はじめに
AWS公式のAmazon SageMaker の開始方法の手順に沿って、機械学習モデルを構築してデプロイするまでの流れを実践してみる事にしました。
本記事は自身のハンズオン学習メモとして投稿します。
目次
機械学習とは
ここでは割愛。概要を把握するには以下を参照。
SageMakerの概要
詳しくはAWS公式のAmazon SageMaker のドキュメントを参照。
Amazon SageMaker は、完全マネージド型の機械学習サービスです。Amazon SageMaker では、データサイエンティストと開発者が素早く簡単に機械学習モデルの構築と研修を行うことができ、稼働準備が整ったホスト型環境に直接デプロイできます。統合された Jupyter オーサリングノートブックインスタンスから、調査および分析用のデータソースに簡単にアクセスできるため、サーバーを管理する必要がありません。また、一般的な機械学習アルゴリズムも使用できます。そうしたアルゴリズムは、分散環境できわめて大容量のデータに対しても効率良く実行できるよう最適化されています。自前のアルゴリズムやフレームワークもネイティブでサポートされているため、Amazon SageMaker ではお客様固有のワークフローに合わせて調整できる柔軟性の高い分散型トレーニングも行えます。Amazon SageMaker Studio または Amazon SageMaker コンソールからクリック 1 つで起動して、安全でスケーラブルな環境にモデルをデプロイします。トレーニングとホスティングは、分ごとの使用量で課金されます。最低料金や前払いの義務はありません。
(https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/whatis.html より引用)
SageMakerの説明図を見る限りいくつかインスタンスが存在するが、それぞれどのような役割なのか?
→AWS公式が公開している資料が分かりやすかったので、以下に記載。
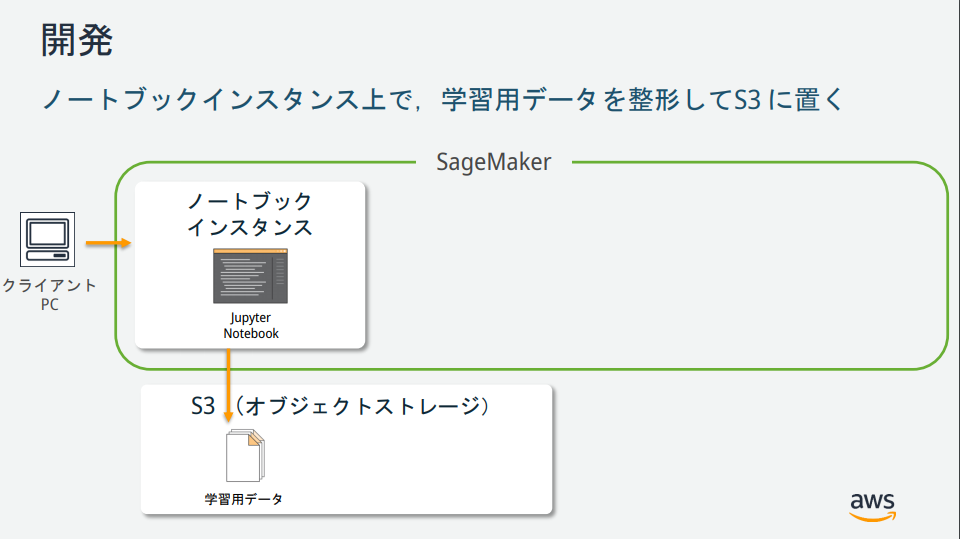

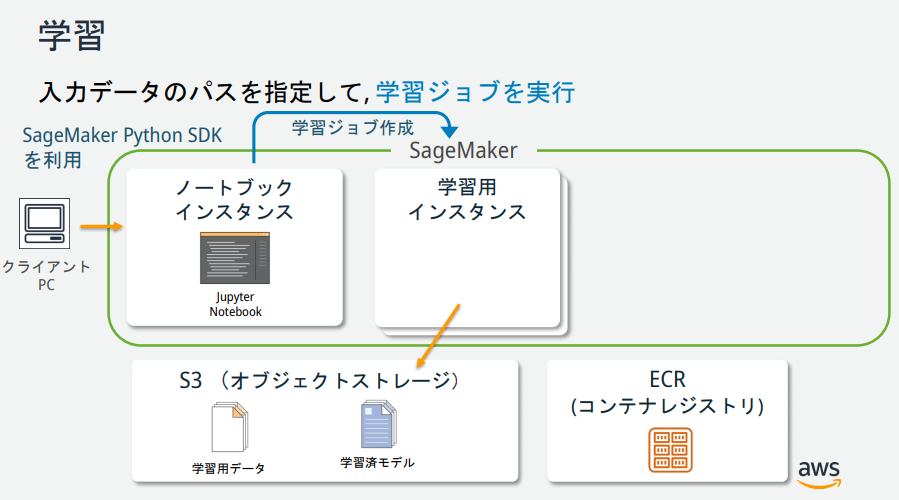
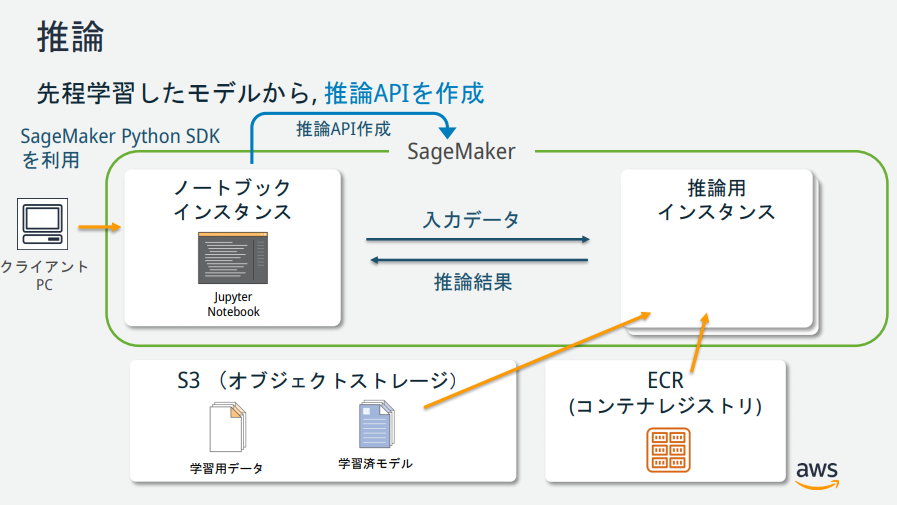
(https://pages.awscloud.com/event_JAPAN_hands-on-ml_ondemand_confirmation.html より引用)
チュートリアル
AWS公式のチュートリアルを実施。
Amazon S3 バケットを作成する
機械学習に使用するデータ、および、学習結果(モデル)を格納するための場所(バケット)を作成。
Amazon SageMaker ノートブックインスタンスの作成
Amazon SageMakerノートブックインスタンスとは、Jupyter Notebookがインストールされたフルマネージドな機械学習EC2コンピューティングインスタンス。
Jupyter ノートブックを作成する
Jupyter ノートブックとは
プログラムの作成、実行結果、グラフ、作業メモや関連するドキュメントなどを、ノートブックと呼ばれるファイル形式にまとめて、一元的に管理することを目的としたオープンソースツール。
データ分析作業などで、対話的にプログラムを実行してその結果を参照しながら次の作業を行う場合や、出力された結果を保存し、メモとともに作業記録のように残したい場合などに特に有益である。
(https://www.seplus.jp/dokushuzemi/blog/2020/04/tech_words_jupyter_notebook.html より引用)
「New」から「conda_python3」を選択。新しいノートブックが作成される。

S3とロールを指定するコードを記述。
from sagemaker import get_execution_role
role = get_execution_role()
bucket='0803-sagemaker-sample'
データをダウンロード、調査、および変換する
MNIST データセットをダウンロードする
MNISTデータとは
MNIST(Mixed National Institute of Standards and Technology database)とは、手書き数字画像60,000枚と、テスト画像10,000枚を集めた、画像データセットです。さらに、手書きの数字「0〜9」に正解ラベルが与えられるデータセットでもあり、画像分類問題で人気の高いデータセットです。
(https://udemy.benesse.co.jp/ai/mnist.html より引用)
MNISTデータセットのダウンロードを行うコードを記述。
%%time
import pickle, gzip, numpy, urllib.request, json
# Load the dataset
urllib.request.urlretrieve("http://deeplearning.net/data/mnist/mnist.pkl.gz", "mnist.pkl.gz")
with gzip.open('mnist.pkl.gz', 'rb') as f:
train_set, valid_set, test_set = pickle.load(f, encoding='latin1')
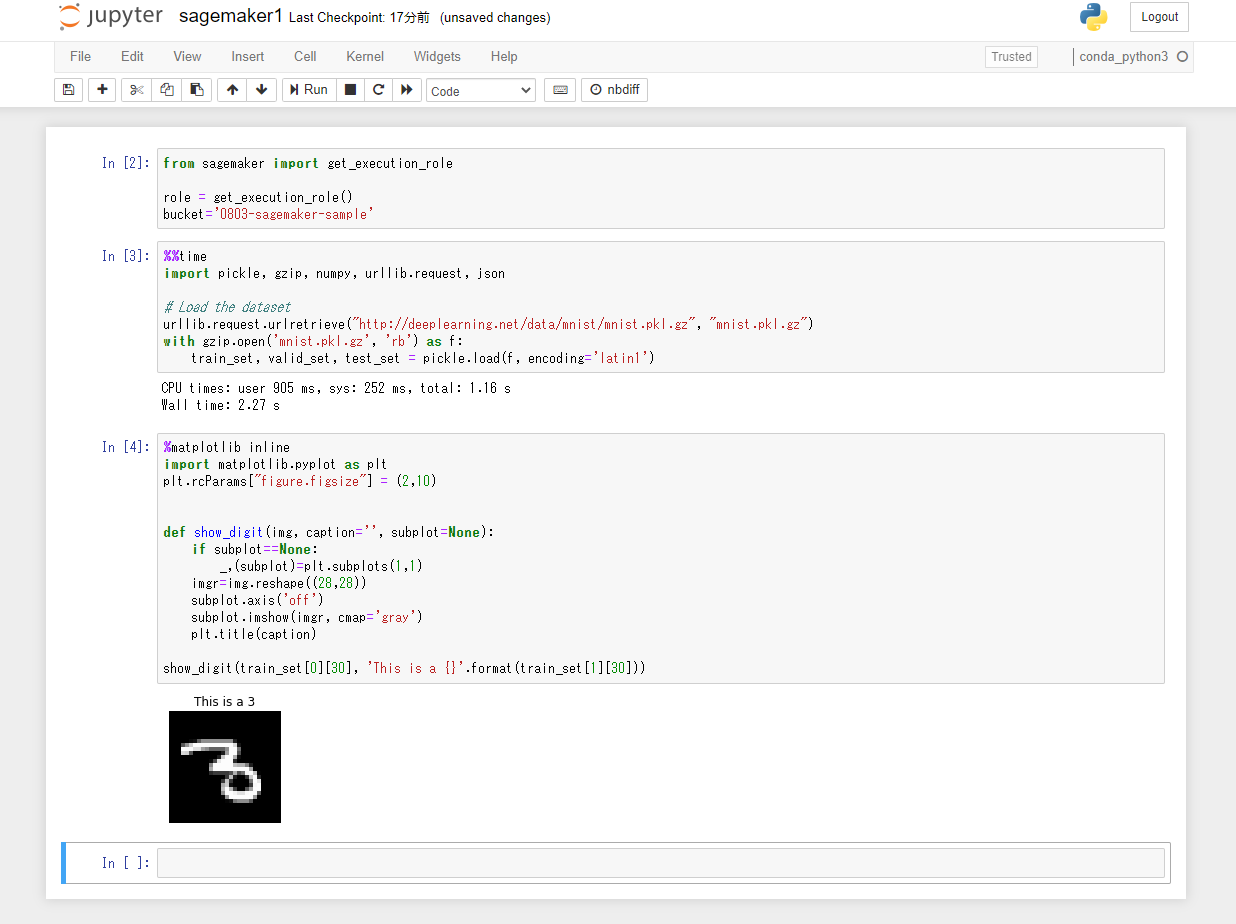
トレーニングデータセットを調べる
以下のPythonコードを3つ目のセルにペーストして、「Run」ボタンをクリック。MNISTデータセットの31枚目の画像データがラベルの内容と共に表示される。
%matplotlib inline
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (2,10)
def show_digit(img, caption='', subplot=None):
if subplot==None:
_,(subplot)=plt.subplots(1,1)
imgr=img.reshape((28,28))
subplot.axis('off')
subplot.imshow(imgr, cmap='gray')
plt.title(caption)
show_digit(train_set[0][30], 'This is a {}'.format(train_set[1][30]))
モデルをトレーニングする
トレーニングアルゴリズムを選択する
機械学習では、通常モデルに適したアルゴリズムをみつけるための評価プロセスが必要になる。
今回は SageMaker の組み込みアルゴリズムの1つである k-means を使うことが決まっているため、評価プロセスはスキップする。
k-meansとは
K-means 法はクラスタリングを行うための定番のアルゴリズムの1つ。ここでは詳細は割愛。
トレーニングジョブの作成
以下のPythonコードを4つ目のセルにペーストして、「Run」ボタンをクリック。
from sagemaker import KMeans
data_location = 's3://{}/kmeans_highlevel_example/data'.format(bucket)
output_location = 's3://{}/kmeans_example/output'.format(bucket)
print('training data will be uploaded to: {}'.format(data_location))
print('training artifacts will be uploaded to: {}'.format(output_location))
kmeans = KMeans(role=role,
train_instance_count=2,
train_instance_type='ml.c4.8xlarge',
output_path=output_location,
k=10,
data_location=data_location)
トレーニングの実行
モデルのトレーニングを実行。以下のPythonコードを5つ目のセルにペーストして、「Run」ボタンをクリック。トレーニングの所要時間は約10分。
%%time
kmeans.fit(kmeans.record_set(train_set[0]))
モデルのトレーニング完了後にS3を確認すると、モデルのトレーニングデータとモデルのトレーニング中に生成されるモデルアーティファクトが格納されている。
モデルを Amazon SageMaker にデプロイする
SageMaker にモデルをデプロイするためには、以下の3ステップの手順を実施する必要がある。
- SageMaker上でモデルを作成
- エンドポイントの設定の作成
- エンドポイントの作成
deployというメソッド一つでこれらの作業を行うことができる。以下のPythonコードを6つ目のセルにペーストして、「Run」ボタンをクリック。
%%time
kmeans_predictor = kmeans.deploy(initial_instance_count=1,
instance_type='ml.m4.xlarge')
モデルを検証する
モデルがデプロイされた為、検証を行う。以下のPythonコードを7つ目のセルにペーストして、「Run」ボタンをクリック。
result = kmeans_predictor.predict(valid_set[0][28:29])
print(result)
valid_setデータセットの30番目の画像に対する推論結果が得られる。valid_setの28番目のデータは、クラスター6に属していることがわかる。
[label {
key: "closest_cluster"
value {
float32_tensor {
values: 6.0
}
}
}
label {
key: "distance_to_cluster"
value {
float32_tensor {
values: 6.878328800201416
}
}
}
]
続いて、valid_setデータセットの先頭から100個分の推論結果を取得する。以下のPythonコードを8つ目のセルと9つ目のセルにペーストして、順番に「Run」ボタンをクリック。
%%time
result = kmeans_predictor.predict(valid_set[0][0:100])
clusters = [r.label['closest_cluster'].float32_tensor.values[0] for r in result]
for cluster in range(10):
print('\n\n\nCluster {}:'.format(int(cluster)))
digits = [ img for l, img in zip(clusters, valid_set[0]) if int(l) == cluster ]
height = ((len(digits)-1)//5) + 1
width = 5
plt.rcParams["figure.figsize"] = (width,height)
_, subplots = plt.subplots(height, width)
subplots = numpy.ndarray.flatten(subplots)
for subplot, image in zip(subplots, digits):
show_digit(image, subplot=subplot)
for subplot in subplots[len(digits):]:
subplot.axis('off')
plt.show()
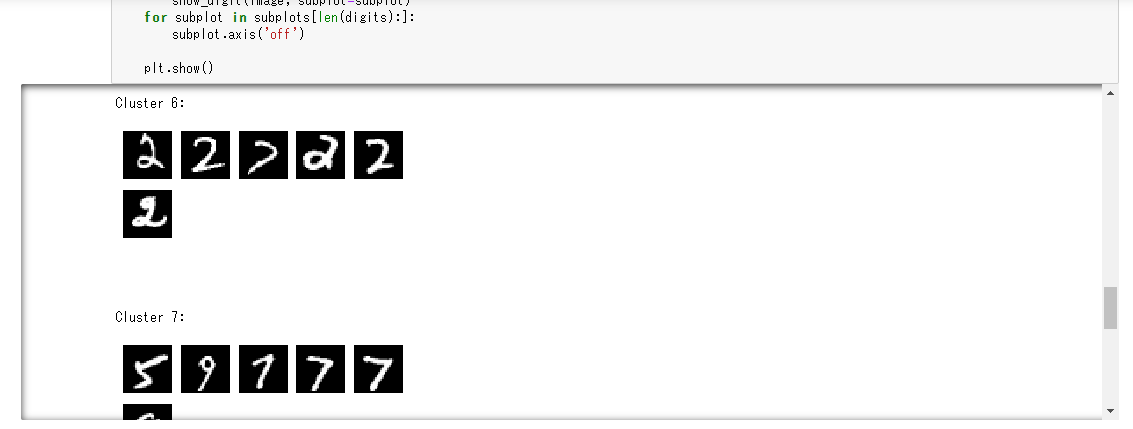
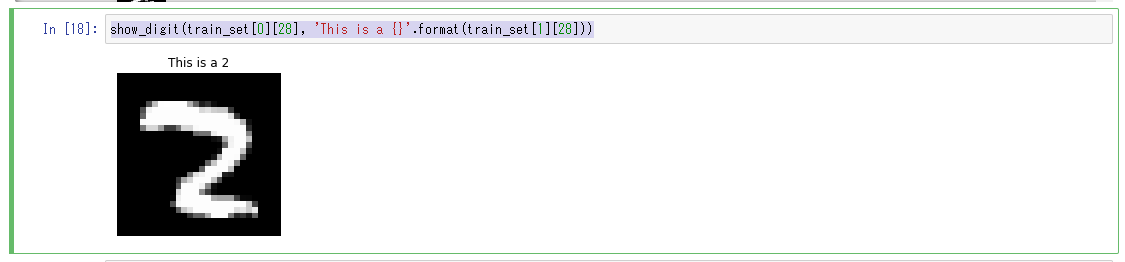
「トレーニングデータセットの調査」で使用したshow_digitメソッドを利用しvalid_setデータセットの28番目を表示。
クラスター4に含まれている画像である事が分かる。
show_digit(train_set[0][28], 'This is a {}'.format(train_set[1][28]))
モデルがデプロイされて、動作していることも検証できた為完了。
作成した AWS リソースの削除
粛々と削除。特筆すべき事はなし。
おわりに
今回はSagrMakerを利用し、初めての機械学習に挑戦してみた。
機械学習、というと何となく障壁が高いイメージだったが、想像以上に簡単に使う事ができた。
各パブリッククラウドの最近の発表を見ていると、機械学習への敷居を下げようとしている印象を受ける。
(レベルが高い分析を行う場合は専門の機械学習エンジニアのスキルが必要となると思うが、)一定レベルの機械学習については、機械学習を専門とするエンジニア以外でもマネージドサービスを使ってスピード感を持って構築するスキルが求められていくのではないかと考えるので、機械学習についても学習を進めていきたい。
参考資料
Amazon SageMaker の開始方法
【初心者向け】Amazon SageMakerではじめる機械学習 #SageMaker
Amazon SageMaker 機械学習エンジニア向け体験ハンズオン