はじめまして,@kuz44ma69です
Neural Architecture Search (NAS) Advent Calendar 2019
25日目最初で最後の記事です
職場で
NAS勉強しようぜ!
⇒ Advent Calendar やろうぜ!
⇒ Calendar 作ったよ!
⇒ 参加者いない…
という悲しい流れが発生しこのような状態になりましたが,
せっかくなので何か書こうということで,
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware(ICLR 2019)
を備忘録がてらまとめたいと思います
もう古く(約1年前)なってきてますが,
NASでサーチ部分の実装を公開している数少ない?論文なので読んでみました
かなりやっつけで書いたのでいつか修正したい(するとは言ってない)
本論文関連リンク
お前の解説なんぞいらんという人はこちらをどうぞ
Proxy Less?
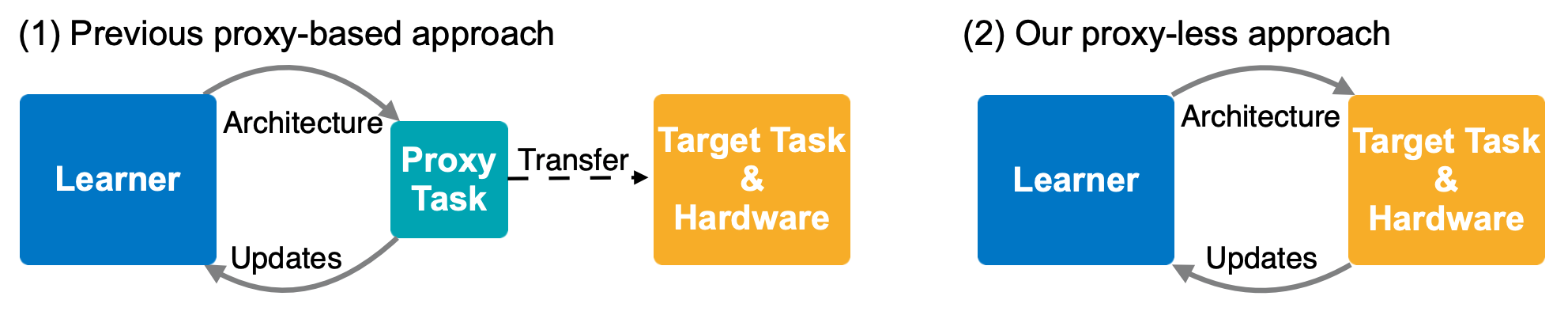
Proxy(代理、代理権、代理人、代理委任状)がLessなNASということで,
図の通りターゲットタスクに対して"ダイレクトに"最適化を行います
サーチが高速なNAS手法でメジャーなDARTS[^1]は,
候補となるNW構造を全部含んだhypernetworkを保持するのでメモリをめちゃ食います
なので,ちゃんとセルを積み上げたNWを使って探索を行わず,
浅めに積んだNWを代替として使って探索を行います
つまり浅く積んだNWを使った探索がProxyタスクとなっています
本論文では,コストを抑えることで,
Proxyタスクを用意せずにダイレクトな最適化を実現しています
Target Hardware?
本論文では,実行ハードウェアでの計算時間を考慮した探索を行っています
NW構造から各計算機(GPU, CPU, Mobile)での処理時間を推定し損失に加えることで,
各計算機での処理時間が良い感じになるよう探索を行っています
コストを抑える?

DARTSでは(b)のように,候補となる各操作(ConvやPool等)を行い,
各出力を重みづけして足し合わせたものを出力とします
で,逆伝搬させて重みを最適化していけば,重みの大きい操作が分かり,
良い感じのNW構造が見つかるという寸法です
が,feature mapをぜ~んぶ持っているのでメモリをドカ食いします
本論文では,バイナリゲートを導入して操作を1つに絞り,
そいつに関するパラメタだけに注目することでメモリを抑制します
バイナリゲートの式はこんな感じで確率によって操作が1つだけ選択されています
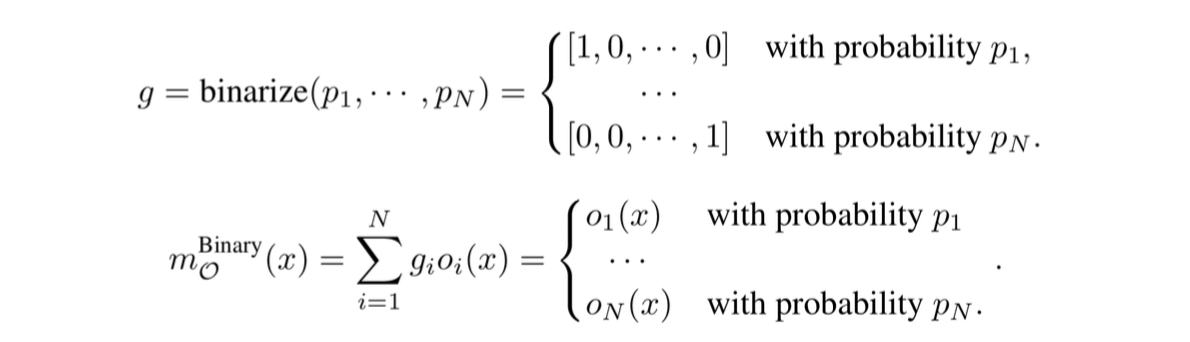
あとは,ゲートで選択された操作のパラメタ更新と,
操作を選択するパラメタの更新を交互に行っていけばOK
とはいかず,このままだと勾配使ってゲートの確率の部分を最適化できないので,
と∂L/∂gi を ∂L/∂piの代わりに使う近似を用いた↓の式を使います
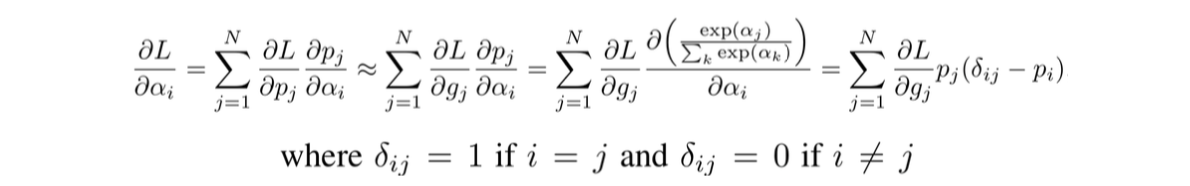
でも,↑の式を使っても,∂L/∂gj を計算するには各操作の出力が必要で,これをどうにかしたい
そこで,"The intuition is that if a path is the best choice at a particular
position, it should be the better choice when solely compared to any other path."
という考えに基づいて2つの操作だけをサンプリングします
(こんなことして良いの?という気持ちが拭えないんですが,よくある話なんですかね…)
これで↑の式を使ってパラメタの更新ができるようになりました
めでたし,めでたし
計算時間を考慮した探索?
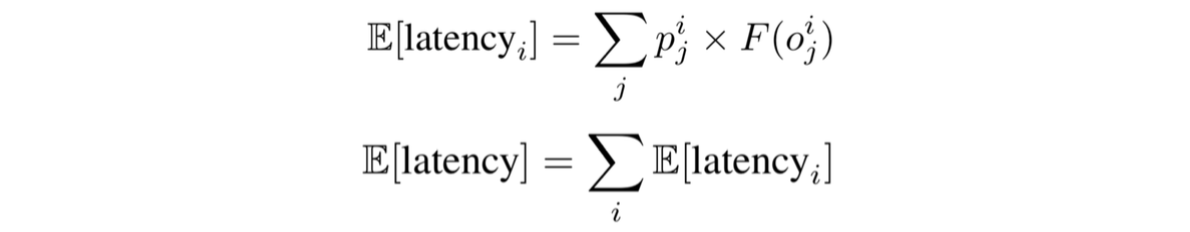
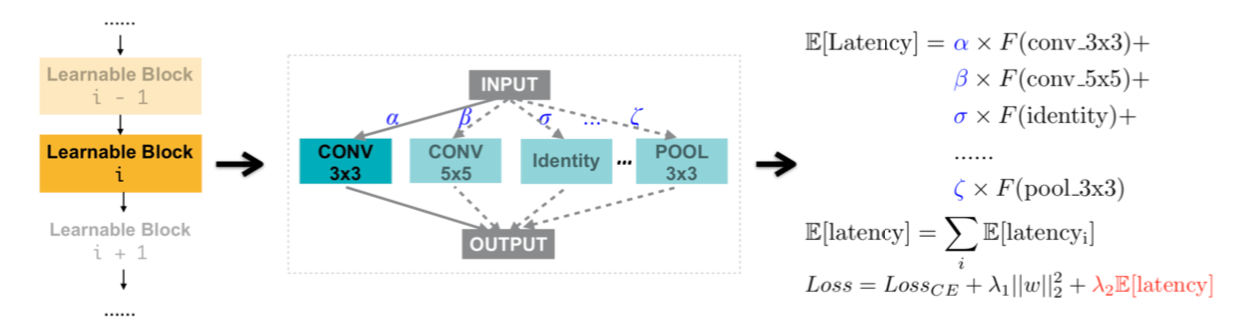
各操作の処理時間を予測する関数Fを用意して,
各操作ごとの重みと各操作の予測処理時間を掛け合わせたものをトータルの予測処理時間とし,
これが小さくなるように損失にぶっこみます
強化学習ベースのアプローチ
REINFORCEを使ってうにょうにょやる
ね,簡単でしょう?(雑
実験結果
Cifar-10
割愛
ImageNet

- Proxyless-G: 勾配ベース
- Proxyless-G + LL: 勾配ベース + 処理時間制御の損失(Latency regularization Loss)
- Proxyless-R: 強化学習ベース(ACC(m) × [LAT(m)/T]^wで性能と処理時間を両立したターゲットを設定)
のどれでやっても探索コストの割りに性能・速度がそれなりに良い感じのものが見つかっています
注意したいのは,探索空間をMobileNetv2のmobile inverted bottleneck convolution(MBConv)に限定していることです
"we allow a set of MBConv layers with various kernel sizes {3, 5, 7} and expansion ratios
{3, 6}. To enable a direct trade-off between width and depth, we initiate a deeper over-parameterized network and allow a block with the residual connection to be skipped by adding the zero operation to the candidate set of its mixed operation."
頭悪そうにすら見えるNAS定番のぐちゃぐちゃした構造はProxylessNASだと見つからないので,
ぐちゃぐちゃさせたい人はDARTSにしときましょう
所感
このグループのAMC: AutoML for Model Compression and Acceleration on Mobile Devicesも読みやすいし賢いやり方してんな~と思う論文だった
ハードごとで処理時間違うというのをちゃんと分かってるとこも素晴らしい
(MACとかパラメタ数とかだけで実際の処理時間は語れないよね…)
冬休みにちょっと遊んでみたいけど,200 GPU hoursか~