はじめに
「せっかくMLのモデル作ったし、なんかwebサービスとかにしたいな・・・」
「やるとしたらクラウドだけどやり方よくわからないな・・・」
と思ってAzureで作ったモデルをデプロイまでしたときのメモです。
Azureについては日本語の記事もAWSに比べると全然見当たりませんし、苦労しました。
同じようなことをしたい方はぜひ参考にしてみてください。
前提
今回デプロイするのは「cGAN(conditional GAN)でくずし字MNIST(KMNIST)の生成」の記事で作ったcGANです。
環境
どうやらAzure側でpython3.7には対応してないみたいなので、python3.6で作り直しました
- python 3.6.9
- PyTorch 1.4.0
- cloudpickle 1.3.0
cloudpickleはPyTorchで作ったモデルをpickle化するためのモジュールです。使い方は普通のpickleとほぼ同じです。
上記事の最後の方に載っているコードで作った.pklファイルをそのまま使います。
必要なもの
- Azureサブスクリプション(無料試用版でOK)
- 適当なソースコードエディタ
実際に使って試したいので、ここではjupyter notebook上でpythonのrequestsモジュールを使っていきます。
手順
①Azureホームからリソースを作成
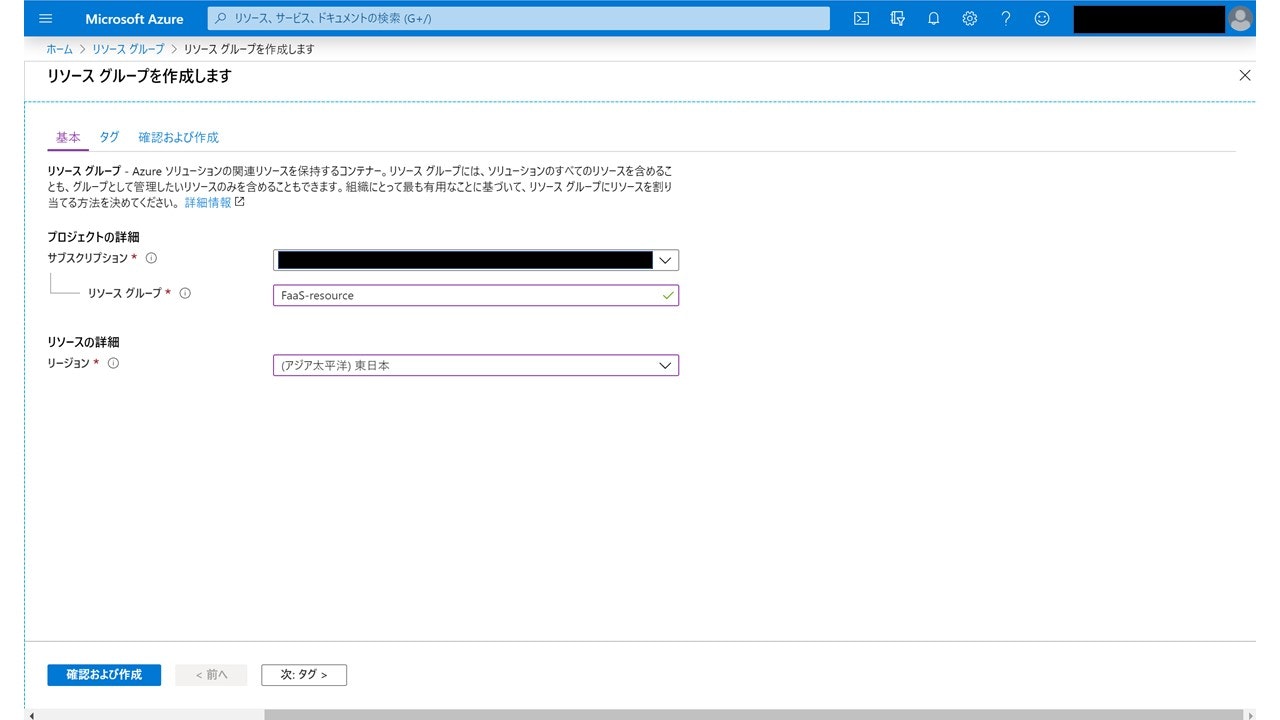
Azure portalのホーム画面から『リソースグループ』→『追加』でリソースグループを作成します。
もともとあるリソースグループを使っても以降の手順はできるので、既存のグループがあれば作らなくても構いません。
ここではリソースグループ名として「FaaS-resource」として作ります。リージョンもなんでもいいですが、「東日本」にしておきます。
②Azure Machine Learningのworkspaceを作成

Azure Machine Learning(AzureML)の機能を使うので、AzureMLのリソースを作成します。
Azure portalホームから、『リソースの作成』で「Machine Learning」と打てば出てくるはずです。『作成』で作成します。
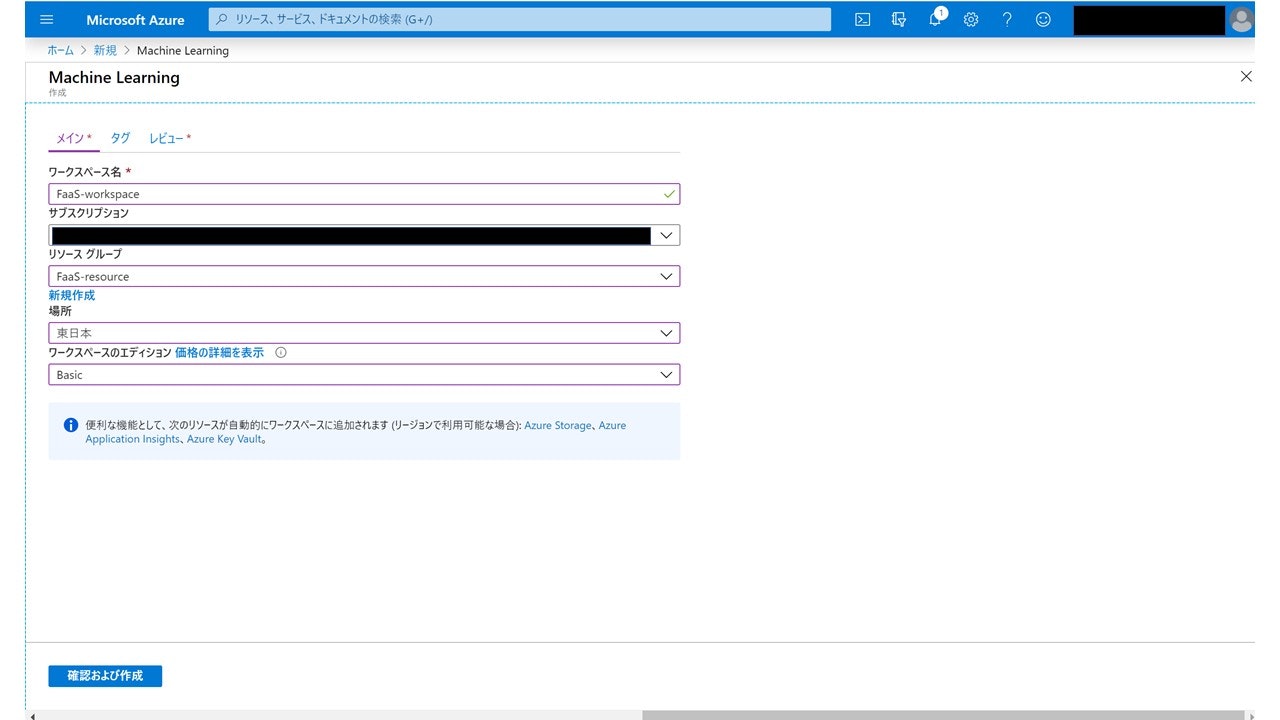
するとこんな画面が出てくるので、ワークスペース名を入力(名前はなんでもいいです)、サブスクリプションを選択し、リソースグループとしてさっき作ったものを選択します。
ワークスペースのエディションは「Basic」でOKです。
③モデルを登録
AzureMLを作成すると、ワークスペースの画面で『Azure Machine Learning Studioを試す』からAzure Machine Learning Studioに移動します。
こんな画面になるはずです。
左側の『アセット』の『モデル』をクリックしてローカルで作ったMLモデルを登録します。
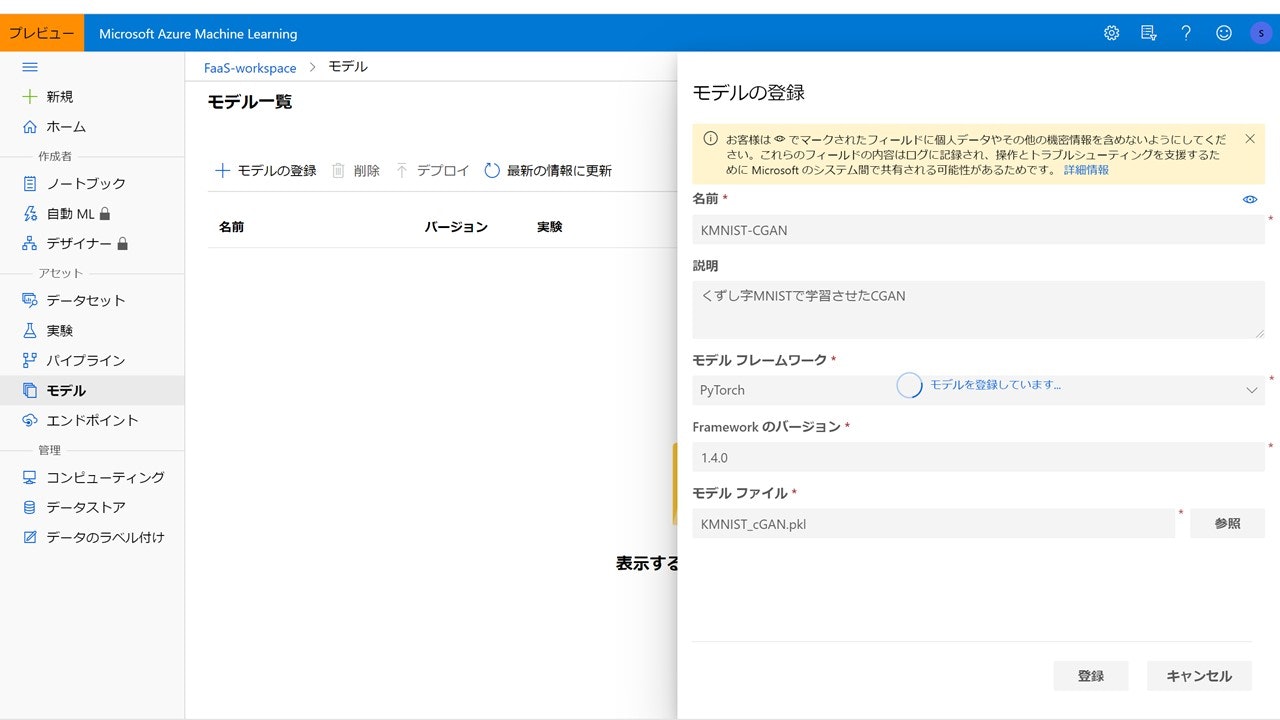
『モデルの登録』をクリックすると、モデルの概要を入力する画面が出てくるので、名前・説明(なくてもいい)を入力。
今回はPyTorchで作ったモデルを使うので、「PyTorch」を選んで、フレームワークバージョンを「1.4.0」と入力、モデルの.pklファイルを選びます。
モデルを登録すると、『モデル一覧』のページに今登録したモデルが表示されます。
ちなみに
Azure Machine Learning Studioの画面で、『ノートブック』からjupyter notebookを操作することができます。
モデルの訓練からデプロイまではこのjupyter notebook上での操作で行うこともでき、Azureの公式ドキュメントのチュートリアルには、その手順例が載っています。
④モデルをデプロイ
『モデル一覧』に登録したモデルを選んで『デプロイ』からデプロイできます。
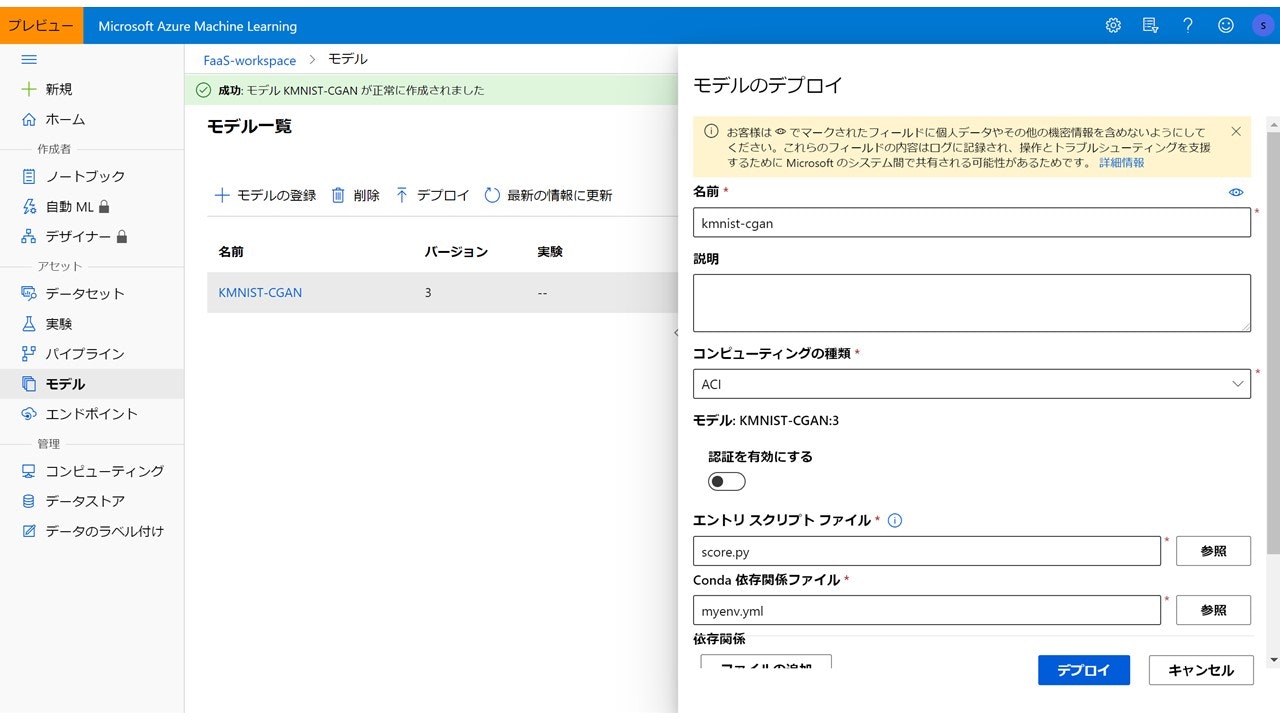
こんな画面が出てきます。名前・説明(なくてもいい)を入力、コンピューティングの種類は「ACI」(=Azure Container Instance)を選択、エントリスクリプトファイルとConda依存関係ファイルをそれぞれ選択します。これについては後述します。
これで『デプロイ』を選択すれば、デプロイが開始されます。
このとき、下の『詳細条件』からアップロードする仮想マシンのCPUコア数やメモリサイズを変えられますが、デフォルトでも構いません。
エントリ スクリプト ファイル
Azureの公式ドキュメントにも説明がありますが、ACIでデプロイしたwebサービスでは、クライアントから送られてきたデータを受け取り、モデルに渡し、出てきた結果をクライアントに返します。この流れを定義しているのがこのファイルです。
適当なソースコードエディタで作っていきます。
# coding: utf-8
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.3.2
# kernelspec:
# display_name: Python 3.6 - AzureML
# language: python
# name: python3-azureml
# ---
import torch
import torchvision
import torchvision.transforms as transforms
import numpy as np
import os
import torch.nn as nn
import torch.nn.functional as F
import cloudpickle
from azureml.core.model import Model
import json
def init():
global model
path = os.path.join(os.getenv('AZUREML_MODEL_DIR'), 'KMNIST_cGAN.pkl')
with open(path, 'rb')as f:
model = cloudpickle.load(f)
def run(raw_data):
indexs = json.loads(raw_data)["indexs"]
index_list = indexs.split(',')
num_class = 49
z_dim = 100
for i, num in enumerate(index_list):
#ノイズ生成
noise = torch.normal(mean = 0.5, std = 1, size = (1, z_dim))
#Generatorに入れるラベルを生成
tmp = np.identity(num_class)[int(num)]
tmp = np.array(tmp, dtype = np.float32)
label = [tmp]
#Generatorでサンプル生成
sample = model(noise, torch.Tensor(label)).detach()
#整形してリストにする
sample = sample.reshape((28,28))
img = sample.detach().numpy().tolist()
if i == 0:
comp_img = img
else:
comp_img.extend(img)
return comp_img
2つの関数が定義されています。
-
init()関数はサービス起動時に1回だけ呼ばれ、モデルを読み込む -
run(raw_data)関数は、受け取ったデータをどのようにモデルに渡して、結果をクライアントに返すかを定義する
モデルを登録すると、AZUREML_MODEL_DIRというディレクトリにモデルが保存されるので、それを呼び出します。
また、クライアントから送られてくるのはjson形式のデータなので、それを取り出してラベルをモデル(cGANのGenerator)に入れ、出てきた結果をreturnします。このとき、上のコードで最後にreturnしているのはpythonのlist型のデータですが、どうやらAzure側でクライアントに送る前にjson形式に変換されているっぽいため、クライアント側でjson.loads()とやる必要があります。
Conda依存関係ファイル
名前そのままですが、必要なCondaパッケージとかを定義するファイルです。
これもソースコードエディタなどで.yml形式で作っていきます。
# Conda environment specification. The dependencies defined in this file will
# be automatically provisioned for runs with userManagedDependencies=False.
# Details about the Conda environment file format:
# https://conda.io/docs/user-guide/tasks/manage-environments.html#create-env-file-manually
name: project_environment
dependencies:
# The python interpreter version.
# Currently Azure ML only supports 3.5.2 and later.
- python=3.6.2
- pip:
- azureml-defaults
- azureml-sdk
- azureml-contrib-services
- numpy
- pytorch
- torchvision
- cloudpickle
channels:
- conda-forge
- pytorch
公式ドキュメントに載っていた.ymlを少し変えただけです。この中だと、azureml-defaultsはwebサービスをホストするために必要なパッケージらしいので必須です。モデルに使ったパッケージなどに応じて少し変える必要があります。
⑤デプロイの確認
デプロイには結構時間がかかります。環境にもよるとは思いますが、自分は大体10分~15分程度はかかりました。
デプロイがうまくいっているかどうかを確認します。
Azure portalのホームから『リソースグループ』で、使っているリソースグループを覗くと、デプロイ開始からしばらく経った時点で、作成したコンテナインスタンスが表示されます。
そのコンテナインスタンスのページに移動します。
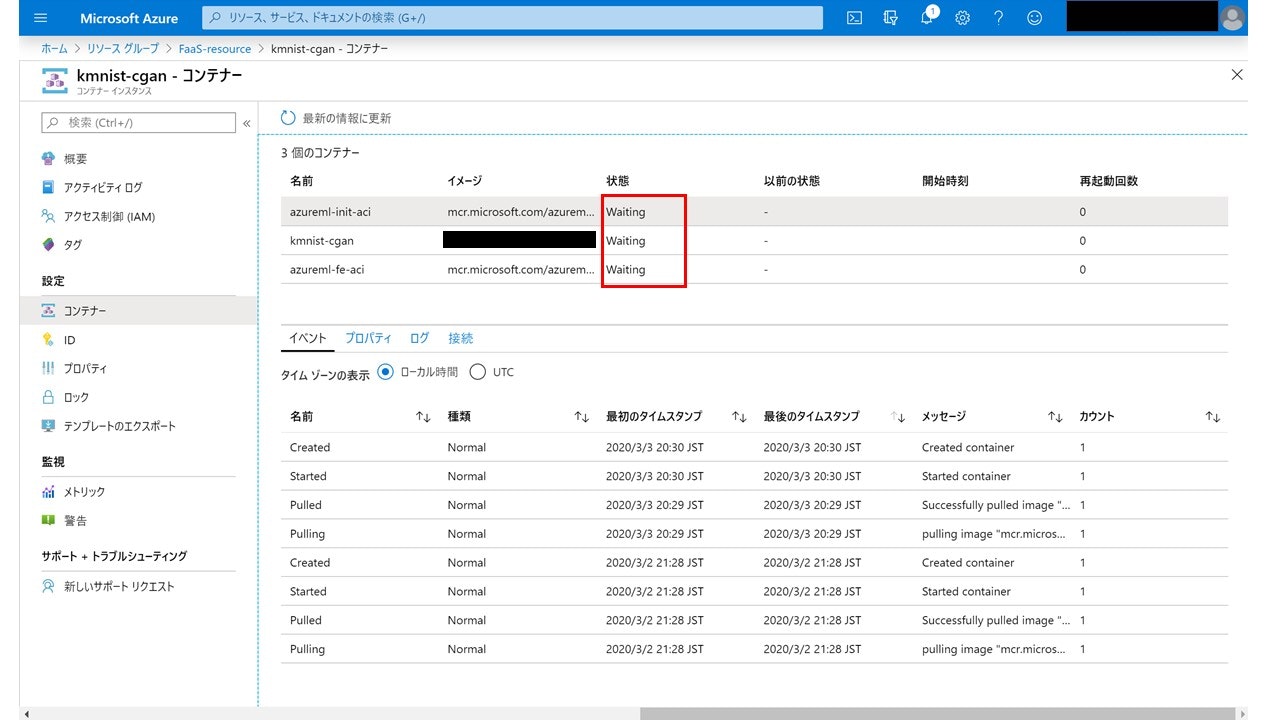
今回は先ほど「kmnist-cgan」という名前でデプロイしたので、コンテナインスタンスの名前がそうなっています。『設定』の『コンテナー』を開くと上記の画面になり、3個のコンテナの『状態』(赤枠の部分)が"Waiting"から"Running"になればデプロイ成功です。
ちなみにデプロイ過程でエラーが出ると、下の『ログ』の部分でエラー内容が表示されます。
特にscore.py内部のバグやリクエスト処理時のエラーは、今回でいう『kmnist-cgan』コンテナのログに表示されるので、ここを見るとトラブルシューティングに役立つかもしれません。
⑥デプロイしたサービスを使ってみる
ここでデプロイしたのは、"文字を入力すると、その文字のくずし字風文字を返してくれるcGAN"です。これをローカルから試してみます。
デプロイが完了してwebサービスが使える状態になっていると、AzureのコンテナインスタンスのページにIPアドレスやFQDNが表示されるのでそれを使います。
import requests
import json
import matplotlib.pyplot as plt
%matplotlib inline
url = "http://【作成したコンテナインスタンスのFQDN】/score"
strings = input()
# 取り出したモデルを使って狙った数字を生成
def FaaS_KMNIST(url, strings):
letter = 'あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらりるれろわゐゑをんゝ'
indexs = ""
input_data = {}
for i in range(len(strings)):
str_index = letter.index(strings[i])
indexs += str(str_index)
if i != len(strings)-1:
indexs += ','
print(indexs)
input_data["indexs"] = str(indexs)
input_data = json.dumps(input_data)
headers = {"Content-Type":"application/json"}
resp = requests.post(url, input_data, headers=headers)
result = json.loads(resp.text)
return result
response = FaaS_KMNIST(url, strings)
plt.imshow(response,cmap ="gray")
こんな感じのコードを書いて試してみます。
input()で入力を受け付けているので、適当に文字を打つと最後にこんな画像が表示されます。
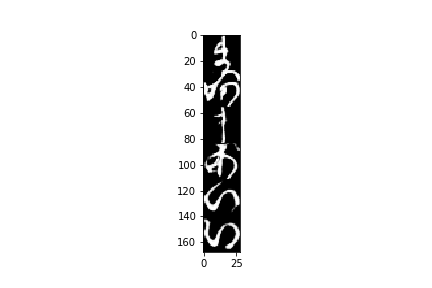
"まあまあいい"んじゃないでしょうか?
最後に
作ったMLモデルをAzureでデプロイしてみました。やり方自体はそんなに難しくないと思います。
少なくともAzure Machine Learning Studioのjupyter notebook内でデプロイするよりは簡単なやり方かと思うので、ぜひ試してみてください。