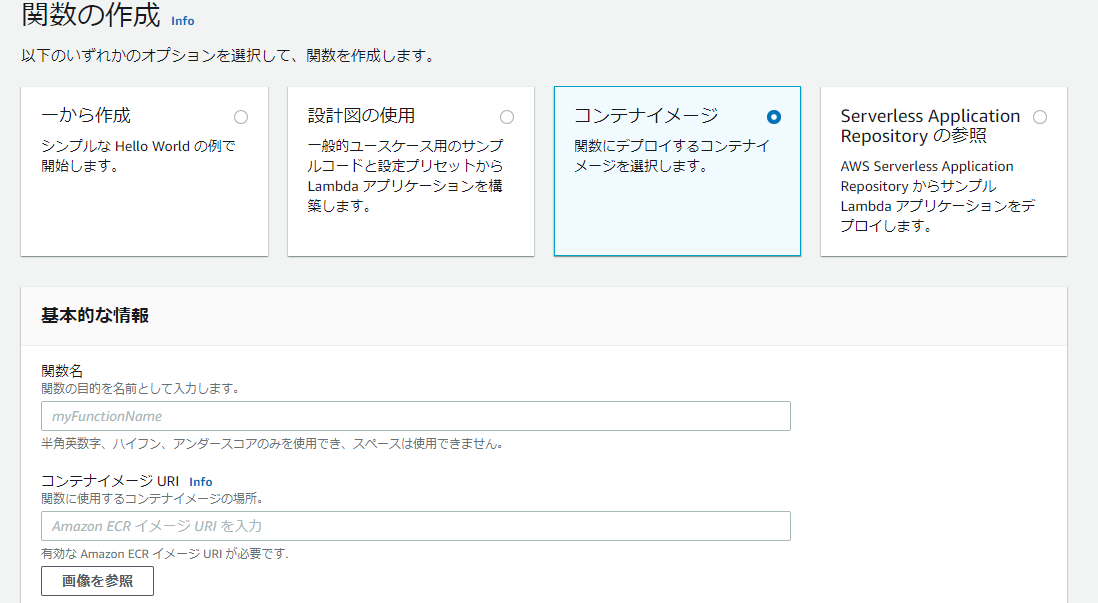
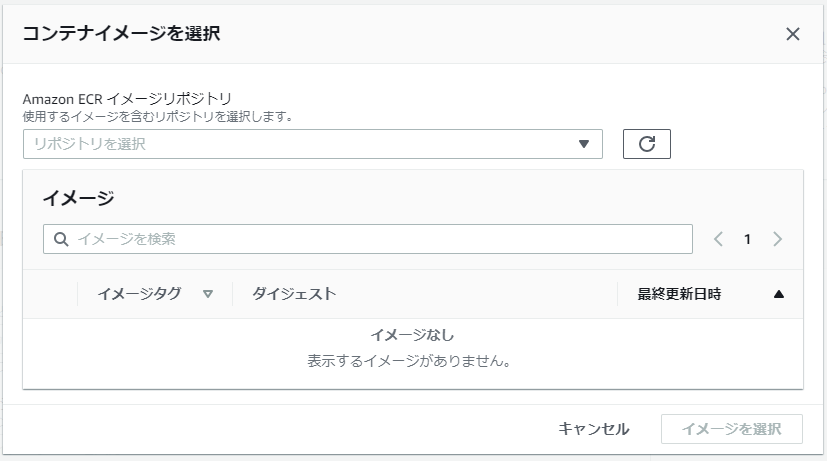
コンテナイメージURIの入力は「画像を参照」ボタンを押下するとこでECRからイメージを選択することが出来ます。
「Browse images」の日本語訳がバグっていますがこれはご愛敬ですね。
この手順で作成した関数は無事、動作することが確認できました。

3. TensorFlowを使用して画像分類をする関数を作成する
この章では、実用的な関数の例としてS3に画像をアップロードしたことをトリガーに画像分類する関数を作成します。
従来のZIP形式でのデプロイでは「AWS LambdaでTensorFlow 2.0を使った画像分類」という記事で扱われているように多くのことを考慮して作成する必要がありますが、コンテナイメージを使用すると前章とほぼ同じ手順で関数を作成することが出来ます。
3.1. 構成
本章の関数のディレクトリ構成は以下の通りです。
├── Dockerfile
└── app
├── app.py
├── model.h5
└── requirements.txt
まず、画像分類を行うため、TensorFlowの学習済みモデルが追加されています。
今回は以下のプログラムで、学習済みモデルをダウンロードしています。
from tensorflow.keras.applications.mobilenet_v2 import MobileNetV2
model = MobileNetV2(weights='imagenet')
model.save('model.h5', include_optimizer=False)
もう一点、TensorFlowなどのパッケージをインストールする必要があるため、 requirements.txtを追加しています。
今回はTensorFlowでの推論とS3へのアクセスを行うため、それに必要なものを記述しています。
boto3
tensorflow
pillow
Dockerfileには pip installを追加しています。
一応、ビルド時にキャッシュが利用できるように requirements.txtだけを先にコピーしています。
FROM public.ecr.aws/lambda/python:3.8
COPY app/requirements.txt ${LAMBDA_TASK_ROOT}
RUN pip install -r requirements.txt
COPY app ${LAMBDA_TASK_ROOT}
CMD [ "app.handler" ]
app.pyは当然大きく内容が変わっています。処理内容は簡単に、
- handlerの引数、
eventからアップロードされたファイルの情報を取得 - S3から上記ファイルをダウンロード
- 画像を読み込んで推論の前処理を実施
- 推論
という感じです。
本体は4. の後に結果を保存したりすると思いますが、今回は標準出力に出すだけとしています。
import boto3
import tensorflow as tf
from tensorflow.keras.applications.mobilenet_v2 import (decode_predictions,
preprocess_input)
from tensorflow.keras.preprocessing.image import img_to_array, load_img
s3_client = boto3.client('s3')
model = tf.keras.models.load_model('./model.h5', compile=False)
def handler(event, context):
try:
for record in event['Records']:
# アップロードされた画像をダウンロード
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
download_path = '/tmp/target_image'
s3_client.download_file(bucket, key, download_path)
# 画像を読み込んで前処理
img = load_img(download_path, target_size=(224, 224))
img = img_to_array(img)
img = img[tf.newaxis, ...]
img = preprocess_input(img)
# 推論
predict = model.predict(img)
result = decode_predictions(predict, top=5)
print(result)
return 'Success'
except Exception as e:
print(e)
return 'Failure'
3.2. ローカルでの動作確認
この関数はS3へのアクセスが必要となるため、以下の通り環境変数を渡してDockerを起動します。
docker run --rm \
-p 9000:8080 \
-e AWS_ACCESS_KEY_ID={アクセスキー} \
-e AWS_SECRET_ACCESS_KEY={シークレットキー} \
-e AWS_DEFAULT_REGION={リージョン} \
{イメージ名}
関数の実行ではS3へのPUTを模したデータを送信します。
curl -d '{"Records": [{"s3": {"bucket": {"name": "バケット名"}, "object": {"key": "ファイル名"}}}]}' \
http://localhost:9000/2015-03-31/functions/function/invocations
3.3. デプロイ
この関数のデプロイ方法は本記事の主題からは離れるため割愛しますが、
- 前章の通りイメージをプッシュ
- 関数を作成
- S3の当該バケットへのアクセス権限を設定
- 関数のトリガーを設定
のようにすることでS3に画像をアップロードすると推論を実施する関数が作成できます。
4. まとめ
本記事では2つの関数を作成しながらAWS Lambdaの新機能を確認しました。
個人的には従来通りの使用感で用途が広がっており、ローカルでの動作確認もしやすいので良い機能だと感じています。
今回は手動でデプロイを行いましたが、SAMやCDKなどを使用してデプロイが行えればすぐにでも実用可能な機能かなと思います。
次はデプロイ用のツールも含めて技術検証が行えたらと考えています。