Panasonic×AI Advent Calendar 2021 24日目の記事です.
最近調査している、データ拡張の自動最適化AutoAugmentの進化についてまとめたいと思います
記事で言及しているFaster AAやMADAOの著者グループ(東大中山先生と幡谷さん)のSSII 2021のチュートリアルももう少し広い範囲でデータ拡張について解説されており参考になるかと思います
手法一覧
ECCV2020でFaster AAやDADAなどが登場して、計算コストが実用的なレベルになってきた印象です
AAやRAで見つかった拡張パターンを使ってる人の方が多いですが、自分で探索するのが当たり前という時代が来るやもと感じます
| AA(CVPR2019) | RA(NeurIPS2020) | FastAA(NeurIPS2019) | FasterAA(ECCV2020) | DADA(ECCV2020) | DDAS(ICCV2021) | UA(2020) | TA(ICCV2021) | MADAO(WACV2022) | DABO(WACV2021) | |
|---|---|---|---|---|---|---|---|---|---|---|
| ImageNetエラー率(ResNet50) | 22.4 | 22.2 | 22.4 | 23.5(200epoch) | 22.5 | 22.3 | 22.3 | 22.0 | 23.0 | 23.8 |
| 計算コスト(GPU hour@ImageNet) | 15000(P100) | 4750(2080Ti) | 450(V100) | 2.3(V100) | 1.3(Titan XP) | 1.2(2080Ti) | 0 | 0 | 通常学習x2程度 | 通常学習x5程度 |
| 公式実装 | なし | あり? | あり | あり | あり | あり | なし | あり | なし | あり |
| ざっくり | 強化学習で探索.一般人には無理 | 探索空間を簡略化して高速化 | (拡張なしで学習したモデルの)評価性能を最大化するデータ拡張をベイズ最適化で探索(モデルは固定されるので高速) | 微分可能なので超高速.拡張したデータとしてないデータの分布間距離を最小化 | 微分可能なので超高速.ほぼほぼNASのDARTSっぽい感じ. | 微分可能なので超高速.複数の拡張パターンを同時に評価したり探索空間の表現を変えることで近似を回避 | ランダムに拡張操作を選択して探索を不要に | ランダムに拡張操作を選択して探索を不要に | E2E学習.陰関数微分でValidationエラーの最小化を解けるようにし、ノイマン級数を利用して計算コストを抑制 | E2E学習.拡張方法の探索をSpatial Transformer Network(性能を最大化するアフィン変換パラメタをNWパラメタに組み込む)の学習に置換 |
各手法のざっくりとした紹介
まずはここから
AutoAugment: Learning Augmentation Policies from Data (略称AA)
↓の論文のFig.1にまとまっていて、
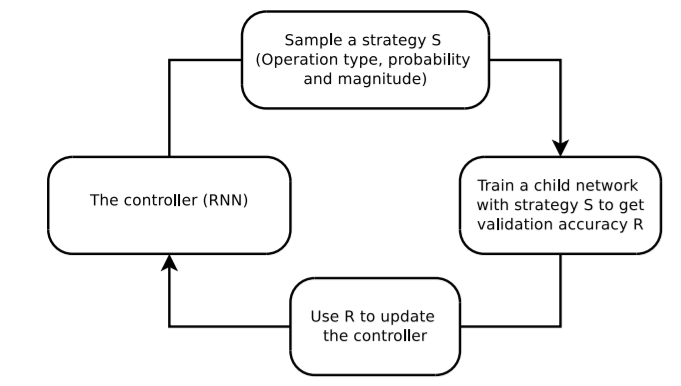
- Controllerを使ってデータ拡張のstrategy S=パラメタ(操作・その確率・その強度)群をサンプリングする
- Child Networkを1でサンプリングしたデータ拡張パラメタで学習し、バリデーション性能Rを得る
- 2で得られたRを使ってControllerをアップデートする
という流れです
"1のstrategy S=パラメタ(操作・その確率・その強度)群"は、
↓の論文のFig.2のような形で、

5つのSub-policyで構成されます
Sub-policyは2つの拡張操作とそれぞれの確率と強度で表現されています
Sub-policy 3を見てみると、
- 操作1: Shear X(せん断), 確率0.9, 強度4
- 操作2: Auto Contrast(コントラスト調整), 確率0.8, 強度3
となっており、Batch 1~3の実際にSub-policyが適用された結果画像をみると、
操作1,2がかかった画像が生成されています
操作2のAuto Contrastの方は確率が0.8でShear Xより少し低いので、
Batch 2の時は適用されなかったようですね
(ちなみに、この5つのSub-policyのどれが選ばれるかは等確率となっています)
拡張操作は16種類、確率と強度はそれぞれ11段階と10段階で離散的に表現しており、
Sub-policyごとに161011通りの候補の操作から2つ選び、
Sub-Policyを5つ選ぶため、全体で$(161011)^{10}≒2.9*10^{32}$の探索空間となります
この探索空間から良さそうなものを選ぶのがControllerの役割です
ContorollerはRecurrent Neural Network(RNN)で構成され、
強化学習手法のProximal Policy Optimization(PPO)で学習します
RNNのイメージは↓の図のような形で、
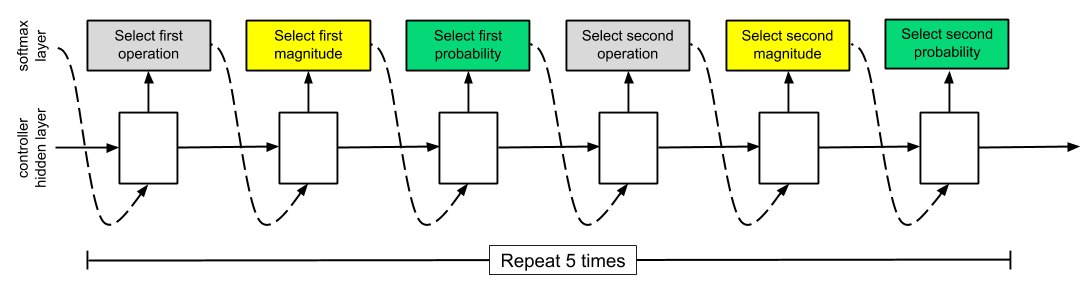
Softmaxを使って3つの要素(=操作・強度・確率)を予測します
操作1つあたりに3要素あり、2つの操作で構成されるSub-policyを5つ予測するので、
$325=30$個のSoftmax予測器を持っています
また、Child NetworkとそのNetworkを選ぶ確率を予測するSoftmaxを持っています
Child Networkは30個Softmax基づいて予測された5つのSub-policyで学習され、
それぞれにValidation性能を評価しています
このValidation性能の値を使って、性能高いChild Networkを選択する確率が高くなるように、
RNN学習するという処理をしていると思われます
15,000のPolicyについて学習していき、その過程でValidation性能が高かった5つのPolicyを、
最終出力として返します
(Policyは5つのSub-policyからなるので、最後は25個のSub-Policyが返ってきます)
Child Networkの学習はフルデータで15,000回学習するのは辛すぎるので、
間引いたデータで学習することで計算コスト削減をしています
15,000回も学習したら探索方法がどうであれそれなりに良さげなものが見つかるのでは?と著者たちも考えたのか、探索方法は沢山あるなかからやってみただけ(≒最適な方法とは言ってない)だよ、みたいなことも言っています
力技な感じがすごいので、後に続く論文はもう少し楽に探索したいよね、という問題設定が基本となります
Fast AutoAugment (略称FastAA)
ということで出てきたのがFast AAです。
(PBAが同時期に出てるけど割愛)
AAでは、あるPolicyを評価するために、毎度NWの学習を行う必要があり、このせいでとんでもない計算コストが必要となっていました
そこで、Fast AAでは、Policyの探索をNWの学習と切り離すことで計算コストを削減しています
AAでは、Policyに基づくデータ拡張を行いながらNWを学習し、NWの(Validation)性能を最大化する、という問題を解いていましたが、Fast AAでは、↓の図のように、元画像の分布の足りないところを、拡張した(変換)画像で埋める、
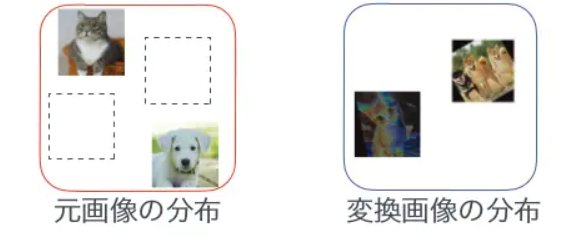
という問題を解いています
Fast AAではこの問題を、$D_{train}$とデータ拡張された$D_{Valid}$のdnesityをmatchさせる、データ拡張Policyの探索、と設定しています
(全データでこれを解くのはきついので、学習データ$D_{train}$を、NW学習用の$D_{M}$と疑似Validation用の$D_{A}$に分割しています)
この問題を式で表現すると↓となり、
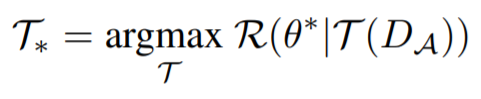
$D_{M}$を使って学習したNWのパラメタを使って、データ拡張Policy$Τ$で拡張された疑似Validationデータ$T(D_{A})$を評価した性能$R(θ^{*}|T(D_{A}))$を最大化する$Τ$を探す、という問題になります
$θ^{*}$は$D_{M}$を使って学習したNWのパラメタで、このNWの性能を最大化する拡張は、$D_{A}$を$D_{M}$に近づける変換となり、元の学習データにありそうでなかった画像を生成可能にする、というお気持ちかなと思っています
また、Policyの探索、すなわち$Τ$の最大化(式で言うargmax)においては固定されています
これで最初に述べた、Policyの探索をNWの学習と切り離す、ことが出来ました
Policyの探索はベイズ最適化で行いますが、HyperOpt(Optunaみたいなもの)というライブラリにお任せすればOKです
全体の流れとしては、↓のアルゴリズムに示す通り、データをK-fold分割して、それぞれのデータを$D_{M}$と$D_{A}$に分割し、K個のデータで個別にモデル学習とベイズ最適化によるPolicy最適化を行い、結果をマージする、という感じになります

こんな感じで、AAの15,000 GPU hourから450GPU hourまで、大幅に計算時間を削減しています(P100⇒V100にGPUが変わってることの効果も含まれます)
微分しようぜ!
Fast AAでだいぶ速くなった気がしましたが、V100のGPUを20日弱使わないと探索終わらないというのは普通の人には厳しい状況です
そこで微分使ってもっと速くしようぜ!というのがここから紹介する手法となります
Faster AutoAugment: Learning Augmentation Strategies using Backpropagation (略称FasterAA)
微分出来るようにするためにどうするの?ということで、
- 拡張のパラメタ(=操作の確率、強度)が微分出来ないのを近似を取り入れた
- Policyの探索を重みの最適化問題にした
- 問題を(Fast AAと似た)元画像と変換画像の分布間距離最小化にして微分可能にした
がやっていることです
1について、
- 操作の確率はベルヌーイ分布で微分出来ないので、Relaxed Bernoulli distributionを利用します
- 操作の強度は、連続値なrotateやtranslateは良いとして、PosterizeやSolarizeなど離散値だと逆伝搬ができません.そこでStraight-Through Estimatorを使って、逆伝搬が可能となるようにします
2について、
↓の図の$w_{1}$や$w_{2}$のように全操作の重み付和を考えます
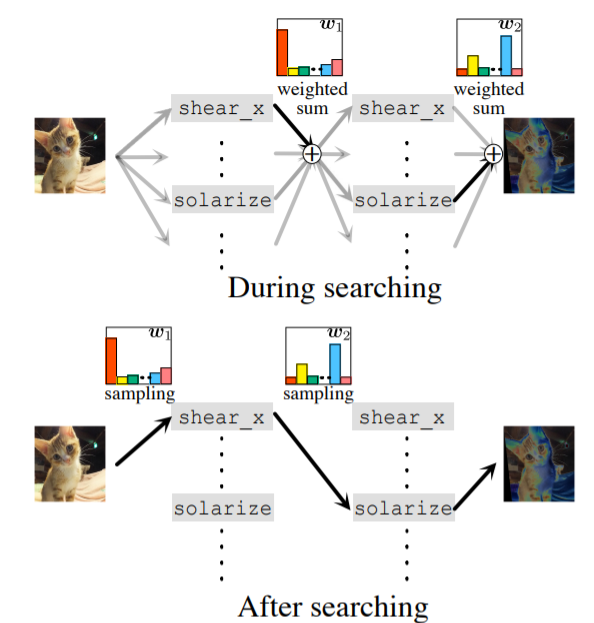
(適切な温度パラメタで)この重みのSoftmaxを算出することで、onehot-likeなベクトルが得られ操作が選択されるのと同じ効果が得られる、みたいなことをやっています
NASを微分可能にして高速化したDARTSでNWの要素を選択するのと同じような仕組みかなと思います
(DARTSって?という人は私の記事に解説記事へのリンクをいくつか挙げているので参考になるやもです)
3について、
Fast AAと似たような感じで、元画像と変換画像の分布間距離最小化、という問題を解いていきます
Faster AAでは、微分可能な問題にするために、GANでも利用されるWasserstein distanceの最小化を解きます
この最小化は変換画像と元画像の区別がつかないように学習するWGAN-GPによるGANの学習となっています
また、拡張によって別クラスの画像を生み出すような変なことがないように、通常の(=物体認識とかでいつも使う)クラス分類問題も解きます
こういった取組により探索を微分可能な問題にして、Fast AAの450 GPU hourを、2.3 GPU Hourまで大幅に短縮しました.
DADA: Differentiable Automatic Data Augmentation(略称DADA)
Faster AAと同じようにDARTSっぽい形でPolicy探索を行う手法としてDADAも提案されました
大きな違いは、
- 拡張操作選択の部分でGumbelSoftmaxを使った近似を取り入れている
- Faster AAが拡張画像と元画像の分布の一致という問題を解いていたのに対し、DADAはDARTS同様Validation性能誤差の最小化を解いている、
というところかと思います
拡張操作の強度や確率パラメタの近似の部分は、Faster AAと同じ方法を採用しています
(なのにFaster AAを引用していないのは??という感じがしました)
GumbelSoftmaxによる近似の部分では、RELAX estimatorというのを使って勾配のバイアスを抑制するという工夫も行っているようです
Validation性能誤差の最小化の解き方は、DARTSまんまという感じです
DARTSの論文の数式(3)~(8)におけるNWの構造を決めるパラメタ$α$の部分を、拡張Plicyを決めるパラメタ(をまとめたもの)$d$に置き換えたら、DADAの数式(16)~(19)はだいたい完成します
(なので、DARTSの解説のこちらの記事とかこちらの記事とかを読んで頂くと、腑に落ちるかなと思います)
ちなみに、Faster AAでは、計算コストとメモリコストが高いという理由でこの解き方を避けたと説明されています
However, this bi-level formulation takes a lot of time and costs a large memory footprint [7].
DARTSにGumbelSoftmaxを取り入れるアイディアは、DARTS以降のNASの論文でも提案されており(DADAの論文内でも言及されています)、NASの改良を拡張Policy探索に落とし込むという論文は今後も出てくるかもしれないなと思ったりします
GPUが違うのであれですが、Faster AAから速度・性能ともに改善しており、約1hでImageNetのPolicy探索が完了するという結果で、AAの15,000 GPU hourからするととんでもない高速化を実現しています
また、物体検出タスクへの適用も検討しており、そちらでも効果が確認されています
Direct Differentiable Augmentation Search (略称DDAS)
ここまで説明したとおり、Faster AAもDADAも近似が色々と入っています
近似をなくす(正確にする)と性能良くなるのでは?というのがDDASのポイントかなと思います
やってることは
- 操作と強度を合体して探索候補とする(回転15度、回転30度は別の操作として扱うみたいなイメージ)
- Policyの探索を、何かしら拡張を行う確率と各操作の確率を最適化する、という設計で表現
というかたちで、Faster AAやDADAのDARTSっぽい形から変わっています
後者については↓の図のようなかたちで、
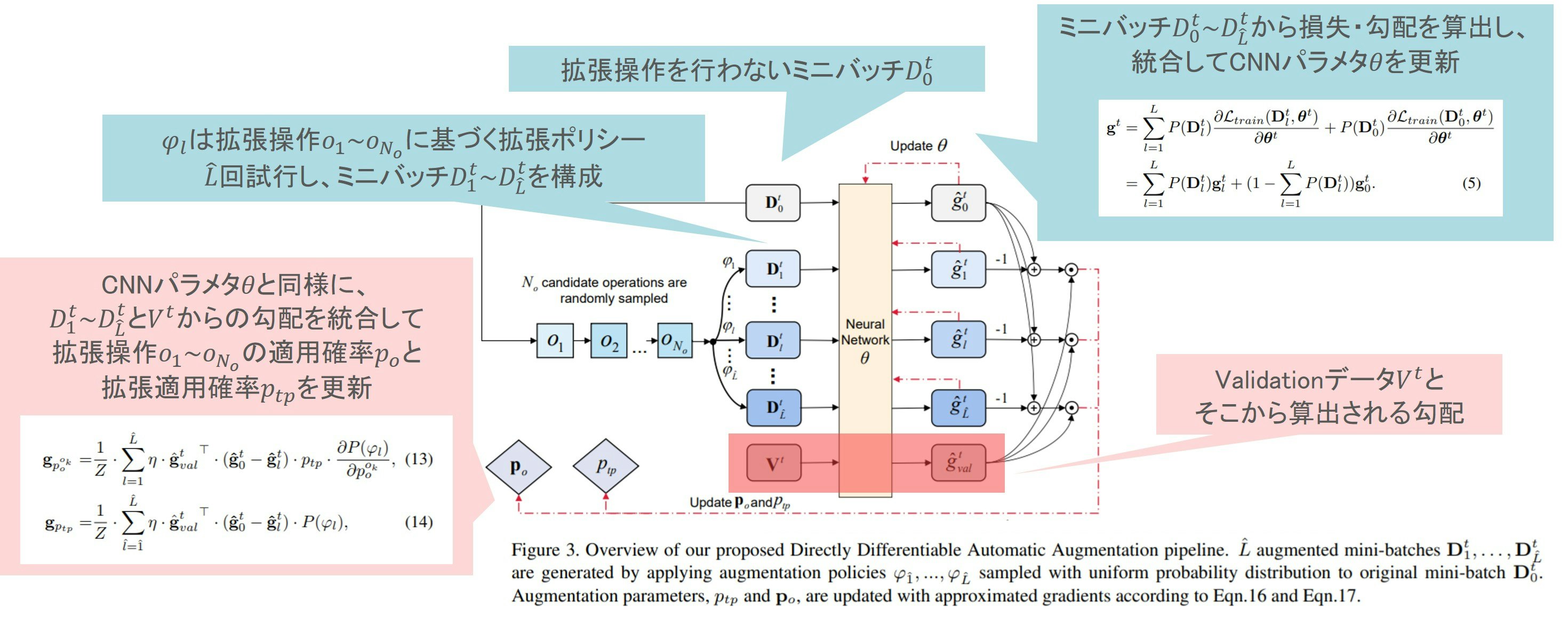
- 色々な拡張Policyでモデルを学習してみてその結果を組合せた勾配を得てNWパラメタを更新(図青枠部分)
- Validationで得た勾配と↑で得た勾配を組合せて拡張Policyパラメタを更新(図赤枠部分)
ということをやっています
DADAから若干性能改善するとともに、DADAでは発散してしまう深いNWでの物体検出タスク向けの探索が出来るようになっています
探索やめようぜ!
ここまで色々な手法が工夫を凝らして探索していましたが、そんなことせんでも性能出るよ、というどシンプルな手法たちです
RandAugment: Practical automated data augmentation with a reduced search space (略称RA)
こちらの解説を読んで頂くのが良いかなと思います
候補の操作(14個)の中からN個の操作を選択、候補の強度(10段階)の中から強度Mを選択、のN,Mをグリッドサーチで最適化するというシンプルな手法です
探索空間がAAでは$10^{32}$でしたが、$10^{2}$となるのでグリッドサーチでも探索出来ちゃいます
また、学習データをシュリンクしたりしないでフルデータでしっかり学習して性能確認するので、正しい最終性能がわかります
CVPR workshop版だと、探索コスト0とか書いてますが、流石にそれは無理がある…
実際にはフルデータの学習をNxM回行うので、それなりにコストがかかります
UniformAugment: A Search-free Probabilistic Data Augmentation Approach (略称UA)とTrivialAugment: Tuning-free Yet State-of-the-Art Data Augmentation (略称TA)
UAもTAもほぼほぼ同じで、探索しないで、探索空間からランダムにパラメタ選びながら学習しようぜ、という手法になります
UAのアルゴリズムは↓で

どの操作を行うかの$t$、確率を$p$、強度を$λ$として、一様分布から全部選んできて$NumOps$回これを繰り返します
TAのアルゴリズムは↓で

どの操作を行うかの$a$、強度を$m$として、ランダムに(こちらも一様確率で)選びます
UAもTAもわりと性能がよく、TAに至ってはこの分野でTop性能を叩き出しています
こういう結果をみると、探索とは…?という気持ちにもなってしまいますね
とはいえ、そもそもの探索空間の設計(候補の操作とか強度の最大・最小レンジとか)が物体認識系は出来上がっているから成立するだけであって、未知のタスクだと性能崩壊するのでは?という気もちょっとします.例えば、あんまり対象物が面内回転しないようなタスクで、回転の最大45度とかから一様サンプルしたらむしろ悪影響しそうだなと.なので、手法を組合せてPolicy探索でレンジを最適化する、みたいな研究が出てくるのかもな~と個人的には思ったりしています
その他
ここまで紹介した手法は、基本的に探索と学習を別々に行う必要がありましたが、MADAOやDABOは1度の学習で同時に拡張PolicyとNWパラメタを最適化するE2Eな手法となっており、こういった路線の研究も今後増えていくのかなと思います.また、これらの手法は、よくある物体認識系(CIFAR10/100, ImageNet)以外のデータセットを評価しており、応用しやすいのかもと感じます.加えて、DABOでは拡張をSTNで表現していましたが、同様にNWを利用して表現する方式がMIRU 2021で見られました(MADAOと同じ著者グループの"iMADAO: 画像事例に応じたデータ拡張戦略の設計手法"やデンソーアイティーラボラトリの"ニューラルネットワークによる画像認識のためのデータ拡張探索手法の検討").この辺りと従来の表現の優劣も気になるところです.
ちなみに弊社パナソニックでもこの分野の研究を行っており、AutoDOがCVPR 2021に採択されています.データインバランスやラベルノイズがあるような実応用の場面を想定した手法となっています.概要は弊社HPやcvpaper.challengeで紹介されています.解説ブログも弊社HPで公開されるかもなので、公開の際には是非ご覧ください
まとめ
AutoAugmentは探索時間が長すぎて使えないと思っていた方も、最近の手法を取り入れることで自身の解きたいタスクに最適な拡張Policyを現実的な時間で見つけられそうな時代がやってきそうです.実装も公開されているので是非みんなで触ってみましょう!
論文、参考文献リスト
AutoAugment: Learning Augmentation Policies from Data
- arxiv
- googleの解説ブログ
- 英語の解説:RNNのイメージが説明されていて助かります
- 日本語の解説: 実験結果とかこちら見ると良いかと
Fast AutoAugment
Faster AutoAugment: Learning Augmentation Strategies using Backpropagation
- arxiv
- 日本語版論文(短い)
- 著者グループのSSII 2021講演資料:SSII 2021参加者配布版は同じグループのMADAOの解説なども含まれています
- cvpaper.challengeのサマリ
- 公式実装