NMF(Non-negative Matrix Factorization)を使用したレコメンドをなんとなくわかった気になったので書き留めてみる。
ユーザ毎のアイテムに対する評価を持っている状況でのレコメンドを考える。
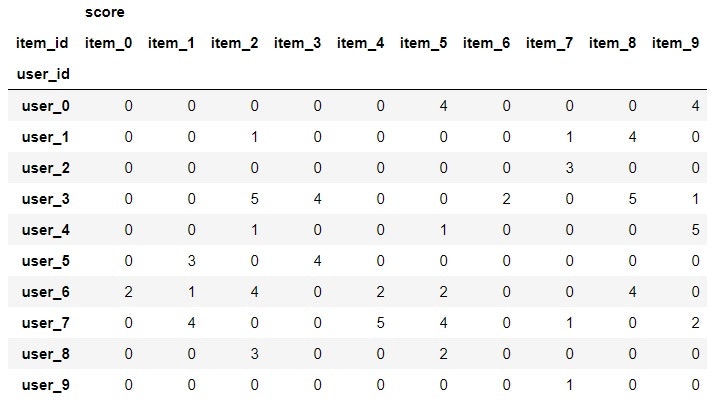
使用するデータは以下。
各アイテムに対する各ユーザの評価値(1-5)を持っている。
0は未評価の項目。
df
NMFを使って未評価の部分を補完した行列を作る。
ただし、通常のNMFはscikit-learnにも実装されているが、欠損値を含む場合には対応していないらしい。
https://github.com/scikit-learn/scikit-learn/issues/8447
欠損値を含むNMFについてはこちらが詳しかった。
def update(Y, W, H, M):
W = W * np.dot(Y * M, H.T) / np.dot(np.dot(W, H) * M, H.T)
H = H * np.dot(W.T, Y * M) / np.dot(W.T, np.dot(W, H) * M)
return W, H
この更新式を適当な回数繰り返し、低次元の$W$, $H$によって$M$に近似させる。
k = 5
M = df.values
n, m = M.shape
W = np.random.rand(n, k)
H = np.random.rand(k, m)
mask_M = (M > 0)
# W,Hの更新を適当な回数繰り返す
# W @ H が徐々に M に近づいていく
for _ in range(100):
W, H = update(M, W, H, mask_M)
pd.DataFrame(W @ H, index=users, columns=items)
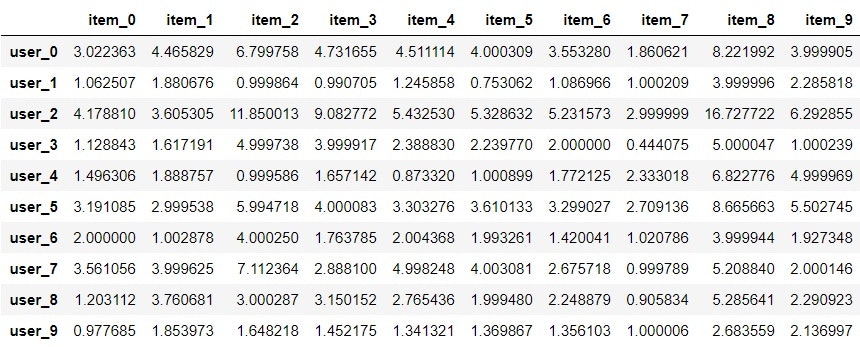
評価のあった項目は元の値に近くなっており、未評価の項目にも値が入っている。
例えばuser_0は未評価のアイテムのうち最も評価値の高いitem_8をレコメンドしよう、となる。