目次
- プロンプト5大原則
- AIエージェントとは
- LangChainとLangGraphとは
1. プロンプト5大原則
当勉強会を通じて、最終的に「LLMになんとなく指示出しをする」というレベルから脱却することを目的とします。
まずは基本の5大原則から見てみましょう。
1. 方向性を示す
5大原則全般に言えることですが、基本的に「入力」から「思考」に至り、「出力」するまでのルートを決めてあげることが安定したアウトプットを得るための原則になります。
この「方向性を示す」では以下のような例があります。
- ロールプロンプティング
- プリウォーミング
ロールプロンプティング
ロールとは「役割」を示す言葉です。文字通り、LLMに前提条件としてどういう立場で回答させるかを設定させます。
この役割設定をしてあげるだけでLLMもそのような立場からの回答を生成するので精度の向上に役立ちます。
どういうロールを設定するかは、使う場面や欲しい回答によって切り替えてみると良いと思います。
例:あなたはイーロンマスクのような斬新な思考を持ち合わせています。
:あなたはQAエンジニアです。
:あなたはxxxというアプリケーションのプロダクトリーダーです。
プリウォーミング / 内部検索
これは、生成AIにアウトプットさせるとき従わせたい基本ルールや、ある程度のベストプラクティスなどを渡しておくことです。エンジニアで言えば、プロダクトにおけるアーキテクチャやメインのドメイン知識なども事前に提示しておくと良いと思います。
あらかじめあると良いものの、なければそれも問いかけつつプロンプトの作成をすることでも多少の効果があります。
マーケティング業界の専門家の立場として、新商品の命名ルールについて要点を教えてください。
2. 出力形式を指定する
「アウトプットの形式が決まった型に従っている」ということはAIにとってもアウトプットが安定しやすくなる要因になり得ます。
たとえば、jsonで固定する場合も、単にプロンプトで「jsonで出力して」と問い合わせてもjson以外に「以下が回答となります」や「以上がアウトプットの結果です」のようなjson以外のノイズになるテキストも出力されがちです。
これは後述する「例示をする」である程度解決しますが、最近は生成AIの中にも出力形式の指定ができるものも増えてきています。
OpenAI
Claude
Gemini
3. 例示をする
LLMの業界では、例示することを「ショット」と言ったりします。
- ゼロショット:例示なし
- ワンショット:1つだけ例示
- フューショット:複数の例示
アウトプットの参考例・フォーマットの指定をすることは精度を高めることに対してとても有効です。これを拡張したものがファインチューニングのようなものになるのですが、やはり手間がかかるので一旦フューショットのプロンプトを利用してどれくらい有効かを見るのが良いでしょう。
| タスク | 指標 | Zero-shot | One-shot | Few-shot |
|---|---|---|---|---|
| TriviaQA (知識問題) | 正解率 | 64.3% | 68.0% | 71.2% |
| LAMBADA (文脈予測) | 正解率 | 76.2% | 72.5% | 86.4% |
| HellaSwag (常識推論) | 正解率 | 78.9% | 78.1% | 79.3% |
Language Models are Few-Shot Learners
これは、モデルやデータ量が多ければ多いほどゼロショットとフューショットの差は顕著になります。
そのほかにも、出力形式にjsonを指定したい場合などにも有効です。
以下フォーマットのJSONで返答してください。
JSONフォーマット:
{"activityDate":"活動日(yyyy-MM-dd形式)","account":"顧客企業名","subject":"営業活動のタイトル","detail":"営業活動の詳細"}
最終応答は、"{"で始まり"}"で終わる、または"["で始まり"]"で終わるJSONのみを出力し、JSON以外の文字は一切応答に含めないでください。
JSON:
また、少し面白いですが末尾にこのような一文を入れるだけでかなりの確率でjsonで出力できるという結果もあるようです。
Assistant: {
4. 品質を評価する
LLMのアウトプットに対して、品質評価をしてフィードバックを行うことも生成AIを用いた開発には重要です。
「評価」とはいろいろな指標があるかもしれませんが、定番はベンチマーク指標でしょう。
Model Evaluation – Approach, Methodology & Results
Gemini 3 Pro
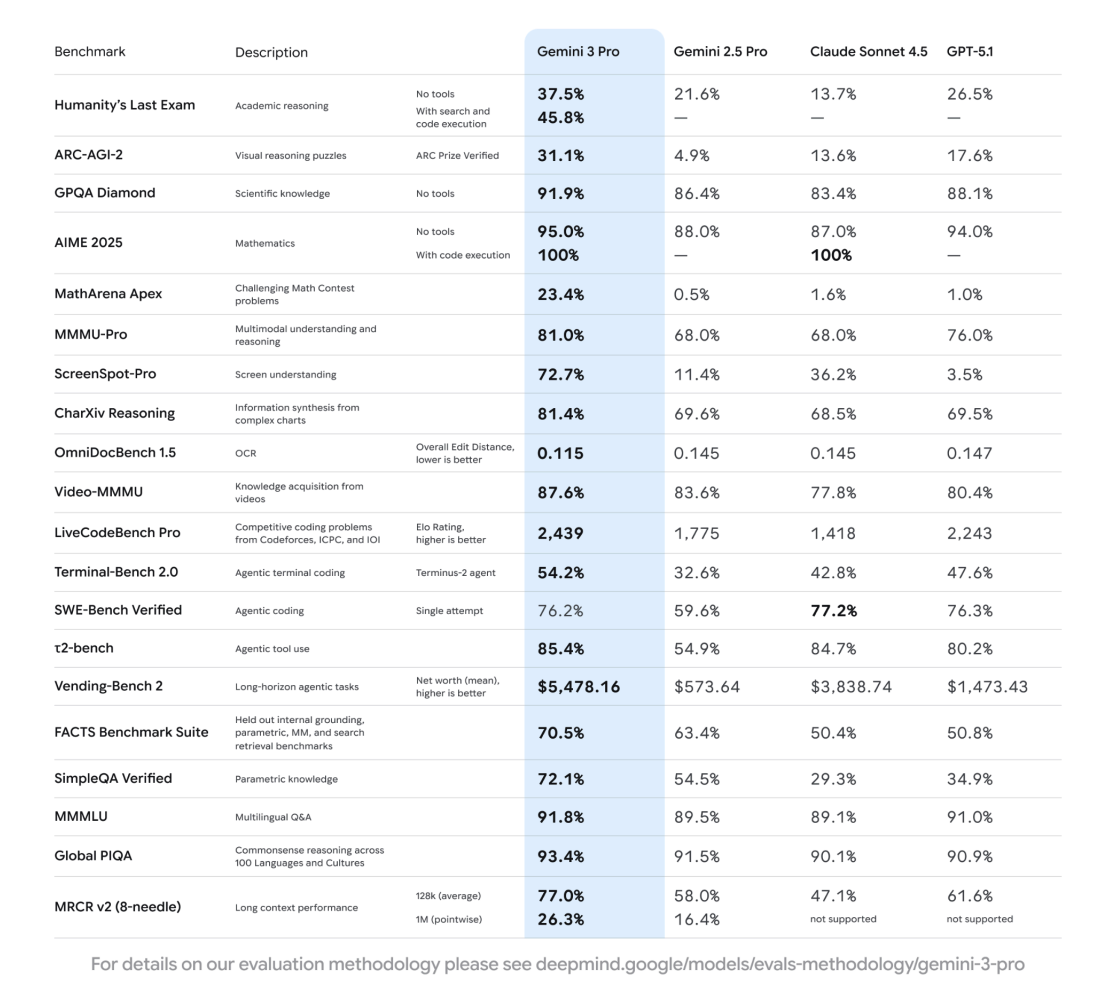
| ベンチマーク | 説明 | 条件 | Gemini 3 Pro | Gemini 2.5 Pro | Claude Sonnet 4.5 | GPT-5.1 |
|---|---|---|---|---|---|---|
| Humanity's Last Exam | 学術的推論 | ツールなし | 37.5% | 21.6% | 13.7% | 26.5% |
| 検索とコード実行あり | 45.8% | — | — | — | ||
| ARC-AGI-2 | 視覚的推論パズル | ARC Prize認証済み | 31.1% | 4.9% | 13.6% | 17.6% |
| GPQA Diamond | 科学知識 | ツールなし | 91.9% | 86.4% | 83.4% | 88.1% |
| AIME 2025 | 数学 | ツールなし | 95.0% | 88.0% | 87.0% | 94.0% |
| コード実行あり | 100% | — | 100% | — | ||
| MathArena Apex | 難解な数学問題 | 23.4% | 0.5% | 1.6% | 1.0% | |
| MMMU-Pro | マルチモーダル理解と推論 | 81.0% | 68.0% | 68.0% | 76.0% | |
| ScreenSpot-Pro | 画面理解 | 72.7% | 11.4% | 36.2% | 3.5% | |
| CharXiv Reasoning | 複雑なチャートからの情報統合 | 81.4% | 69.6% | 68.5% | 69.5% | |
| OmniDocBench 1.5 | OCR | 全体編集距離(低いほど良い) | 0.115 | 0.145 | 0.145 | 0.147 |
| Video-MMMU | 動画からの知識獲得 | 87.6% | 83.6% | 77.8% | 80.4% | |
| LiveCodeBench Pro | Codeforces、ICPC、IOIの競技プログラミング問題 | Eloレーティング(高いほど良い) | 2,439 | 1,775 | 1,418 | 2,243 |
| Terminal-Bench 2.0 | エージェント型ターミナルコーディング | Terminus-2エージェント | 54.2% | 32.6% | 42.8% | 47.6% |
| SWE-Bench Verified | エージェント型コーディング | シングル試行 | 76.2% | 59.6% | 77.2% | 76.3% |
| t2-bench | エージェント型ツール使用 | 85.4% | 54.9% | 84.7% | 80.2% | |
| Vending-Bench 2 | 長期的なエージェントタスク | 純利益(平均)(高いほど良い) | $5,478.16 | $573.64 | $3,838.74 | $1,473.43 |
| FACTS Benchmark Suite | 内部接地、パラメトリックMM、検索取得ベンチマーク | 70.5% | 63.4% | 50.4% | 50.8% | |
| SimpleQA Verified | パラメトリック知識 | 72.1% | 54.5% | 29.3% | 34.9% | |
| MMMLU | 多言語Q&A | 91.8% | 89.5% | 89.1% | 91.0% | |
| Global PIQA | 100言語と文化における常識的推論 | 93.4% | 91.5% | 90.1% | 90.9% | |
| MRCR v2 (8-needle) | 長文コンテキストパフォーマンス | 128k(平均) | 77.0% | 58.0% | 47.1% | 61.6% |
| 1M(ポイントワイズ) | 26.3% | 16.4% | 未対応 | 未対応 |
そのほかにも、生成AIのチューニングとして以下のような項目も検討してみてください。
- 遅延対策:生成AIの応答待ちでユーザー体験を損ねないか
- 呼び出し回数:内部で複数呼び出しなど発生していないか
- 性能の改善
- 分類の精度:ルールベースのラベリング等による評価
- 推論の精度:論理的・数学的な推論を誤ってしまうケース
- ハルシネーション:全く存在しない用語や情報がある条件下で発生してしまうことへの対策
- 安全性:生成した結果に対しての整合性チェック
- 誤検知:禁止用語やプロンプトによるインジェクションの対策の結果、ユーザーのリクエストを誤検知してしまう割合の評価
- プロンプトインジェクション:プログラム外のプロンプトを実行させることができないようにする
etc ...
5. タスクを分割する
こちらは「方向性」を示す(例:ペルソナ指定など)と似たような効果を感じるかもしれませんが、特にAIが複雑なタスクを処理するにあたり、その思考プロセスを段階的に導いてあげるための、より実践的なテクニックです。
複雑な問題を一度に解かせようとすると、AIは誤った結論を導き出したり、途中で情報が欠落したりする可能性があります。これを防ぐために、タスクを小さなステップに分解し、AIに**「順序立てて考える」**ことを要求します。
その代表的な例として「CoT推論」や「プロンプトチェーン」といった手法があります。
5.1. CoT推論(Chain-of-Thought Prompting)
$$\text{Chain-of-Thought (CoT)} : \text{思考の連鎖}$$
CoT推論は、AIに対して最終的な回答を出す前に、その思考の過程をステップバイステップで出力するように指示する手法です。これにより、AIは複雑な推論問題(特に算術や常識的な推論タスク)において、高い精度を発揮することが知られています。
💡 なぜ効果的なのか?
- 中間ステップの確認: AIは思考プロセスを明示することで、タスクの各段階で自身の計算や判断が正しいかを確認できます。
- コンテキストの拡張: 思考の連鎖(一連のステップ)がプロンプトに追加されることで、AIが最終回答を生成するための**コンテキスト(文脈)**が豊かになります。
- デバッグと修正: 人間側もAIの思考過程を追うことができるため、どこで誤りが生じたかを特定しやすくなります。
📝 実装方法(シンプルな例)
プロンプトの最後に、以下のような指示を追加するのが一般的です。
「ステップバイステップで考えてください。」
「順を追って、あなたの思考プロセスを説明してください。」
5.2. プロンプトチェーン(Prompt Chaining)
プロンプトチェーンは、複数のプロンプトを連続して実行し、それぞれのプロンプトの出力を次のプロンプトへの入力として繋げていく手法です。一つの複雑なタスクを、よりシンプルで管理しやすい一連のサブタスクに分割して処理します。
💡 なぜ効果的なのか?
- 役割の分離: 各プロンプトに特定の役割(例:情報抽出、要約、翻訳、形式変換など)を割り当てることで、それぞれのタスクの精度を最大化できます。
- 柔軟なワークフロー: 複雑なワークフローを構築でき、一つのAIモデルだけでは難しい高度な処理も実現しやすくなります。
- 長文の処理: 最初のプロンプトで長文を要約し、次のプロンプトでその要約から特定の情報を抽出するなど、コンテキストウィンドウの制限を回避しつつ効率的に情報を処理できます。
📝 実装方法のイメージ
| ステップ | プロンプトの内容 | 出力 | 次の入力 |
|---|---|---|---|
| 1 (抽出) | 「以下の文章から、重要なキーワードを5つ抽出してください。」 | [キーワードリスト] | キーワードリスト |
| 2 (構成) | 「[キーワードリスト]を使って、技術ブログのタイトル案を10個提案してください。」 | [タイトル案10個] | タイトル案10個 |
| 3 (評価) | 「[タイトル案10個]を、キャッチーさに基づいて5段階評価し、最も良いものを1つ選んでください。」 | [最終タイトル] | N/A |
これは、人間が手動で行うこともありますが、LangChainなどのフレームワークを利用して、一連の流れを自動化することも可能です。
5.3. メタプロンプティング
とはいえ、これらの事前準備は苦労する面があると思います。その場合、それすらAIにやらせてしまうというのも一つの手です。
「AIにAIのためのプロンプトを作成させる」というのがメタプロンプティングというものです。
(例)
あなたは、ユーザー体験(UX)デザイナーであり、その専門知識を活かして、AIに効果的な指示を作成します。
以下の**[最終目標]**を達成するために、AIが「批判的な思考を持つビジネスアナリスト」として機能するためのプロンプトを作成してください。
[最終目標]: 例:新しいサブスクリプションサービスの価格設定モデルの長所と短所を評価し、競合他社との比較表を作成する。
プロンプトは、分析の深さと構造化を要求するものでなければなりません。
- 複雑なタスクの分解と自動化
一つの大きなタスクを、AI自身に最適な複数のステップに分解させ、それぞれのステップを実行するためのプロンプトを自動生成させます。
活用例:
「新しいスタートアップの事業計画書を作成する」という目標に対し、AIが「市場調査用のプロンプト」「製品定義用のプロンプト」「財務予測用のプロンプト」などを次々に生成し、実行していく。
結果: ユーザーは初期の「目標」を与えるだけで、AIが自律的にタスクを完了へと導く。
- 特定の制約下でのクリエイティブな出力
非常に厳格な制約(文字数、特定のキーワード、文体など)がある場合、その制約を確実に満たすための指示をAIに考えさせます。
活用例:
「俳句の形式(5・7・5)を厳守し、**『宇宙』と『ノスタルジア』**をテーマにしたキャッチコピーを10個作成する」というタスクに対し、AIが「5・7・5の制約を最初に強調し、キーワードの組み込みを必須化する」ような厳密なプロンプトを作成する。
結果: ユーザーが直接プロンプトを書くよりも、制約を破る可能性が低い、質の高いアウトプットが得られる。
2. AIエージェントとは?
AIエージェント(Artificial Intelligence Agent)とは、環境を知覚し、自律的に判断を下し、行動することで、ユーザーやシステムが設定した特定の目標を達成しようとするAIシステムのことです。
これは単なる自動化プログラム(スクリプト)とは異なり、目標達成のために計画を立案し、状況の変化に応じて行動を修正する能力(推論・学習)を持つ点が特徴です。
基本的な構造は、以下のサイクルを繰り返します。
- 知覚(Perception): センサーやAPIを通じて、現在の環境(データ、状況)を観測します。
- 推論・計画(Reasoning & Planning): 観測結果と目標に基づき、次に取るべき最適な行動を決定します。
- 行動(Action): 決定した行動を環境に対して実行します(例:ツールの実行、データ書き込み、メッセージ送信など)。
AIエージェントが得意とすること・苦手とすること
| カテゴリ | 得意とすること (強み) | 苦手とすること (限界) |
|---|---|---|
| 複雑なタスク処理 | 複数のステップやツールを連携させる複雑なワークフローの実行。 | 未知の状況や予期せぬエラーへの対応(訓練データ外の事態)。 |
| 情報収集・分析 | Web検索、データベース、ファイルなど複数のソースからの情報統合・分析。 | 倫理的判断や感情的な配慮が必要な、人間特有の機微な判断。 |
| 自律的行動 | 人間の監視なしで継続的なタスクの実行と、状況に応じた計画の柔軟な変更。 | 曖昧すぎる目標の解釈や、計画立案における非論理的な飛躍。 |
| データ活用 | 大量の過去のデータやリアルタイムデータを基にした最適な行動戦略の選択。 | リアルタイム性が極度に要求される極めて応答速度の速い環境への適応。 |
🇯🇵 日本におけるAIエージェントの活用事例
| 分野 | 活用事例 | 詳細 |
|---|---|---|
| カスタマーサポート | 高度な対話型AI(チャットボット・ボイスボット) | ユーザーの意図を解釈し、複雑な手続き案内やFAQだけでなく、予約変更や解約処理までをAPI連携により自律的に完結させる。 |
| 金融・証券 | 自動取引システム | 市場データ、ニュース、企業の財務情報などを総合的に分析し、人間が介入することなく最適な売買判断を自律的に実行する。 |
| 製造業 | 設備・品質管理エージェント | センサーデータをリアルタイムで分析し、異常発生前の予知保全計画を立案・実行したり、製造ラインのパラメータを自律的に調整し品質を最適化する。 |
| ビジネス業務 | RPAの高度化(次世代型デジタルワーカー) | 定型業務だけでなく、メール内容の分析、最適な担当者へのタスク割り当て、データ収集・分析レポート作成までを自律的に判断し実行する。 |
⚙️ AIエージェントを開発するにあたり必要な技術スタック
AIエージェントの開発には、中核となる大規模言語モデル(LLM)の周辺に、エージェントが「知覚」し「行動」するための技術が必要です。
-
中核技術:
- 大規模言語モデル(LLM): エージェントの「脳」にあたり、推論、計画立案、自然言語の理解・生成を担います。(例:GPT-4o, Claude 3, Gemini, Llama 3など)
-
計画・実行フレームワーク:
- エージェントフレームワーク: 複雑なタスク分解、記憶管理、ツール利用を支援するライブラリ。(例:LangChain, CrewAI, AutoGen)
-
ツール・API連携:
- 外部API: エージェントが行動を実行するためのインターフェース。Web検索API、データベースAPI、業務システム(SaaS)のAPIなど。
- コード実行環境: データ分析や複雑な処理のために、エージェント自身がコード(Pythonなど)を生成・実行するサンドボックス環境。
-
記憶(Memory):
- ベクトルデータベース: 過去の対話や実行結果、外部文書などの情報を埋め込みとして保存し、推論時に必要な情報を高速に取り出す。(例:Pinecone, ChromaDB, Weaviate)
- 短期・長期記憶モジュール: エージェントが直前の対話(短期)や、過去の経験(長期)を記憶し、行動に反映させるための仕組み。
3. LangChainとLangGraphの紹介(次回向け)
🔗 LangChainとは
LangChainは、大規模言語モデル(LLM)を活用したアプリケーションを開発するためのオープンソースのフレームワークです。
LLMの持つ強力な推論能力を最大限に引き出すため、複数のコンポーネントを組み合わせて複雑なタスクを実行できるように設計されています。これにより、LLMを単なるテキスト生成ツールとしてではなく、インテリジェントな意思決定エンジンとして機能させることが可能になります。
従来の形式だとFunction Callingなどが手段としてありますが、やや難易度が高くなってしまったり、プロンプトの設定等のスキルが高度に要求されます。(FW任せにしたいかフルスクラッチで行きたいかの違いです)
LangChainの主要なコンポーネント
| コンポーネント | 役割 | 説明 |
|---|---|---|
| LLMs | 言語モデルのインターフェース | OpenAIやClaudeなど、各種LLMとの接続を標準化します。 |
| Prompts | プロンプト管理 | ユーザー入力や過去の履歴を基に、LLMに最適な指示を与えるプロンプトを構築します。 |
| Chains | コンポーネントの組み合わせ | 複数のLLM呼び出しや他のコンポーネント(Retrieversなど)を連結し、一連の処理の流れを定義します。 |
| Retrieval | 外部データ連携 | 外部ドキュメントやデータベースから関連情報を取得し、プロンプトに含めるための仕組み(RAGの核)。 |
| Agents | 自律的な意思決定 | 目標達成のために、利用可能なツールの中から次に取るべき最適な行動を自律的に判断し、実行します。 |
| Memory | 記憶管理 | 過去の会話履歴やタスクの実行結果を保持し、長期的なコンテキストを提供します。 |
🧠 LangGraphとは
LangGraphは、LangChainエージェントの処理フローをグラフ構造で定義するためのライブラリです。
従来のLangChainエージェントでは処理が直線的になりがちでしたが、LangGraphはステートフルな実行と**サイクル(ループ)**を可能にすることで、LLMがより複雑な思考パターン(例:試行錯誤、自己修正)を模倣できるようにします。
これにより、LLMは推論の結果、アクションが不適切だった場合に前のステップに戻って再考する、といったマルチステップの推論サイクルを効率的に実装できます。
LangGraphの強み
- サイクル(ループ)の実現: エージェントが目標達成まで「推論→行動→結果の評価」を繰り返す、再帰的なプロセスを簡単に構築できます。
- ステートフルな実行: 実行中の状態(State)を保持し、ノード(ステップ)間で情報を受け渡しながら処理を進めます。
- 柔軟な制御フロー: 条件分岐や並列処理など、複雑なロジックをグラフのノードとして視覚的・構造的に定義できます。
💪 LangChain/LangGraphが得意とすること・苦手とすること
| カテゴリ | LangChain/LangGraphが得意なこと (強み) | LangChain/LangGraphが苦手なこと (限界) |
|---|---|---|
| 複雑なタスク | RAG(Retrieval-Augmented Generation)を用いた外部知識に基づいた回答生成。 | LLM自体の**ハルシネーション(嘘の生成)**や不正確な推論の完全な排除。 |
| 自律性 | Agent機能によるツールの自律的な選択・実行(例:Web検索、コード実行、DB操作)。 | 実行時間やコストを意識しない非効率なツールの利用(制御の最適化が必要)。 |
| 開発効率 | モジュール化されたコンポーネントを組み合わせる迅速なプロトタイプ開発。 | 大規模な本番環境で求められる低レイテンシ(低遅延)や高スループットの実現(最適化の余地)。 |
| 推論 | LangGraphによるマルチステップの自己修正や、複雑な意思決定の繰り返し。 | 常に最適な推論パスを選ぶこと(プロンプトやモデルの能力に大きく依存する)。 |
🇯🇵 日本におけるLangChain/LangGraphの活用事例
| 分野 | 活用事例 | 詳細 |
|---|---|---|
| 社内業務効率化 | 社内ナレッジベース検索システム(RAG) | 企業の膨大なマニュアルや過去のプロジェクト資料をRetrieval機能で連携し、正確で最新の情報に基づいたQAを瞬時に提供する。 |
| データ分析・BI | データ分析エージェント | ユーザーの自然言語による「〜の傾向を分析して」という指示に対し、Pythonコードを生成・実行し、結果をグラフ化してフィードバックする。 |
| 顧客対応 | 高度なチャットボット | Agent機能を利用し、FAQ検索だけでなく、予約システムのAPIを叩いて予約の空き状況を確認・変更するなど、マルチステップな業務を完結させる。 |
| 教育・研究 | 自律的な研究アシスタント | あるテーマについて、Web検索で最新論文を探し(Tool)、内容を要約し(Chain)、不十分であればさらに深掘りして探す(LangGraphのLoop)といった作業を自律的に行う。 |
その他:プロンプト・LLMに関する参考サイト
包括的
Anthropic
OpenAI
GitHub
MicroSoft
LangChain / LangGraph