※2018/7/4 追記 Kubernetesのドキュメントにkubeadmを使ったHA clusterの構築方法が追加されましたようですので、できるだけ公式の方法に従った構築をしましょう
今年はKubernetesはDockerコンテナのオーケストレーションツールのデファクトスタンダードの立場を獲得したといえるでしょう。これから利用者はますます増えるはずです。この記事をかいているとき、ちょうど"KubeCon + CloudNativeCon North America 2017"が開催されていてどんな発表が出るのか楽しみです。
とはいえ、自分のところでもKubernetesクラスタを運用しているもののアップデートのたびにだいたい困ったことが起こるのでまだまだ自前で運用するにはつらいツールです。(つらみはチャットに吐き出しています)
それでも、Kubernetesが流行ってきているので手元の数台のサーバを使ってクラスタを構築して触ってみたい、できればマスタが故障してもクラスタの機能を継続できるしたいという方にこの記事が参考になればと思います。
ちなみに、現時点の最新版のkubeadm 1.8ではMasterを冗長化したクラスタの構築自動化はまだ実現できておらずkubernetes/kubeadm #216で開発中です。
言い訳
ここで紹介する方法は最新のv1.8.4ではうまくいきませんでした。検証してみたかったのですが、時間がなかったため同じ方法で構築した本番系と同じv1.7.5を使うことにします。
はじめに全体構成の確認
High-Availability Masterの構成

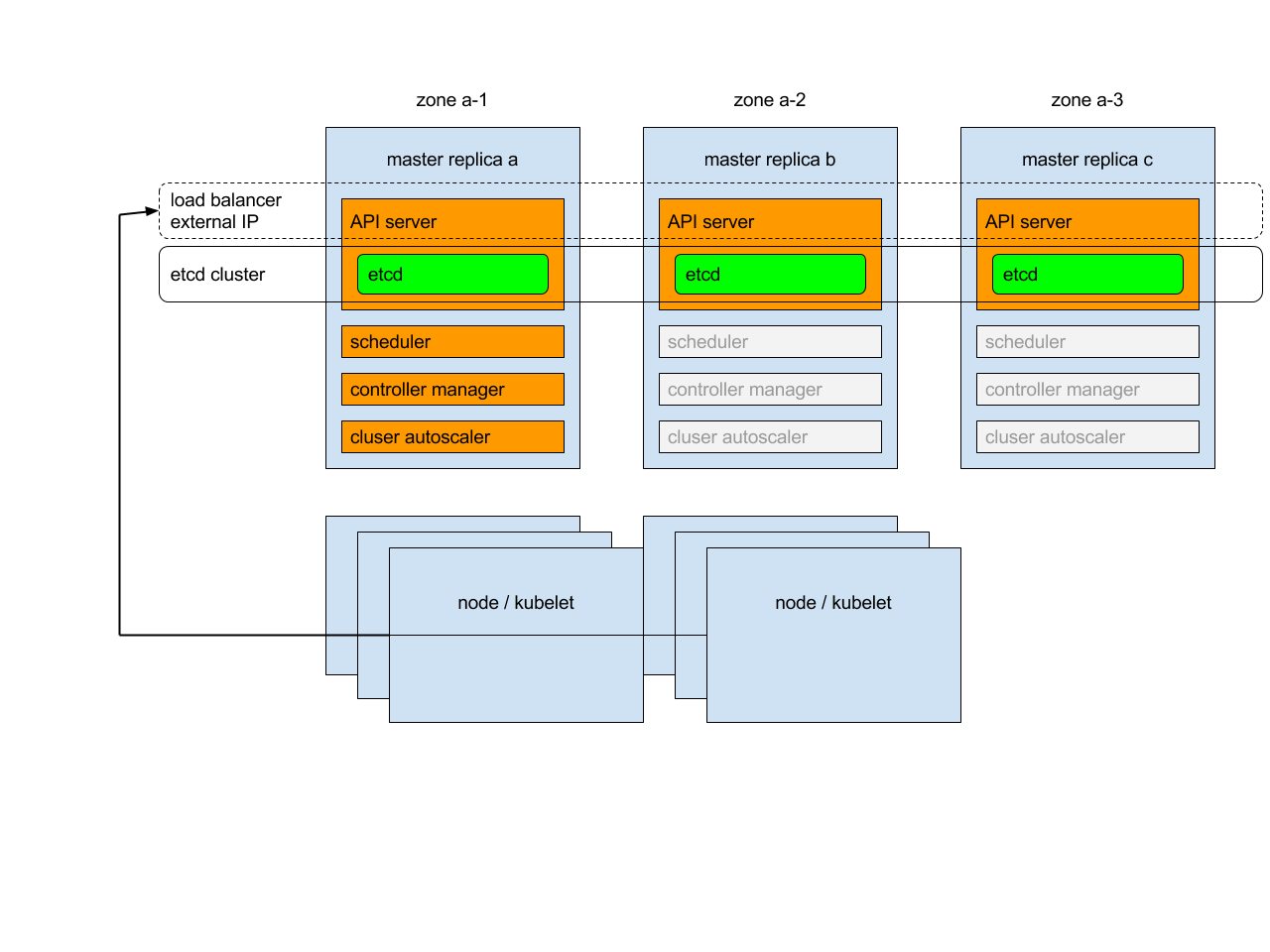
公式ドキュメントから引用してきた図です。
まとめると以下のようになります。
- Masterはアクティブ/アクティブ構成
- Nodeからのリクエストはロードバランサが受け付けて複数のMasterに振り分け
- Master同士はetcdクラスタに情報を保存
kubeadmのオプションを使おう
kubeadmは人手でやると面倒な証明書の作成やセキュリティのための設定をしてくれて便利なのですが、Masterの情報を保存するetcdはkubeadm initを実行したホスト上で単体構成で作られます。Masterとetcdは同じホストで動いているためetcdクラスタを作り冗長化しないとホストがダウンした途端にサービスの継続ができなくなります。
そこで、etcdクラスタをkubeadmの機能を使わず自分で構築します。kubeadm initは実行時のオプションで既存のetcdを利用することができるので、etcdクラスタを自分で先に構築して利用することにします。
また、先ほど書いたkubeadmが自動で作ってくれる証明書もkubeadm initを実行したホストのためのものです。クライアントが実行するkubectlはkubeadm initを実行すると生成されるadmin.confをコピーした~/.kube/config中の設定(contexts)を使ってMasterと通信しますが、この通信相手はロードバランサになるはずなので、admin.confにはロードバランサとの通信方法を埋め込んでもらわなければなりません。これもkubeadm initのオプションで指定します。
構成
ロードバランサ1台、Master3台、クライアント1台の計5台の構成を試します。全てCentOS 7.3です。
| ホスト名 | IPアドレス | 役割 | ホスト上のプロセス | コンテナプロセス |
|---|---|---|---|---|
| lb | 192.168.1.9 | ロードバランサ | Nginx | なし |
| server1 | 192.168.1.10 | Master1 | kubelet, etcd | apiserver, controller-manager, scheduler, weave, proxy |
| server2 | 192.168.1.11 | Master2 | kubelet, etcd | apiserver, controller-manager, scheduler, weave, proxy |
| server3 | 192.168.1.12 | Master3 | kubelet, etcd | apiserver, controller-manager, scheduler, weave, proxy |
| server4 | 192.168.1.13 | Node | kubelet | weave, proxy |
| server5 | 192.168.1.14 | Client | kubectl | なし |
server1〜3の上でアクティブ/アクティブ構成のMasterを構築します。Nginxの障害には目をつぶります。
構築
ロードバランサの構築
以下の設定でnginxを構築します。
upstream test_api_server {
server 192.168.1.10:6440;
server 192.168.1.11:6440;
server 192.168.1.12:6440;
}
server {
error_log /var/log/nginx/test-stream.log info;
listen 6440;
proxy_pass test_api_server;
}
etcdクラスタ構築
server1, server2, server3でetcdクラスタを構築します。
etcdクラスタの構築はstatic方式、etcd Discovery方式、DNS Discovery方式があります。サーバの役割が固定であること、外部サービスをあまり使いたくないことから今回はstatic方式を取ることにしました。
構築方法はこちらをごらんください。
パッケージインストール
公式ドキュメントにOSごとのインストール方法が書かれているので、CentOS向けの方法をコピーして実行します。
SELinuxを無効化してkubeadm, kubelet, kubectlをインストールしています。
ドキュメントでは最後にkubeletデーモンを起動しているのですが、条件によってはトラブルが起こるため意図的に消しています。詳しくはあとで出てきます。
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
setenforce 0
yum install -y kubelet-1.7.5 kubeadm-1.7.5 kubectl-1.7.5
続いて、以下の二つを確認して必要であればkubeletの実行オプションを定義している/etc/systemd/system/kubelet.service.d/10-kubeadm.confを変更します。
- インストールされているDockerはリソースの分割に何を使っているか
- 確認コマンド:
docker info|grep Cgroup - kubeletはsystemdを使っています。もしもインストールされているDockerがcgroupfsを使っている場合、それに合わせるために10-kubeadm.confの中身を
--cgroup-driver=cgroupfsと書き換えます。 - 逆に、DockerのCgroup Driverをsystemdに変更してもいいです。
- 確認コマンド:
- ホストにswap領域があるか、kubeletはv1.8以降か。
- 確認コマンド:
swapon -s - v1.8からkubeletはswap領域が設定されていると起動に失敗するようになりました。
- swapを無効化するか、swapがあっても無視するようにkubeletの実行オプションに
--fail-swap-on=falseを追記します。
- 確認コマンド:
これは全てのMasterで実施します。
1つめのMaster構築
接続するetcdクラスタを指定する、ロードバランサが動くホストのための証明書を作る二つのオプションとKubernetes v1.7.5を使うためのオプションを指定してkubeadm initを実行します。オプションの内容はあらかじめkubeadm.yamlとして用意しておきます。
これまでと違い、この作業はMasterのうち1箇所だけで実行します。
今回はserver1で実行します。
apiVersion: kubeadm.k8s.io/v1alpha1
kind: MasterConfiguration
kubernetesVersion: v1.7.5
api:
advertiseAddress: 192.168.1.9 # ロードバランサのIPアドレス
bindPort: 6440
etcd:
endpoints:
- http://127.0.0.1:2379
apiserverのデフォルトのポート番号は6443ですが、このロードバランサは本番環境とテスト環境の両方を兼ねており、6443は本番環境用に使っているためあえて違うポートを使っています。
# server1でkubeletを起動
[root@server1 ~]# systemctl start kubelet.service
# kubeadm initを実行
# kubeletでswapを無視する設定をしていてもkubeadmがWarningをはいてとまるため、--skip-preflight-checksオプションを指定
[root@server1 ~]# kubeadm init --skip-preflight-checks --config ./kubeadm.yaml
(略)
Your Kubernetes master has initialized successfully!
To start using your cluster, you need to run (as a regular user):
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
http://kubernetes.io/docs/admin/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join --token c09462.90821166b9dcf3d1 192.168.1.9:6440
しばらく待つと、apiserverやschedulerなどKubernetesのMasterに必要なプロセスがPodして立ち上がり、NodeがKubernetesクラスタに参加するために必要なトークンが出力されます。このトークンはNodeを登録するときに使います。
まだMasterの機能が完成していないKubernetesクラスタにPodができる理由は、kubeletにはMasterを介さず起動するStatic Podという特別なPodをたてる機能を使っているためです。kubeletがStatic Podを作るために監視している/etc/kubernetes/manifestsディレクトリにkubeadmがapiserverやschedulerのマニフェストを作成し、kubeletがそれを検知してStatic Podとして立ち上げます。
続いて、生成されたadmin.confをkubectlの設定ファイルの置き場所にコピーしてkubectlを実行可能にします。
[root@server1 ~]# mkdir -p $HOME/.kube
[root@server1 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@server1 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
最後に、Kubernetesの仮想ネットワークを作ります。ここではWeave Netを使っています。
[root@server1 ~]# kubectl apply -f https://git.io/weave-kube-1.6
serviceaccount "weave-net" created
clusterrole "weave-net" created
clusterrolebinding "weave-net" created
role "weave-net-kube-peer" created
rolebinding "weave-net-kube-peer" created
daemonset "weave-net" created
2つめ以降のMasterの構築
Masterに必要な設定は1つめのMasterでkubeadm initを実行したときに完了しています。あとは、それらの設定を残りのMasterで共有すればいいだけです。
server2, server3でkubeletを動かし、server1で作られたStatic Pod用のマニフェストと証明書をコピーすることで3つのMasterの状態をそろえることにします。
一点注意が必要なのは、コピー前にserver1のapiserverのマニフェストである/etc/kubernetes/manifests/kube-apiserver.yaml中の--admission-controlオプションから「NodeRestriction」を削除することです。kubeletはマニフェストが書き換えられたことを検知して自動的にapiserverのコンテナを再起動します。
apiserverはいくつかのセキュリティポリシーを持っているのですが「NodeRestriction」はそのNodeの設定を変更できるのはそのNodeの操作権限を持つユーザだけというポリシーです。kubeadm initはserver1の操作権限を持つユーザを作ってくれてはいますが、server2, server3の操作権限を持つユーザを作ってくれていません。権限を含めて同じMasterを作る上でこのポリシーは邪魔になります。
まず、server2, server3でkubeletを動かします。
[root@server2 ~]# systemctl start kubelet.service
[root@server3 ~]# systemctl start kubelet.service
その後、server1の/etc/kubernetesディレクトリ一式をserver2, server3にコピーします。
[root@server1 ~]# scp -rp /etc/kubernetes/* server2:/etc/kubernetes/
[root@server1 ~]# scp -rp /etc/kubernetes/* server3:/etc/kubernetes/
仮想ネットワークを動かすためのWeave Netは/etc/kubernetes/manifestsに含まれていませんが、全てのサーバで動くDaemonSetsとして実行されているため自動的にserver2, server3でも立ち上がります。
しばらく待つと3台のMasterがそろいます。
[root@server1 ~]# kubectl get nodes
NAME STATUS AGE VERSION
server1 Ready 6m v1.7.5
server2 Ready 2m v1.7.5
server3 Ready 1m v1.7.5
最後に、各Masterに通常のPodが作られないようにtaintを設定します。
[root@server1 ~]# kubectl taint nodes server1 node-role.kubernetes.io/master="":NoSchedule
node "server1" tainted
[root@server1 ~]# kubectl taint nodes server2 node-role.kubernetes.io/master="":NoSchedule
node "server2" tainted
[root@server1 ~]# kubectl taint nodes server3 node-role.kubernetes.io/master="":NoSchedule
node "server3" tainted
Node構築
kubadm initを実行したときに最後に出力されたとおりに叩きます。Nodeからはロードバランサが動いているホストがKubernetesのMasterにみえます。
[root@server4 ~]# kubeadm join --token c09462.90821166b9dcf3d1 192.168.1.9:6440
(略)
Node join complete:
* Certificate signing request sent to master and response
received.
* Kubelet informed of new secure connection details.
Run 'kubectl get nodes' on the master to see this machine join.
クライアントの設定
クライアントからkubectlでapiserverと通信できるようにします。
server5にkubectlの設定ファイルの置き場所を作り、server1からcontextsを含むadmin.confをコピーします。
[root@server5 ~]# mkdir ~/.kube
[root@server1 ~]# scp /etc/kubernetes/admin.conf server5:~/.kube/config
Masterの障害時に動作確認
Masterの停止
Masterを一台シャットダウンしても新しいコンテナを作ることができるか確認します。ここではserver3をダウンさせましょう。
[root@server3 ~]# shutdown -h now
障害対応
ここで、何らかのモニタリングによってserver3が死んだとアラートがあがったとします。障害対応としてKubernetesクラスタからserver3を削除します。
# server3にこれ以上コンテナを割り当てられないようにした上で、動いていたユーザのPodを他のNodeで再実行させる。実際はMasterにはユーザのPodは割り当てられないため何も起こらない。
[root@server1 ~]# kubectl drain --ignore-daemonsets --force server3
node "server3" cordoned
WARNING: Deleting pods not managed by ReplicationController, ReplicaSet, Job, DaemonSet or StatefulSet: kube-apiserver-server3, kube-controller-manager-server3, kube-scheduler-server3; Ignoring DaemonSet-managed pods: kube-proxy-jvjs5, weave-net-x68br
node "server3" drained
# 確認
[root@server1 ~]# kubectl get nodes
NAME STATUS AGE VERSION
server4 Ready 24m v1.7.5
server1 Ready 34m v1.7.5
server2 Ready 30m v1.7.5
server3 NotReady,SchedulingDisabled 29m v1.7.5
# server3を削除
[root@server1 ~]# kubectl delete nodes server3
node "server3" deleted
Masterの冗長性の動作確認
次に、Masterが1台ダウンしてもクライアントからNginxのDeploymentを作れることを確認します。
まず、マニフェストを作った後、Deploymentsを作ります。
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
# Deploymentsの作成
[root@server5 ~]# kubectl create -f nginx.yml
deployment "nginx-deployment" created
# Deploymentができたかを確認
[root@server5 ~]# kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 1 1 1 1 1m
ということで、Masterが故障しても新しいDeploymentsを作ることができました。