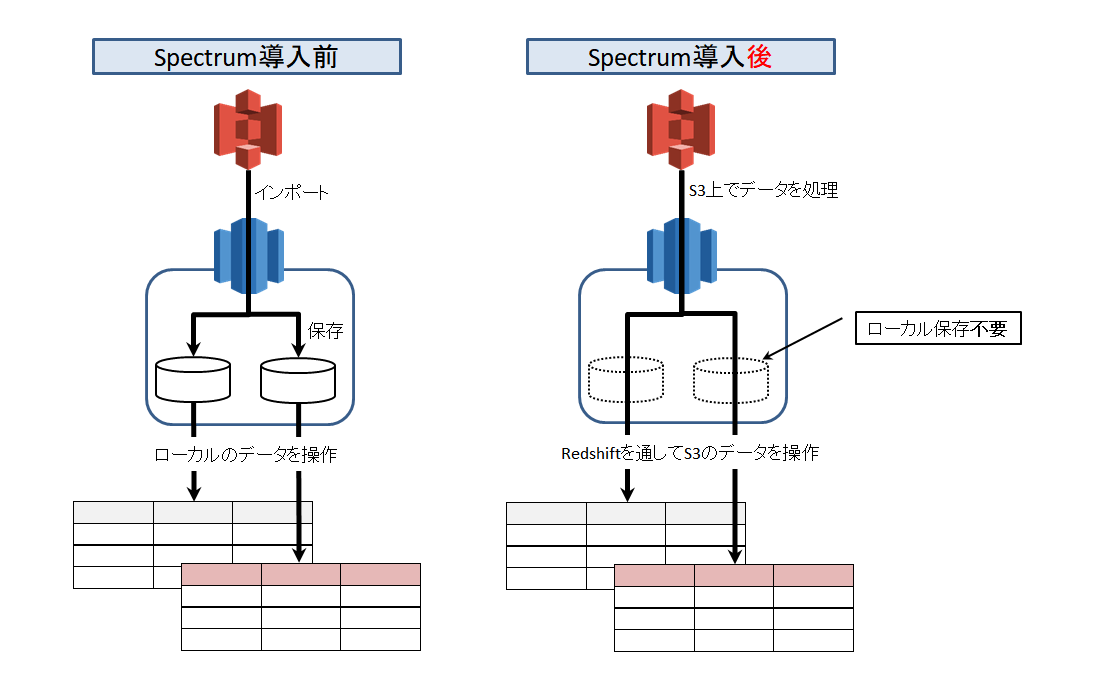
RedshiftSpectrumとは、
S3に保存したテキストファイルやParquetなどのカラムナフォーマットを
Redsihft上で直接読込処理できるサービス。
容量無限大のS3をデータレイクとして利用できるようになり、
Redshiftのストレージに拡張性が加わった。
ようは、**今までよりお安く大容量化できますよ!**ということ。
Spectrumへの置換手順
具体的にどのような手順で置換作業を進めればよいのか。
Spectrumのサービス開始から日が浅いため
ネット情報もあまりなく、Redshiftのドキュメントが頼り。。。
結構な回り道と試行錯誤があったが、
最終的にはSpectrum置換フレームワークを得られたと思う。
事前準備
- GlueもしくはAthenaのサービスを利用可能にしておく
※本件はGlueの場合を解説しています - Parquetを作成する手段を決めておく
※EMRか、GlueのETLか、PySparkか、PyArrowか…
※PyArrowでテキストファイルからParquetファイルを作成する方法 にて詳細記述 - Parquetの圧縮形式を決めておく
※gzipか、snappyか、非圧縮か - 外部テーブルのパーティション名を決めておく(テーブル列名と重複禁止)
- Create External Schema文で外部テーブルと外部スキーマを作成しておく
外部スキーマの作成.sql
CREATE EXTERNAL SCHEMA spectrum_schema_test
FROM
DATA CATALOG --DATA CATALOGと指定
DATABASE 'spectrum_db' --作成したい外部データベース名
IAM_ROLE 'arn:aws:iam::xxxxxx/xxxx-anars,arn:aws:iam::yyy/yyyyy-redshift' --※
CATALOG_ROLE 'arn:aws:iam::xxxxx/xxxxx-anars' --データカタログのアクセス許可に使用するIAM_ROLEを指定
CREATE EXTERNAL DATABASE IF NOT EXISTS
;
/*
※
ここでは、S3とGlueカタログ所有者が違う場合のIAM_ROLEの指定方法を記述。
アカウントyyyの管理するS3バケットに、アカウントxxxがSpectrumでデータを参照しに行く許可を得ている
*/
置換対象のテーブルを決める
Redshift内にあるテーブルのメンテナンスパターンは、大きく3パターン。
一番シンプルなのは、レコード追加のみのテーブル。
これは単純に置換が可能。
ただ、テーブル総入替とレコード更新のパターンは場合によっては
置換ができないケースもあると思われる。
| パターン | テーブル 更新形式 |
適用容易さ | 理由 |
|---|---|---|---|
| レコード追加 | INSERT or COPY |
〇 | 一番シンプル |
| テーブル総入替 | TRUNCATE & COPY |
△ | 入替行数多→恩恵無し 入替行数少→検討余地あり |
| レコード更新 | UPDATE & INSERT |
× | 変更発生個所のみ カラムナフォーマットの更新が必要 |
Spectrum化によるデータ確保量を見積もる
- 置換対象テーブルのデータ量を算出
- まずは小さいテーブルで検証
- 検証後、容量の大きいテーブルから進める
実装フロー
RedshiftSpectrumの導入に当たっては、次のフローで
進めるのがよさげです。
1. Spectrumに置換したいテーブルの定義書を確認
- CHAR列やVARCHAR列について、CR(CHR(10))とLF(CHR(13))が含まれていないか確認。
含まれている場合は、空文字に置換する
2. 区切りたいパーティション毎にRedshiftからS3へUNLOADする
- たとえば日付でパーティション区切りたい場合、日付ごとにUNLOADを実行
- 出力先は、s3://spectrum/org/2015-01-01/000.gz など…。
※ディレクトリを都度切るかはこの後の実装処理次第
3. UNLOADしたファイルをPySparkやPyArrowでParquet形式に変換
- 変換後、Spectrum参照用のディレクトリへ配置する。
※ローカルで処理する場合、変換対象ファイルをDL→Parquet変換→S3へUP - 日付でパーティション区切りの場合、次のようにディレクトリを切る。
※太字の部分でパーティションを表すが、この後作成する外部テーブルの列名と重複させないこと。 - s3://spectrum/parquet/part_date=2015-01-01/000.parquet
- s3://spectrum/parquet/part_date=2015-01-02/000.parquet
- s3://spectrum/parquet/part_date=2015-01-03/000.parquet
4. 外部テーブルを作成、ALTER TABLE でパーティションを区切る
- 構文は後述(◆)を参照
- Glueの機能で区切ってもよい
- パーティションを区切った数と、S3で作成したパーティション数が一致するか確認。
テーブルのパーティション数はSELECT * FROM SVV_EXTERNAL_PARTITIONS;で確認可能。
5. 元のテーブルと外部テーブルを比較し、同一内容か確認する。
- 違ってた場合、下記のポイントで検討をつける
- UNLOAD時(例:改行の置換漏れ)
- Parquet変換時(例:データ型相違、Sparkのタイムゾーンで変換時に時刻ずれ発生)
- 外部テーブルからの読込時(例:データ型相違)
6. 遅延バインディングで外部テーブルの遅延VIEWを作成する
CREATE VIEW ビュー名 AS SELECT * FROM 外部スキーマ.外部テーブル WITH NO SCHEMA BINDING;- 遅延VIEWを作成しないと、BIツールやSQLクライアントで外部テーブルを認識できないケースあり
7. Spectrumとローカルのパフォーマンスを比較
- WHEREとJOINの性能検証。結果次第では下記2パターン
- Parquetの圧縮形式見直し検討(snappy、もしくは非圧縮)
- パーティションの見直し検討
- 性能検証で問題ないと判断後、ローカルのデータをDELETE
- 適宜タイミングを見計らって日次バッチ処理等に移管
(◆)外部テーブル作成構文
◆外部テーブル作成構文.sql
/* ### Superユーザーじゃないと作成不可 ### */
CREATE EXTERNAL TABLE 外部スキーマ.テーブル名(
date_time date
, id int
)
PARTITIONED BY ----- S3のディレクトリ構造でパーティション化する
(part_date DATE) ----- パーティション名:part_date DATE型
STORED AS parquet ----- 元データ保存形式:parquet
LOCATION 's3://spectrum/parquet/' ----元データ保存ディレクトリorファイル
;
--ALTER TABLE でテーブルにパーティションを認識させる
ALTER TABLE 外部スキーマ.外部テーブル
ADD PARTITION (part_date='2015-01-01')
LOCATION 's3://spectrum/parquet/part_date=2015-01-01/'
;
注意点
- 外部テーブルの作成は、スーパーユーザーのみ可能
- 一般ユーザーは参照のみ
- 文字列置換について
- 改行コード(CR,LF)はParquet変換時にエラーになるため、置換を忘れずに
- Parquet形式変換時、空文字はNULLに置換される
- 遅延バインディングについて
- ビューコメントは可能
- ただし、カラムコメントは付与できない
※VIEWの対象に実テーブルを挟んでもダメ
補足
【Parquet形式を選んだ理由】
1. Parquet形式のほうがドキュメント多く、学習コストが低かった
2. 検証段階でORC形式への変換が上手くいかなかった
【外部テーブルについて】
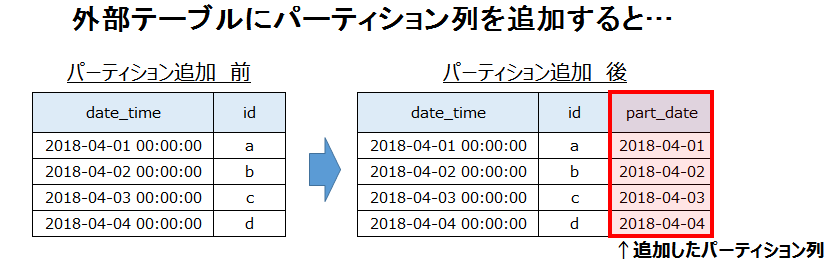
- ALTER TABLE でパーティションを切ると、外部テーブルにパーティション列が追加される(下図参照)
- あくまでも列の1つなので、
SELECT パーティション列名 FROM 外部テーブル;でデータ抽出も可能 - 追加されたパーティション列は、遅延ビュー化すると列名候補にあがってくる(SQLクライアントに依存)