Web スクレイピングで Python の勉強がもっと楽しくなる!
みなさん、こんにちは。
株式会社キカガクの機械学習講師 二ノ宮です。
突然ですが、初めて Python を学習をしているこんなことを感じませんか?
「if 文や for 文など基本的な文法は学んだが、実際にどうやって活用していけばいいのかわからない」
語学の勉強で考えるとわかりやすいですが、基礎的な文法と実際に学んだことを活用していくシーンが紐付いていないと、学んでもどこに応用できるのかがわからず、使える知識になっていきません。
このような状況ですと、身につけた知識で具体的にできることのイメージがわかない→プログラミング学習が楽しくない→勉強しなくなるという悪循環にハマってしまいます。
そこで、 Web スクレイピングという手法で Web サイトのデータを効率的に取得する実践的な Python の活用法を複数回に分けて紹介していきます。
今回の記事の最後では、実際に特定のサイトのソースコードを取得してくるところまで扱うので、お楽しみにしていてください。
※ サイトからソースコードを取得しているデモ
本記事は、以下のような読者を対象にしています。
・Python 文法を一通り学んでみたが、その知識をどこに活用していくかイメージがつかない方
・他のプログラミング言語をやってみたことがあり、Python も学んでみたいと思っている方
・スクレイピングをやってみたい方
いずれかに該当する方が、実際に手を動かしながら本連載を読み終わっているころには、Python を使ったプログラミングが楽しい!と感じる状態になっているはずです。
※ 基礎的な Python の文法を学んでから取り組みたいという方は、後日公開されます「Python 基礎文法編」の記事をご参照しながら、本記事を読んでいただければ幸いです。
目次
1.「Web スクレイピング」を使った Web データ収集の仕組み
2. 全体の流れ
3. 事前準備
4. 環境構築
5. まとめ
6. 参考
1. 「Web スクレイピング」を使った Web データ収集の仕組み
タイトルにいきなり**「スクレイピング」**という言葉がでてきましたが、警戒する必要はありません。
簡単に言うと、スクレイピングとは、任意の Web サイトからデータを自動的に取得していくことを表します。
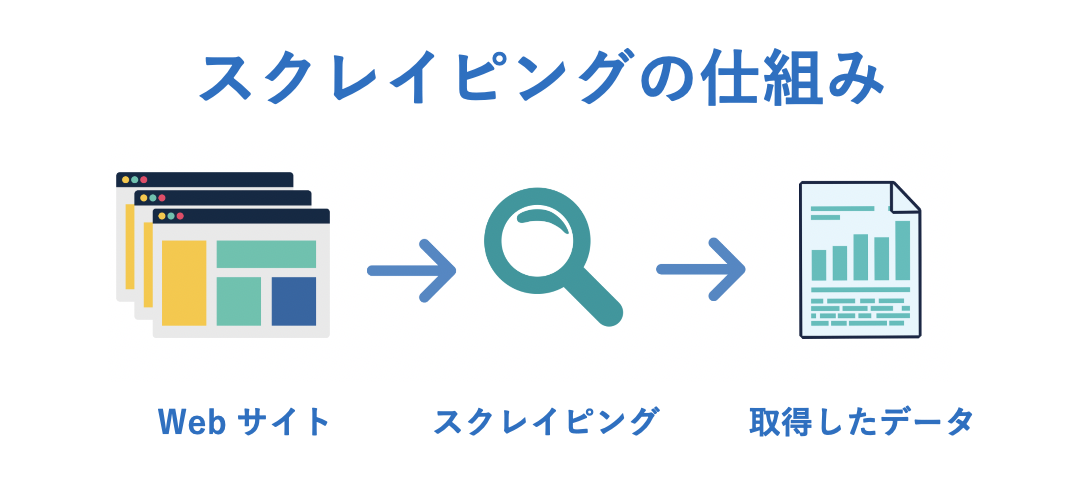
スクレイピングを行うことで例えば、次のことができるようになります。
- 世界中のトレンドを可視化するために、ニュースサイトから注目ランキング上位のニュースのデータを取得
- 株価予測をするために、株価を公開している Web サイトから株価情報を取得
- 特定の芸能人の画像を集めるために、SNS にログインし全ての画像を自動で取得
また、機械学習のシステムを構築する際も、最初にモデルをつくるためのデータが必要です。
確かに手動で Web 上のデータをコピー & ペーストとしていくことで、情報を取得していくことができますが、非常に手間と時間がかかってしまいます。
そこで、スクレイピングを使うことで、Web データの取得における手間を効率化することが可能になります。
このように Python だけではなく、今後、機械学習を使ってデータの予測をしてみたい方は、これを機に Web 上でのデータを収集するスクレイピング力を身に着けていただければと思います。
※補足:スクレイピング以外の手法として、Web API を利用することで Web サービスが保有しているデータを外部から利用することも可能です。
注意事項
なお、スクレイピングをする際は、必ず Web サイトからデータを取得してよいかどうかの確認をしてください。
詳しくはこちらをご参照ください。
▶ Web スクレイピングの注意事項一覧
2. 全体の流れ
それでは、さっそくコーディングをしていく前に全体像を把握しておきましょう。
スクレイピングをするためには、Selenium というブラウザの操作を自動化するパッケージを使います。
Selenium を使うことで、入力ボックスにチェックをいれることや、特定のサイトにアクセスが可能になるため、定期的に特定の Web ページから画像やテキストデータといった情報を取得する用途で使われる場合があります。
この Selenium を含めたパッケージを使ってスクレイピングをするには、大きく分けて以下の 4 つのステップがあります。
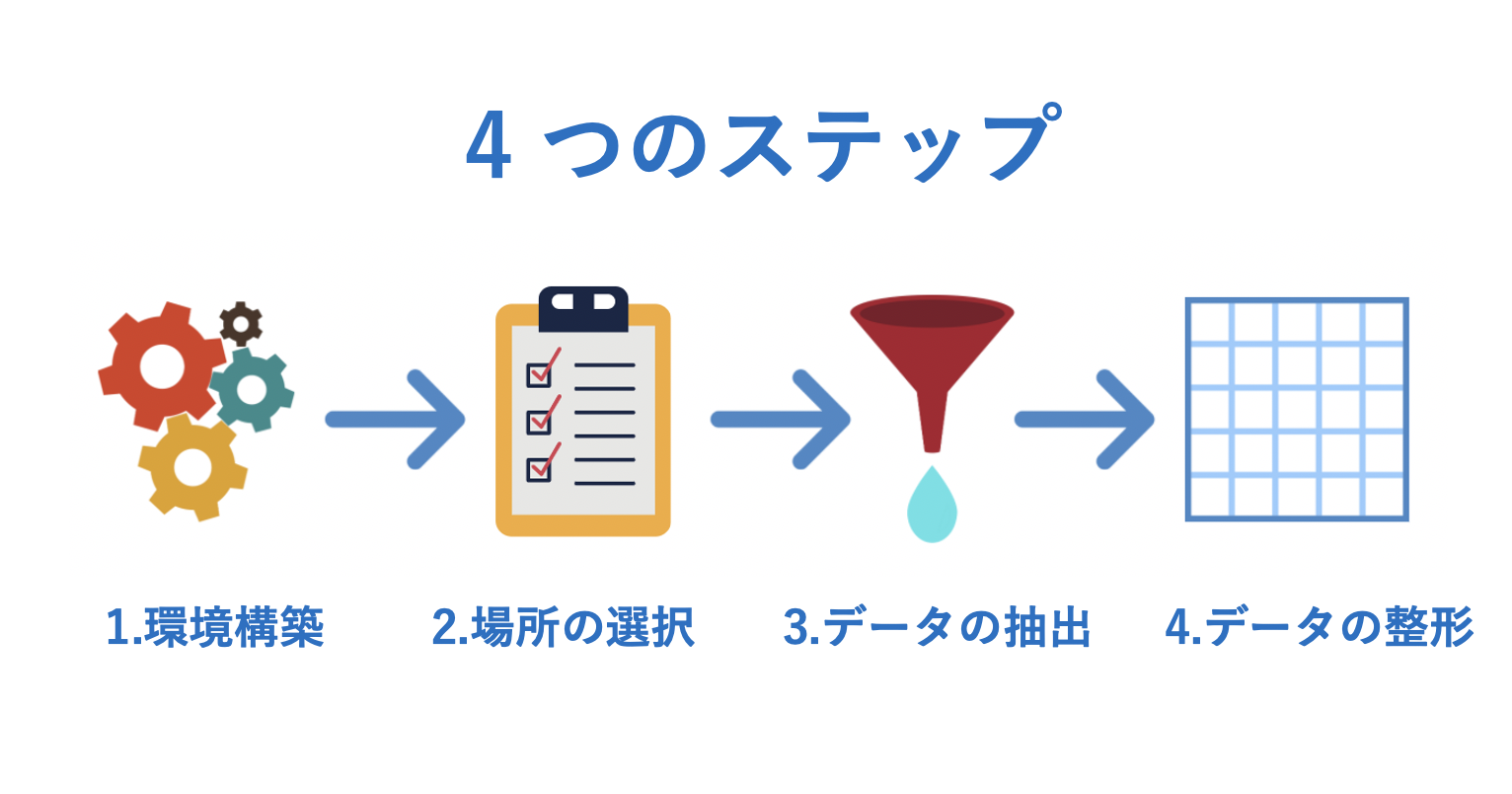
1. 環境構築
Selenium を使用するために必要な環境を準備します。
2. 場所の選択
「どこのサイト」の「どの部分」を抽出するのかを選択します。
データを取得する範囲を絞ることは後のデータの整形という部分の工程が楽になるというメリットがあります。
3. データの抽出
どの Web サイトのどこのデータをスクレイピングをするのかを決めたら、実際にデータを取得します。
4. データの整形
最後に取得したデータを扱えるように、データをきれいに整えていきます。
機械学習用の場合、データセットに活用できるように Pandas や NumPy といったパッケージを使用することが多いです。
まずは、ステップ 1 の環境構築の解説していきます。
3. 事前準備
使用していくものは以下の二点です。
- Google Chrome(デスクトップアプリ)
- Google Colaboratory(Google のサービス)
実行環境としては、 ブラウザから Python を記述、実行できる Google Colaboratory(以下、Colab)を使用します。
Colab は Python の環境構築をする必要がなく、最初から数百の Python パッケージがインストール済となっている非常に便利なツールです。
まずは、以下のサイトにアクセスして、Google アカウントでログインしてください。
▶参考: [Google Colaboratory]
(https://colab.research.google.com/notebooks/welcome.ipynb?hl=ja)
すると、このようなページが開かれます。
次に画面の左上にある「ファイル」というボタンから、「ノートブックの新規作成」をクリックして、今回作業するためのノートブックを作成してください。
ノートブックとは実際にスクレイピングのコーディングをしていく場所のことを指します。
すると、新しいノートブックが開きます。
画面左上に表示されている名前をクリックすれば、ノートブックの名前の変更が可能になります。
ここまででコーディングをするための準備ができました。
詳しい Colab の使用方法は以下の記事をご参照ください。
▶参考:[Google Colaboratory なら Python ですぐに学べる] (https://gammasoft.jp/blog/google-colaboratory-for-learning/)
4. 環境構築
では、さっそくスクレイピング用のパッケージ Selenium をインストールしていきましょう。
Seleniumでは、WebDriver (ChromeDriver) を仲介してブラウザを操作します。
つまり Selenium を使うには WebDriver のインストールが不可欠です。
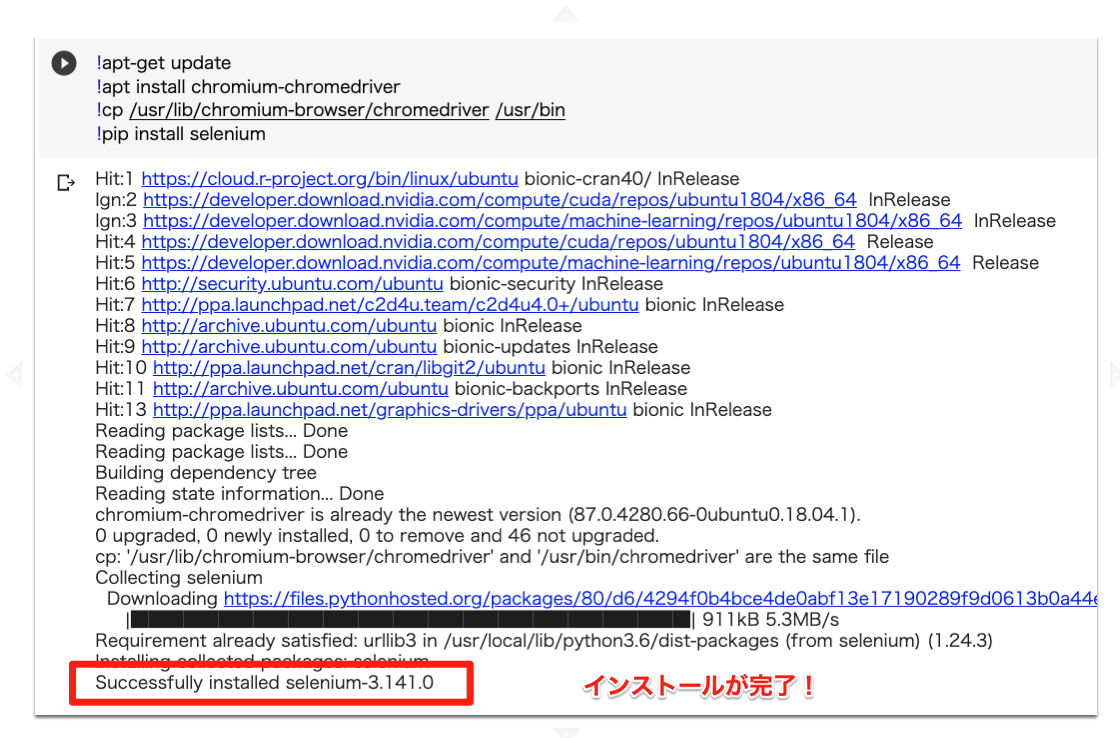
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver/usr/bin
!pip install selenium
すると、このような結果が出力されるかと思います。
次に webdriver と詳細設定の Options をインポートしていきます。
Options は selenium の詳細設定をするものくらいの理解で大丈夫です。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
では、インポートをした Options を使って selenium の詳細設定をしていきます。
Headless モードを始めとした記述内容は、次回の記事で解説いたします。
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
browser = webdriver.Chrome('chromedriver',options=options)
最後に本当に環境構築ができたかどうかをソースコードを取得することで確認してみましょう。
今回は Web スクレイピング用に独自に用意したサイトを使ってスクレイピングをしてみます。
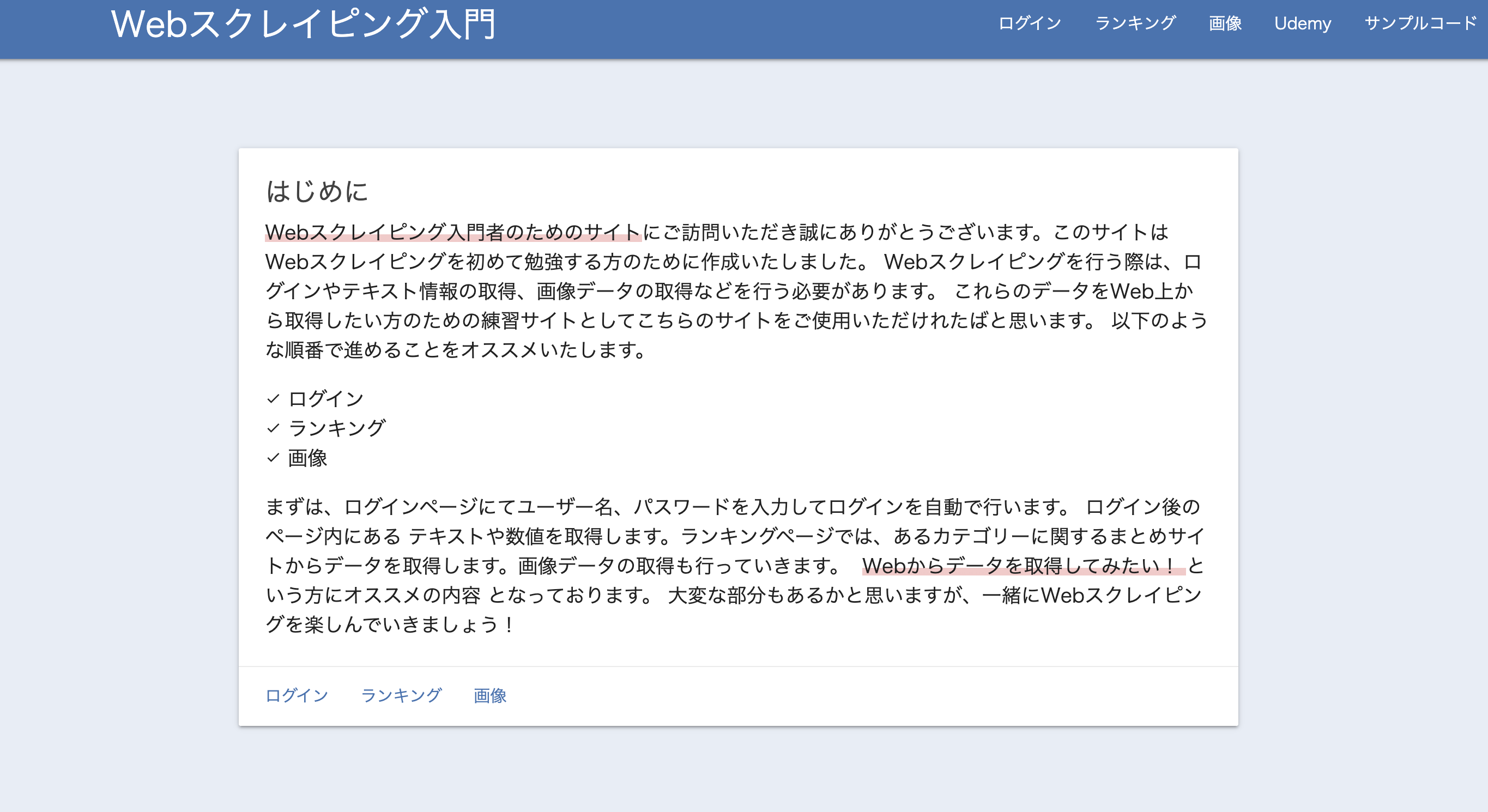
▶Web スクレイピング入門
※ 本サイトは、サイトの所有者に事前に許可を得てアクセスしておりますので、皆様も安心してご使用いただけます。
ただし、繰り返しアクセスをしてしまうとサイトに負荷がかかってしまうため、本記事の内容に沿って挙動を確かめる目的のみでのご使用をお願い致します。
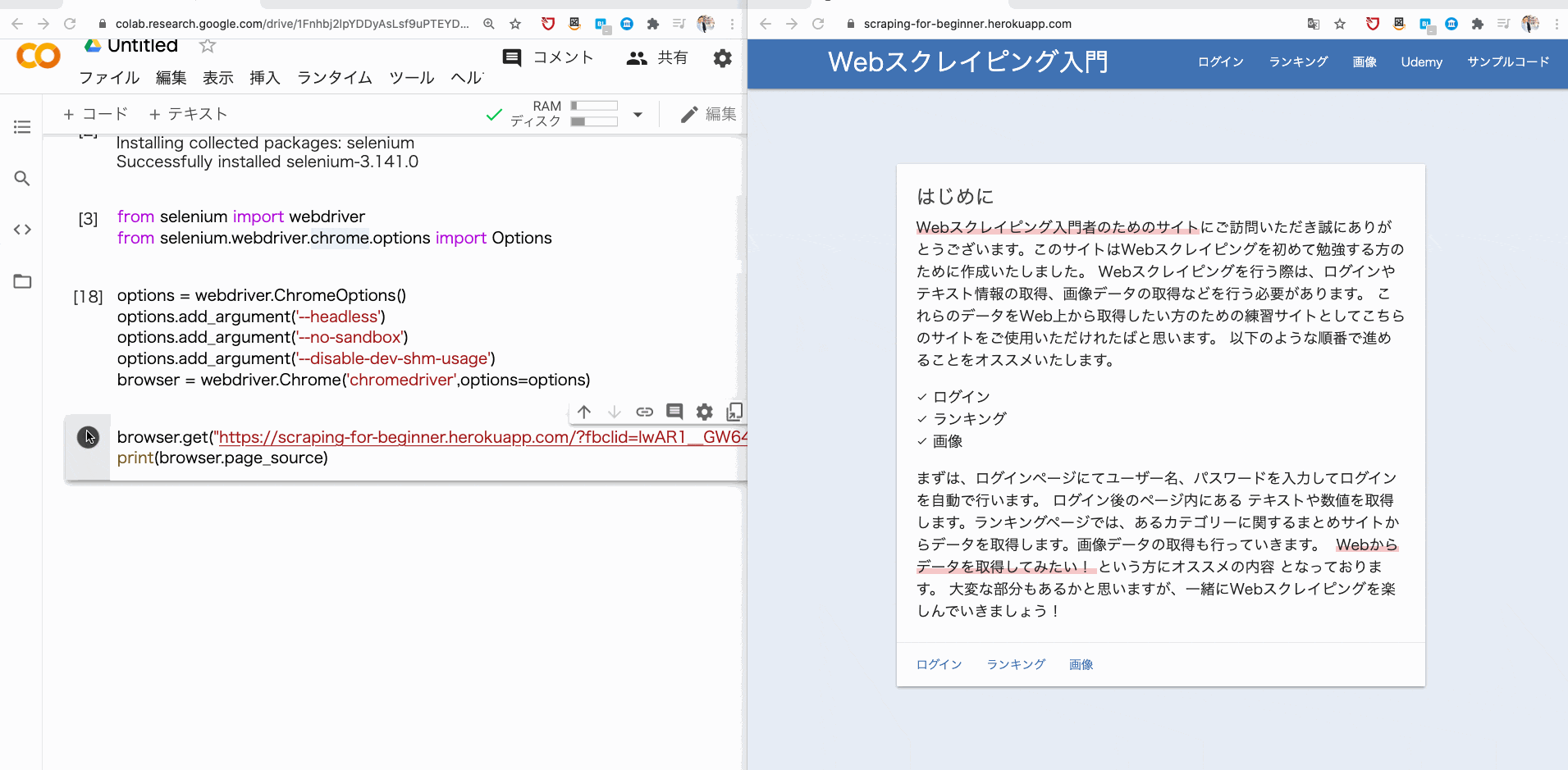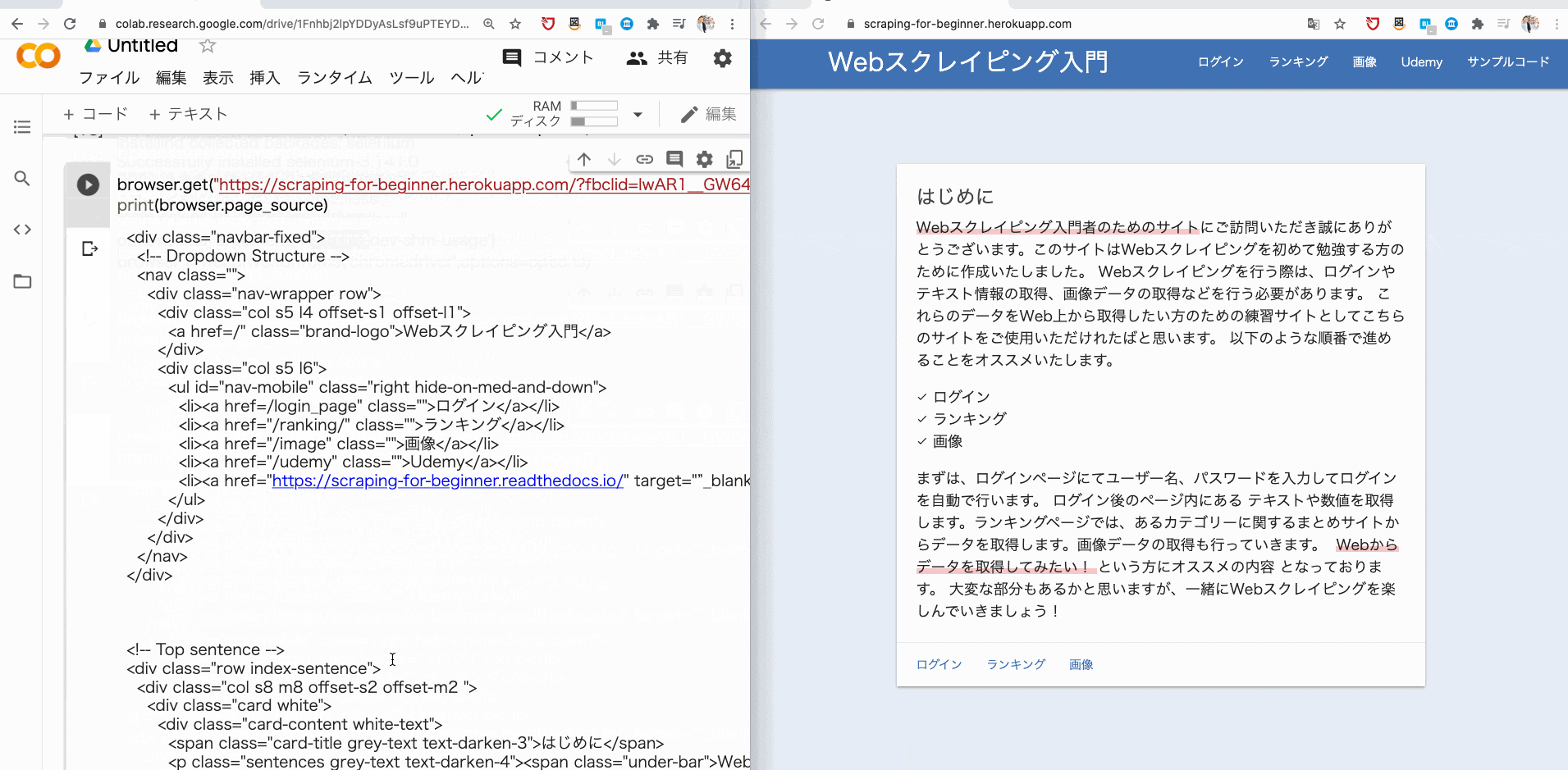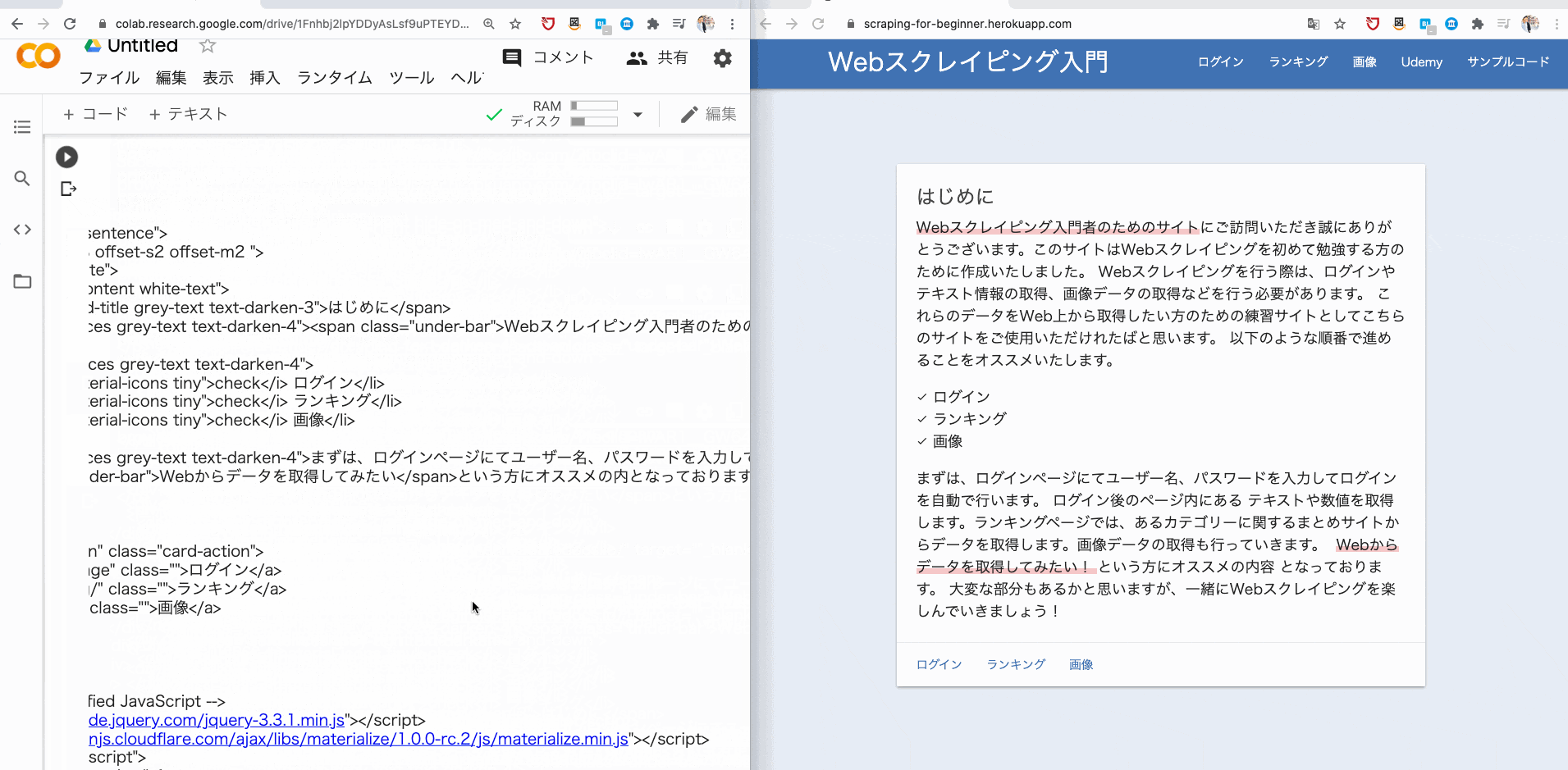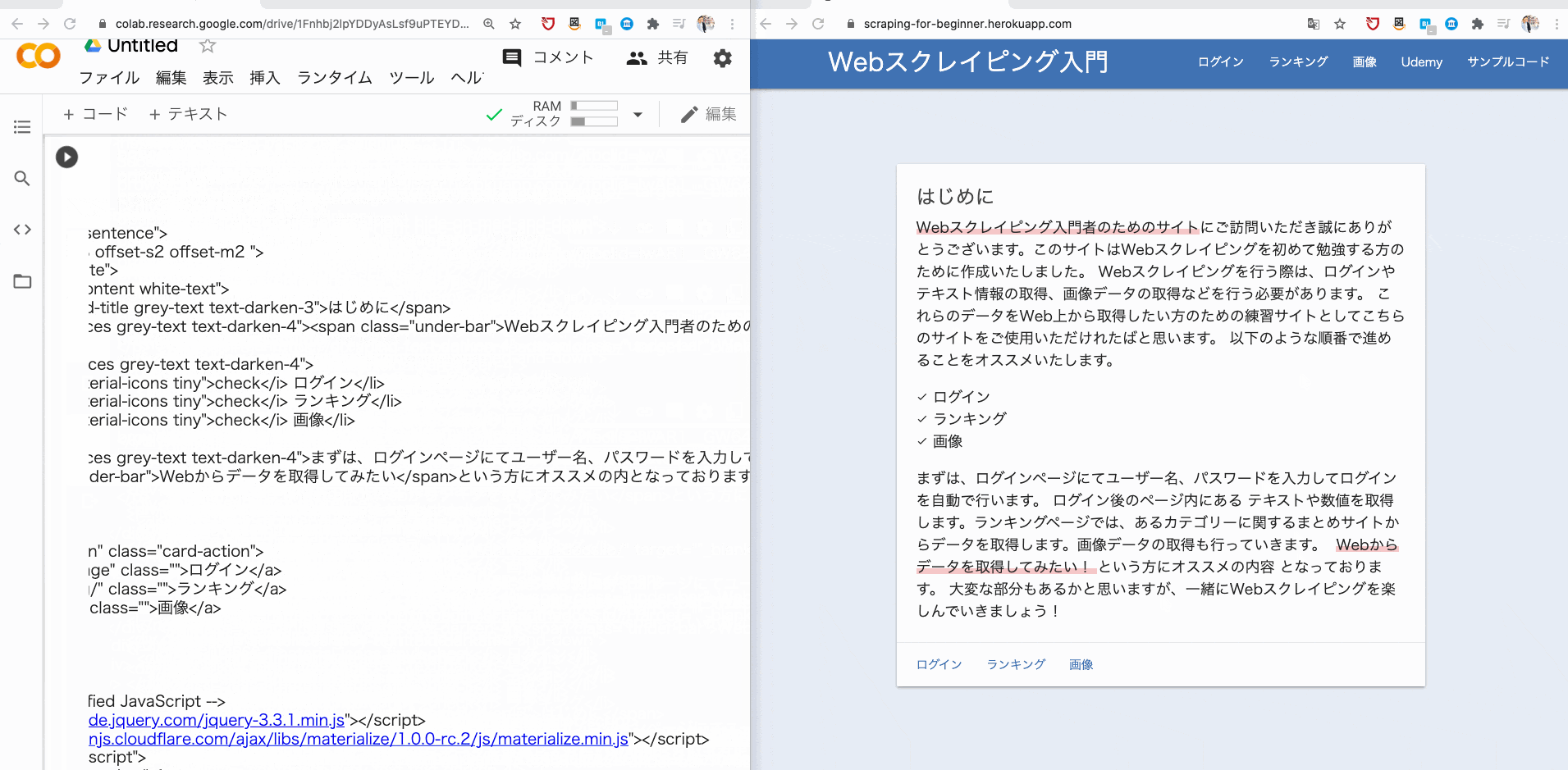
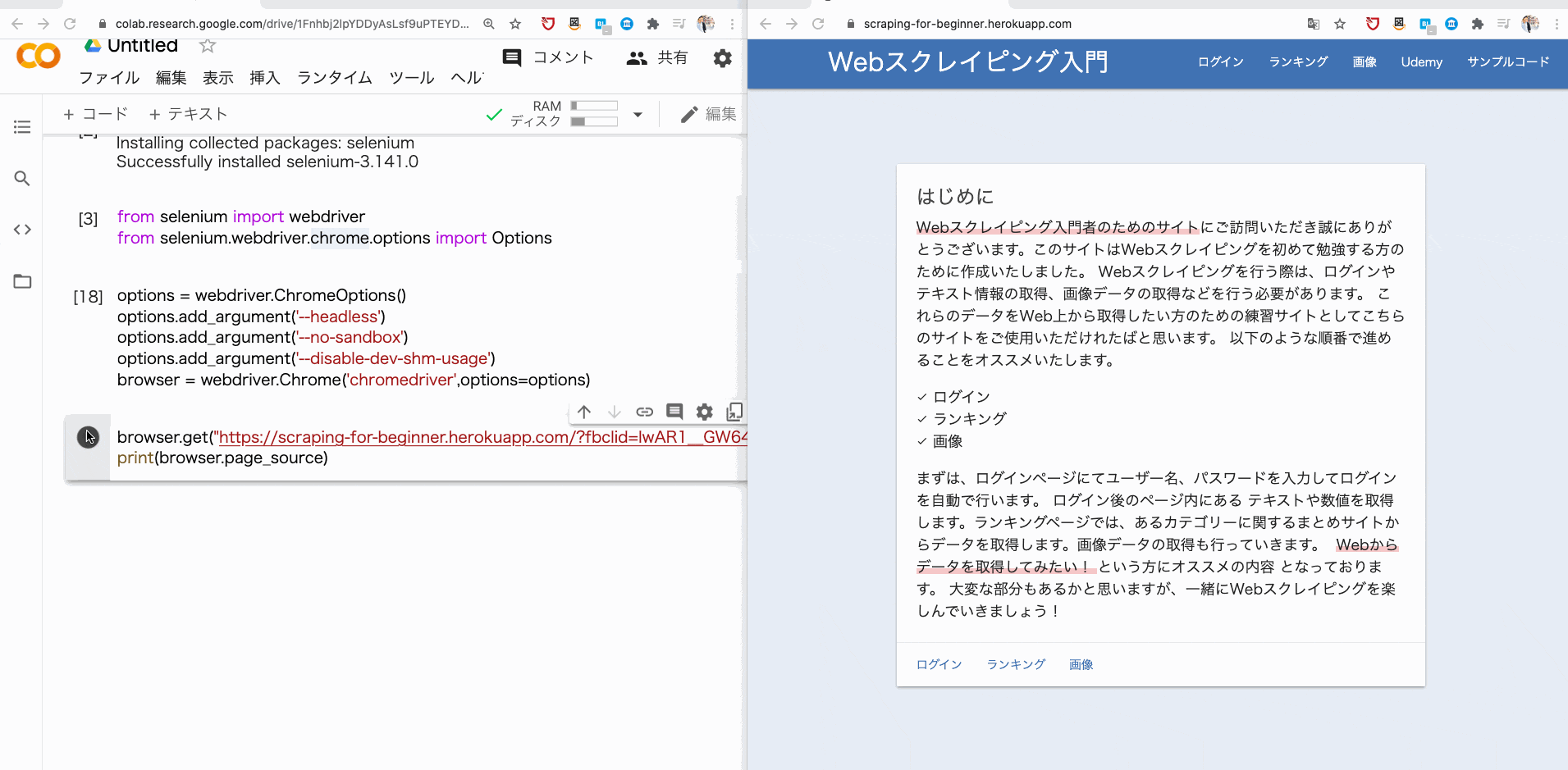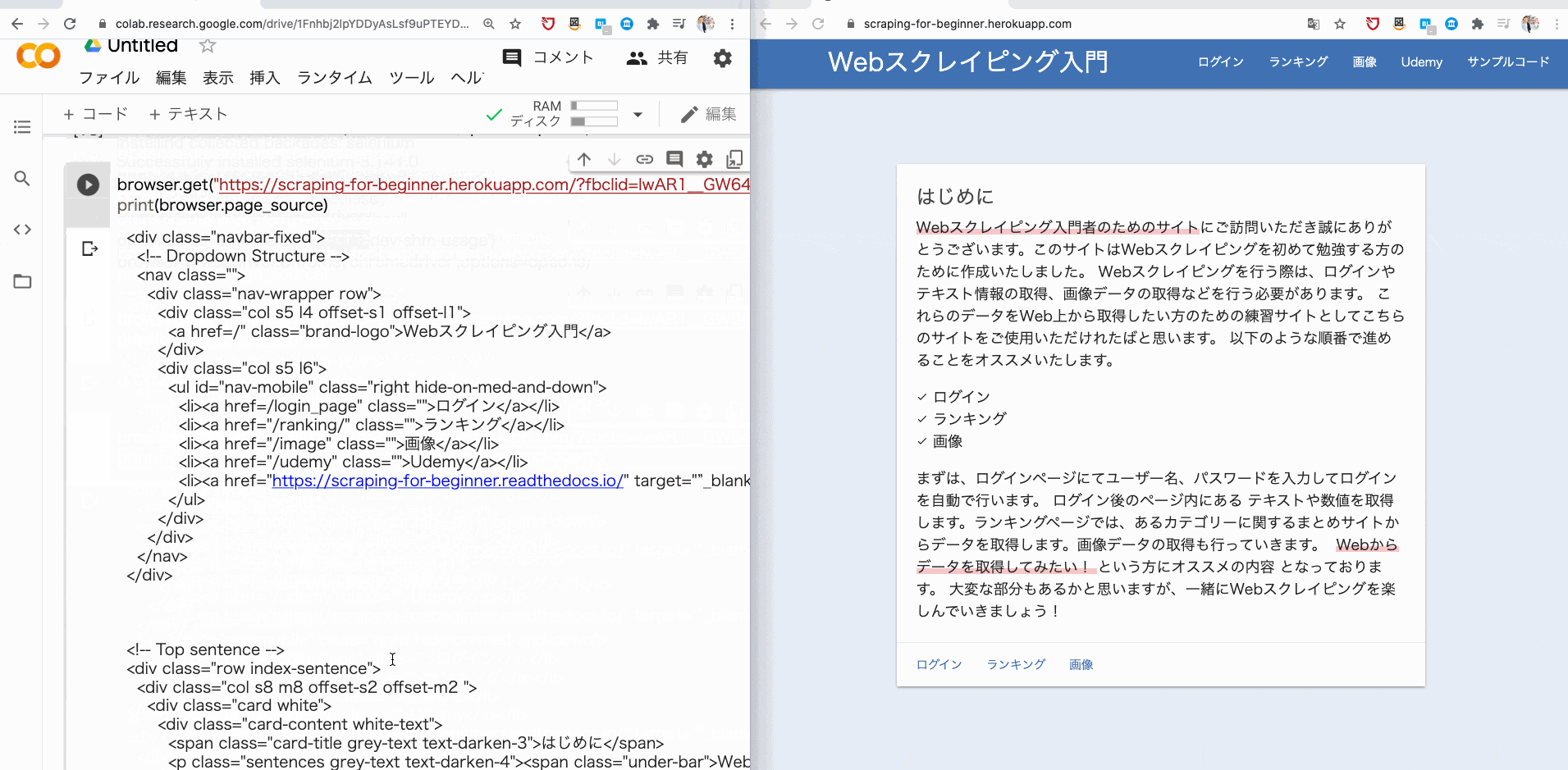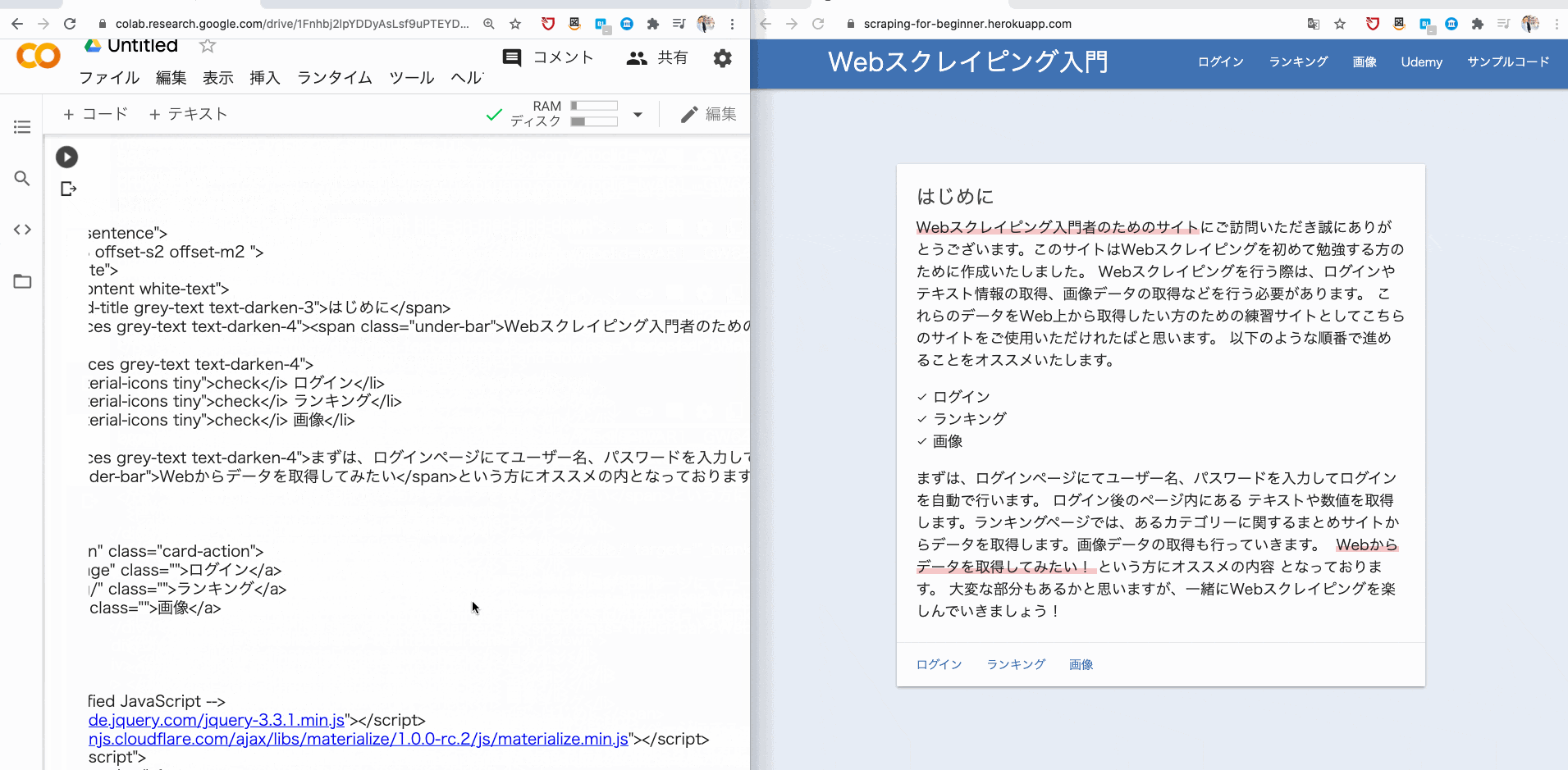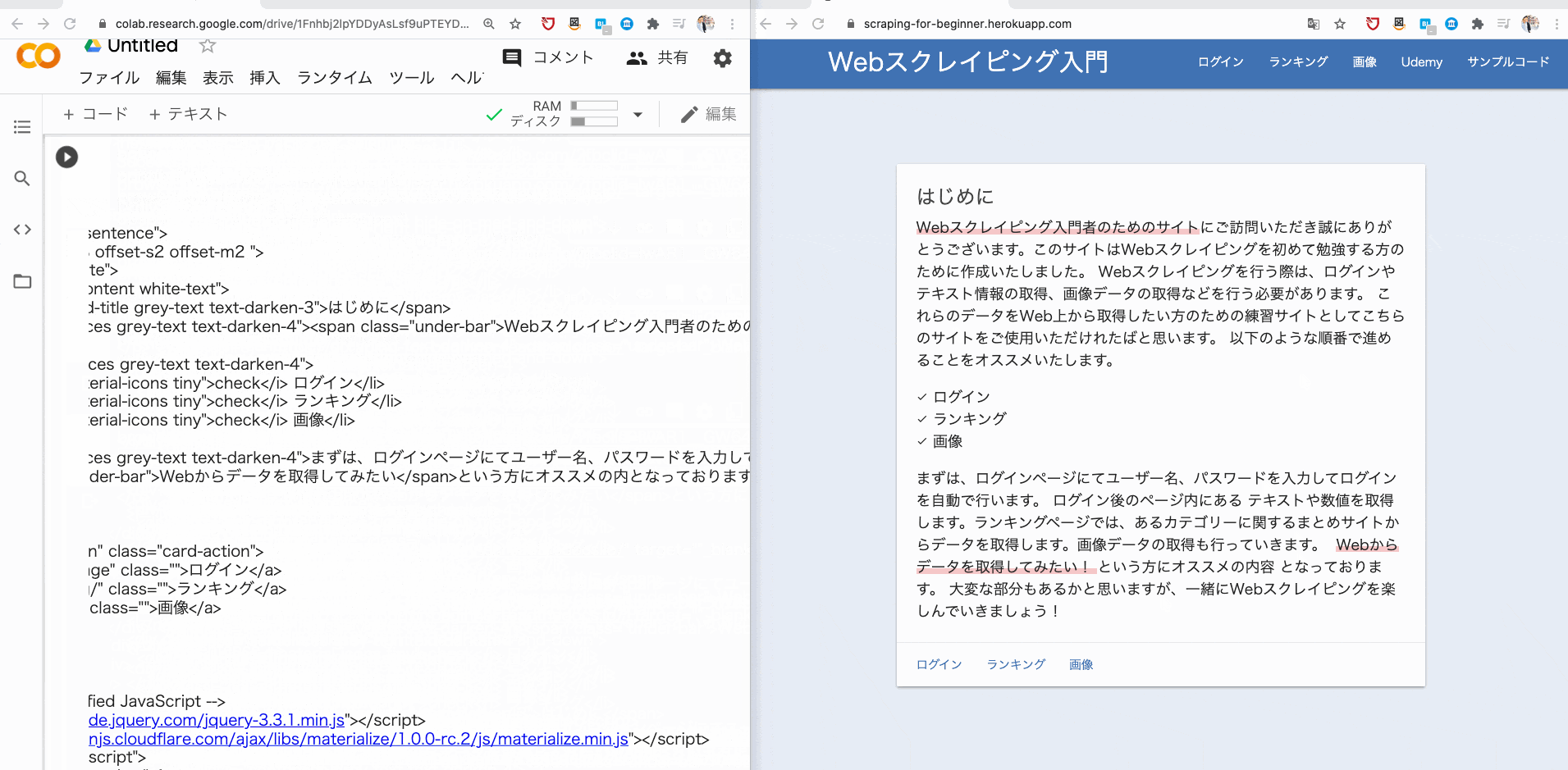
そこで、browser.get で、指定した URL に遷移し、その URL のソースコードを print で表示させてみましょう。
browser.get("https://scraping-for-beginner.herokuapp.com/?fbclid=IwAR1__GW643UFEJmc1486KoGZfPJHhrRN-ybnWw8YTCznyQm2aS4myUR3kI8")
print(browser.page_source)
すると、このようにソースコードが取得できるはずです。
以上になります。
お疲れさまでした!
5. まとめ
このように、簡単に短時間でスクレイピングをするための環境構築が可能になりました。
今回は、記述するコード量が多くなかったですが、次回の記事ではより本格的に Python を使いながらデータの収集をやっていきましょう!
お知らせ

動画を通じて、ディープラーニングが一から学習できる大人気コースの脱ブラックボックスが無料になりました。
手書きの数学とハンズオン形式のプログラミングによって、初学者でも安心して一から学習できます。
機械学習やディープラーニングを基礎から実践を学びたい方は、ぜひ教材の1つとしてご利用ください!
▶︎ 脱ブラックボックスコースを無料で学び始めたい方はこちら!