前置き
2chで有名なコピペの「初カキコ…ども…」がありますね。
今週のオモコロの記事【第1回】初カキコ…ども…選手権の影響で初カキコが再び話題になっています。
このコピペを感情分析したら、ポジティブ・ネガティブになるか分析してみました。
初カキコの全文は以下になります。
初カキコ…ども…
俺みたいな中3でグロ見てる腐れ野郎、他に、いますかっていねーか、はは
今日のクラスの会話
あの流行りの曲かっこいい とか あの服ほしい とか
ま、それが普通ですわな
かたや俺は電子の砂漠で死体を見て、呟くんすわ
it’a true wolrd.狂ってる?それ、誉め言葉ね。
好きな音楽 eminem
尊敬する人間 アドルフ・ヒトラー(虐殺行為はNO)
なんつってる間に4時っすよ(笑) あ~あ、義務教育の辛いとこね、これ
実行結果
-
感情値が
-0.488227のため、ネガティブという結果になりました。 -
ポジティブ・ネガティブの単語に色付け

-
全体的にネガティブが多い…
実行結果(全文表示)
一文ずつの感情値を出力しました。
全体的に感情値がネガティブになっていることが分かると思います。
全文の感情値の平均を求めると-0.488227となります。
-0.28484 初カキコ…ども…
-0.98782 俺みたいな中3でグロ見てる腐れ野郎、他に、いますかっていねーか、はは
-0.20401 今日のクラスの会話
-0.72328 あの流行りの曲かっこいい とか あの服ほしい とか
0.0 ま、それが普通ですわな
-0.77961 かたや俺は電子の砂漠で死体を見て、呟くんすわ
-0.98429 it’a true wolrd.狂ってる?それ、誉め言葉ね。
0.12064 好きな音楽 eminem
-0.63717 尊敬する人間 アドルフ・ヒトラー(虐殺行為はNO)
-0.40189 なんつってる間に4時っすよ(笑) あ~あ、義務教育の辛いとこね、これ
Ave = -0.488227
感情分析とは?
極性辞書
-
東工大が公開している単語感情極性対応表のこと。
-
単語に(ネガティブ)-1~(ポジティブ)1と感情値を振ってある表となります。
-
ポジティブな単語(一部抜粋)

-
ネガティブな単語(一部抜粋)

ポジティブ・ネガティブの出し方
-
「今日は良い天気だ」の感情値を求めると、
0.47101という結果が出力され、ポジティブな文章と分析できます。 -
極性辞書より「今日」「良い」「天気」の単語の感情値を求めます。
- 今日:0.172375
- 良い:0.999995
- 天気:0.24065
-
感情値を全て足し合わせた後、単語の総数で割ることで
0.47101となります。- (0.172375 + 0.999995 + 0.24065) / 3 = 0.47101
なぜポジティブ・ネガティブの結果になった?
-
初カキコの文章がネガティブになった理由は、ネガティブの単語数が全体の9割を占めているため。
-
極性辞書の単語数は全55,125語
- ポジティブの割合(0.0<感情値≦1.0):0.093(4882語)
- ネガティブの割合(-1.0≦感情値<0.0):0.907(47776語)
- ニュートラルの割合(感情値=1.0):0.000(13語)
コード説明(GoogleColabで実行)
janomeをインストール
- JanomeはPythonの形態素解析エンジン
- 日本語のテキストを形態素ごとに分割して品詞を判定したり分かち書き(単語に分割)したりすることができる
!pip install janome
極性辞書をアップロード
- 極性辞書(pn_ja.dic)を単語感情極性対応表からダウンロード
- GoogleColabにアップロードする
from google.colab import files
files.upload()
テキスト(初カキコ)の文から空白などを削除
- テキストを適当な変数に入れる
original_text = """初カキコ…ども…
俺みたいな中3でグロ見てる腐れ野郎、他に、いますかっていねーか、はは
今日のクラスの会話
あの流行りの曲かっこいい とか あの服ほしい とか
ま、それが普通ですわな
かたや俺は電子の砂漠で死体を見て、呟くんすわ
it’a true wolrd.狂ってる?それ、誉め言葉ね。
好きな音楽 eminem
尊敬する人間 アドルフ・ヒトラー(虐殺行為はNO)
なんつってる間に4時っすよ(笑) あ~あ、義務教育の辛いとこね、これ"""
- 改行ごとに要素をリストに入れる
- 空白(\u3000)を削除
result = original_text.split('\n')
result = [i for i in result if not i in ("","\u3000")]
感情値を求める
- コード
sentiment_dic = {}
with open('pn_ja.dic', 'r') as f:
lines = f.readlines()
for line in lines:
line_components = line.split(':')
sentiment_dic[line_components[0]] = line_components[3]
from janome.tokenizer import Tokenizer
keyword = []
def sentiment_analyse(text):
t = Tokenizer()
tokens = t.tokenize(text)
sentiment_val = 0
word_cnt = 1e-6 #割り算で使うので0に近い値
for token in tokens:
#単語の基本形を取り出し
word = token.surface
if word in sentiment_dic:
keyword.append([word, float(sentiment_dic[word])])
sentiment_val = sentiment_val + float(sentiment_dic[word])
word_cnt += 1
return round(sentiment_val/word_cnt, 5)
ave_list = []
cnt = 0
result_list = []
for i in result:
print(sentiment_analyse(i),i)
ave_list.append(sentiment_analyse(i))
result_list.append([i,sentiment_analyse(i)])
print("Ave = ",sum(ave_list)/len(ave_list))
- 出力結果
-0.28484 初カキコ…ども…
-0.98782 俺みたいな中3でグロ見てる腐れ野郎、他に、いますかっていねーか、はは
-0.20401 今日のクラスの会話
-0.72328 あの流行りの曲かっこいい とか あの服ほしい とか
0.0 ま、それが普通ですわな
-0.77961 かたや俺は電子の砂漠で死体を見て、呟くんすわ
-0.98429 it’a true wolrd.狂ってる?それ、誉め言葉ね。
0.12064 好きな音楽 eminem
-0.63717 尊敬する人間 アドルフ・ヒトラー(虐殺行為はNO)
-0.40189 なんつってる間に4時っすよ(笑) あ~あ、義務教育の辛いとこね、これ
Ave = -0.488227
ポジティブ・ネガティブの単語のリストを整理
- 重複している単語が多いため、重複単語を1つのみに変更
keyword = list(map(list, set(map(tuple, keyword))))
ポジティブ・ネガティブの単語に色付け
- ポジティブ単語は赤、ネガティブ単語は青で色付け
import re
color_dic = {'red':'\033[31m', 'blue':'\033[34m', 'end':'\033[0m'}
def print_hl(text, keyword, color="yellow"):
for kw in keyword:
if float(kw[1]) < 0:
bef = kw[0]
aft = color_dic["blue"] + kw[0] + color_dic["end"]
text = re.sub(bef, aft, text)
elif float(kw[1]) > 0:
bef = kw[0]
aft = color_dic["red"] + kw[0] + color_dic["end"]
text = re.sub(bef, aft, text)
print(text)
for i in result:
print_hl(i, keyword)
おまけ
- ユーザーローカル感情認識AIで感情分析してみました。
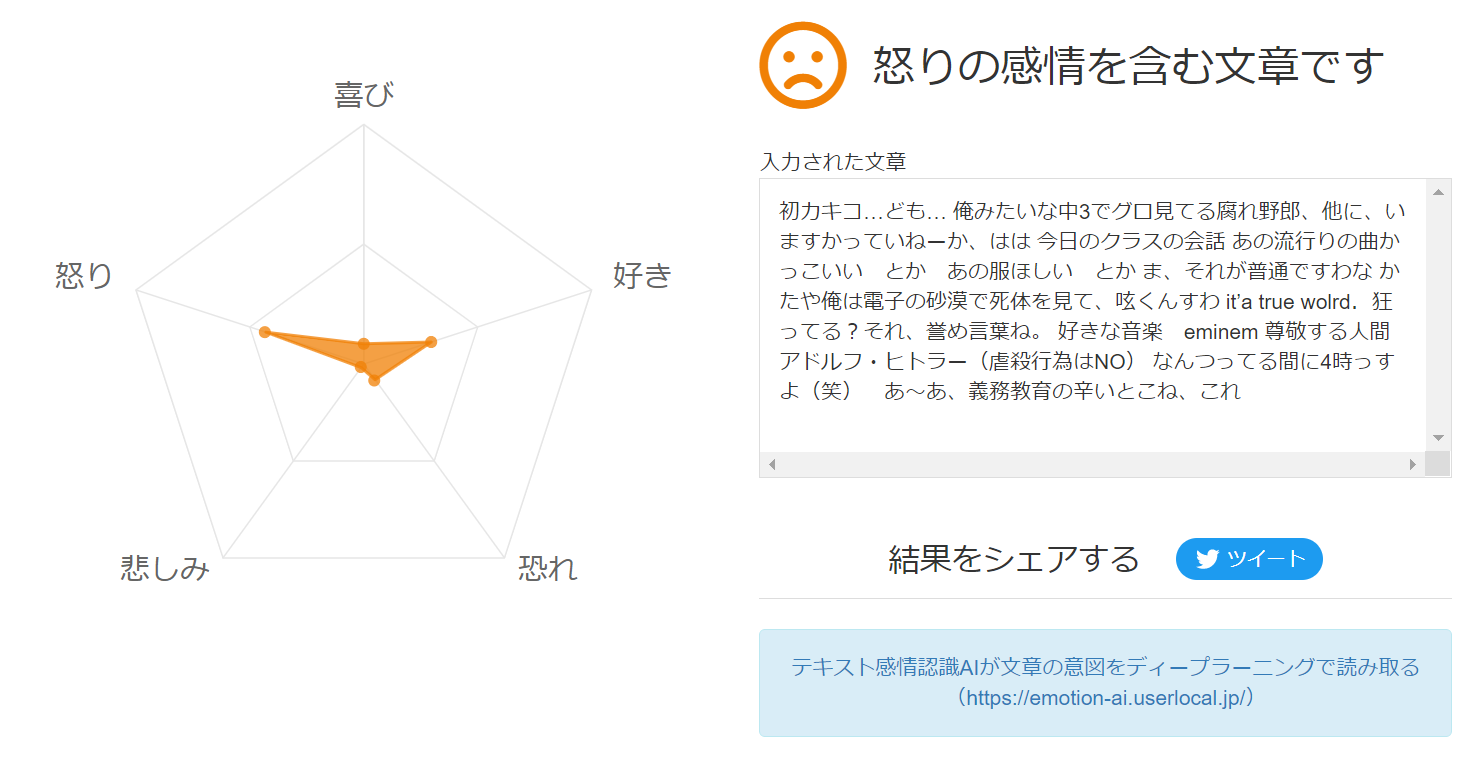
- 怒りの感情が多く含んでいるようです
- この文章の感情が怒り・好き・恐れが含まれているのは違和感ありますね、
中二病の感情はわかりづらい