1.概要
Liquid AI が2026年1月に公開した、ローカルデバイス上での動作に焦点を当てた日本語特化の小型 AI モデル「LFM2.5」について検証を行った。
本検証では、CPU 上で動作可能な 8-bit(Q8)量子化モデルを使用し、CLI 、Web UIでの両方の動作確認を実施した。
その結果、CLI・Web UI ともに、Pythonからの呼び出しも正常に動作し、また、PDF / TXT ファイルの読み取りにも対応していることを確認しました。
2.検証環境
ハードウェア
・CPU : Intel Core i7-10700 @ 2.90GHz(8 Core / 16 Thread)
・メモリ : 128GB
ソフトウェア
・OS : CentOS Stream 9
・推論エンジン : llama.cpp
・モデル : LFM2.5-1.2B 日本語モデル(Q8 量子化)
3.インストール手順
3.1 必要パッケージのインストール
sudo dnf install -y git gcc gcc-c++ make cmake python3 python3-pip
sudo dnf install -y libgomp
3.2 llama.cpp のビルド
cd /opt
sudo git clone https://github.com/ggerganov/llama.cpp.git
sudo chown -R $USER:$USER llama.cpp
cd llama.cpp
mkdir build
cd build
cmake .. -DLLAMA_OPENMP=ON
cmake --build . --config Release -j$(nproc)
3.3 モデルの取得
mkdir -p ~/models/LFM2.5
cd ~/models/LFM2.5
wget https://huggingface.co/LiquidAI/LFM2.5-1.2B-JP-GGUF/resolve/main/LFM2.5-1.2B-JP-Q8_0.gguf
4. 動作確認(CLI)
[root@localhost build]# cd /opt/llama.cpp/build
./bin/llama-cli \
-m /root/models/LFM2.5/LFM2.5-1.2B-JP-Q8_0.gguf \
--ctx-size 8192 \
-n 2000 \
--temp 0.9
Loading model...
build : b0-unknown
model : LFM2.5-1.2B-JP-Q8_0.gguf
modalities : text
available commands:
/exit or Ctrl+C stop or exit
/regen regenerate the last response
/clear clear the chat history
/read add a text file
起動後、対話モードにて以下の算数問題を入力した。
> ある商品を定価で買うと 12,000 円です。
この商品を
・最初に 20% 引き
・次に 10% 引き
した場合の最終価格を求めてください。
出力結果
最初に商品を20%引きした後の価格は:
12,000 × (1 - 0.20) = 12,000 × 0.80 = 9,600円
次に、9,600円に10%引きした価格は:
9,600 × (1 - 0.10) = 9,600 × 0.90 = 8,640円
したがって、最終価格は **8,640 円** です。
推論性能
[ Prompt: 202.1 t/s | Generation: 29.4 t/s ]
CPU 実行としては十分実用的な推論速度であり、計算問題に対しても安定した応答を確認できた。
5. Web UI(API サーバー)
5.1 起動方法
./bin/llama-server \
-m /root/models/LFM2.5/LFM2.5-1.2B-JP-Q8_0.gguf \
--host 0.0.0.0 \
--port 8080
ブラウザからアクセスすることで Web UI を利用可能。
Web UI では テキスト入力に加え、PDF / TXT ファイルの読み込みにも対応しており、簡易的な文書要約・解析用途としても活用できる。
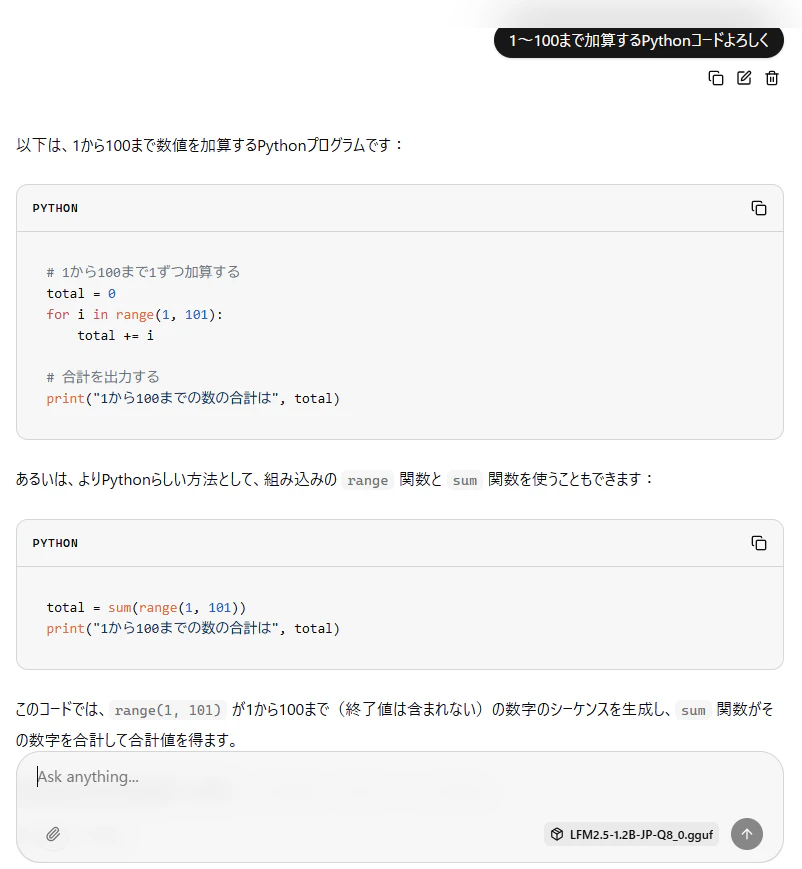
6. Pythonから呼ぶ方法
OpenAI 互換の API を提供しているため、requests ライブラリを使えば Python から簡単に呼び出すことができます。
ここでは、**「1~100まで加算する Python コードを生成してもらう」**例を紹介します。
LFM API を呼び出すサンプルコード
以下は、ローカルで起動している LFM サーバ(localhost:8080)に対して、
/v1/completions エンドポイントを使ってプロンプトを送信する例です。
import requests
url = "http://localhost:8080/v1/completions"
payload = {
"model": "lfm",
"prompt": "1~100まで加算するPythonコードよろしく",
"max_tokens": 2048,
"temperature": 0.9
}
response = requests.post(url, json=payload)
response.raise_for_status()
data = response.json()
print(data["choices"][0]["text"])
実際に返ってきたコードの一例が以下です。
# python add.py
# 100まで加算するPythonコード
sum_result = sum(range(1, 101))
print(sum_result)
7. 所感・まとめ
・LFM2.5 は CPUのみの環境でも十分に実用的
・Q8 量子化モデルにより、精度と速度のバランスが良好
・CLI / Web UI の両対応により用途の幅が広い
・ローカル実行のため、情報を外部に出せない環境での利用に適する
特に、メモリ容量が十分にある環境では、コンテキスト長を大きく取れる点も実運用上のメリットと感じられた。