紹介する論文
タイトル:MobileNetV4 -- Universal Models for the Mobile Ecosystem
学会:ECCV2024
研究機関:Google
MobileNetV4は軽量DNNアーキテクチャです。Universal Inverted BottlenecksとMobile MQAを基本構造として持ち、NASで探索して得られたモデルです。
最近公開された生成AIモデルのGemma 3nでは、画像エンコーダとしてMobileNetV5が使われています。MobileNetV5はMobileNetV4と似た構造らしく1、MobileNetV4はMoblieNetV5につながる技術のようです。
画像・数式は論文から引用しています。
MobileNetV1~V3の復習

MobileNetV1~V3を簡単に振り返ります。
MobileNetV12はDepthwise Separable Convolutionの基本構造が特徴的です。従来のVGG163などで使われているConvolutionをDepthwise ConvolutionとPointwise Convolutionに分解することで計算量を削減しています。
MobileNetV24はInverted Residual Blockの基本構造が特徴的です。1つ目のPointwise Convolutionでは特徴量を増やし、Depthwise Convolution適用後に2つ目のPointwise Convolutionで元の特徴量に戻しています。また、活性化関数はReLU6を使っています。
MobileNetV35はSqueeze-and-Excitationブロックを導入し、特徴量に重みづけを行っています。活性化関数はh-swishを使っています。
MobileNetV4の基本構造
Universal Inverted Bottlenecks (UIB)

MobileNetV3の基本構造は図のUniversal Inverted Bottlenecks (UIB) です。UIBの灰色部分にはDepthwise Convを入れるか入れないかを選択することができます。これによってUIBで複数種類のブロックを表現することができます。
Extra DWは両方にDepthwise Convを入れたもので、本論文で登場したブロックです。MoblieNet Inverted BottleneckはMobileNetV2で登場したブロックです。ConvNext-LikeはConvNeXt6で登場したブロックです。FFNはTransformerでもよく用いられているブロックです。
またFused IBはStemでのみ採用されるブロックです。Conv2Dを使うため計算コストは高いですが、高い表現力を得るために使われています。
UIBで4種類のうちどれを選ぶかはNAS (Neural Architecture Search) で探索します。パラメータは探索中に共有されます。
Mobile MQA
Mobile MQAの構造
最近のモデルは、Convolution系だけでなくTransformerの要素が取り入れられています。MobileNetV4では、UIBだけでなく、Transformerの要素を含むMobile MQAブロックを探索対象に入れることもできます。
Mobile MQAブロックは論文では詳細な構造が解説されていません。timmのMobileNetV5のコード78を見ると、画像の空間方向(高さ・幅)を時間方向と思ってAttentionを適用しているようです。
Spatial Reduction (SR)

Mobile MQAのKey, Valueでは、画像サイズを小さくしてからAttentionに入れるSpatial Reduction (SR) 9 の考え方が採用されています。MobileNetV4では、stride-2, Depthwise 3x3で画像サイズを小さくしています。
式で書くと以下のようになります。

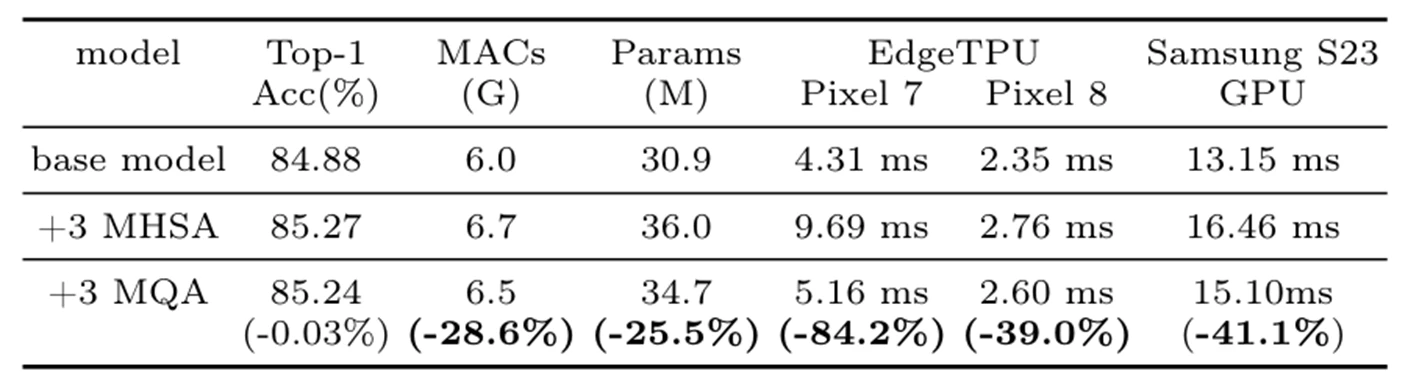
表からわかるように、精度を大きく変えずに、推論時間が大きく減少していることがわかります。

Multi Query Attention (MQA)
Attentionでは、Multi Query Attention (MQA) を採用しています。つまり、Key, Valueを全Headで共通化しています。MQAによってメモリ負荷削減・高速化を図っています。画像認識タスクに初めて導入されたそうです。
表からわかるように、精度を大きく変えずに、推論時間が大きく減少していることがわかります。
MobileNetV4の設計
設計方針
MobileNetV4では"Simplicity Meets Efficiency"が設計原則です。具体的には下記が挙げられています。
- Squeeze-and-Excitation, GELU, LayerNormはハードウェアサポートが悪い(遅い)ので使わない
- ハードウェアによらず使える標準的な演算を使う
- DepthwiseConv, PointwiseConv, ReLU, BatchNorm, Multi-Head Attentionなど
アーキテクチャの探索
アーキテクチャの探索にはTuNAS10が使われています。TuNASは強化学習ベースのシンプルなNASです。重みは共有重みとし、報酬関数として精度と推論時間を使っています。
MobileNetV4では2段階でアーキテクチャを探索しています。
- Cource-Grained Search: 最適なフィルタサイズを決める。
- Fine-Grained Search. UIBのDepthwiseConvの有無及びカーネルサイズを探索する。

1段階で探索するよりも、2段階で探索する方が、精度・速度とも良いアーキテクチャが得られたようです。
実験
Pixel 6 EdgeTPUやPixel 7 EdgeTPUをターゲットに、いくつかのサイズでアーキテクチャ探索しています。

どのエッジ端末においても、従来の軽量ネットワークよりも良い精度-速度トレードオフ傾向が見られます。