はじめに
本記事はNTTテクノクロス Advent Calendar 2024の20日目です。
みなさん、どうもこんにちは。NTTテクノクロスの下本です。
社内のチームにGAN(敵対的生成ネットワーク)を紹介する機会があったので、生成モデルを自作してみようと考えました。今回は画像生成ができることを目標とします。
技術紹介
GAN
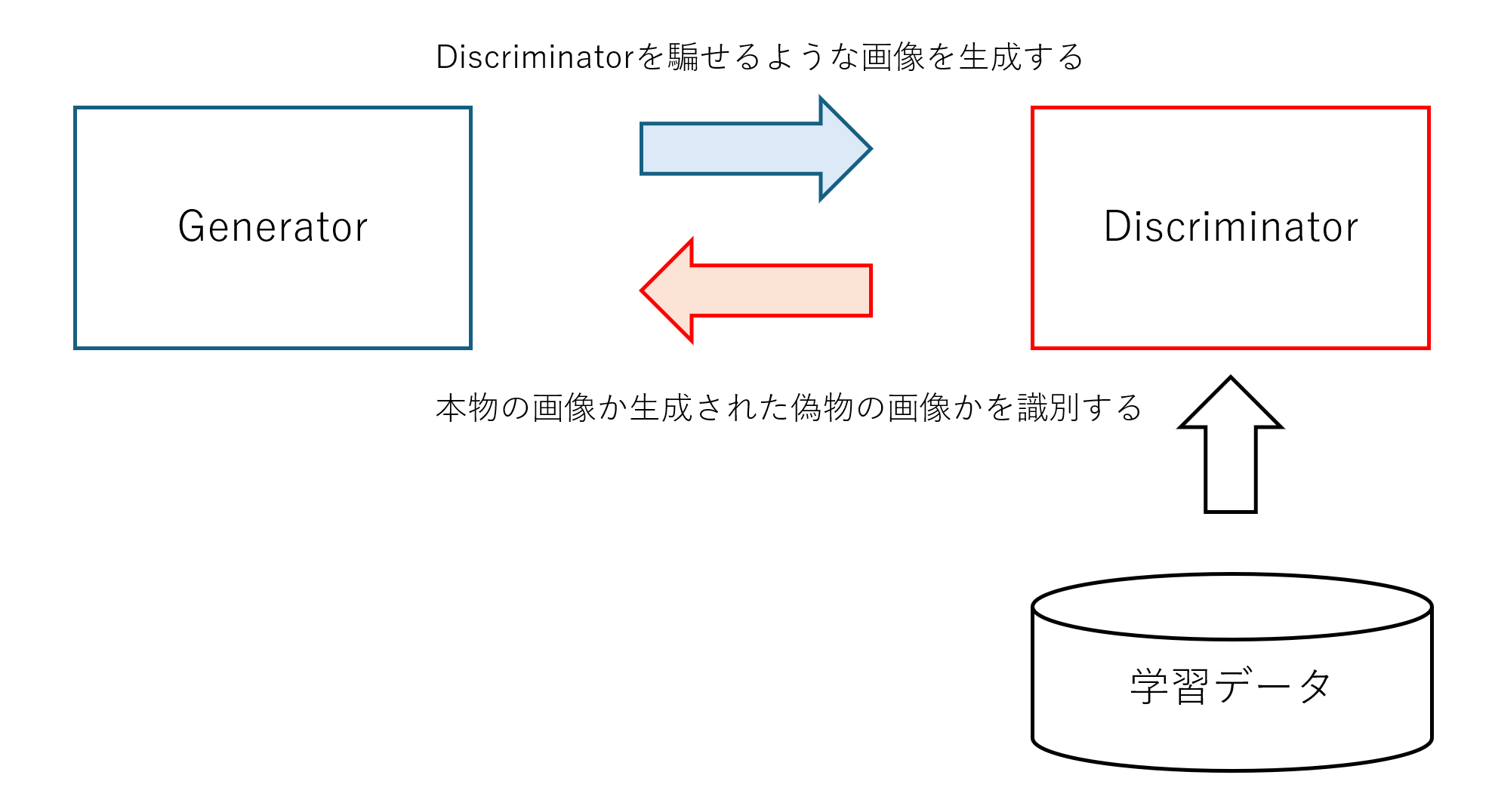
GANとはGenerative Adversarial Networksの略称です。特徴としてはGeneratorとDiscriminatorの2つのネットワークがそれぞれ学習を進めて、本物に近い画像を生成できるモデルになっていきます。画像生成専門ではなく、音声や動画の生成も可能です。
詳細は 以下の記事 や 論文 1で説明されています。
シンプルに構造を図示すると以下のようになります。対立して学習していく構造から、敵対的と呼ばれています。それぞれが学習を重ねてレベルアップしていくため、最終的に生成させるモデルは精工な学習データに似たデータを生成することができます。
PGGAN
GAN自体は以前から存在する技術のため、拡張手法であるPGGAN(Progressive Growing of GANs)も作成してみます。詳細なアルゴリズムの説明はここではしませんが、以下の記事で丁寧に説明されています。元となった論文2はこちらです。学習が素早く進行するように拡張されたモデルです。
全体を通して学習データにはMNISTデータベースで公開されている手書き数字画像を用います。機械学習の学習や評価で使用されています。論文3はこちらになります。以下の記事にて丁寧に説明されているので詳しく知りたい方はご確認ください。採用理由はPythonのモジュールを用いると1行でダウンロードできるためです。元データを一度もご覧になったことがない方は先に配布元のデータをご自身で確認いただけると、この後に記載している生成画像の結果と比較がしやすいと思います。
実装
以下実装パートです。
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.utils as vutils
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def prepare_dataloader(batch_size):
transform = transforms.Compose([
transforms.Resize(32),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),
])
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(root='./data', train=True, download=True, transform=transform),
batch_size=batch_size, shuffle=True
)
return dataloader
class Generator(nn.Module):
def __init__(self, latent_dim):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 1024),
nn.ReLU(),
nn.Linear(1024, 28 * 28),
nn.Tanh()
)
def forward(self, z):
return self.model(z).view(-1, 1, 28, 28)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28, 1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 1),
nn.Sigmoid()
)
def forward(self, img):
return self.model(img)
def train_gan(generator, discriminator, dataloader, criterion, optimizer_G, optimizer_D, latent_dim, num_epochs, output_dir, device):
generator.to(device)
discriminator.to(device)
for epoch in range(num_epochs):
for i, (real_imgs, _) in enumerate(dataloader):
batch_size = real_imgs.size(0)
real_imgs = real_imgs.to(device)
# ラベルの作成
real_labels = torch.ones((batch_size, 1), device=device)
fake_labels = torch.zeros((batch_size, 1), device=device)
# ノイズを生成
z = torch.randn((batch_size, latent_dim), device=device)
fake_imgs = generator(z)
# Discriminatorの学習
optimizer_D.zero_grad()
real_loss = criterion(discriminator(real_imgs), real_labels)
fake_loss = criterion(discriminator(fake_imgs.detach()), fake_labels)
d_loss = real_loss + fake_loss
d_loss.backward()
optimizer_D.step()
# Generatorの学習
optimizer_G.zero_grad()
g_loss = criterion(discriminator(fake_imgs), real_labels)
g_loss.backward()
optimizer_G.step()
# 生成画像の保存
if (epoch + 1) % 10 == 0:
with torch.no_grad():
z = torch.randn((16, latent_dim), device=device)
generated_imgs = generator(z)
generated_imgs = (generated_imgs + 1) / 2
vutils.save_image(generated_imgs, os.path.join(output_dir, f'generated_epoch_{epoch + 1}.jpg'), nrow=4, normalize=True)
50エポック(50回目の学習結果)時点の生成画像がこちらです。目でみる限りは手書き数字画像が生成できていると言えるのではないでしょうか。

現状以下はハイパーパラメータとして指定しています。バッチサイズや次元数は学習結果に影響があるので色々変更して実行してみてください。マシンスペックにもよりますが、そこまで学習に時間はかからないと思います。
latent_dim = 100
num_epochs = 50
batch_size = 64
learning_rate = 0.0002
次にPGGANです。上記のコードとの共通部分は省略します。こちらはlearning_rateは指定しています。
class Generator(nn.Module):
def __init__(self, latent_dim, num_layers):
super(Generator, self).__init__()
self.num_layers = num_layers
self.layers = nn.ModuleList()
self.layers.append(nn.Sequential(
nn.ConvTranspose2d(latent_dim, 512, 4, 1, 0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(True)
))
self.layers.append(nn.Sequential(
nn.ConvTranspose2d(512, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True)
))
self.layers.append(nn.Sequential(
nn.ConvTranspose2d(256, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True)
))
self.layers.append(nn.Sequential(
nn.ConvTranspose2d(128, 1, 4, 2, 1, bias=False),
nn.Tanh()
))
def forward(self, x, depth):
for i in range(depth + 1):
x = self.layers[i](x)
return x
class Discriminator(nn.Module):
def __init__(self, num_layers):
super(Discriminator, self).__init__()
self.num_layers = num_layers
self.layers = nn.ModuleList()
self.layers.append(nn.Sequential(
nn.Conv2d(1, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True)
))
self.layers.append(nn.Sequential(
nn.Conv2d(128, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True)
))
self.layers.append(nn.Sequential(
nn.Conv2d(256, 512, 4, 2, 1, bias=False),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2, inplace=True)
))
self.layers.append(nn.Sequential(
nn.Conv2d(512, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
))
def forward(self, x, depth):
for i in range(depth + 1):
x = self.layers[i](x)
return x
def train_pggan(num_epochs, latent_dim, num_layers, dataloader, output_dir):
generator = Generator(latent_dim, num_layers).to(device)
discriminator = Discriminator(num_layers).to(device)
criterion = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
for epoch in range(num_epochs):
for i, (real_imgs, _) in enumerate(dataloader):
batch_size = real_imgs.size(0)
real_imgs = real_imgs.to(device)
real_labels = torch.ones((batch_size, 1, 1, 1), device=device)
fake_labels = torch.zeros((batch_size, 1, 1, 1), device=device)
# ノイズを生成
z = torch.randn((batch_size, latent_dim, 1, 1), device=device)
fake_imgs = generator(z, num_layers - 1)
# Discriminatorの学習
optimizer_D.zero_grad()
real_loss = criterion(discriminator(real_imgs, num_layers - 1), real_labels)
fake_loss = criterion(discriminator(fake_imgs.detach(), num_layers - 1), fake_labels)
d_loss = real_loss + fake_loss
d_loss.backward()
optimizer_D.step()
# Generatorの学習
optimizer_G.zero_grad()
g_loss = criterion(discriminator(fake_imgs, num_layers - 1), real_labels)
g_loss.backward()
optimizer_G.step()
こちらは10エポック時点で以下のような画像を生成しました。

参考までにGANの10エポック時点の生成画像が以下でした。まだ学習しきれていないので、学習速度の差が顕著に現れていることが確認できます。

この結果になった要因としては、GeneratorとDiscriminatorに低解像度の層を追加したことにあります。Discriminatorだと以下の部分です。各ネットワークの学習を低解像度から始めていくことで単純な質問に答えていくだけのような状況で学習できるようになります。複雑である潜在表現から高解像度の画像へのマッピングは段階的に学んだほうが簡単と言われています。
self.layers.append(nn.Sequential(
nn.Conv2d(1, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True)
))
まとめ
GANと拡張手法であるPGGANを構築してみました。Discriminatorの層の数、各層への入力チャネル数、カーネルサイズを意識しながら構築する部分に苦戦しました。シンプルにしか実装できなかったこと、パラメータチューニングまで実施できなかったので今後の課題です。GANと比較される拡散モデル(Diffusion Model)の構築にも挑戦したかったのですが時間と技術不足の都合で断念しました。今後も精進していきたいと思います。
明日は@Nukkkkkkoさんの記事が投稿されます。YOLOとCore MLを用いたオブジェクトカウンティング、という内容ですので興味がある方はそちらの記事も是非ご覧ください。
では、またどこかで。
論文のリンク
-
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley,
Sherjil Ozair, Aaron Courville, Yoshua Bengio "Generative Adversarial Nets"arXiv 2014.
https://arxiv.org/pdf/1406.2661 ↩ -
Tero Karras, Timo Aila, Samuli Laine, Jaakko Lehtinen
" PROGRESSIVE GROWING OF GANS FOR IMPROVED QUALITY, STABILITY, AND VARIATION"
arXiv 2018.
https://arxiv.org/pdf/1710.10196v3 ↩ -
Y. Lecun; L. Bottou; Y. Bengio; P. Haffner "Gradient-based learning applied to document recognition" in Proceedings of the IEEE, vol. 86, no. 11, pp. 2278-2324, Nov. 1998, doi: 10.1109/5.726791.
https://ieeexplore.ieee.org/document/726791/ ↩