はじめに
Twitterの一部の映画ファンの間では、年末時期になるとその年に観た映画のタイトルをベスト10形式でつぶやくという文化があります。以下みたいな感じです。年間数十~数百本も映画を観るコアな映画ファンが選りすぐった10本ということで、世間一般的な興収ランキングや人気ランキングとはまた違った結果 が得られそうな気がします。ということで、今回はプログラムでそれらのツイートを自動収集し、つぶやかれたタイトルを集計してみました。
映画ベスト10ツイートの例
遅くなったけど。2019年の劇場鑑賞数は75作品。以下、順不同です。
— マロン (@kurikou02) January 3, 2020
・アリータ
・殺さない彼と死なない彼女
・スパイダーマン FFH
・イップマン外伝 マスターZ
・ヒックとドラゴン3
・ガリーボーイ
・スパイダーバース
・ジョン・ウィック3
・僕のヒーローアカデミア
・天気の子#2019年映画ベスト10
全体概要
- Twitterから対象のハッシュタグを含むツイートを収集しDBに蓄積
- タイトルマッチング用に、映画情報サイトから作品タイトルや公開情報(公開時期、上映時間等)を取得しDBに格納
- 最後に、それらの情報を組み合わせて出現タイトルの判定・集計処理を実行、最終的な出力として集計結果を得ます

タイトル集計の考え方
- 集計対象作品:2019年に国内で劇場公開された映画作品
- 集計対象ツイート:「#2019年映画ベスト10」のハッシュタグを含むツイート
- 集計方法:ツイート中の対象作品の出現回数のみカウント
※順不同で投稿している人も多いので、順位による重み付け等は今回行いません。
開発環境
- OS:Windows10 Pro
- IDE:Visual Studio Code
- DB:MongoDB v4.0.10
- 開発言語:Python 3.7.3
開発のポイント
今回の開発ポイントは大きく以下の3つです。
- Twitter APIによるツイート自動収集
- Webスクレイピングによる映画DBの構築
- 自然言語処理によるタイトルマッチングと集計処理
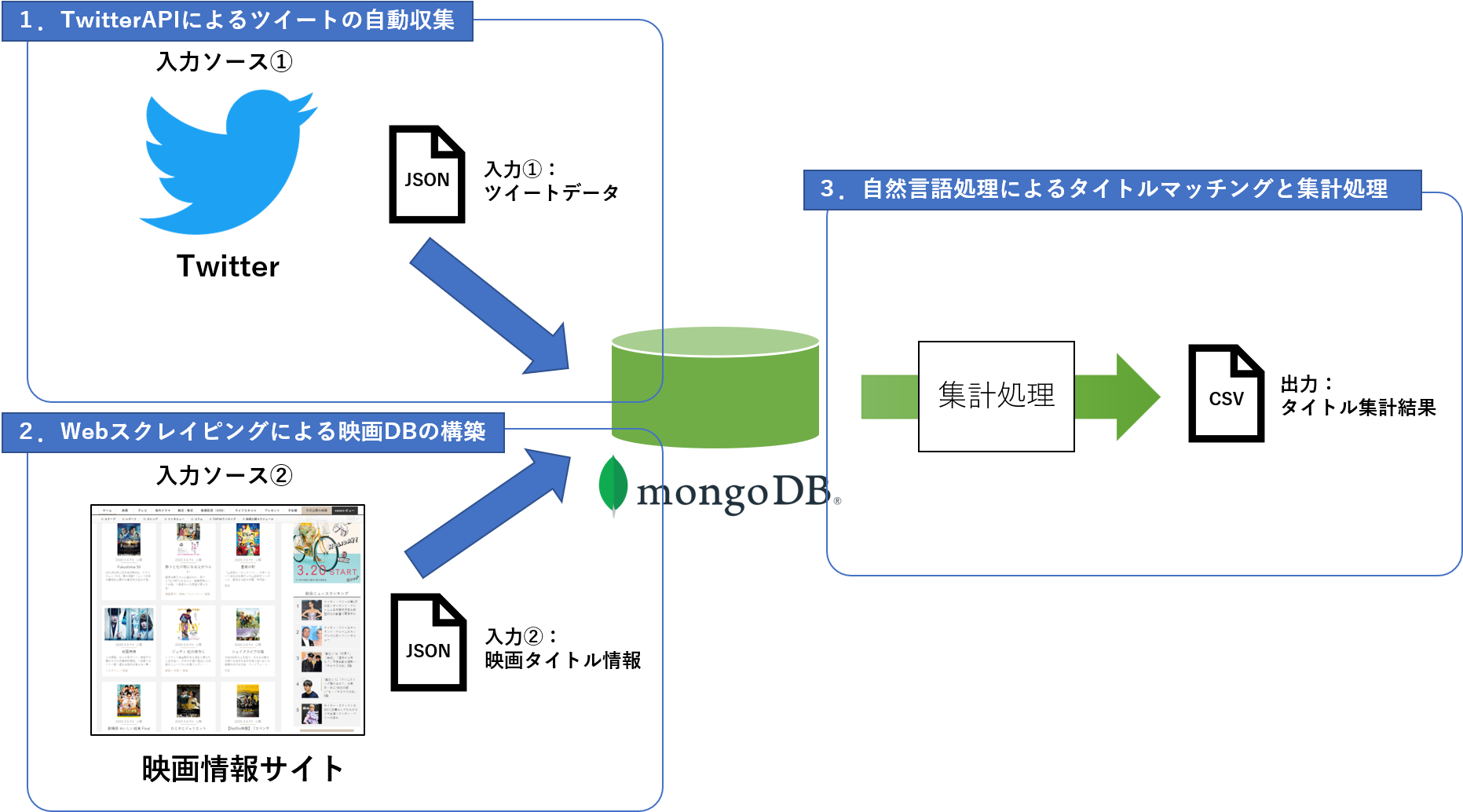
今回のキモは、3番目の タイトルマッチング部分 です。Twitter特有のクセ(**タイトルの表記ゆれ、誤字脱字、略称・俗称などなど)**に対応しながら、 映画サイトに載っている公式タイトルとどうマッチングするか が大きなポイントでした。
1.Twitter APIによるツイートの自動収集
「#2019年映画ベスト10」 を検索キーワードとして、TwitterのSearch APIを使用してツイートを収集しました。ライブラリは OAuth1Session を使用しています。SerachAPIによるツイート収集のサンプルはQiitaやgithubにもたくさんありますので詳細は割愛します。以下のページが大変参考になります。
◆スタバのTwitterデータをpythonで大量に取得し、データ分析を試みる その1
実装ポイント
少しコツがいる点としては、 「since_id」 と 「max_id」 をきちんと指定するところです。since_idとmax_idの意味は以下のページで分かりやすく説明されています。since_idをきちんと指定しないと、 検索結果が重複 してしまい、後々データ整理が面倒くさいことになります。
◆「Twitter API Timeline解説」のんびりしているエンジニアの日記
繰返しTweetデータを取得するサンプル(一部抜粋)
import sys
import traceback
import logging
import os
import json
import re
import datetime
import time
import pytz
import requests
import ssl
import pymongo
from pymongo import MongoClient
from requests_oauthlib import OAuth1Session
from config import Config
# 認証キーとアクセストークン
CK = Config.CONSUMER_KEY
CS = Config.CONSUMER_SECRET
AT = Config.ACCESS_TOKEN
ATS = Config.ACCESS_TOKEN_SECRET
SEND_ID = Config.SEND_DM_ID
# 大域変数
twitter = None
connect = None
db = None
tweetdata = None
meta = None
# 初期化処理
def initialize():
global twitter, connect, db, tweetdata, meta
twitter = OAuth1Session(CK, CS, AT, ATS)
connect = MongoClient('localhost', ******)
db = connect.*******
tweetdata = db.*******
meta = db.*******
# 検索ワードを指定して100件のTweetデータをTwitter REST APIsから取得する
def getTweetData( keyword, max_id, since_id ):
global twitter
url = 'https://api.twitter.com/1.1/search/tweets.json?tweet_mode=extended'
params ={
'q' : keyword, # 検索キーワード
'lang' : 'ja', # 日本語のみ
'count' : '100', # 取得するtweet数
}
if max_id != -1:
params['max_id'] = str(max_id)
if since_id != -1:
params['since_id'] = str(since_id)
# Tweetデータの取得
req = twitter.get(url, params = params)
# 取得データの分解
if req.status_code == 200: # 成功した場合
timeline = json.loads(req.text)
metadata = timeline['search_metadata']
statuses = timeline['statuses']
limit = req.headers['x-rate-limit-remaining'] if 'x-rate-limit-remaining' in req.headers else 0
reset = req.headers['x-rate-limit-reset'] if 'x-rate-limit-reset' in req.headers else 0
return {'result':True, 'metadata':metadata, 'statuses':statuses, 'limit':limit, 'reset_time':datetime.datetime.fromtimestamp(float(reset)), 'reset_time_unix':reset}
else: # 失敗した場合
print_ex('Error: %d' % req.status_code)
return{'result':False, 'status_code':req.status_code}
# 文字列を日本時間にタイムゾーンを合わせた日付型で返す
def str_to_date_jp(str_date):
dts = datetime.datetime.strptime(str_date,'%a %b %d %H:%M:%S +0000 %Y')
return pytz.utc.localize(dts).astimezone(pytz.timezone('Asia/Tokyo'))
# 現在時刻をUNIX Timeで返す
def now_unix_time():
return time.mktime(datetime.datetime.now().timetuple())
# 日付型の列'created_datetime'を付加する
def add_datetime_filed():
# 日付型の列'created_datetime'を付加する
for d in tweetdata.find({'created_datetime':{ '$exists': False }},{'_id':1, 'created_at':1}):
tweetdata.update_one({'_id' : d['_id']},
{'$set' : {'created_datetime' : str_to_date_jp(d['created_at'])}})
# sid(検索の終了地点のid)を返す
def get_sid():
for d in tweetdata.find({},{'id':1, 'created_at':1}).sort([{'id',pymongo.DESCENDING}]).limit(1):
if d is not None:
return d['id']
return -1
# mid(次の検索の開始位置のid)を返す
def get_mid():
for d in meta.find({},{'metadata':1, 'insert_date':1}).sort([{'insert_date',pymongo.DESCENDING}]).limit(1):
next_url = d['metadata']['next_results']
pattern = r'.*max_id=([0-9]*)\&.*'
ite = re.finditer(pattern, next_url)
for i in ite:
return i.group(1)
return -1
# 繰り返しTweetデータを取得
def run_get_tweet(key_word, sid, mid ):
# 進捗表示用
done = 0
total_count = 0
while(True):
try:
# ツイート取得
res = getTweetData( key_word, max_id=mid, since_id=sid )
# 失敗したら終了する
if res['result']==False:
print_ex('status_code %d ' %res['status_code'])
break
# 回数制限に達したので休憩
if int(res['limit']) == 0:
# 日付型の列'created_datetime'を付加する
add_datetime_filed()
# 待ち時間の計算. リミット+10秒後に再開する
diff_sec = int(res['reset_time_unix']) - now_unix_time()
print_ex('sleep %d sec.' % (diff_sec+10))
if diff_sec > 0:
time.sleep(diff_sec + 10)
else:
# metadata処理
if len(res['statuses'])==0:
# 取得可能なツイートがない
# -> 遡れるだけ取り尽くした状態。一旦終了して休ませる(30分)。
# 日付型の列'created_datetime'を付加する
add_datetime_filed()
# sidを更新
print_ex('statuses is none. waiting...\n done:{},total_count:{}\n'.format(done, total_count))
sid = get_sid()
mid = -1
time.sleep(30*60)
elif 'next_results' in res['metadata']:
# 結果をmongoDBに格納する
meta.insert_one({'metadata':res['metadata'], 'insert_date': now_unix_time()})
for s in res['statuses']:
tweetdata.insert_one(s)
next_url = res['metadata']['next_results']
pattern = r'.*max_id=([0-9]*)\&.*'
ite = re.finditer(pattern, next_url)
for i in ite:
mid = i.group(1)
break
# 進捗表示
done += 1
total_count += len(res['statuses'])
sys.stdout.write('\rツイート取得成功:試行回数{}回 今回取得{}件 総取得{}件\n'.format( done, len(res['statuses']), total_count ))
# ちょっと休ませる
time.sleep(5)
else:
print_ex('next is none. finished.')
break
"""
例外処理など(記載割愛)
"""
# ツイートの取得開始
def run(keyword = ''):
# 初期化処理
initialize()
# 最後に取得したツイートのID(since_id)を保持
sid = get_sid()
# 処理開始
run_get_tweet(keyword, sid, -1)
# メイン処理
def main(args):
# Tweet収集開始
run('#2019年映画ベスト10')
return 0
処理結果のDM通知
処理終了時には、処理結果やエラー内容などをTitterのDMで通知するようにしました。以下、その部分のサンプルコードです。
# DM送信
def send_dm( msg='' ):
headers = {'content-type': 'application/json'}
url = 'https://api.twitter.com/1.1/direct_messages/events/new.json'
payload = {'event':
{'type': 'message_create',
'message_create': {
'target': {'recipient_id': SEND_ID },
'message_data': {'text': msg,}
}
}
}
payload = json.dumps(payload)
res = twitter.post(url,headers=headers,data=payload)
# 拡張print関数( コンソール出力とDM送信を同時に行う )
def print_ex( msg = '', dmsend = True ):
print(msg)
# DM通知送信
if dmsend == True : send_dm(msg)
ツイート収集結果
基本的には収集用のプログラムを回し続け、 たまにネットワークエラー等でコケでDMが飛んできたら再起動する …といった感じで運用しました。今回は2019年12月中旬ごろから取得を初めて、約一ヶ月で21083件のツイートが集まりました。収集したツイートはMongoDBにもどんどん取り込み、MongoDBのクライアントツールであるMongoDB Compassを使って確認しています(下図)

実際はここから無効なツイートや無関係なツイートなどのノイズ除去を行ったり、データの前処理が色々と必要ですが、そこはタイトルマッチングや集計処理のところで詳しく記載します。ツイートの自動収集については以上です。
2.スクレイピングで映画DB構築
次に、映画作品の タイトルを判定する基となる 、映画DBを構築していきます。 既存のオープンDB 等で、なにか使えないか少し調べてみたんですが、 意外にも全然マッチするものが無く て驚きました。映画レビューの分類問題なんか自然言語処理の超古典的なタスクだと思いますが、日本語で書かれた邦題や、日本国内の公開情報が反映されたようなデータベースはどうしても見つかりませんでした。
既存の映画DBとしてはTHE MOVIE DATABASEが一番良さげだったんですが、やはり海外基準の情報になっており、邦画や国内公開情報にはあまりマッチしませんでした。気軽にアクセス可能な情報源がここまで見つからないのは予想外で、今回の取り組みで地味に手間がかかったのがこの映画DB部分でした。 世間一般の映画サイト や 映画関連アプリ を開発されてるところはどうやって情報収集してるんでしょうか…詳しい方おられましたら、ぜひご教示頂きたいです。とりあえず、今回は映画サイトの情報を参考に力技で構築しました。
実装ポイント
よくあるPythonのWebスクレイピングを使っていますが、今回対象とした映画サイトの一部ではJavascriptを多用して動的に描画されているものがあり、そこは Webdriverでブラウザ操作をエミュレート して対応しています。また、映画タイトルだけでは寂しいので、 公開日や製作国、上映時間などの付帯情報 も合わせてデータベース化してみました。
映画タイトルクラス
今回は、映画1本分の情報をTitleDataクラスとしてまとめる設計にしました。
# 作品情報クラス
class TitleData():
def __init__(self, release_date, title, detail_info ):
self.release_date = release_date # 公開日時
self.title = title # タイトル
self.detail_info = detail_info # 作品詳細情報
# 作品詳細情報クラス
class DetailInfo():
def __init__(self, org_title='', prod_year='', country='', screening_time='', rating='', company='', credit=''):
self.org_title = org_title # 原題
self.production_year = prod_year # 制作年
self.country = country # 製作国
self.screening_time = screening_time # 上映時間
self.rating = rating # 映倫区分
self.company = company # 配給会社
self.credit = credit # クレジット
def show(self):
print("原題:", self.org_title)
print("製作年:", self.production_year)
print("製作国:", self.country)
print("上映時間:",self.screening_time)
print("映倫区分:",self.rating)
print("配給会社 :", self.company)
print("クレジット:", self.credit)
映画情報取得の概要
今回やってみて初めてわかったんですが、映画のタイトル表記 や、記載されている詳細情報の有無 には、各映画サイトによって微妙に違いがある ようです。よって今回は、メインの映画サイトで情報が取れなかった(記載が無かった)作品については、別のサイトでその作品を検索 し、抜けている情報を補完 する2段構えの設計にしています(下図)
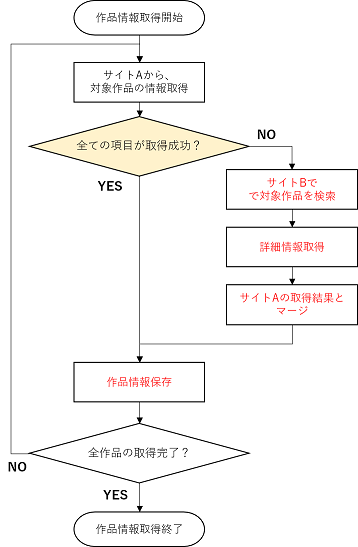
Webdriverによるブラウザ操作エミュレートのサンプル
情報取得のメインとなる映画サイトは、一般的なWebスクレイピングで情報取得が可能な静的なWebページでした。スクレイピング用のライブラリにはおなじみの BeautifulSoup を使用し、特に工夫も無く取得できました。こちらについては詳細は割愛しますので、Qiitaにたくさんある解説記事を参考にしてみてください。少しコツが必要だったのはWebdriverによるブラウザエミュレートが必要な場合で、こちらはサンプルコードを一部紹介します。
メインとなるサイトA で作品情報がうまく取れなかった場合に、対象作品を別のサイトBで検索し直して情報を補完 します。この時、サイトBの検索フォームに対象となる作品のタイトルを入力したり、検索ボタンを押したりする操作を Webdriverでエミュレート していきます。ポイントは、対象ページを読み込んだ時に、 コンテンツが全て読み込まれるまで少し待ってあげること です。読込後すぐにページ内容を取得しても、まだ描画が完了しておらず、欲しい情報が取得できない場合があります。
import sys
import os
import pprint
import json
import re
import requests
import datetime, time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from pymongo import MongoClient
import difflib
import jaconv
from titledata import TitleData,DetailInfo
# 指定ページのデータをBeautifulSoupで取ってくる
def get_page(url, param = None):
# paramは連想配列で
if param == None: # GET
return BeautifulSoup(requests.get(url).content, 'lxml')
else: # POST
return BeautifulSoup(requests.post(url, data=param).content, 'lxml')
# 映画サイトを検索して、指定のタイトルの詳細情報を取得するサンプル
def get_detail_info( search_title='' ):
if search_title == '' :
print('Search title is none')
return None
# Webdriver立ち上げ準備:Headlessモードを有効にする
#(コメントアウトするとブラウザが実際に立ち上がる)
options = Options()
options.set_headless(True)
options.add_argument("--log-level=3")
# ブラウザ起動・トップページを開く
driver = webdriver.Chrome(executable_path=r'***\***\chromedriver.exe', chrome_options=options)
driver.get('http://www.****.com/')
# ページが完全に読み込まれるまで待機
WebDriverWait(driver, 15).until(EC.presence_of_all_elements_located)
print( 'Top page loaded : {}'.format(driver.current_url ))
# 検索フォームにキーワードを入力し送信
driver.find_element_by_id("intput_search_header").send_keys( search_title )
elem_search_btn = driver.find_element_by_id("btn_search_header")
elem_search_btn.click()
print('Search title done : title is [ {} ]'.format(search_title))
# 検索結果の要素が完全に読み込まれるまで待機
WebDriverWait(driver, 60).until(EC.element_to_be_clickable((By.ID, "box_result_search_search_string")))
print( driver.current_url )
print( 'Search result page loaded : {}'.format(driver.current_url ))
# 検索結果から、作品詳細ページへのリンクを取得
html = driver.page_source.encode('utf-8') # more sophisticated methods may be available
soup = BeautifulSoup(html, "lxml")
"""
ページの中身を解析して欲しい情報を取得し、detailinfoクラスに格納
(対象Webサイトごとに構造異なるため、詳細割愛)
"""
# WebDriverの終了処理
driver.close()
driver.quit()
# 抽出したデータセットを返す
return dinfo # 返り値:detailinfoクラス
タイトルの類似度判定
また、上記のサンプルコードでは割愛していますが、別サイトで対象作品の情報を補完する際、タイトルの判定にはdifflibによる単語の類似度判定を用いています。 映画サイトによりタイトル表記が微妙に異なる 場合があるため、その 表記ゆれ を吸収するためです。
"""
タイトル判定部分のみ抜粋(match_titleは検索結果の作品タイトル)
"""
# 全角->半角変換
match_title = jaconv.z2h(match_title, kana=False, digit=True, ascii=True)
score = difflib.SequenceMatcher(None, search_title, match_title ).ratio()
# 類似度80%未満なら却下(不一致)
if score < 0.8 :
# WebDriverの終了処理
driver.close()
driver.quit()
print( 'Matching title notshing! (low score {} : {})'.format(score, match_title) )
return None
映画DB構築結果
今回はcinemacafeさんを主に参考にさせて頂き、情報が無い場合はkinenoteさんで補完する、という流れで運用しました。もちろん、Webサイトに負荷がかからないよう、十分な待機時間を入れながら、数日に分けて実行しています。結果的には、2019年に国内公開された映画としては全部で987作品分の情報を取得することができました。
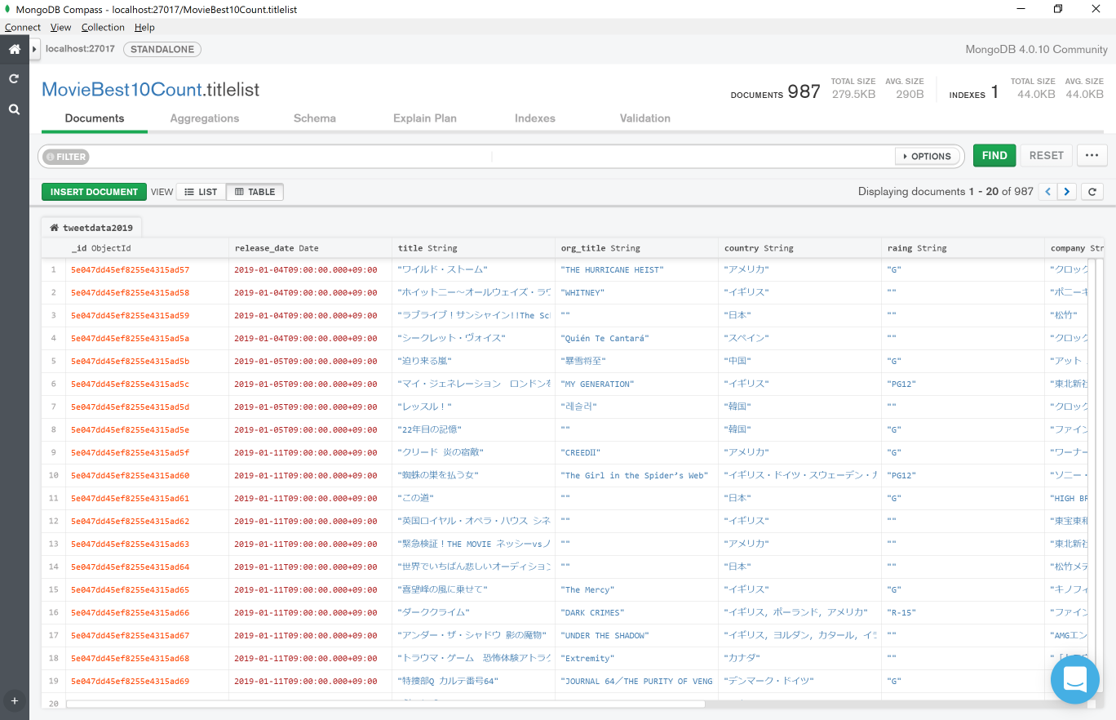
上のイメージを見て分かる通り、 2つのサイトで補完しあっても、取得できなかった項目 が結構あります。ここらへんを見る限り、映画サイトといえど100%の情報精度ではないというか、国内の映画業界向けに完全に統一されたデータベースみたいなものは存在しないのかもしれません。(無ければ作ってしまおうか、とも少し思いましたがそれはまた別途…)
3.自然言語処理によるタイトル集計
さて、ようやく今回の取り組みのメインとなる、 自然言語処理によるタイトルマッチングと集計処理 についてです。Twitter APIで収集したツイートを解析し、自前で構築した映画DBのタイトルとマッチングしていきます。ここはとにかく、表記ゆれや略称、誤字脱字が多く含まれるツイート中のタイトル文字列 と、 正式なタイトル文字列 をいかにマッチングするかが課題です。
実装のポイント(処理の流れ)
言葉で書いても分かりづらいので以下の図にまとめました。ポイントは、ツイートの各行に対して1行ずつ全てタイトル判定を行うのではなく、 一度全ての入力行をハッシュに格納し圧縮している点 です。(言葉では分かりづらいので後で詳しく説明します) また、どうしても正式タイトルとのマッチングが難しい表記や、Twitter特有の表記については、自前で変換用辞書(メタ辞書)を作成して補完しています。では、各Stepごとに詳しい内容を記載していきます。

Step1.前処理
まずは入力となるツイートの前処理を行います。前処理の概要は以下のとおりです。
- RTやリプライといった無関係な内容のツイートならスキップ
- 明らかに短いツイートならスキップ
- 特定のストップワードを含むツイートはスキップ
- ハッシュタグやURLなどのノイズ除去
上記の処理を通過したら、今度はツイートを1行ごとに分割し、各行ごとに正規化処理を行います。
- ストップワードを含む行はスキップ
- 半角文字を全角に統一
- 全角スペースの置換
- 箇条書きの文頭記号などの除去
- カギカッコの除去
- 絵文字の除去
前処理の実装
前処理に伴う一連の操作や正規表現のパターンは、全て前処理用の自前クラス「Preprocessor」にまとめて実装しました。特に、正規表現の部分は トライ&エラーで何度もテストしながら地道にパターンを洗い出し ており、だいぶアナログな実装となっています。もっと冴えたやり方があるかと思いますので、ぜひアドバイス頂ければ幸いです。正規表現の書き方もだいぶ適当なので、書き方を見直せばマッチングコストをもっと改善できるかもしれません汗
# ノイズ除去やストップワードの除去などの前処理
import re
from pymongo import MongoClient
import unicodedata
import emoji
class Preprocessor:
def __init__(self):
# ストップワード:含まれていたらツイートごと集計対象から除外
self.stop_patter = re.compile( r'(^RT|絶賛上映中)' )
# リムーブワード:対象ワードはツイート中から取り除く
# ハッシュタグ、URL等
self.remove_patter = re.compile(r'#(\w+)|(https?://t.co/\w+)')
# スキップする行
self.skip_patter = re.compile(r'^次点')
# 箇条書き等の文頭記号パターン
self.symbol_patters = [
re.compile( r'^( |\t)+' ),
re.compile( r'^\d+(\.|:|:| | |、|,|位|\))?( )?' ),
re.compile( r'^(\.|・|⚫︎|○|□|■|△|▽|▼|▲|◆|◎|◇|●|▶|▷|★|☆|◀|◁|⚪︎|、)( )?' ),
re.compile( r'^(➀|➁|➂|➃|➄|➅|➆|➇|➈|①|②|③|④|⑤|⑥|⑦|⑧|⑨|⑩|❶|❷|❸|❹|❺|❻|❼|❽|❾|❿|⓫|⓬|⓭|➊|➋|➌|➍|➎|➏|➐|➑|➒|➓|⓵|⓶|⓷|⓸|⓹|⓺|⓻|⓼|⓽|⓾)(\.|:|:| | |、|,|位|\))?')
]
# 括弧の除去パターン
self.brackets_patter = re.compile( r'^(『|「|【|\"|“|\()(.*)(』|】|」|”|\"|\))$' )
# 無効ツイートのスキップ判定
def is_skip( self, tweet ):
return True if ( self.stop_patter.match( tweet ) or len(tweet) < 50 ) else False
# ハッシュタグやURLなどのノイズ成分除去
def remove_noise( self, tweet ):
return self.remove_patter.sub('', tweet )
# 文の正規化
def normalization( self, line ):
# スキップ判定
if self.skip_patter.match(line):return ''
# 半角文字を全角に変換
line = unicodedata.normalize('NFKC', line)
# 全角スペースを置換
line = line.replace(' ', ' ')
# 箇条書きの記号を削除
for patter in self.symbol_patters:
line = patter.sub('', line)
# かぎかっこパターンを削除
if self.brackets_patter.match(line):
m = self.brackets_patter.search( line )
line = m.group(2)
# 絵文字の削除
return ''.join(c for c in line if c not in emoji.UNICODE_EMOJI)
Step2.入力のハッシュ化
Step1で一連の前処理を適用したら、前処理済みのツイート及びその各行文字列をハッシュに格納していきます。ハッシュに格納する目的は、タイトル判定の回数を削減するためです。Twitter上の表記は確かに非常に曖昧ですが、とはいえ全く同じ表記パターンも多数存在します。ハッシュ化することで頻出表現をユニークなパターンとして圧縮することができ、タイトル判定処理の反復回数が減らせます(下図)
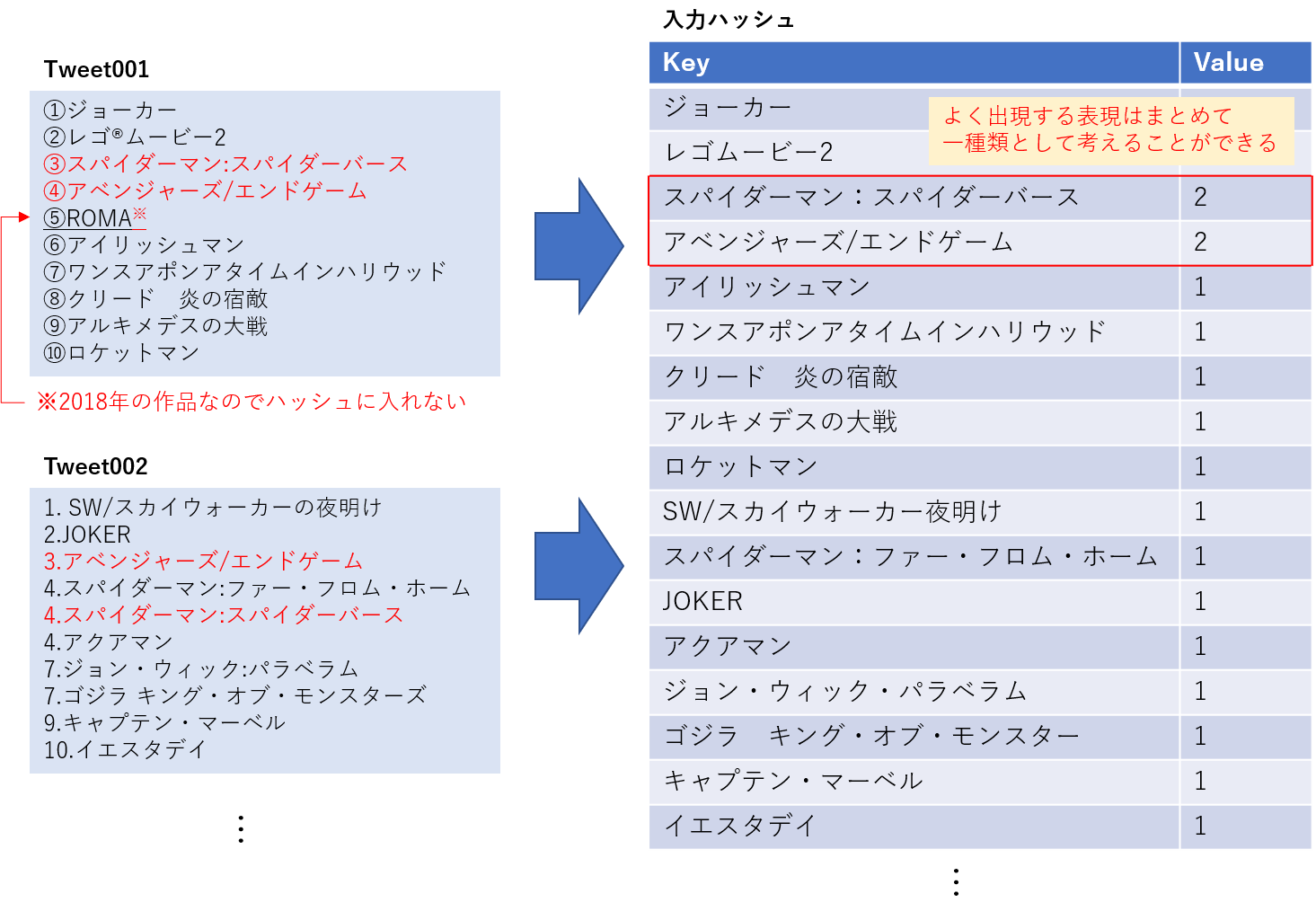
実装としては、特に工夫も無くただ連想配列にぶっ込んでいますが、より大規模なデータセットになると使えないかもしれません。以下、実際に前処理を呼びながら入力ハッシュを生成する部分のサンプルです。※上記の図とはValueの中身が違いますが無視してください。
# 行の正規化と、全入力パターンの取得
# 返り値
# all_lines : 入力行の全パターンハッシュ(Key:1行文字列, Val:None)
# normalize_tweets : 正規化後のツイート保持用
# (Key: ツイートID, Val:正規化後のツイート)
def get_all_lines():
global find_limit
docs = get_docs() # 今回解析対象となる全ツイートのデータセット
pp = Preprocessor() # 共通前処理クラス
# 返り値
all_lines = {} # 全入力パターンの連想配列
normalized_tweets = {} # 正規化後のツイートの保持
# 進捗表示用カウンタ
doc_count = 0
doc_max = str( docs.count( True ) )
for doc in docs:
# ツイート本文取得
tweet = doc['text'] if 'text' in doc else doc['full_text']
# ツイートのスキップ判定とノイズ除去
if pp.is_skip(tweet):continue
tweet = pp.remove_noise( tweet )
# ツイートを1行ごとに分解
normalized_lines = []
lines = tweet.split('\n')
for line in lines:
# 文の正規化
line = pp.normalization(line)
normalized_lines.append(line)
# 全入力パターン辞書に記録
all_lines[line] = None
#正規化後のツイートを保持
normalized_tweets[ doc['id'] ] = normalized_lines
# 進捗カウンタ更新
doc_count += 1
sys.stdout.write('\rdoc {}/{}'.format( doc_count, doc_max))
return ( all_lines, normalized_tweets)
Step3.タイトル判定
ここが今回の最もキモとなる部分で、ツイートを分解して抽出したタイトル表記文字列を、自前で構築した映画DBの公式タイトルとマッチングしていきます。表記ゆれや略称をどう公式タイトルと結びつけていくかがポイントです。例えば、 Twitter上の表記と公式タイトルでギャップがある例 としては以下のようなものがあります。これらのギャップを、なるべく変換ルールを手書きすることなく、自動で吸収していけるかがポイントです。
Twitter上の表記と公式タイトルのギャップが有る例
| Twitter上の表記 | 正式タイトル |
|---|---|
| スパイダーマンFFH | スパイダーマン:ファー・フロム・ホーム |
| アベンジャーズEG | アベンジャーズ/エンドゲーム |
| ワンハリ | ワンス・アポン・ア・タイム・イン・ハリウッド |
| ゴジラKOM | ゴジラ キング・オブ・モンスターズ |
アルファベット略称への対策(メタ辞書によるキーワード置換)
上記の例で、例えば「FFH = ファー・フロム・ホーム」のようにアルファベットによる略称が使われるものに関しては、さほどパターンが多くないので、置換パターンとして定義してしまいます。以下のようなイメージです。
# アルファベットによる略語対策
# Keyの文字列があったらValueで置換する(正式タイトルとの類似度上げる)
reprace_words = {
'FFH': 'ファー・フロム・ホーム',
'KoM':'キング・オブ・モンスターズ',
'KOM':'キング・オブ・モンスターズ',
'KotM':'キング・オブ・モンスターズ',
'king of the monsters':'キング・オブ・モンスターズ',
'新宿PE':'新宿プライベート・アイズ',
'FFXIV':'ファイナルファンタジーXIV',
'FF14':'ファイナルファンタジーXIV',
'MIB':'メン・イン・ブラック',
'GODZILLA':'ゴジラ',
}
その他の略称やサブタイトル割愛への対策(独自変換ルールの定義)
やっかいなのが、 サブタイトルを省略 したり、独自の略称 で表記されている場合です。こちらは大事な情報が欠落しており、独自にマッチングルールを定義していくしかありませんでした。 何度もトライ&エラーを繰返しながら地道に手動で定義 していきましたが、かなり大変だったのでもうあまりやりたくないです。ここの自動化や効率化が大きな課題ですね…。
イメージとしては以下のような具合です。(Keyが正式タイトル、Valueに判定文字列のリストが入っています)
# タイトルの略称やサブタイトル割愛への対策
# マッチングのキーワードをゆるくする
# ※比較的類似度が高い(0.5~0.7)結果に適用(無関係な文章の誤抽出防止)
title_keywords = {
'アリータ:バトル・エンジェル':['アリータ'],
'アベンジャーズ/エンドゲーム':['エンドゲーム','アベンジャーズ','アベンジャーズ EG','アベンジャーズ/EG','アヴェンジャーズ','AVENGERS','ENDGAME'],
'スパイダーマン:スパイダーバース':['スパイダーバース','スパイダーマンITSV'],
'スパイダーマン:ファー・フロム・ホーム':['ファーフロムホーム','ファー・フロム・ホーム'],
'THE GUILTY/ギルティ':['ギルティ','GUILTY','THE GUILTY'],
'LUPIN THE IIIRD 峰不二子の嘘':['峰不二子の嘘'],
'イップ・マン外伝 マスターZ':['マスターZ','イップマン外伝','イップ・マン外伝'],
'サスペリア(2018)':['サスペリア'],
'アラジン(2019)':['アラジン'],
'クリード 炎の宿敵':['クリード','炎の宿敵','クリード2','クリードII'],
'劇場版 ファイナルファンタジーXIV 光のお父さん':['光のお父さん','光のおとうさん'],
'ダンボ(2019)':['ダンボ'],
'劇場版 幼女戦記':['幼女戦記'],
'バーニング 劇場版':['バーニング'],
'パピヨン(2018)':[' パピヨン'],
'名探偵コナン 紺青の拳':['名探偵コナン','紺青の拳'],
'ゴジラ キング・オブ・モンスターズ':['ゴジラ','GODZILLA'],
'劇場版ウルトラマンR/B セレクト!絆のクリスタル':['ウルトラマンR/B','ウルトラマンルーブ','ウルトラマンR/B','ウルトラマンRB'],
'劇場版 響け!ユーフォニアム~誓いのフィナーレ~':['ユーフォニアム'],
'ラブライブ!サンシャイン!!The School Idol Movie Over the Rainbow':['ラブライブ'],
'メン・イン・ブラック:インターナショナル':['MIB','M.I.B'],
'X-MEN:ダーク・フェニックス':['ダークフェニックス','X-MEN DF','ダーク・フェニックス'],
'RBG 最強の85才':['RBG','最強の85'],
'ROMA/ローマ':['ROMA','ローマ'],
'ジュリアン(2017)':['ジュリアン'],
"""
もっともっと大量にありますが割愛します…。
今回は全部で200作品分のルールを定義しました。
"""
}
その他の特別ルール ( 続編やシリーズ物の判別 )
あと地味に面倒くさいのが シリーズもの です。1年のうちに何本かに分けて公開されるもので、アニメ作品に多い傾向がありました。シリーズものの作品はナンバリングタイトルになっているものが多く、それぞれ独自にルールを書かないと判定が困難です。(単語類似度だけでは判定しづらい)
たとえば以下は、劇場版サイコパスのタイトル判定用特別ルールの例です。
# サイコパス劇場版判定
if cls.psycho_pass_patter.search( line , re.IGNORECASE ) :
if re.search(r'Case(\.?)(1|1)', line, re.IGNORECASE ): return 'PSYCHO-PASS サイコパス Sinners of the System Case.1 罪と罰'
if re.search(r'Case\.?(2|2)', line, re.IGNORECASE ): return 'PSYCHO-PASS サイコパスSinners of the System Case.2 First Guardian'
if re.search(r'Case\.?(3|3)', line, re.IGNORECASE ): return 'PSYCHO-PASS サイコパスSinners of the System Case.3 恩讐の彼方に__'
else : return 'PSYCHO-PASS サイコパス Sinners of the System Case.1 罪と罰'
その他だと『劇場版「Fate/stay night [Heaven’s Feel]」II.lost butterfly』と『Fate/kaleid liner Prisma☆Illya プリズマ☆ファンタズム』の判別とか、『劇場版シティーハンター <新宿プライベート・アイズ>』と『シティーハンター THE MOVIE 史上最香のミッション』の判別などなど…。どれも地味に面倒くさかったです。
単語類似度によるタイトルマッチング
どうしても判定が難しいものに関してはメタ辞書のルールを活用しましたが、 基本的には単語類似によるスコアリング でタイトル判定を行っています。タイトルの表記ゆれが強すぎるため、正規表現や単純な文字列一致は今回あまり使えません。
各ツイートを1行ずつ、正式タイトル全987作品とマッチングしていきます。ただし、単語の類似度計算はそれなりに計算コストが有り、これを単純に数万行のループで回すとかなりの計算時間となるため、類似度による判定回数をなるべく減らす方針で設計しました。
具体的には、正式タイトルの連想配列で 一発で変換可能なもの(完全一致しているもの)を最初に判定 したり、判定中に 一定しきい値を超えた場合(高いスコアが出た場合)はその場で反復を打ち切る ようにしています。単語類似度によるタイトル判定部分のサンプルコードは以下になります。
# タイトル判定
def title_macthing( self, line ):
score = -1
# 正式タイトルと完全一致 -> 結果確定で即リターン
# 完全一致時は類似度スコアは1.0で決め打ち
if line in self.title_dic: return ( line, 1.0 )
# タイトル一致度のスコアリング判定
max_score = 0.0 # 最大スコア
candidate = '' # タイトル候補
for title in self.title_dic:
# 類似度スコア計算
score = difflib.SequenceMatcher(None, title, line).ratio()
# MAXスコア更新、タイトル候補の保持
if score > max_score:
max_score = score
candidate = title
# 高スコアが出たら打ち止めして終了
if( max_score >= 0.8 ): break
return ( candidate , max_score )
Step3.5. チューニング
実際にはこの工程に割いた時間が一番多く、非常に泥臭い作業の連続でした。Step1~3までを行うことで、一旦各ツイートに対するタイトル判定結果と、一致スコア(完全一致なら1.0~不一致なら0.0)が得られます。以下のように、スコアリングによる判定がOKだったもの(=集計対象)と、NGだったもの(集計対象外)をそれぞれ中間結果として出力し、誤判定が無いかを目視で細かくチェックしました。
判定OKの中間結果の例
,org,correction,result,score
0,アベンジャーズ / エンドゲーム,,アベンジャーズ/エンドゲーム,0.8666666666666667
1,スパイダーマン:FFH,スパイダーマン:ファー・フロム・ホーム,スパイダーマン:ファー・フロム・ホーム,0.9473684210526315
2,この素晴らしい世界に祝福を!紅伝説,,この素晴らしい世界に祝福を!紅伝説,0.9411764705882353
3,この世界の(さらにいくつもの)片隅に,,この世界の(さらにいくつもの)片隅に,0.8888888888888888
4,スパイダーマン:スパイダーバース,,スパイダーマン:スパイダーバース,0.9375
5,海獣の子供,,海獣の子供,100.0
6,アナと雪の女王2,,アナと雪の女王2,100.0
7,ヒックとドラゴン 聖地への冒険,,ヒックとドラゴン 聖地への冒険,0.9333333333333333
8,プロメア,,プロメア,100.0
9,HELLO WORLD,,HELLO WORLD,100.0
# 以下割愛
判定NGの中間結果の例
,org,correction,result,score
86,発表のFBページはこちら⇒,,僕たちのラストステージ,0.25
87,少年の青春ドラマっぽい映画の雰囲気を醸し出しながら、なんともやりきれない、救いようのない映画、映像キレイだし、雰囲気いいので、ワーストというより、胸糞。2度と観ない。,,あいが、そいで、こい,0.15053763440860216
88,パラサイト 半地下の家族,,パリの家族たち,0.42105263157894735
89,詳細はブログに,,アイ・ビロング,0.2857142857142857
90,すんごく今更だけど。完全に今の気分で好きな映画10本集めた。 ,,ぼくの好きな先生(2019),0.26666666666666666
91,2019年中に観たもの,,楽園(2019),0.42105263157894735
92,ダークナイト,,ダーククライム,0.6153846153846154
93,シンデレラ,,シンクロ・ダンディーズ,0.375
94,スーサイド・スクワッド,,スピード・スクワッド ひき逃げ専門捜査班,0.5806451612903226
95,モアナと冒険の海,,アナと雪の女王2,0.5
96,シュガーラッシュオンライン,,センターライン,0.4
# 以下割愛
上記の結果を見ながら、誤判定や判定漏れしているものについて原因を調査し、潰し込んでいくイメージです。この作業は、そもそも どのタイトルが「今年公開された映画なのか」 を判断するための前提知識や、 Twitter特有の略称 などについても知っておく必要があるため、かなりドメイン知識を求められます。地味ですが、映画好きの本領が発揮できる工程でした。
Step4.タイトル集計
Step1~3をチューニングしながら繰返し、十分な精度が得られたら、 最後のタイトル集計処理 に移ります。この「十分な精度が得られたら」の判断基準ですが、今回は先程の中間結果を目視で確認しながら肌感で判断しています。 「いやそこは定量的に評価しろよ!」 と言われそうですが、 Twitterの投稿や表記そのものが曖昧 な部分もあるため、今回の集計にそこまでの厳密性を求めても意味はないかなとも考えています。 大まかな傾向がつかめればいいな 、くらいの具合です。とはいえ最低でも90~95%以上の精度では判定成功していると思います。
集計処理自体は至極簡単です。Step3までの工程で、全ツイートの各行に対するタイトル変換テーブルが完成していますので、あとはそれぞれの出現回数を連想配列にカウントしていくだけです。最終的な出力結果は以下のようになります。あとはこれをソートすればランキングの完成です。
,title,count
0,ワイルド・ストーム,21
1,ホイットニー~オールウェイズ・ラヴ・ユー~,6
2,ラブライブ!サンシャイン!!The School Idol Movie Over the Rainbow,18
3,シークレット・ヴォイス,17
4,迫り来る嵐,21
5,マイ・ジェネレーション ロンドンをぶっとばせ!,5
6,レッスル!,2
7,22年目の記憶,4
8,クリード 炎の宿敵,392
9,蜘蛛の巣を払う女,25
10,この道,1
…
978,みぽりん,6
979,男はつらいよ お帰り 寅さん,41
980,だれもが愛しいチャンピオン,5
981,劇場版 新幹線変形ロボ シンカリオン 未来からきた神速のALFA-X,17
982,尾崎豊を探して,0
983,ヘヴィ・トリップ/俺たち崖っぷち北欧メタル!,42
984,燃えよスーリヤ!!,2
985,死霊の盆踊り HDリマスター版,2
986,今日もどこかで馬は生まれる,1
全体の結果と考察など
今回は、12月15日~1月15日までにつぶやかれたツイートを対象に、全部で5550ツイート分のタイトルを集計することができました。その結果についてはTwitterやnoteにも細かくまとめていますので、映画好きな方はぜひそちらもご覧ください。狙い通り、一般の興行収入ランキングや一般映画サイトの満足度ランキングとは異なる興味深い結果が得られました。いかにも「Twitterらしい」濃い感じがよく出ていて、個人的にもかなり満足しています。
【結果のダイジェスト版】
お待たせしました。「 #2019年映画ベスト10 」集計結果発表です!今回は合計5,550ツイートを集計!昨年最も多くの映画クラスタがベスト10に選んだ作品は、あのアメコミ映画でした…!まずはベスト100位までの作品をどうぞ。今回も素敵なデザイン協力:映女さん( @movie0girl ) pic.twitter.com/THheqhh8Jr
— マロン (@kurikou02) January 20, 2020
【結果の詳細と考察記事】
「#2019年映画ベスト10」でつぶやかれた作品を集計してみた結果と考察【詳細版】|マロン @kurikou02 #note
https://note.com/kurikou02/n/n7d117cfdaa32
まとめ
毎年Twitterで盛り上がる年間ベストタグの全体数や結果の傾向が気になり、ふと思い立ってはじめた取り組みでしたが、Twitter APIの使い方やWebスクレイピング、MongoDBの活用や、Twitterのテキストを対象にした言語処理等、様々な要素技術に触れることが出来て大変良い勉強になりました。記載したサンプルコード等、色々不備やツッコミどころがあるかと思いますので、お気軽にコメント/アドバイス頂ければ幸いです。
今後の課題としては、処理の高速化と、今回人手でゴリゴリ書いたメタ辞書作成の効率化/自動化ですね。Twitterの特性上どうしてもドメイン知識は必須になると思いますが、人手でルールを書く部分のコストをもっと減らしていきたいと思います。
年間ベストのタグはTwitter映画クラスタの間では毎年の恒例行事となってきているので、もし来年もあれば引き続きチャレンジしてみたいと思います。また、映画関連の公開データベースや、統一的な情報源についてなにか知識をお持ち方はご教示いただけると幸いです。
以上です。長文にも関わらずここまで読んで頂き、本当にありがとうございます。
(全部を1記事にまとめたら大変なボリュームになってしまいました。次回からは分けて書こうかな…。)
参考ページ
スタバのTwitterデータをpythonで大量に取得し、データ分析を試みる その1
Python Webスクレイピング テクニック集「取得できない値は無い」JavaScript対応@追記あり6/12
正規表現のパフォーマンスの話をされても全くピンと来なかった僕は、backtrackに出会いました。
MongoDB インデックス概要