はじめに
本記事では、BIツールにデータを取り込む(地味だけど大事な)コネクタについての役割、そして、現在(2018/12/3)Power BI が提供しているコネクタの対応状況についてまとめてみました。
BIツールにおけるコネクタの位置付け
BIツールでのデータを川の流れのように表現した場合、最終的にユーザが見るダッシュボードなどのビジュアライズが下流、データソースからBIツールにデータを取り込むコネクタは上流にあたります。
【上流】[データソース]→**[コネクタ]**→[データプレパレーション]→[モデリング]→[ビジュアライズ] 【下流】
コネクタは、分析やビジュアライズに必要なデータをデータベースやアプリケーション、そしてストリーミングで発生するデータにダイレクトに接続してデータを収集する部分です。
もし、BIツール側に対応するコネクタが無いと、都度、BIツールに取り込めるようなフォーマット(具体的にはCSVファイルなど)に変換してから取り込む必要があり、「データ準備が分析作業の75%が占める」と言われているようにBIの運用負荷をあげてしまう要因となっています。そのため、コネクタは、カバーしているデータソースのラインナップがBIツールの競争力に直結するといえます。
コネクタに求められること
それは、異なるデータソースを全て同じ表形式(テーブル)化する事でデータに同じ方法でアクセス出来るようにするです。表形式(テーブル)とは、行(レコード)と列(カラム・フィールド)でデータを保持するデータ構造の事です。
コネクタに必要な機能をもう少しブレークダウンすると具体的には以下の3点です。
| 機能 | 説明 |
|---|---|
| 接続 | 認証やネットワーク越しのデータソースにアクセス |
| メタデータの付与 | データセットの纏まりをテーブルオブジェクトにしてテーブルオブジェクトにはフィールド(列)の名称・型・桁数などの属性情報を定義 |
| 標準クエリーでのアクセス | SQLなどの標準的なデータ取得方法でデータにアクセス |
これを満たす事により、どのようなデータソースであっても同じようにデータに対してアクセス出来るようになります。
Power BI におけるコネクタとは
Power BI では、このコネクタの事をデータソースとも呼ばれています。現在、PowerBIで利用出来るコネクタは94種類(2018/12/3現在)あります。
(参考情報) Power BI Desktop のデータ ソース
これらのコネクタは「データを取得」から使うことが出来ます。
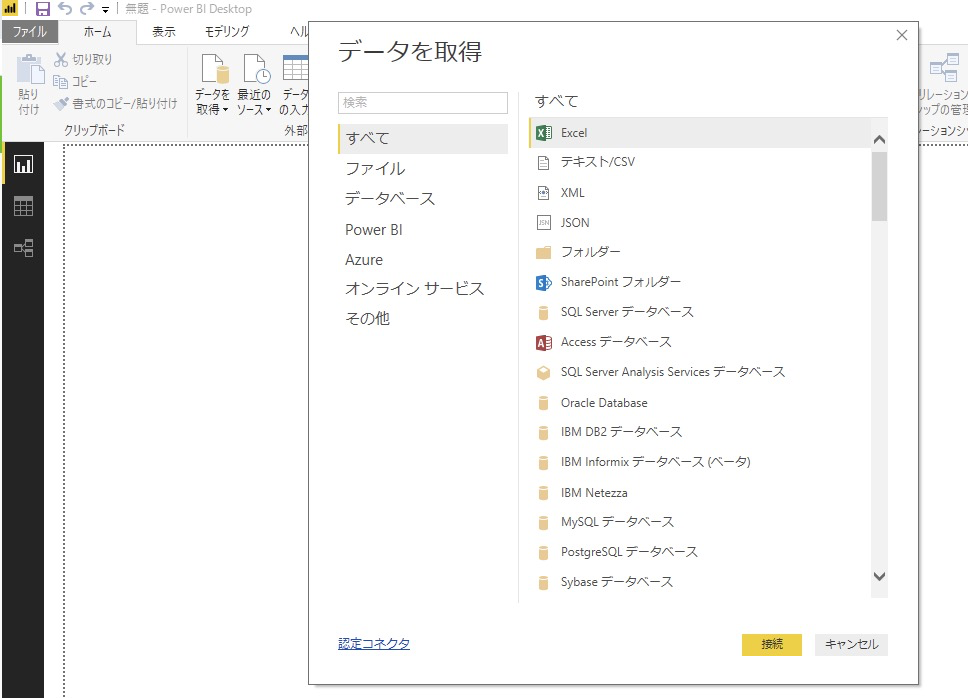
現在Power BI が対応しているコネクタを見てみよう
Power BIのコネクタの分類は以下の通りグループ化されています。
・すべて
・ファイル
・データベース
・Power BI
・Azure
・オンライン サービス
・その他
「すべて」は全コネクタとなるので「ファイル」から順に見ていきます。
ファイル
・Excel
・TEXT/CSV
・XML
・JSON
・フォルダー
・PDF (ベータ)
・SharePoint フォルダー
ExcelやTEXT/CSVというのは従来のExcelやMS-Accessのデータソースとしても利用されていたのでテーブル化のイメージは湧きやすいと思います。
一方、XMLやJSONは、データの内容によって保有する項目が異なり階層状にデータを保持する「非構造化データ」と呼ばれており(「規則性のある非構造化データ」ともいうみたいです)、構造化されたテーブルとは異なるデータ構造となります。
Power BI でJSONデータソースをどのようにしてテーブル化して扱えるようにしているかについて後半の(補足)JSONデータソースのテーブル化の章で説明しています。
フォルダーというのは、(テーブルの列)構造が同じExcelやCSVファイルであれば、同一フィルダ内の複数ファイルを1つのテーブルとして扱える、というものです。「yyyymmdd.csv」などのように日付毎にフォルダに格納されるデータや「部門XX.xlsx」のように部門別のファイルを纏めて扱うといったユースケースで活用出来ます。
(参考情報) [https://docs.microsoft.com/ja-jp/power-bi/desktop-combine-binaries]
最近追加されたようですが、PDFファイルも扱えるようになりました。自治体などのオープンデータはPDFでしか公開していないケースも多いので、このコネクタを使ってオープンデータとローカルデータのマッシュアップといった事も出来るようになるのでは、と思っています(すいません、私はまだ試した事がないです。PDF生成ソフトや元ファイルによってどこまでのファイルを読み込めるのか、、、が気になります)。
(参考情報) Power BI Desktop で PDF ファイルに接続する (プレビュー)
データベース
・SQL Server データベース
・Access データベース
・SQL Server Analysis Services
・Oracle データベース
・IBM DB2 データベース
・IBM Informix データベース (Beta)
・IBM Netezza
・MySQL データベース
・PostgreSQL データベース
・Sybase データベース
・Teradata データベース
・SAP HANA データベース
・SAP Business Warehouse Application サーバー
・SAP Business Warehouse メッセージ サーバー
・Amazon Redshift
・Impala
・Google BigQuery
・Snowflake
・BI コネクタ
・Exasol
・Dremio (ベータ)
・Jethro (ベータ)
・Kyligence Enterprise (ベータ)
これらのデータソースは、いわゆるRDBなのでテーブル構造のデータで保持しているので、専用コネクタかベンダーが提供しているODBCドライバで利用する事が出来ます。
また、これらのデータソースの中で、ビッグデータ処理基盤を中心にDirectQueryがサポートされており、アドホックな大量データの集計処理をサポートしています。
(参考情報) Power BI で DirectQuery を使用する
(参考情報) Power BI の DirectQuery でサポートされるデータ ソース
Power BI
・Power BI データ セット
・Power BI データフロー (ベータ)
クラウド上のPower BI サービスのデータセットを利用する事が出来るため、組織で共有しているデータセットを用いたレポートやダッシュボードを作る事が出来ます。
Power BI データフローについては、Power BI の新しい機能で、データプレパレーション(準備)を行う機能です。私は、まだ、詳しくはキャッチアップ出来てませんが、セルフサービス型のETLやジョブスケジューリングような機能でマルチデータソースを統合するのに便利そうです。なので、データフローでマルチデータソースを統合&クレンジング済みのデータをPower BI のデータソースとして扱える、という事だと理解しています。
(参考情報) Power BI でのセルフサービスのデータ準備 (プレビュー)
(参考情報) Power BI Desktop で Power BI データフローによって作成されたデータに接続する (ベータ版)
AZURE
・Azure SQL Database
・Azure SQL Data Warehouse
・Azure Analysis Services データベース
・Azure BLOB ストレージ
・Azure テーブル ストレージ
・Azure Cosmos DB (ベータ版)
・Azure Data Lake Storage
・Azure HDInsight (HDFS)
・Azure HDInsight Spark
・HDInsight 対話型クエリ
・Azure Data Explorer (ベータ)
MicrosoftのBIツールだけあって、Azure上のデータベースやデータ処理基盤への対応カバー範囲は他のBIツールに比べても群を抜いています。RDBベースのSQL Databaseだけではなく、OLAPベースのAnalysis Services、最新のNoSQL・分散データベースであるCosmos DBまでカバーしています。
(参考情報) Azure と Power BI
オンライン サービス
・SharePoint Online リスト
・Microsoft Exchange Online
・Dynamics 365 (オンライン)
・Dynamics NAV
・Dynamics 365 Business Central
・Dynamics 365 Business Central (オンプレミス)
・アプリ用 Common Data Service (ベータ)
・Microsoft Azure Consumption Insights (Beta)
・Azure DevOps (ベータ)
・Azure DevOps Server (ベータ)
・Salesforce オブジェクト
・Salesforce レポート
・Google アナリティクス
・Adobe Analytics
・appFigures (Beta)
・comScore Digital Analytix (Beta)
・Dynamics 365 for Customer Insights (ベータ)
・Data.World - データセットの取得 (Beta)
・Facebook
・GitHub (Beta)
・MailChimp (Beta)
・Marketo (Beta)
・Mixpanel (Beta)
・Planview Enterprise One - PRM (Beta)
・Planview Projectplace (Beta)
・QuickBooks Online (Beta)
・Smartsheet
・SparkPost (Beta)
・Stripe (Beta)
・SweetIQ (Beta)
・Planview Enterprise One - CMT (Beta)
・Twilio (Beta)
・tyGraph (Beta)
・Webtrends (Beta)
・Zendesk (Beta)
・TeamDesk (Beta)
これらのデータソースはアプリケーションやWebサービスです。対象は、CRM、MA(マーケティングオートメーション)、ERP、会計、グループウェア、更にはSNSと様々です。DynamicsシリーズやSharePointといったMicrosoftプロダクトも充実しているのも特徴です。
Power BIでは、従来のファイルやデータベースというデータソースだけでなく、SaaSと呼ばれる業務アプリケーション内のデータをWebAPI経由でダイレクトに接続してデータを取得出来ます。データへのアクセスは、データソース側が提供しているWebAPIへのHTTPベースのリクエストで、レスポンスはJSONやXML形式で取得されます。下記の図でいうと、下段の「アプリケーション」という部分がPower BI となります。
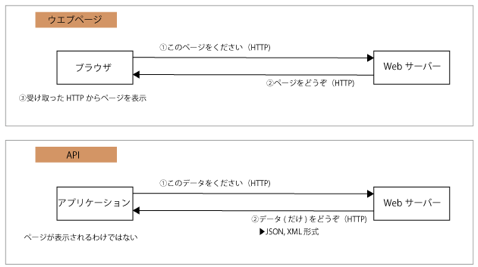
これらのアプリケーションは、データベースではないため#コネクタに求められることで述べた「メタデータの付与」がポイントとなります。Facebookのようにテーブル構造が予め決まっているものもあれば、SalesforceやDynamics365のようにカスタムオブジェクトやカスタムフィールドが自由に追加・変更出来るものもあり、その場合には、データの内容やメタデータ取得APIエンドポイントを利用したダイナミックなメタデータの付与が必要となります。また、認証方式も従来のRDBとは大きく異なり、個別に異なり、サービスのユーザID&パスワードに加えて、OAuthやTokenでの認証する方式のものが多くあります。
その他
・Vertica
・Web
・SharePoint リスト
・OData フィード
・Active Directory
・Microsoft Exchange
・Hadoop ファイル (HDFS)
・Spark
・R スクリプト
・Python スクリプト
・ODBC
・OLE DB
・Denado
・Paxata (ベータ)
・空のクエリ
この中で、下記のデータソースを使うと、これまで説明してきたPowerBIのデータソースのリストにないデータソースにも接続する事が出来ます。これらのデータソースは、ジェネリックデータインタフェースと呼ばれています。
・ODBC
・OLE DB
・OData
・REST API
・R スクリプト
(参考情報) Power BI Desktop でジェネリック インターフェイスを使用してデータに接続する
例えば、ODBCデータソースを利用する事で、私が所属するCData Software社のODBCドライバを使いkintoneなどのWebサービスやDynamoDBやMongoDBといったNoSQLデーたベースなど(PowerBI標準と被りはあるものの)100を超えるデータソースにダイレクトに接続する事が出来るようになります。
(参考情報) CData ODBC Drivers
また、ODataやREST APIのコネクタを使用する事で、OData規格のREST APIでデータを公開しているSAPシステムやGETメソッドで単純なJSONをレスポンスで返すようなWebAPIを提供しているクラウドサービスからデータを取得する事が出来ます。ただし、一口にREST APIといっても仕様のばらつきが大きいので、実際、お目当のデータソースから意図した形でデータが取得出来るかどうかは試してみないと分からないです。
Rスクリプトについては、私は使用した事ないですが、Rスクリプトによる統計解析結果の他にSASやSPSSという商用統計解析ソフトウェアの結果も取り込めるようです。
(補足)JSONデータソースのテーブル化
ファイルの章でも説明しましたが、XMLやJSONは、データの内容によって保有する項目が異なり階層状にデータを保持する「非構造化データ」と呼ばれており(「規則性のある非構造化データ」ともいうみたいです)、構造化されたテーブルとは異なるデータ構造となります。本章では、Power BI でJSONデータソースをどのようにしてテーブル化して扱えるようにするかみてみましょう。
以下、サンプルとして使用する「顧客が所有している車両のメンテナンスの履歴データ」のJSONデータです。
{
"people": [
{
"personal": {
"age": 20,
"gender": "M",
"name": {
"first": "John",
"last": "Doe"
}
},
"vehicles": [
{
"type": "car",
"model": "Honda Civic",
"insurance": {
"company": "ABC Insurance",
"policy_num": "12345"
},
"maintenance": [
{
"date": "07-17-2017",
"desc": "oil change"
},
{
"date": "01-03-2018",
"desc": "new tires"
}
]
},
{
"type": "truck",
"model": "Dodge Ram",
"insurance": {
"company": "ABC Insurance",
"policy_num": "12345"
},
"maintenance": [
{
"date": "08-27-2017",
"desc": "new tires"
},
{
"date": "01-08-2018",
"desc": "oil change"
}
]
}
],
"source": "internet"
}
]
}
上記のJSONデータを、最も最下層のMemberであるmaintenanceの粒度でテーブル化した場合は以下の通りです。
| age | gender | name_first | name_last | type | model | insurance_company | insurance_policy_num | maintenance_date | maintenance_desc | source |
|---|---|---|---|---|---|---|---|---|---|---|
| 20 | M | John | Doe | car | Honda Civic | ABC Insurance | 12345 | 07-17-2017 | oil change | internet |
| 20 | M | John | Doe | car | Honda Civic | ABC Insurance | 12345 | 01-03-2018 | new tires | internet |
| 20 | M | John | Doe | truck | Dodge Ram | ABC Insurance | 12345 | 08-27-2017 | new tires | internet |
| 20 | M | John | Doe | truck | Dodge Ram | ABC Insurance | 12345 | 01-08-2018 | oil change | internet |
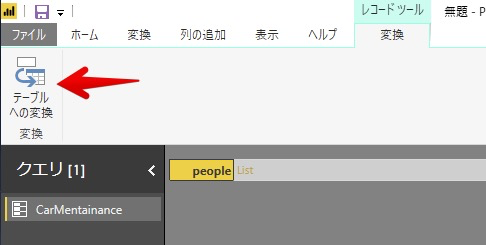
Power BIでは、これらのテーブル化はJSONデータソースでJSONファイルを指定した後に「クエリを編集」にて行うことが出来ます。
「クエリを編集」内の「テーブルへの変換」を実行
ヘッダーの「←→」のアイコンをクリックして別項目として展開するName(項目名)を指定
※JSONの階層が深いと何回か指定しないといけないです
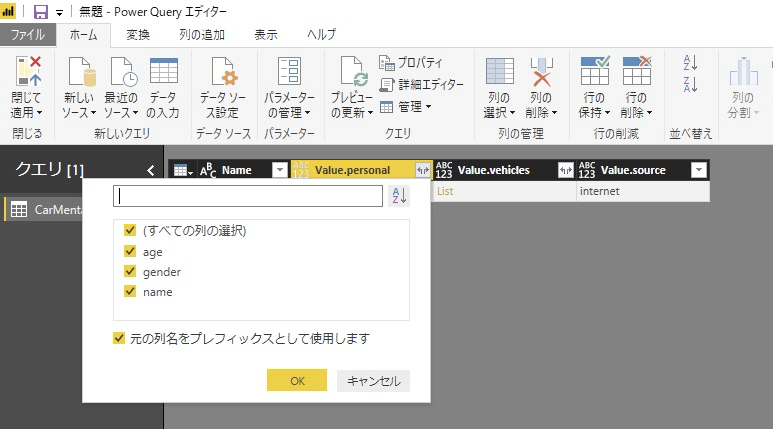
JSONの各Name(項目名)が列となった非正規化されたテーブルが作成
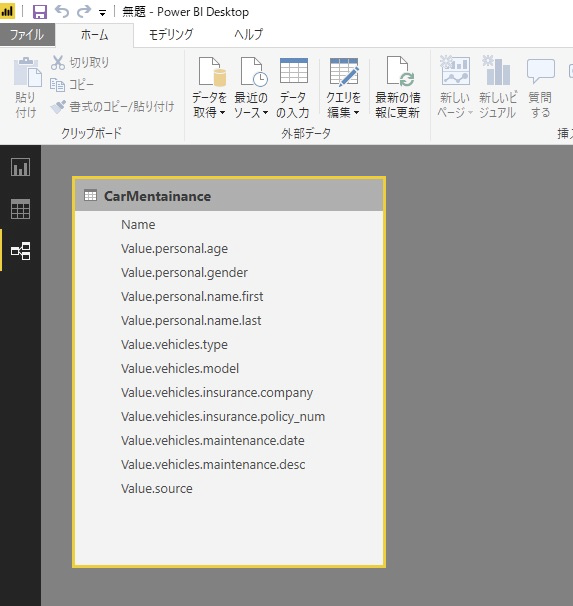
更に、このデータを正規化して分割してみると以下のテーブルで表現出来ます。
※全てのテーブルにId列を追加しました。
personalテーブル
| Id | age | gender | name_first | name_last |
|---|---|---|---|---|
| 1 | 20 | M | John | Doe |
vehiclesテーブル
| Id | type | model | insurance_company | insurance_policy_num | personal_id |
|---|---|---|---|---|---|
| 1 | car | Honda Civic | ABC Insurance | 12345 | 1 |
| 2 | truck | Dodge Ram | ABC Insurance | 12345 | 1 |
maintenanceテーブル
| Id | date | desc | vehicles_Id |
|---|---|---|---|
| 1 | 07-17-2017 | oil change | 1 |
| 2 | 01-03-2018 | new tires | 1 |
| 3 | 08-27-2017 | new tires | 2 |
| 4 | 01-08-2018 | oil change | 2 |
このようなJSONデータもテーブル構造に変換出来れば、テーブル形式のデータの列を選択してデータフォーマットを整えたり、テーブルを分割して重複を排除した正規化や分析データモデル(スタースキーマ/スノーフレークモデル)を作成する事が出来るようになります。
まとめ
Power BI では、日々すごい勢いでコネクタが増えています。今後どのようなコネクタが追加されるかは、サードパーティーのコネクタベンダーとして気になるところです。来年(2019年)のアドベントカレンダーでは、「2019年で追加されたPower BI コネクタ」をネタに書こうかと企んでます(笑)。