想定している状況
- スプレッドシートのデータをGASで取得して処理したい
- ただしフォーマットが確定していない
- あとからカラムの追加や移動があるかもしれない
A「1列目ID、2列目TYPE、3列目DATE…やな!」
B「ごめん、IDのとなりにNAMEが必要やったわ!」
A「できたで。1列目ID、2列目NAME、3列目TYPE、4列目DATE…やな!」
B「先日のNAMEやけどな、FAMILY NAMEとLAST NAMEに分けたいねん!」
A「…。」
列番号指定でスクリプトを動かすのはやめて、オブジェクト化してカラム名で扱いましょう!
console.log(array[1]) //なにが入っているかわからない、列が移動すると困る
console.log(object["name"]) //わかる
目次
ダミーデータ
二次元配列を取得する
オブジェクトにする
MAPオブジェクトにする
おまけ…Python(gspread)の場合
ダミーデータ
ダミーデータを用意しました。1行目がヘッダー、2行目以降にレコードが続きます。

二次元配列
まずはgetValues();で二次元配列を取得します。
const id = "XXXXXXXXXXXXXXXX";
const ss = SpreadsheetApp.openById(id);
const sheet = ss.getSheetByName('DUMMY_personal_infomation');
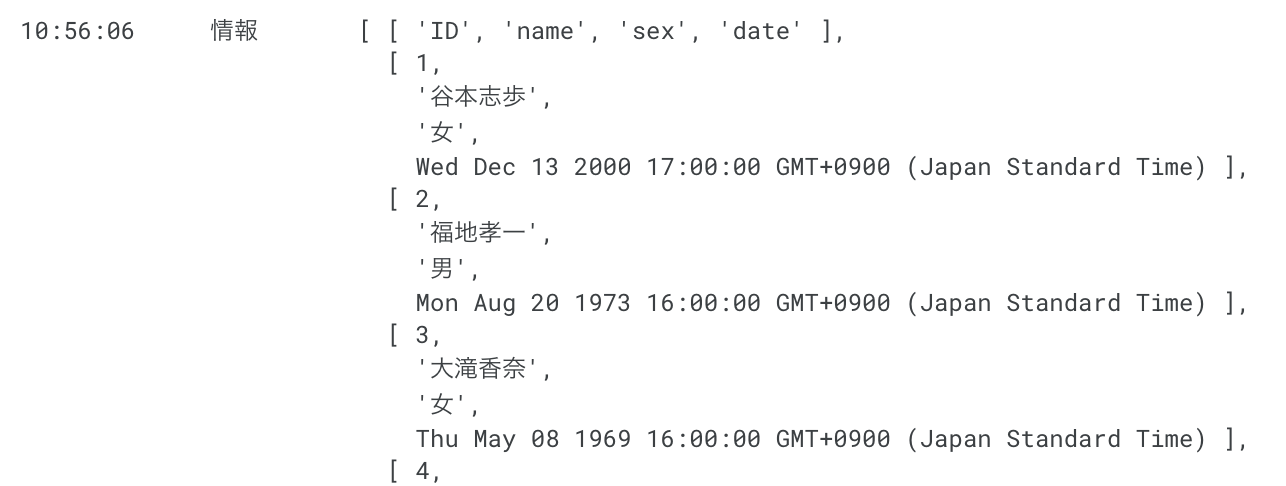
// 二次元配列を取得する
const values = sheet.getDataRange().getValues();
console.log(values)
オブジェクト
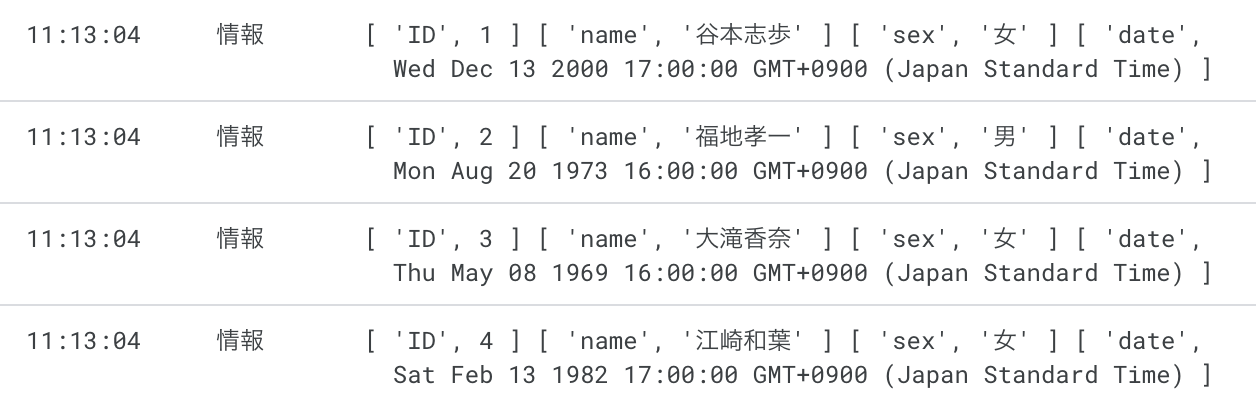
二次元配列をオブジェクトにしてみましょう。
// 二次元配列を取得する
const values = sheet.getDataRange().getValues();
// オブジェクトにする
const [header, ...records] = values; //1行目がヘッダー、以降がレコード
const objects = records.map(
record => record.reduce((acc, value, index) => {
acc[header[index]] = value;
return acc;
}, {})
);
console.log(objects)

- 二次元配列のvalues[0]がヘッダー、[1]以降がレコードにあたります。
-
values.shift();で最初の要素を削除してもよいですが、…スプレッド構文でも最初の要素(header)と、以降の要素(records)に分けられます。 - あとは行数recordsの数だけループして処理していけばよいでしょう。
- reduceのaccは「直前の処理で返された値」を持つので、初期値「 {}」に対して順々にプロパティを追加していきます。
なお、プロパティの追加にスプレッド構文を使うとさらに短くなります。
const values = sheet.getDataRange().getValues();
const [header, ...records] = values;
const objects = records.map(
record => record.reduce((acc, value, index) => ({...acc, [header[index]]:value}), {})
);
MAPオブジェクト
二次元配列をMAPオブジェクトにしましょう。
// 二次元配列を取得する
const values = sheet.getDataRange().getValues();
// MAPオブジェクトにする
const [header, ...records] = values;
const maps = records.map(
record => record.reduce((acc, value, index) => acc.set(header[index], value), new Map())
);
for (m of maps) {
console.log(...m);
}
- Mapオブジェクトもオブジェクトと同様にキーと値のペアを保持します。
- Arrayで使用されるMapメソッドとは異なるため注意。ややこしいですね。
- またMapオブジェクトは、要素を追加したり取得したりするメソッドが用意されています。
-
new Map();で空のMAPオブジェクトを生成して、初期値としてreduceに渡します。 -
set(key, value);で要素を追加します。
オブジェクトでスプレッド構文を駆使するより、専用メソッドのあるMAPオブジェクトの方が処理がわかりやすい…でしょうか?
おまけ…Python
Pythonの辞書型で取得するには、gspreadライブラリを使用してworksheet.get_all_records()の1行でよい…
from google.colab import auth
from google.auth import default
import gspread
from pprint import pprint #Dictを整形してきれいに出力できる
# 認証
auth.authenticate_user()
creds, _ = default()
gc = gspread.authorize(creds)
workbook = gc.open_by_key('XXXXXXXXXXXXXXXX')
worksheet = workbook.worksheet('DUMMY_personal_infomation')
# worksheetの全データをdictで取得
recordsDict = worksheet.get_all_records()
pprint(recordsDict)
