- 感情分析でネガポジの極性値を取得する元となる感情値辞書は、日本語では次の3つが挙げられます。
- 本記事では全 55,125 語が登録された「単語感情極性値対応表」を利用させて頂きます。上記公式サイトによれば『岩波国語辞書』をリソースとして、感情極性値は語彙ネットワーク(筆者注 : 語や語句の意味的な関連性を示すネットワーク)を利用して自動的に計算された-1 から +1 の実数値となっています。
⑴ 「単語感情極性値対応表」の取得
1. 「単語感情極性値対応表」を読み込む
import pandas as pd
pd.set_option('display.unicode.east_asian_width', True)
# 感情値辞書の読み込み
pndic = pd.read_csv(r"http://www.lr.pi.titech.ac.jp/~takamura/pubs/pn_ja.dic",
encoding="shift-jis",
names=['word_type_score'])
print(pndic)

- pandas の
set_option()は表示形式など様々なオプションを指定するもので、引数の'display.unicode.east_asian_width'は全角文字を考慮してカラム名と値の位置をそろえて表示させます。 - 「単語感情極性値対応表」は、1行ずつ「語(終止形):読み:品詞:感情値[-1, +1]」の形式で登録されており、極性値は -1 に近いほどネガティブ、+1 に近いほどポジティブを表します。
2. 語と感情値のみ抽出して dict 型に変換
- カラム内を
split()で「:」を区切り文字として4分割し、語(終止形)"word"と感情値"score"を抽出して dict 型に変換します。
import numpy as np
# 語と感情値を抽出
pndic["split"] = pndic["word_type_score"].str.split(":")
pndic["word"] = pndic["split"].str.get(0)
pndic["score"] = pndic["split"].str.get(3)
# dict型に変換
keys = pndic['word'].tolist()
values = pndic['score'].tolist()
dic = dict(zip(keys, values))
print(dic)

⑵ 分析対象となるテキスト
- 今回はリソースを NHK のニュースサイトに求め、任意に2020年12月29日付のビジネス関連記事「スパゲッティ輸入量 過去最多に」を取り上げます。
- 句点「。」を区切り文字として行単位のリストに変換します。
text = 'スパゲッティの全国の輸入量が、ことし10月までに過去最多となり、税関は新型コロナウイルスの感染拡大の影響で増えた、いわゆる『巣ごもり需要』が背景にあるでのはないかとしています。横浜税関によりますと、全国の港や空港から輸入されたスパゲッティの量はことし10月末の時点でおよそ14万2000トンでした。これは、3年前の1年間の輸入量を4000トンほど上回り、過去最多となりました。また、マカロニもことし10月までの輸入量が1万1000トン余りに上り、過去最多だった4年前の1年間の輸入量とほぼ並んでいるということです。'
lines = text.split("。")

⑶ 形態素解析によるテキストのデータ化
1. MeCab による形態素解析のインスタンスを生成
- MeCab をインストールします。
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7
- MeCab をインポートし、出力モードを
"-Ochasen"としてインスタンスを生成します。 - 例として 1 行目の形態素解析結果を示します。
import MeCab
mecab = MeCab.Tagger("-Ochasen")
# 1行目の形態素解析結果を例示
print(mecab.parse(lines[0]))

2. 品詞を限定してデータリスト化
- 文章ごとの ポジティブ/ネガティブ の性格づけに寄与すると考えられる品詞として、名詞・形容詞・動詞・副詞の4カテゴリに絞ります。
# 形態素解析に基づいて単語を抽出
word_list = []
for l in lines:
temp = []
for v in mecab.parse(l).splitlines():
if len(v.split()) >= 3:
if v.split()[3][:2] in ['名詞','形容詞','動詞','副詞']:
temp.append(v.split()[2])
word_list.append(temp)
# 空の要素を削除
word_list = [x for x in word_list if x != []]
print(word_list)

- こちら文章単位のリストを対象として「単語感情極性値対応表」から ポジティブ/ネガティブ を判定する感情極性値を取得します。
⑷ 感情極性値の取得
1. 辞書から感情極性値を取得
- 文章ごとに、単語ごとの感情極性値を取得してデータフレームに出力してみます。
result = []
# 文単位の処理
for sentence in word_list:
temp = []
# 語単位の処理
for word in sentence:
word_score = []
score = dic.get(word)
word_score = (word, score)
temp.append(word_score)
result.append(temp)
# 文毎にデータフレーム化して表示
for i in range(len(result)):
print(lines[i], '\n', pd.DataFrame(result[i], columns=["word", "score"]), '\n')

-
全 4 行の結果を下表にまとめました。左から順に、各行の単語とその感情極性値となっています。
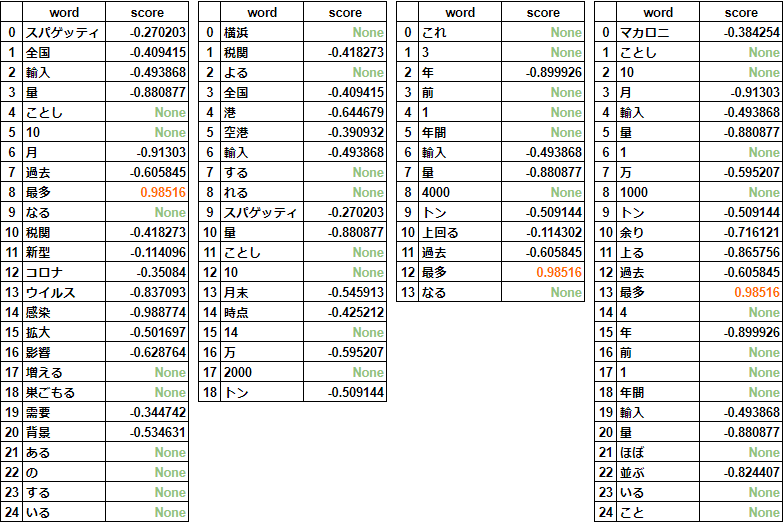
-
まず None は「単語感情極性値対応表」に登録されていない単語であり、いかに収録語彙数の多い辞書を以てしても必ず起きる問題といえます。
-
ただ、問題といえば、感情極性値に正の値をもつ単語はただ一つ「最多」しかなく、それ以外はすべて負の値となっていることです。その中には、なぜネガティブと判定されるのか実感のわかないものが少なくありません。
2. 文章ごとに感情極性値の平均値を計算
# 文単位の平均値を計算
mean_list = []
for i in result:
temp = []
for j in i:
if not j[1] == None:
temp.append(float(j[1]))
mean = (sum(temp) / len(temp))
mean_list.append(mean)
# データフレーム化して表示
print(pd.DataFrame(mean_list, columns=["mean"], index=lines[0:4]))

- 全般的にほぼ負の値なので、自ずと語数が少ないほど平均値は高くなり、もっとも文章の短い3行目のネガティブの程度が小さめとなっています。
- ここで改めて「単語感情極性値対応表」を検討してみます。
⑸ 「単語感情極性値対応表」再考
1. ネガポジの構成比を確認する
- そもそも「単語感情極性値対応表」における ポジティブ/ネガティブ 及び ニュートラル の割合はどうなっているのでしょうか。
# ポジティブの語数
keys_pos = [k for k, v in dic.items() if float(v) > 0]
cnt_pos = len(keys_pos)
# ネガティブの語数
keys_neg = [k for k, v in dic.items() if float(v) < 0]
cnt_neg = len(keys_neg)
# ニュートラルの語数
keys_neu = [k for k, v in dic.items() if float(v) == 0]
cnt_neu = len(keys_neu)
print("ポジティブ の割合:", ('{:.3f}'.format(cnt_pos / len(dic))), "(", cnt_pos, "語)")
print("ネガティブ の割合:", ('{:.3f}'.format(cnt_neg / len(dic))), "(", cnt_neg, "語)")
print("ニュートラル の割合:", ('{:.3f}'.format(cnt_neu / len(dic))), "(", cnt_neu, "語)")

- ネガティブが全体の9割を占めており、著しく偏っていることがわかります。かりに10語あったとしてポジティブな語はそのうち1語あるかないかですから、文章単位の平均値は概ねネガティブとなります。
- また例えば、先に「スパゲッティ:-0.270203」「マカロニ:-0.384254」とありましたが、人それぞれの嗜好やシチュエーションによってネガポジの実感は異なるはずです。
- なお、先の結果で唯一ポジティブな語とされた「最多」ですが、昨今の「新規感染者が最多を更新」といった語用をみても、必ずしもポジティブな意味だけに使われる語でないことは明らかです。
2. 重複している語を確認する
- 登録数は 55,125 語ですが、dict 型に変換した時点でその総数は 52,671 語に減じています。
print("dict型に変換前の要素数 :", len(pndic))
print("dict型に変換後の要素数 :", len(dic), "\n")
pndic_list = pndic["word"].tolist()
print("dict型に変換前の一意な要素数 :", len(set(pndic_list)))

- 登録の形式は原則として
語(終止形):読み:品詞:感情値[-1, +1]となっていますが、例えば、次のように同一の語(終止形)をもつ複数のデータが散在しています。こうした重複をなくした一意な要素数をカウントすると、上記のとおり dict 型に変換後の要素数 52,671 と一致します。

- さて、感情分析には「-ない」「だが」といった否定による極性の反転や、「とても」「非常に」というような感情強度の増幅などの処理が必要です。辞書自体の問題のみならず、以上の処理では全く十分ではありません。
- 辞書作りには多大なエネルギーと莫大なコストがかかります。そうした先行投資があってのことで、既成のものの恩恵に浴しようとして、その完成度をあれこれ批評することにいささか抵抗を感じます。かつてヒューマンリソースをつかって自然言語処理をやってきた個人的な経験からいえば、当事者意識をもって日本語の感情分析を考えていきたい、ですね。
- 3. Pythonによる自然言語処理 5-4. 日本語文の感情値分析[日本語評価極性辞書(名詞編)]
- 3. Pythonによる自然言語処理 5-5. 日本語文の感情値分析[日本語評価極性辞書(用言編)]