自己紹介
こんにちは、ソフトバンク株式会社2026年度入社のクシャル・チョットパッダエです。
これから諸々の取り組みと論文から得た知識を、Qiita上で共有したいと思います。
色々投稿していきますので、どうぞよろしくお願いします。
Sarashina-Embedding-v2-1B と次元削減の課題

2025年7月、SB Intuitionsは Sarashina-Embedding-v2-1B という埋め込みモデルを公開しました。
特徴を公式サイトより抜粋します。
「Sarashina-Embedding-v2-1B」は、日本語 LLM「Sarashina2.2-1B」をベースにした日本語テキスト埋め込みモデルです。本モデルはマルチステージの対照学習によって訓練されており、JMTEB(Japanese Massive Text Embedding Benchmark)の28データセット平均において、最高水準の平均スコア(2025年7月28日時点)を達成しています。文や文章を 1792 次元 の高密度ベクトル空間にマッピングし、意味的テキスト類似度、意味検索、パラフレーズマイニング、テキスト分類、クラスタリングなどのタスクに利用可能です。
Sarashina-Embedding-v2-1B は、JMTEB を基準とした評価において非常に高い性能を示しています。一方で、テキスト検索、特に RAG(Retrieval-Augmented Generation)のような検索ベースのユースケースにおいては、1792 次元という高次元な埋め込みベクトルが、計算コストやレイテンシの増加につながる可能性があります。
本記事では RAG そのものを対象とした評価は行わず、埋め込み表現の次元削減が意味表現に与える影響を分析するため、類似性評価(STS)タスクに焦点を当て、日本語ベンチマークである JSTS を用いて検証を行いました。
EmbeddingGemma は 768 次元、Sentence Transformers で広く用いられている MiniLM-L6-v2 は 384 次元であり、それらと比較すると Sarashina-Embedding-v2-1B は相対的に「重い」モデルであると言えます。(実は、EmbeddingGemmaの特徴の一つに、Matryoshkaを利用している点があります。)
低次元の埋め込みを直接学習する方法や、後処理として単純に次元削減を行う方法も考えられます。しかし、闇雲に次元を削除すると性能劣化のリスクもあります。
そこで本稿では、1792 次元の埋め込みベクトルを、一定の精度を維持しつつ、いかに圧縮できるかという次元削減の課題に取り組む。具体的には、Hugging Face に投稿されている🪆 Introduction to Matryoshka Embedding Modelsに記載された手順を参考に、Matryoshka 表現学習の適用を試みた。
導入
近年、Matryoshka 表現学習(MRL)が提案され、埋め込み次元の柔軟な削減と性能維持を両立する手法として注目を集めています。まずは全体像を説明すると、🪆Matryoshkaの特徴は、埋め込みベクターを縮小しても意味を保持することです。
通常、埋め込みを作成する場合、テキストをモデルに通すと、例えば1792次元の埋め込みが得られます。一度この埋め込みを作成すると、その次元を変更することはできません。
しかし、MRLでは埋め込みを作成する際に、128次元、256次元、768次元など、さまざまなサイズの埋め込みを生成できます。小さい埋め込みを作成することで、計算量やレイテンシを削減できるため、検索速度を向上させることができます。

希望する出力次元は (768, 512, 256, 128, 64) と仮定しましょう。この場合、訓練を行う際に、それぞれの次元で損失を加算して学習を行います。こうすることで、全体の情報が上位次元に効率的に反映され、最初の128次元でも埋め込みの主要な潜在的な表現を保持させることが可能です。
HuggingFaceのSarashina埋め込みモデルをロード
まず、loggingを整理し、対象にしているsarashina-embedding-v2-1bというSentenceTransformers埋め込みモデルを初期化していきます。
import logging
import sys
import traceback
from datetime import datetime
from datasets import load_dataset
from sentence_transformers import (
SentenceTransformer,
SentenceTransformerTrainer,
SentenceTransformerTrainingArguments,
losses,
)
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator, SequentialEvaluator, SimilarityFunction
model = SentenceTransformer("sbintuitions/sarashina-embedding-v2-1b")
logging.basicConfig(format="%(asctime)s - %(message)s", datefmt="%Y-%m-%d %H:%M:%S", level=logging.INFO)
batch_size = 16
num_train_epochs = 4
matryoshka_dims = [1792, 1280, 768, 256, 64] #対象次元
output_dir = f"output/jsts_sarashina-embedding-v2-1b-{datetime.now().strftime('%Y-%m-%d_%H-%M-%S')}"
logging.info(model)
SentenceTransformerTrainerの引数を設定
今回、MTEB の一部である JSTS(Japanese Semantic Textual Similarity Benchmark)を Trainer に入力として使用します。
注意点として、JSTS の score はすべて正の値で定義されているため、Trainer での学習には MultipleNegativesRankingLoss を使用します。CoSENTLoss は類似度スコアが [-1, 1] に正規化されていることを前提として設計されているため、JSTS には適していません。
このように、使用するデータセットのラベル分布と、損失関数が想定する入力形式が一致しているかを、事前に必ず確認する必要があります。
train_dataset = load_dataset("mteb/JSTS", split="train")
eval_dataset = load_dataset("mteb/JSTS", split="validation")
logging.info(train_dataset)
# 3. Define our training loss
# similarity score column (between 0 and 1)
inner_train_loss = losses.MultipleNegativesRankingLoss(model=model)
train_loss = losses.MatryoshkaLoss(model, loss=inner_train_loss, matryoshka_dims=matryoshka_dims)
# 4. Define an evaluator for use during training. This is useful to keep track of alongside the evaluation loss.
evaluators = []
for dim in matryoshka_dims:
evaluators.append(
EmbeddingSimilarityEvaluator(
sentences1=eval_dataset["sentence1"],
sentences2=eval_dataset["sentence2"],
scores=eval_dataset["score"],
name=f"sts-dev-{dim}",
truncate_dim=dim,
)
)
dev_evaluator = SequentialEvaluator(evaluators, main_score_function=lambda scores: scores[0])
# 5. Define the training arguments
args = SentenceTransformerTrainingArguments(
# Required parameter:
output_dir=output_dir,
# Optional training parameters:
num_train_epochs=num_train_epochs,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
warmup_ratio=0.1,
fp16=True,
bf16=False,
eval_strategy="steps",
eval_steps=100,
save_strategy="steps",
save_steps=100,
save_total_limit=2,
logging_steps=100,
report_to="wandb", # Weights & Biasesで学習推移を可視化
run_name="jsts-matryoshka",
)
# 訓練
trainer = SentenceTransformerTrainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss=train_loss,
evaluator=dev_evaluator,
)
trainer.train()
# 7. Evaluate the model performance on the STS Benchmark test dataset
test_dataset = load_dataset("mteb/JSTS", split="validation")
evaluators = []
for dim in matryoshka_dims:
evaluators.append(
EmbeddingSimilarityEvaluator(
sentences1=test_dataset["sentence1"],
sentences2=test_dataset["sentence2"],
scores=test_dataset["score"],
main_similarity=SimilarityFunction.COSINE,
name=f"sts-test-{dim}",
truncate_dim=dim,
)
)
test_evaluator = SequentialEvaluator(evaluators)
test_evaluator(model)
"""
{'sts-test-1792_pearson_cosine': 0.8087781664749797,
'sts-test-1792_spearman_cosine': 0.7435051743546024,
'sts-test-1280_pearson_cosine': 0.8078219018746986,
'sts-test-1280_spearman_cosine': 0.7442250390777712,
'sts-test-768_pearson_cosine': 0.8049404729865752,
'sts-test-768_spearman_cosine': 0.7423149875969083,
'sts-test-256_pearson_cosine': 0.8022025594051618,
'sts-test-256_spearman_cosine': 0.7410686789846747,
'sts-test-64_pearson_cosine': 0.7972183575514205,
'sts-test-64_spearman_cosine': 0.7388646166416691,
'sequential_score': 0.7388646166416691}
"""
比較実験として、Matryoshka Loss を用いない設定で再度学習を行い、同一条件下で JSTS による評価を実施しました。
評価
それでは、評価結果を確認します。
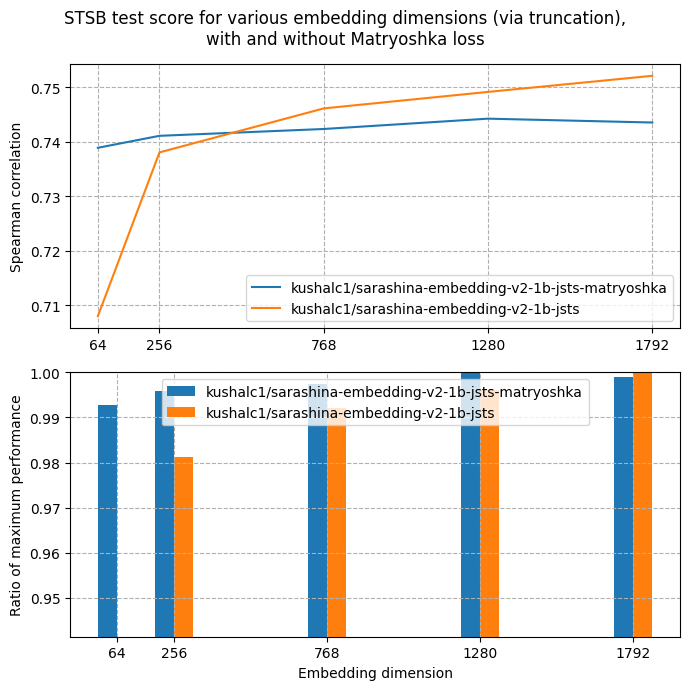
上図は、Matryoshka Loss を用いて学習した際の結果を示しています。比較のために、Matryoshka Loss を用いず、MultipleNegativesRankingLoss(inner_train_loss)のみで学習した結果とも併せて確認しています。
まず、Matryoshka Loss + MultipleNegativesRankingLoss を用いた場合と、MultipleNegativesRankingLoss のみを用いた場合の双方において、学習の比較的早い段階から損失曲線が明確に傾きを持ち、収束方向へ向かっていることが確認できます。特に Matryoshka Loss を併用した設定では、複数の埋め込み次元に対する損失を同時に最適化するため、初期段階から表現が安定しやすくなっていることが示唆されます。
次に、低次元の埋め込みに注目すると、Matryoshka Loss の効果は特に顕著です。64次元や256次元といった truncate された埋め込みにおいて性能差が大きく、Matryoshka Loss を用いたモデルの方が一貫して高い相関スコアを示しています。これは、埋め込みベクトルの先頭部分、すなわち最初の64次元や32次元といった低次元部分に対しても高い性能を発揮するよう、明示的に報酬付けが行われている設計と整合的です。
一方で、高次元の埋め込みでは、Matryoshka Loss を用いない場合の方が JSTS スコアの改善がやや速く進む傾向も観察されます。Matryoshka Loss は選択した複数の次元にまたがって損失を加算するため、例えば1280次元の性能を向上させる際にも、同時に低次元での性能改善が求められます。その結果、単一の次元のみを最適化する MultipleNegativesRankingLoss と比較すると、高次元単体での収束速度が相対的に緩やかになることは自然に説明できます。
モデルをHuggingFace上で共有いたしました。ご参照は以下のリンクからお願いいたします。
https://huggingface.co/kushalc1/sarashina-embedding-v2-1b-jsts-matryoshka
https://huggingface.co/kushalc1/sarashina-embedding-v2-1b-jsts