はじめに
みなさん、こんにちは。
株式会社キカガクの機械学習講師 藏野です。
キカガクは、「AI を含めた先端技術の研修」を行っている会社です。
この記事は、「Web スクレイピングで特定のデータを取得して CSV で出力」までの実務的な内容を取り扱います。
スクレイピングの記事は多くありますが、活用を見据えてデータを取得し保存するところまで取り組みたいという方は、ぜひ参考にされてください。
この記事は、Python を活用しながら Web サイトのデータ収集を効率化(1)【環境構築編】の続きとなっています。
必ず読む必要はありませんが、スクレイピングの仕組みを復習したい方は一読をオススメします。
目次
- スクレイピングの手法
- 環境構築
- 実践
- おわりに
- お知らせ
Web スクレイピングの手法
スクレイピングには、以下の 2 つの手法があります。
- Selenium を使用して、ブラウザを自動操作することでデータを取得する手法
- Beautiful Soup という Python パッケージを使用して、データを取得する手法
各手法の特徴として、Selenium はデータ取得とログイン処理などのブラウザ自動操作を行うことができ、 Beautiful Soup は HTML を解析してデータ取得を行うことができます。
スクレイピングを行うには両方の手法を扱えること理想ですが、今回は Selenium を使用してスクレイピングを行います。
環境構築
環境構築は、はじめに共有したこちらと同じなので、細かい説明は割愛します。
- ブラウザ:Google Chrome
- 実行環境:Google Colaboratory(以下 Colab )
パッケージのインストール
Colab でノートブックを作成後に、Selenium と WebDriver( ChromeDriver )をインストールしてインポートまで行います。
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver/usr/bin
!pip install selenium
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
browser = webdriver.Chrome('chromedriver',options=options)
Headless モード
Selenium は、ブラウザの自動操作を行うことができるので、自動操作用のブラウザを立ち上げて様々な処理を行います。
流れとしては、webdriver.Chrome()でブラウザを立ち上げて、browserという変数に格納し、この browserに対して、メソッドを使用していきます。
通常モードでは、webdriver.Chrome()を実行後に別ウィンドウでブラウザが立ち上がります。
Headless モードは、この自動で立ち上がるブラウザを非表示の状態でコードを実行していくことを意味します。
通常モードの場合は、以下の Gif を参考にしてください。
「ブラウザの立ち上げ > Google にアクセス > 株式会社キカガクを自動入力 > ブラウザを閉じる」 までの処理を行っています。

確認
最後に環境構築ができているか、下記のコードを実行して確認します。私と同じようにソースコードが取得できていれば問題ありません。
browser.get('https://scraping-for-beginner.herokuapp.com/')
print(browser.page_source)

確認ができたら、ブラウザを閉じることを忘れないようにしましょう。
browser.quit()
実践
環境構築ができたので、こちらの Web サイトでスクレイピングを行っていきましょう。
※ 本サイトは、サイトの所有者に事前に許可を得てアクセスしておりますので、皆様も安心してご使用いただけます。
ただし、繰り返しアクセスをしてしまうとサイトに負荷がかかってしまうため、アクセスのしすぎにはご注意ください。
実装の流れ
実装は、以下の3つの流れで行います。
- サイトの構成を把握
- 特定のデータを取得
- CSVファイルで出力
ここでは、抽象的に挙げましたが各章で詳しく解説していくので、今はイメージを持つだけで問題ありません。
1. サイトの構成を把握
環境構築ができたので、すぐにスクレイピングを行いたいところですが、まずはサイトの構成を把握するところから行いましょう。
理由としては、作業が途中で進まなくなったり非効率な順番でデータを取得してします可能性があるからです。
このようなことを避ける為にも、一番始めにサイトの構成をしっかりと把握しておきます。
それでは、先ほどのサイトのトップページから構成を確認していきます。(https://scraping-for-beginner.herokuapp.com/)

更に細かく分けることはできると思いますが、今回は 4 つに分けて考えていきます。
① ヘッダー
② ページ内リンク
③ メインテキスト
④ ページ内リンクボタン
ページ内リンクがあることがわかったので、 ④ のランキングボタンをクリックしてみます。
クリック後は、「観光地ランキングのページ」に遷移していることがわかりました。
それではこのページの構成も確認していきたいと思います。

① 現在のURL:https://scraping-for-beginner.herokuapp.com/ranking/
② ヘッダー
③ タイトル
④ ランキング + 観光地名
⑤ 総合評価( 5 段階)
⑥ 詳細の評価とコメント
ランキングページは、情報量が多く細かい構成になっていることがわかります。ですが、このように事前に構成を確認することで、どのデータが取得できるかを把握することができます。
2. 特定のデータを取得
サイトの構成を把握が把握できたので、本題のスクレイピングを行います。
今回は、「観光地名・ 総合評価」の 2 つの要素を取得したいと思います。
要素を指定する場合には、HTML で対応付けされている属性( id や class )をデベロッパーツールで確認する必要があります。
デベロッパーツールは Google Chrome のデバッグツールで、 Web サイトの HTML 構成や表示スピードなどを確認できます。
「右クリック > 検証」もしくは、「ブラウザのメニュー > その他のツール > デベロッパーツール」で開くことができます。

観光地名を取得
まずは、トップページにアクセスが必要です。
Selenium はブラウザの自動操作ができるので、トップページにアクセスしてランキングボタンをクリックしてもいいですが、ランキングページの URL がわかっているので、今回は直接アクセスしましょう。
アクセスするためには、webdriver.Chrome オブジェクトを生成して、browser.get() の引数に URL を渡すことでアクセスできます。その URL のソースコードを print() で表示させます。
先ほどブラウザを閉じているので、立ち上げるところから始めていきます。
# ヘッドレスモードでオブジェクト生成
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
browser = webdriver.Chrome('chromedriver',options=options)
# urlを変数に格納
url = 'https://scraping-for-beginner.herokuapp.com/ranking/'
# アクセス
browser.get(url)
print(browser.page_source)

ソースコードが出力されてアクセスできたことが確認できたので、「観光地 1」という観光地名を取得していきます。
デベロッパーツールを開き、 ① をクリックすると要素を選択できるようになります。今回は観光地名の属性を確認したいので ② 付近をクリックすると、③ で属性を確認することができます。
観光地 1 は、class 名が u_title の div タグ内に記述されていることがわかりました。

browser.find_element_by_class_name() を使用して u_title クラス内の要素を取得します。
name_elem = browser.find_element_by_class_name('u_title')
name_elem.text

中身を確認すると、「ランキング\n観光地名」で格納されているので、split() を使用して観光地名のみを取得します。
elem = name_elem.text.split('\n')
print(elem)
elem = elem[1]
print(elem)
# elem = name_elem.text.split('\n')[1] ←1行でも書けます

elem を確認すると、観光地名のみを取得できていることが確認できました。
次は複数の観光地名を取得していきます。
同じ class 名の要素を複数取得する場合には、browser.find_elements_by_class_name( ) のように複数形(elements)を使用します。
elems = browser.find_elements_by_class_name('u_title')
print(len(elems))

elems[0].text

先ほどと同じ用に、観光地名のみを取得します。
name_elems = []
for e in elems:
name_elems.append(e.text.split('\n')[1])
# name_elem = [e.text.split('\n')[1] for e in elems] ←1行でも書けます
print(name_elems)

ページ内の 10 件の観光地名を取得することができました。
総合評価
次に総合評価を取得していきます。先ほどと同じように、デベロッパーツールを使用して確認します。
総合評価は、 class 名が u_rankBox の div タグ内に記述されていることがわかります。

それでは、取得していきましょう。取得方法は先ほどと同じなので、できる方はこれまでのコードを参考に自分で挑戦してみてください。
evl_elem = browser.find_element_by_class_name('u_rankBox')
evl_elem.text
総合評価が取得できていることが確認できたので、複数取得していきます。
elems = browser.find_elements_by_class_name('u_rankBox')
print(len(elems))

観光地名と同じように 10 件取得できました。あとは、for 文で各要素のテキストを取得します。
evl_elems = [e.text for e in elems]
print(evl_elems)

これで 2 つの要素は取得できたので、browser を閉じます。
browser.quit()
【補足】ランキングボタンをクリック
今回はランキングページに直接アクセスしましたが、Selenium はブラウザを自動操作することができるので、トップページのランキングボタンをクリックしてページ遷移後にデータを取得することもできます。
まずは、トップページへアクセスをします。クリック後に遷移できているかを確認したいので現在の URL を出力しておきます。
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
browser = webdriver.Chrome('chromedriver',options=options)
# urlを変数に格納
url = 'https://scraping-for-beginner.herokuapp.com/'
# アクセス
browser.get(url)
# 現在のURLを確認
print(browser.current_url)

ランキングボタンは、これまでと同じようにデベロッパーツールで確認すると、 id 名が card-action の div タグ内の a タグで記述されていることがわかります。
ランキングボタンクリックの流れは、以下の通りです。
- 要素を指定
- インデックスを指定
- クリック
elem = browser.find_element_by_id('card-action')
buttons = elem.find_elements_by_tag_name('a')
print(len(buttons))

a タグが3つあるので、要素数も3と出力されています。
a タグには属性が無いので、インデックスでランキング要素を指定してクリックします。
buttons[1].click()
# 現在のURLを確認
print(browser.current_url)

URL がランキングページの URL と一致しているので、クリックできていることが確認できました。
3. CSV ファイルで出力
最後に取得したデータを CSV 形式で出力していきます。スクレイピングとは関係はありませんが、実務の場合はデータを取得して保存しておかないとデータを利用できないので、CSV 形式で出力していきます。
まずは、Python パッケージの Pandas を使用して、各データを DataFrame に格納します。
import pandas as pd
# カラムを定義
columns = ['観光地名', '総合評価']
# DataFrameを作成
df = pd.DataFrame(columns=columns)
# 確認
df
各データが格納されている変数を df に格納して、中身の確認をします。
df['観光地名'] = name_elems
df['総合評価'] = evl_elems
# 上位3件を確認
df.head(3)

確認もできたので、CSV 形式で出力をします。
df.to_csv('sample.csv')
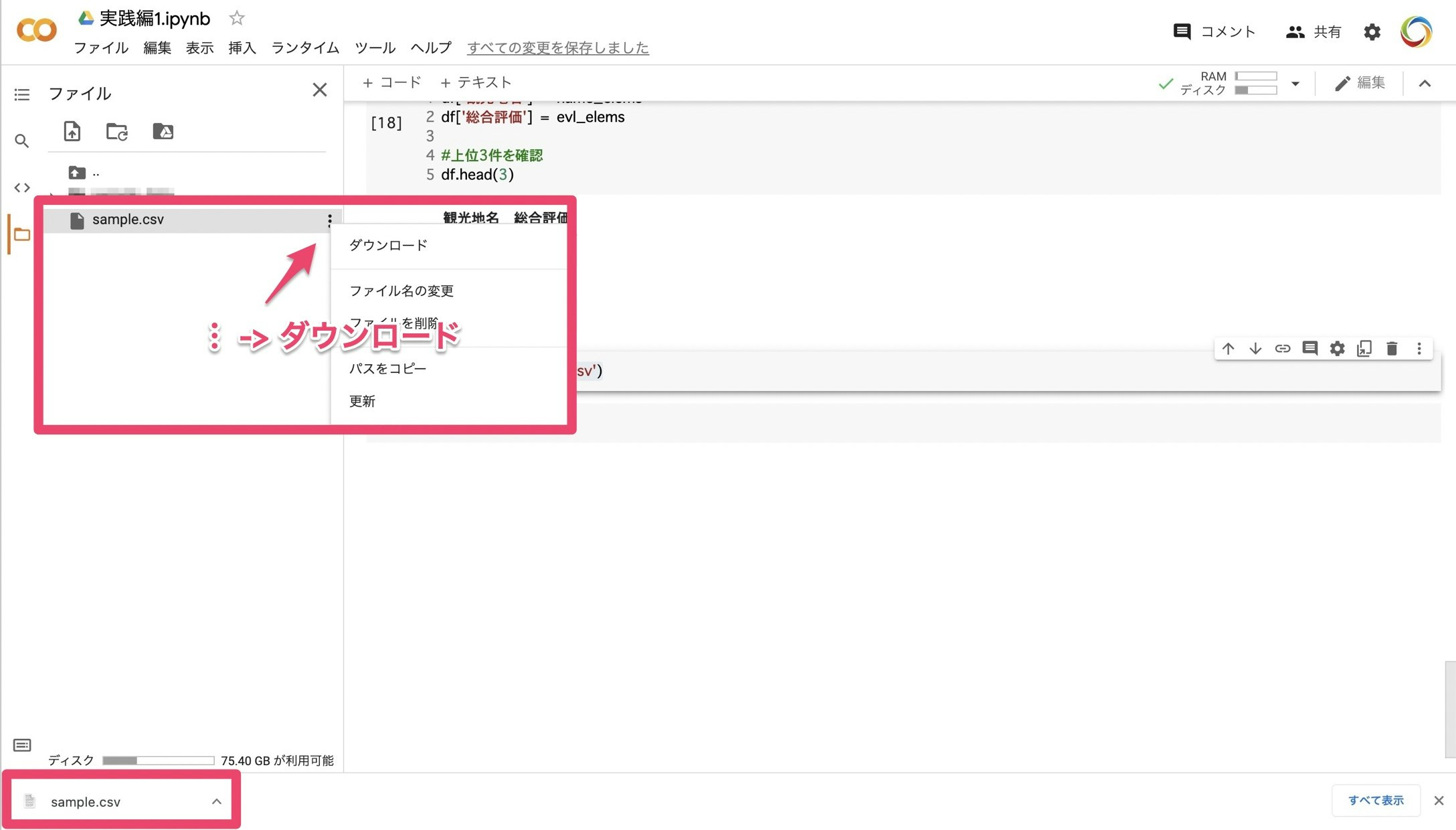
コードを実行すると、サイドバーに sample.csv が作成できていることがわかります。

作成ができたら、 サイドバーの sample.csv にカーソルを合わせて、︙ -> ダウンロードをクリックすると CSV ファイルがダウンロードされます。
おわりに
このように、簡単にスクレイピングから CSV 形式で出力まで行うことができました。
スクレイピングと聞くと難しいイメージを持ちますが、実際のコードを書いてみると似たようなコードが多く覚えることも少ないと思います。
次回の記事では、ログイン処理やタイムアウトなどの処理も含めたデータの取得をやっていきましょう!
お知らせ

動画を通じて、ディープラーニングが一から学習できる大人気コースの脱ブラックボックスが無料になりました。
手書きの数学とハンズオン形式のプログラミングによって、初学者でも安心して一から学習できます。
機械学習やディープラーニングを基礎から実践を学びたい方は、ぜひ教材の1つとしてご利用ください!