【経緯】
ELKでオープンデータを可視化するサイトを作成しております。
マップ上にデータをグラフ表示したく、KibanaのCoordinate Mapを使おうと思ったのですが、予想外に苦戦しました。
備忘を兼ねて投稿します。
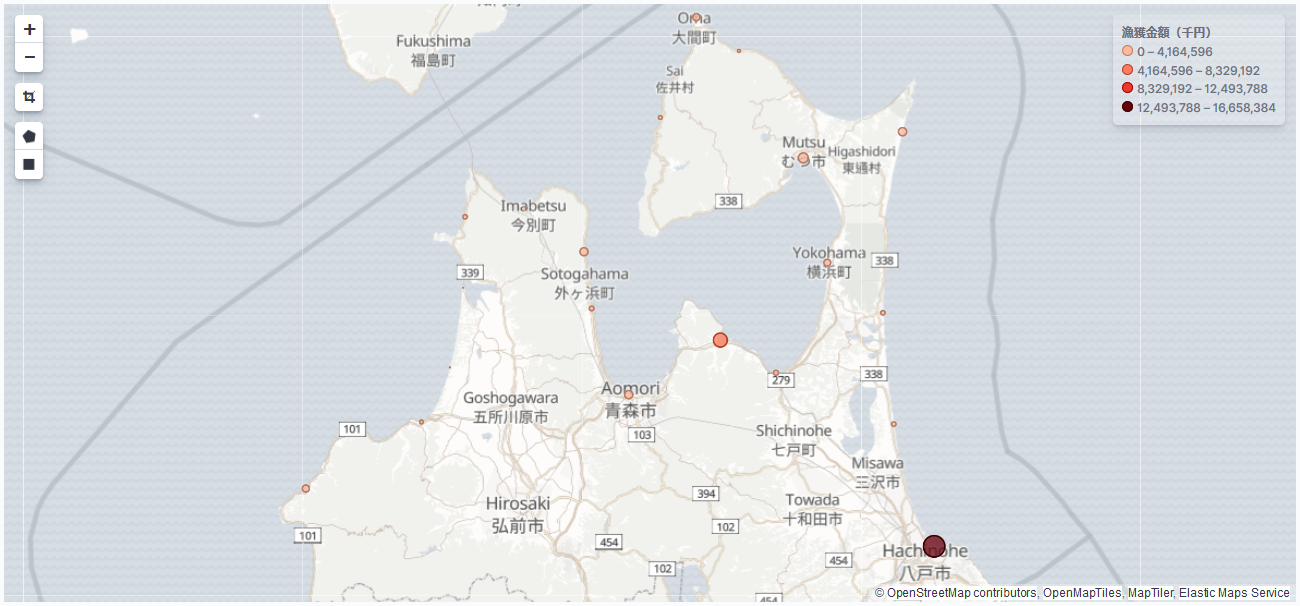
ちなみにMapイメージはこんな感じです。
【Kibanaのマップについて】
Kibanaではマップが2種類あります。
・Region Map:指定した地区の領域を色付けして表示する。
・Coodinate Map:指定した緯度経度のポイントにメトリクスを表示する。
Redion Mapについては以下のサイトが参考になります。
Kibana 5.5.0 の新機能の Region Map を試してみた
Region Map で都道府県のデータを描画してみた
本投稿では、Coodinate Mapを扱いたいと思います。
【環境】
OS:Amazon Linux 2
データベース:Elasticsearch 7.1
データ投入:Logstash 7.1
データ可視化:Kibana 7.1
※注意:本投稿はELK7系での手順です。他バージョンではおそらく違う設定・手順になるかと思うのでご留意ください。
【作業手順】
全体の作業の流れ
- CSVファイルを用意する
- Logstashのconfファイルを作成する
- index templateを設定する
- logstashによりcsvデータを取り込み
- kibanaでCoordinate Mapを作成する
それでは具体的な手順を以下に示します。
1. CSVファイルを用意する
まずはCSVファイルを用意します。
id,nengetsu,chiku,gyorui,kairui,sonota,sourui,sousuu,kingaku,lat,lon #←この行は削除すること
ID,年月,市町村名,魚類,貝類,その他,藻類,総数,漁獲金額,緯度,経度 #←この行は削除すること
1,2018-01-01,深浦町,220201,278,87827,930,309236,199231,40.650993,139.929676
2,2018-01-01,鰺ヶ沢町,82891,16,64543,27,147477,80995,40.778099,140.220862
3,2018-01-01,つがる市,2185,0,688,0,2873,1690,40.882709,140.2922
(以下省略)
先頭の2行は説明のために表記しております。実際のCSVでは先頭2行は削除してください。
2. Logstashのconfファイルを作成する
LogstashでCSVデータを取り込むために、以下のようなconfファイルを用意します。
input {
file {
path => ["/etc/logstash/conf.d/sample.csv"]
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
columns => ["id","nengetsu","chiku","gyorui","kairui","sonota","sourui","sousuu","kingaku","latitude","longitude"]
}
date {
match => ["nengetsu", "yyyy-MM-dd"]
}
mutate {
convert => {
"id" => integer
"chiku" => string
"gyorui" => integer
"kairui" => integer
"sonota" => integer
"sourui" => integer
"sousuu" => integer
"kingaku" => integer
"latitude" => "float"
"longitude" => "float"
}
add_field => {
"[location][lat]" => "%{latitude}"
"[location][lon]" => "%{longitude}"
}
convert => {
"[location][lat]" => "float"
"[location][lon]" => "float"
}
}
}
output {
elasticsearch {
index => "sample"
document_id => "%{id}"
}
}
3. index templateを設定する
csvとconfが用意できたところでデータ投入、と行きたいところですが、投入の前にElasticsearchにてindex templateの設定が必要です。
# curl -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_template/sample' -d '
{
"index_patterns": "sample*",
"mappings": {"properties": {"location": {"type": "geo_point"}}}
}'
上記コマンドを実行し、「{"acknowledged":true}」と表示されればOKです。
4. logstashによりcsvデータを取り込み
それではいよいよデータを投入します。
まずはsample.csvとsample.confを/etc/logstash/conf.d/に配備してください。
# pwd
/etc/logstash/conf.d
# ls
sample.conf sample.csv
そして以下のコマンドで実行です。少々時間がかかるかもしれません。
# /usr/share/logstash/bin/logstash -f ./sample.conf
数分程度時間がかかるかもしれません。
[ERROR]が出ずに[Successfully started Logstash API endpoint]というメッセージが出ればOKです。
([WARN]は気にしなくて大丈夫です。)
5. KibanaでCoordinate Mapを作成する
最後にKibanaでマップを作ります。
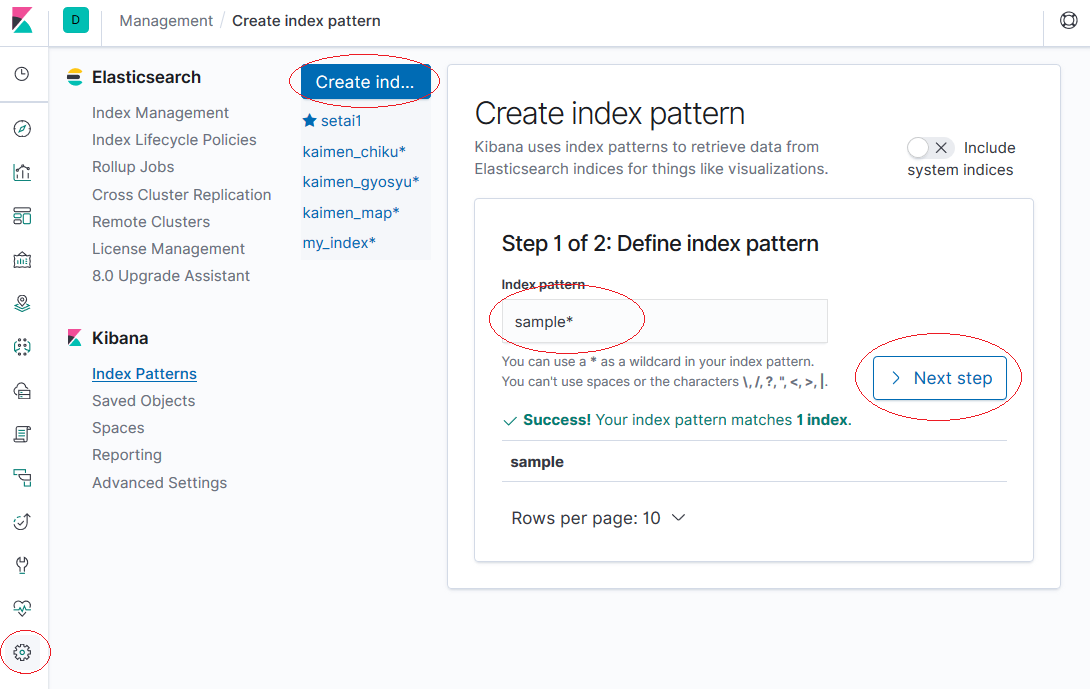
①まず初めに[Management]の[index Patterns]でindex patarnを作成します。
名前は「sample*」とします。
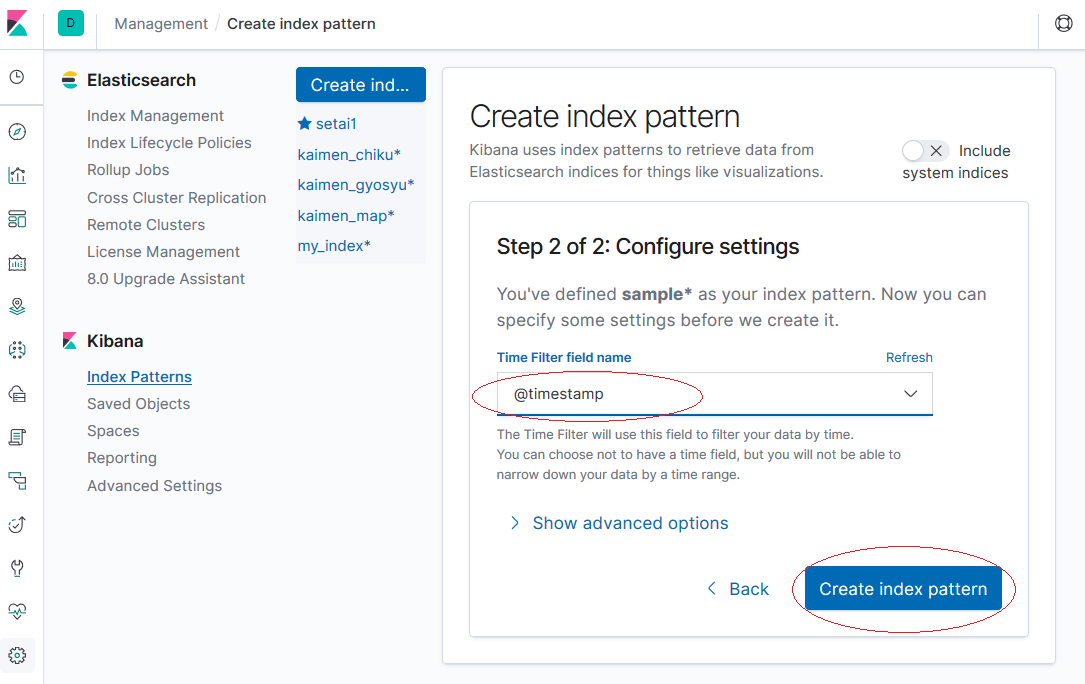
Time Fileterは[@timestamp]を選択します。
②次に[Visualise]の新規作成で[Coordinate Map]を選択し、「sample*」を選択します。  
③[Metrics]と[Buckets]を設定します。 また右上の対象期間を適切に設定してください。(デフォルトのままだと何も表示されないことがあります。) 設定を終えたら三角形の実行アイコンをクリックすると、MAP上に表示されます。  
④MAP左上の真ん中のアイコンをクリックすると、ちょうどいい感じでズームしてくれます。
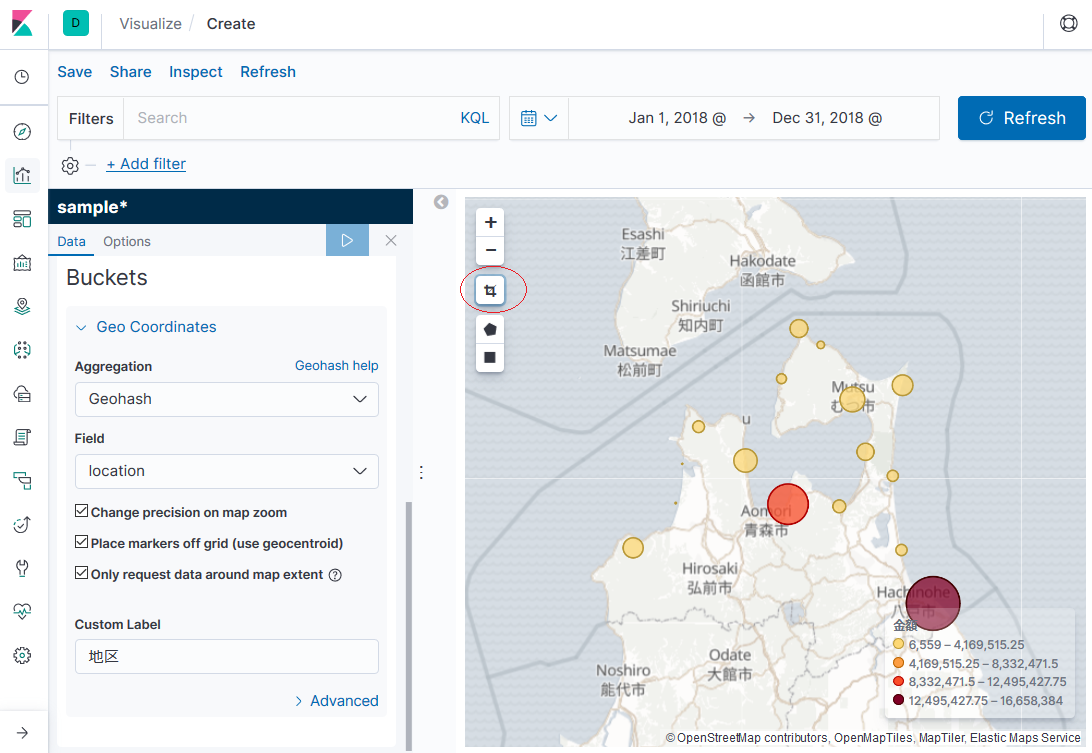
なんかいい感じに表示されました!
【最後に】
ポイントはlogstashで取り込む前にtemplateを設定しておくことですね。これが分からなくて苦戦しました。
(logstashのconfでgeo_point型を設定できないかといろいろチャレンジしてましたが、結局はtemplateで解決しました。)
ElasticとKibanaを使って作成したグラフを以下サイトで公開しております。
興味がございましたら見てみてください。