本記事でやること
Google Cloud PlatformのCloud Composerを用いて以下のような機械学習を行う際の一連のタスクをオーケストレーションします。
- BigQueryから抽出したTrain/TestデータをCSVファイルにしてGCSへ置く
- ML EngineへTrainingのジョブを送る
- モデルのデプロイを行う
- ML EngineへPredictionのジョブを送る
- GCSに置かれているPrediction結果をBigQueryへLoadする
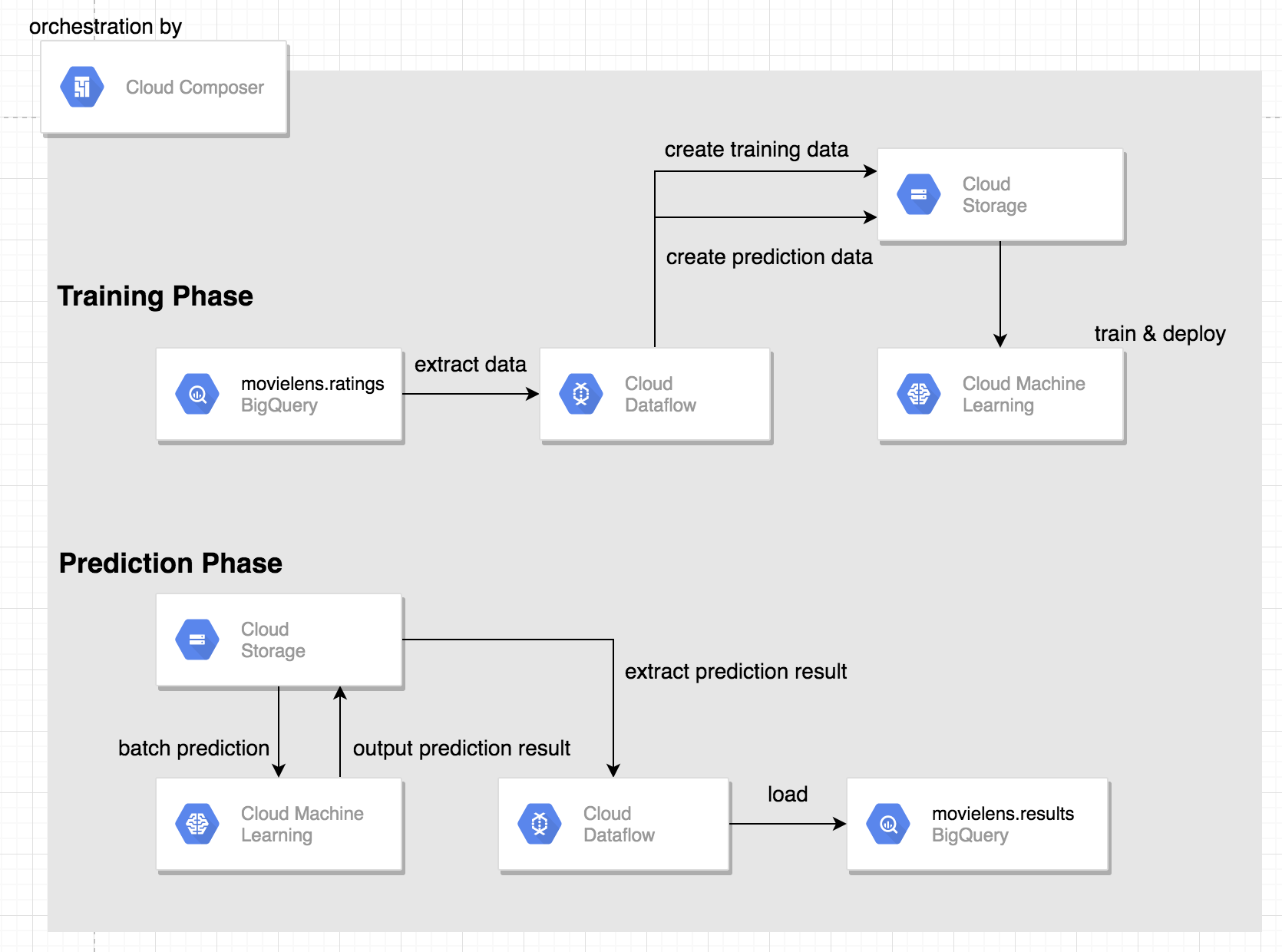
作成するAirflow上のノードとワークフローは下図の様になります。

対象読者
- CloudComposer/AirFlowを触ったことのある方
- ML Engine/DataFlowを触ったことのある方
使用言語とフレームワーク
- Python 3.6.3
- tensorflow 1.15
Airflowのバージョン
- 1.10.6
GCPの各サービスのアーキテクチャ
上記AirflowのタスクをGCPのサービスでそれぞれを表現すると以下の様になります。
1. Cloud Composerの環境設定を行う
以下のbashコマンドでは3つのことを行なっています。
1.Cloud Composerの環境構築
Cloud Composerの環境構築時に注意しないといけないこととしては、引数に--python-version 3を指定することです。デフォルトではpython2系が設定されています。
2.airflowへのライブラリーのインストール
冒頭で示したタスク一覧の中でSlackでメッセージをpostする箇所がありました。このタスクを実行する為にairflowにslackclientライブラリーをインストールする必要があります。
--update-pypi-packages-from-file引数にライブラリーの設定ファイルを指定します。
slackclient~=1.3.2
3.airflow上の環境変数を設定
先述の通り、slackclientライブラリーを使ってslackへメッセージをpostする際にacccess_tokenが必要になるのでairflowの環境変数にaccess_tokenを設定しおくと便利なので予め設定しておきます。(dagファイルにaccess_tokenをベタ書きするのはあまりよろしくない)
# !/usr/bin/env bash
ENVIRONMENT_NAME=dev-composer
LOCATION=us-central1
# 変数を読み込む
eval `cat airflow/config/.secrets.conf`
echo ${slack_access_token}
# cloud composerの環境作成
gcloud composer environments create ${ENVIRONMENT_NAME} \
--location ${LOCATION} \
--python-version 3
# airflowの環境にライブラリーをインストール
gcloud composer environments update ${ENVIRONMENT_NAME} \
--update-pypi-packages-from-file airflow/config/requirements.txt \
--location ${LOCATION}
# airflow上の環境変数を設定
gcloud composer environments run \
--location=${LOCATION} \
${ENVIRONMENT_NAME} \
variables -- \
--set slack_access_token ${slack_access_token} project_id ${project_id}
dagファイルの実装
今回作成したdagファイルは以下の通りになっています。
これだけだと説明が不十分なので、タスク毎にコードを切り分けて説明をしていきます。
import os
import airflow
import datetime
from airflow.models import Variable
from airflow.operators.bash_operator import BashOperator
from airflow.operators.dummy_operator import DummyOperator
from airflow.contrib.operators.dataflow_operator import DataFlowPythonOperator
from airflow.operators.slack_operator import SlackAPIPostOperator
from airflow import configuration
from airflow.utils.trigger_rule import TriggerRule
from airflow.contrib.operators.mlengine_operator \
import MLEngineTrainingOperator, MLEngineBatchPredictionOperator
BUCKET = 'gs://your_bucket'
PROJECT_ID = Variable.get('project_id')
REGION = 'us-central1'
YESTERDAY = datetime.datetime.now() - datetime.timedelta(days=1)
PACKAGE_URI = BUCKET + '/code/trainer-0.1.tar.gz'
OUTDIR = BUCKET + '/trained_model'
DATAFLOW_TRAIN_FILE = os.path.join(
configuration.get('core', 'dags_folder'),
'dataflow', 'extract_train_data.py')
DATAFLOW_PRED_FILE = os.path.join(
configuration.get('core', 'dags_folder'),
'dataflow', 'extract_pred_data.py')
DATAFLOW_LOAD_FILE = os.path.join(
configuration.get('core', 'dags_folder'),
'dataflow', 'load.py')
DEFAULT_ARGS = {
'owner': 'Composer Example',
'depends_on_past': False,
'email': [''],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'start_date': YESTERDAY,
'project_id': Variable.get('project_id'),
'dataflow_default_options': {
'project': Variable.get('project_id'),
'temp_location': 'gs://your_composer_bucket/temp',
'runner': 'DataflowRunner'
}
}
def get_date():
jst_now = datetime.datetime.now()
dt = datetime.datetime.strftime(jst_now, "%Y-%m-%d")
return dt
with airflow.DAG(
'asl_ml_pipeline',
'catchup=False',
default_args=DEFAULT_ARGS,
schedule_interval=datetime.timedelta(days=1)) as dag:
start = DummyOperator(task_id='start')
####
# ML Engineでのtrainingを行うタスク
####
job_id = 'dev-train-{}'.\
format(datetime.datetime.now().strftime('%Y%m%d%H%M'))
job_dir = BUCKET + '/jobs/' + job_id
submit_train_job = MLEngineTrainingOperator(
task_id='train-model',
project_id=PROJECT_ID,
job_id=job_id,
package_uris=[PACKAGE_URI],
region=REGION,
training_python_module='trainer.task',
training_args=[f'--output_dir={OUTDIR}',
f'--job_dir={job_dir}',
'--dropout_rate=0.5',
'--batch_size=128',
'--train_step=1'
],
scale_tier='BASIC_GPU',
python_version='3.5'
)
####
# modelをdeployするタスク
####
BASE_VERSION_NAME = 'v1_0'
VERSION_NAME = '{0}_{1}'.\
format(BASE_VERSION_NAME, datetime.datetime.now().strftime('%Y_%m_%d'))
MODEL_NAME = 'dev_train'
deploy_model = BashOperator(
task_id='deploy-model',
bash_command='gcloud ml-engine versions create '
'{{ params.version_name}} '
'--model {{ params.model_name }} '
'--origin $(gsutil ls gs://your_bucket/trained_model/export/exporter | tail -1) '
'--python-version="3.5" '
'--runtime-version=1.14 ',
params={'version_name': VERSION_NAME,
'model_name': MODEL_NAME}
)
####
# ML Engineでバッチ予測を行うタスク
####
today = get_date()
input_path = BUCKET + f'/preprocess/{today}/prediction/prediction-*'
output_path = BUCKET + f'/result/{today}/'
batch_prediction = MLEngineBatchPredictionOperator(
task_id='batch-prediction',
data_format='TEXT',
region=REGION,
job_id=job_id,
input_paths=input_path,
output_path=output_path,
model_name=MODEL_NAME,
version_name=VERSION_NAME
)
####
# DataFlowでデータ抽出を行うタスク
####
job_args = {
'output': 'gs://your_bucket/preprocess'
}
create_train_data = DataFlowPythonOperator(
task_id='create-train-data',
py_file=DATAFLOW_TRAIN_FILE,
options=job_args
)
create_pred_data = DataFlowPythonOperator(
task_id='create-pred-data',
py_file=DATAFLOW_PRED_FILE,
options=job_args
)
####
# DataFlowでBigQueryへデータをloadするタスク
####
load_results = DataFlowPythonOperator(
task_id='load_pred_results',
py_file=DATAFLOW_LOAD_FILE
)
post_success_slack_train = SlackAPIPostOperator(
task_id='post-success-train-to-slack',
token=Variable.get('slack_access_token'),
text='Train is succeeded',
channel='#feed'
)
post_fail_slack_train = SlackAPIPostOperator(
task_id='post-fail-train-to-slack',
token=Variable.get('slack_access_token'),
trigger_rule=TriggerRule.ONE_FAILED,
text='Train is failed',
channel='#feed'
)
####
# SlackへメッセージをPOSTするタスク
####
post_success_slack_pred = SlackAPIPostOperator(
task_id='post-success-pred-to-slack',
token=Variable.get('slack_access_token'),
text='Prediction is succeeded',
channel='#feed'
)
post_fail_slack_pred = SlackAPIPostOperator(
task_id='post-fail-pred-to-slack',
token=Variable.get('slack_access_token'),
trigger_rule=TriggerRule.ONE_FAILED,
text='Prediction is failed',
channel='#feed'
)
end = DummyOperator(task_id='end')
start >> [create_train_data, create_pred_data] >> submit_train_job \
>> [post_fail_slack_train, post_success_slack_train]
post_fail_slack_train >> end
post_success_slack_train >> deploy_model >> batch_prediction \
>> load_results \
>> [post_success_slack_pred, post_fail_slack_pred] >> end
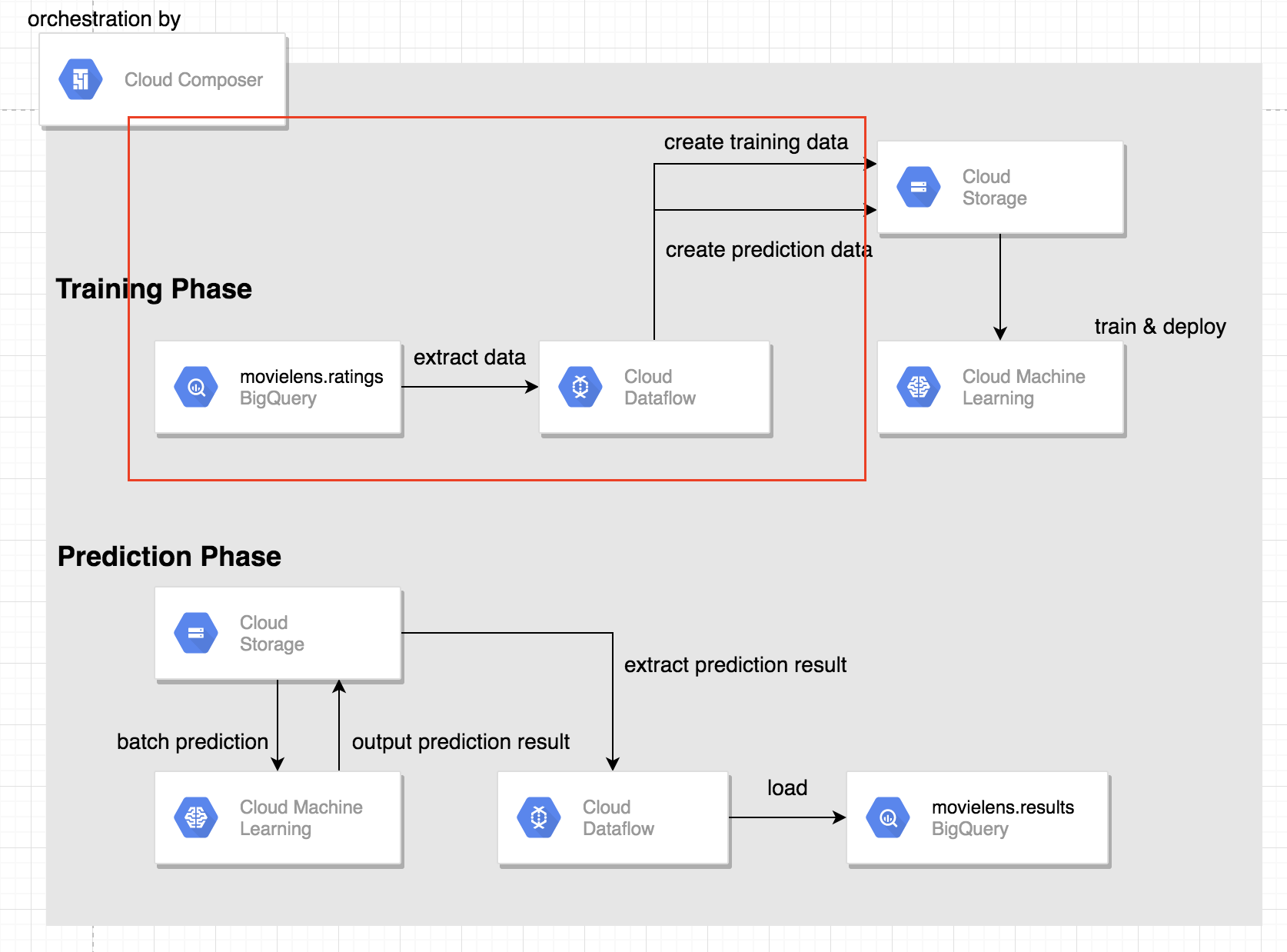
BigQueryからのデータ抽出及びGCSへの書き出し
Training Phaseで行なっている最初のタスクです。(以下図の赤枠)
BigQueryからDataFlowを使ってデータの抽出及びGCSの適当なバケットへデータを置くという処理を行なっています。
Dagファイルの説明
-
定数
DATAFLOW_TRAIN_FILE/DATAFLOW_PRED_FILE- DataFlowの実行ファイルが置かれているファイルパス
- Cloud Composerの環境構築時に作成された
Bucket内のdagsディレクトリ以下のファイルは数秒間隔でairflowのworkerによって同期されています。
-
定数
DEFAULT_ARGS-
dataflow_default_optionsの引数にDataFlow実行時の環境変数を設定します。
-
-
DataFlowPythonOperatorクラス- DataFlowをpythonファイル使用してJOBを実行する際のクラス
-
py_file引数に実行ファイルが置かれているパスをしているする -
options引数に実行ファイルに渡す引数を指定する- 今回はGCSにデータを置く際のファイルパスを指定しています
DATAFLOW_TRAIN_FILE = os.path.join(
configuration.get('core', 'dags_folder'),
'dataflow', 'extract_train_data.py')
DATAFLOW_PRED_FILE = os.path.join(
configuration.get('core', 'dags_folder'),
'dataflow', 'extract_pred_data.py')
DEFAULT_ARGS = {
'owner': 'Composer Example',
'depends_on_past': False,
'email': [''],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'start_date': YESTERDAY,
'project_id': Variable.get('project_id'),
'dataflow_default_options': {
'project': Variable.get('project_id'),
'temp_location': 'gs://your_composer_bucket/temp',
'runner': 'DataflowRunner'
}
}
####
# DataFlowでデータ抽出を行うタスク
####
# GCSにデータを置く際のファイルパス
job_args = {
'output': 'gs://your_bucket/preprocess'
}
create_train_data = DataFlowPythonOperator(
task_id='create-train-data',
py_file=DATAFLOW_TRAIN_FILE,
options=job_args
)
create_pred_data = DataFlowPythonOperator(
task_id='create-pred-data',
py_file=DATAFLOW_PRED_FILE,
options=job_args
)
DataFlow実行ファイルの説明
以下のファイルは、Trainingを行うための、train dataとtest dataに分割しGCSへ置く処理となっています。
(また、記事の簡略化のためtrain dataとtest dataに分割するためのクエリの解説は割愛させて頂きます。timestampのカラムがあることを前提にハッシュ化を行い、除算した余りの値で分割しております)
ここで気をつけたいポイントは2点です。
-
CSVファイルへの変換
- 最終的にCSVファイルとして出力したいのでBigQueryから抽出したデータをカンマ区切りの形式に変換する必要があります。
- ここでは、
to_csvという関数を用意しております。
-
DataFlowのPythonバージョン
- DataFlowのPythonは3.5.xなので3.6から追加された
f-stringsなどの文法は使えません。
- DataFlowのPythonは3.5.xなので3.6から追加された
import os
import argparse
import logging
from datetime import datetime
import apache_beam as beam
from apache_beam.options.pipeline_options import \
PipelineOptions
PROJECT = 'your_project_id'
def create_query(phase):
base_query = """
SELECT
*,
MOD(ABS(FARM_FINGERPRINT(CAST(timestamp AS STRING))), 10) AS hash_value
FROM
`dataset.your_table`
"""
if phase == 'TRAIN':
subsumple = """
hash_value < 7
"""
elif phase == 'TEST':
subsumple = """
hash_value >= 7
"""
query = """
SELECT
column1,
column2,
column3,
row_number()over() as key
FROM
({0})
WHERE {1}
""".\
format(base_query, subsumple)
return query
def to_csv(line):
csv_columns = 'column1,column2,column3,key'.split(',')
rowstring = ','.join([str(line[k]) for k in csv_columns])
return rowstring
def get_date():
jst_now = datetime.now()
dt = datetime.strftime(jst_now, "%Y-%m-%d")
return dt
def run(argv=None):
parser = argparse.ArgumentParser()
parser.add_argument(
'--output',
required=True
)
known_args, pipeline_args = \
parser.parse_known_args(argv)
options = PipelineOptions(pipeline_args)
with beam.Pipeline(options=options) as p:
for phase in ['TRAIN', 'TEST']:
query = create_query(phase)
date = get_date()
output_path = os.path.join(known_args.output, date,
'train', "{}".format(phase))
read = p | 'ExtractFromBigQuery_{}'.format(phase) >> beam.io.Read(
beam.io.BigQuerySource(
project=PROJECT,
query=query,
use_standard_sql=True
)
)
convert = read | 'ConvertToCSV_{}'.format(phase) >> beam.Map(to_csv)
convert | 'WriteToGCS_{}'.format(phase) >> beam.io.Write(
beam.io.WriteToText(output_path, file_name_suffix='.csv'))
if __name__ == '__main__':
logging.getLogger().setLevel(logging.INFO)
run()
ML Engineでのtraining及びdeploy
ここでは、ML Engineを使ったtraining及び学習したモデルのdeployを行うタスクの説明を行いまいす。
また、今回はML Engineで使用する実行ファイルtask.pyやモデルファイルmodel.pyについての説明は割愛させて頂きます。
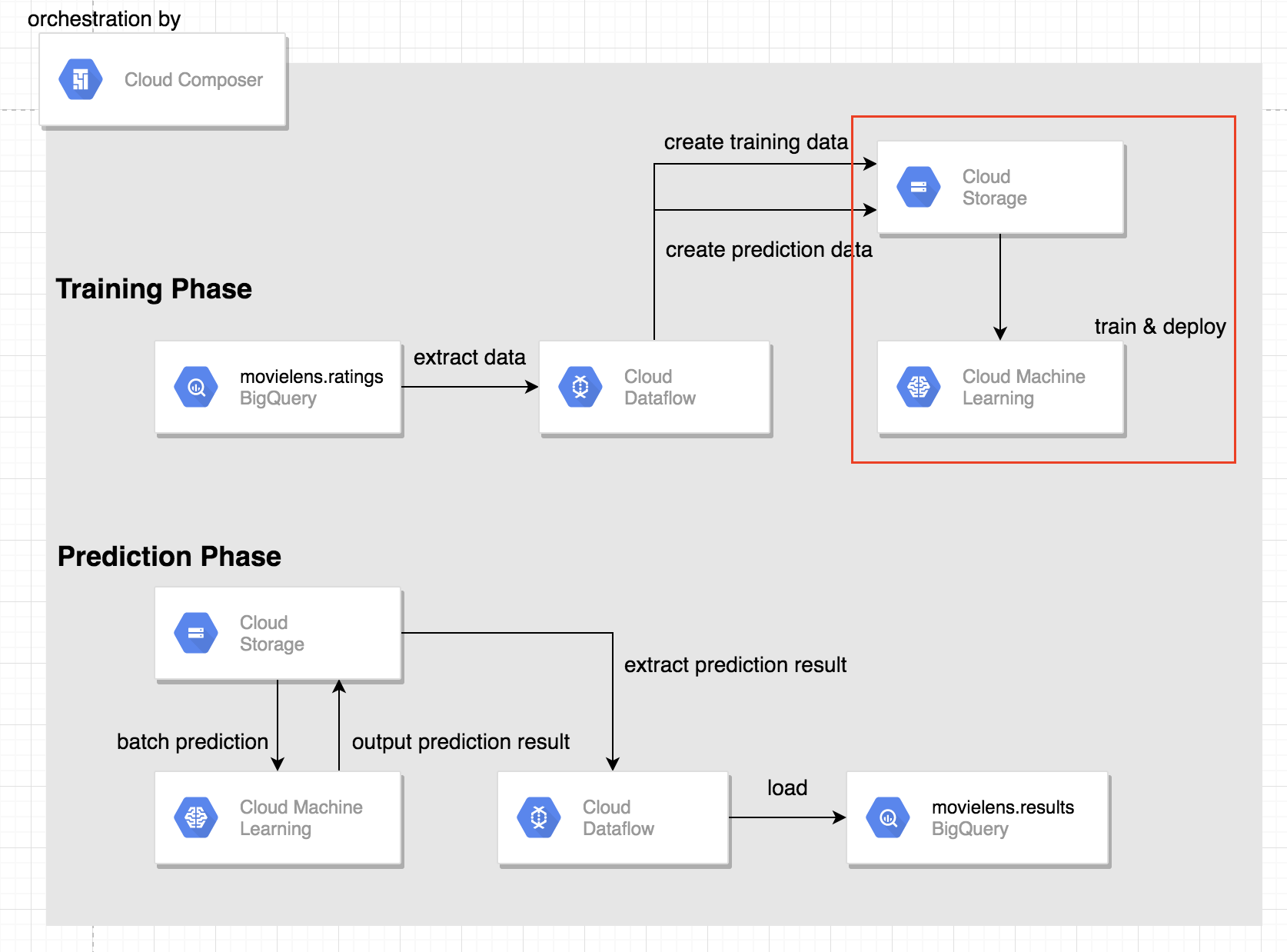
今回ML Engine用にバケットを用意しております。
なので、Cloud Composerの環境構築時で作成されるバケットと合わせると合計2つバケットを使い分けているので注意してください。
.
├── your_bucket
│ ├── code // 学習に必要なmodel.pyやtask.py等を固めたgzファイルを置く
│ │
│ └── trainde_model // 学習済みのmodelファイルが置かれる
│
└── your_composer_bucket // cloud composerの環境構築時に作成されるバケット
Dagファイルの説明
-
定数
PACKAGE_URI- ML Engineの実行ファイルが置いてあるファイルパス
- 今回は
trainer.pyやmodel.pyなどを固めたgzファイルを上記のgs://your_bucket/code以下に置いています。 -
MLEngineTrainingOperatorクラスのpackage_uris引数にこの定数を指定しています。
-
BashOperatorクラス- bashコマンドを実行する際のクラス
- 今回は学習済みのモデルファイルをdeployする際にbashコマンド使用しています。
-
gcloud ml-engine versions createを実行することでmodelのdeployを行なっています
-
- (おそらく)
MLEngineVersionOperatorクラスでも同様のことが行えると思いますが、今回はbashコマンドを利用しました。
PACKAGE_URI = BUCKET + '/code/trainer-0.1.tar.gz'
OUTDIR = BUCKET + '/trained_model'
job_id = 'dev-train-{}'.\
format(datetime.datetime.now().strftime('%Y%m%d%H%M'))
job_dir = BUCKET + '/jobs/' + job_id
submit_train_job = MLEngineTrainingOperator(
task_id='train-model',
project_id=PROJECT_ID,
job_id=job_id,
package_uris=[PACKAGE_URI],
region=REGION,
training_python_module='trainer.task',
training_args=[f'--output_dir={OUTDIR}',
f'--job_dir={job_dir}',
'--dropout_rate=0.5',
'--batch_size=128',
'--train_step=1'
],
scale_tier='BASIC_GPU',
python_version='3.5'
)
today = get_date()
BASE_VERSION_NAME = 'v1_0'
VERSION_NAME = '{0}_{1}'.\
format(BASE_VERSION_NAME, datetime.datetime.now().strftime('%Y_%m_%d'))
MODEL_NAME = 'dev_model'
deploy_model = BashOperator(
task_id='deploy-model',
bash_command='gcloud ml-engine versions create '
'{{ params.version_name}} '
'--model {{ params.model_name }} '
'--origin $(gsutil ls gs://your_bucket/trained_model/export/exporter | tail -1) '
'--python-version="3.5" '
'--runtime-version=1.14 ',
params={'version_name': VERSION_NAME,
'model_name': MODEL_NAME}
)
ML Engineでのバッチ予測
ここでは、先でdeployしたモデルを使ってバッチ予測を行うタスクについて説明をします。

-
定数
input_path- 先で行なった予測用に抽出しGCSにおいたCSVファイルのパス
-
定数
output_path- 予測した結果を置くGCSのファイルパス
Dagファイルの説明
input_path = BUCKET + f'/preprocess/{today}/prediction/prediction-*'
output_path = BUCKET + f'/result/{today}/'
batch_prediction = MLEngineBatchPredictionOperator(
task_id='batch-prediction',
data_format='TEXT',
region=REGION,
job_id=job_id,
input_paths=input_path,
output_path=output_path,
model_name=MODEL_NAME,
version_name=VERSION_NAME
)
バッチ予測結果のBigQueryへのLoad
ここでは、先で予測した予測結果をDataFlowを使ってBigQueryにLoadするタスクについて説明します。
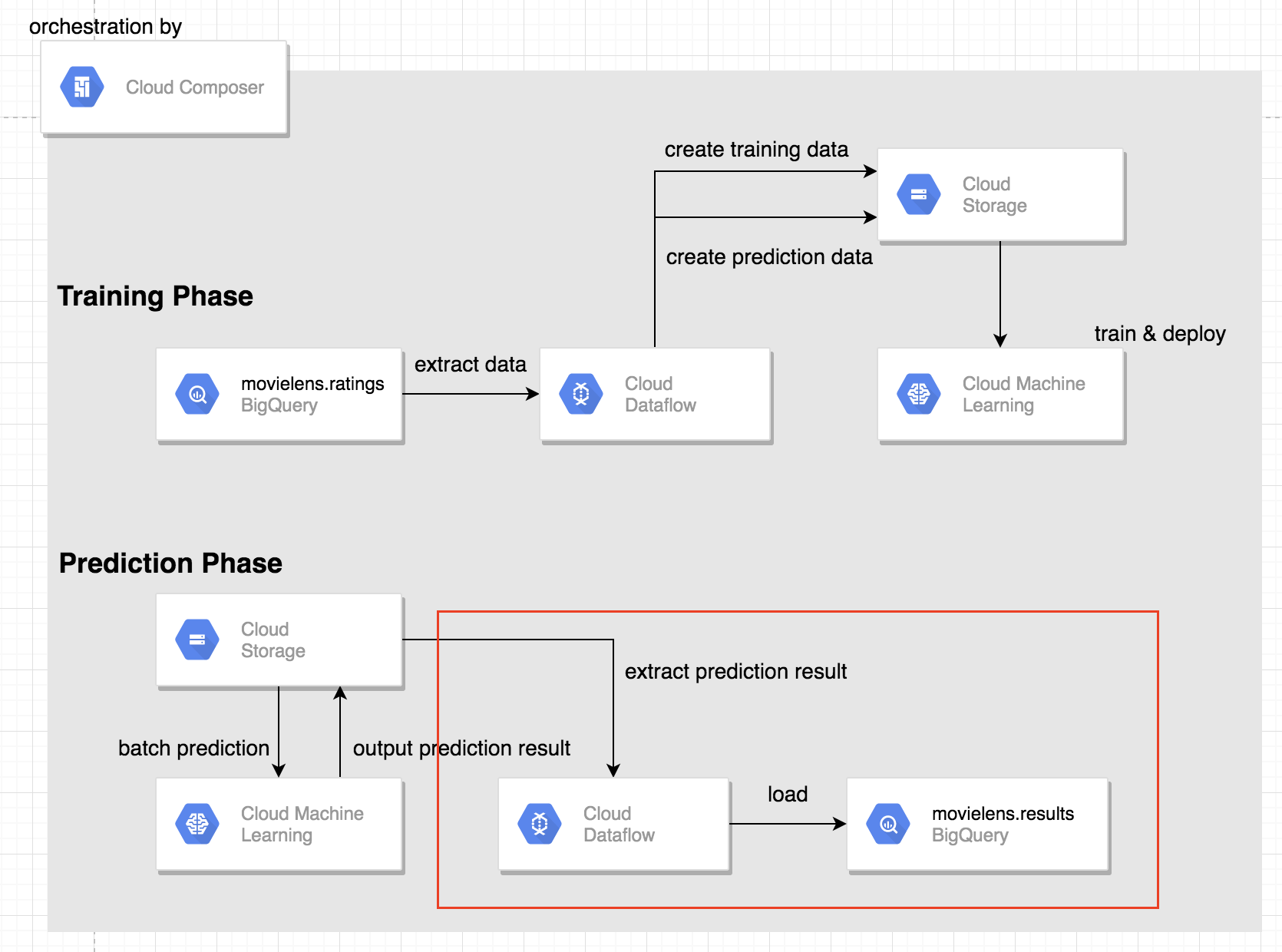
Dagファイルの説明
Dagファイルについて、冒頭で説明した"BigQueryからデータを抽出する"タスクと同様になります。
定数DATAFLOW_LOAD_FILEにDataFlowの実行ファイルがおかれているGCSのファイルパスを指定しています。
DATAFLOW_LOAD_FILE = os.path.join(
configuration.get('core', 'dags_folder'),
'dataflow', 'load.py')
load_results = DataFlowPythonOperator(
task_id='load_pred_results',
py_file=DATAFLOW_LOAD_FILE
)
DataFlow実行ファイルの説明
以下のファイルでは、GCSに置かれているファイル読み込み、Json形式へと変換しBigQueryの適当なテーブルへloadをしております。
ここで気をつけたいこととしては
- バッチ予測結果はjson形式のテキストファイルとしてGCSに置かれます。
- テキストファイルに書かれているpredictionの出力結果の値などはリスト形式として記載されているのでそのままloadしようとすると型が合わなくてエラーが生じます。
{"key": [0], "prediction: [3.45...]"}
- テキストファイルに書かれているpredictionの出力結果の値などはリスト形式として記載されているのでそのままloadしようとすると型が合わなくてエラーが生じます。
import logging
import argparse
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
BUCKET_NAME = 'your_bucket'
INPUT = 'gs://{}/result/prediction.results-*'.format(BUCKET_NAME)
def convert(line):
import json
record = json.loads(line)
return {'key': record['key'][0], 'predictions': record['predictions'][0]}
def run(argv=None):
parser = argparse.ArgumentParser()
known_args, pipeline_args = \
parser.parse_known_args(argv)
options = PipelineOptions(pipeline_args)
with beam.Pipeline(options=options) as p:
dataset = 'your_dataset.results'
read = p | 'ReadPredictionResult' >> beam.io.ReadFromText(INPUT)
json = read | 'ConvertJson' >> beam.Map(convert)
json | 'WriteToBigQuery' >> beam.io.Write(beam.io.BigQuerySink(
dataset,
schema='key:INTEGER, predictions:FLOAT',
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_TRUNCATE))
if __name__ == '__main__':
logging.getLogger().setLevel(logging.INFO)
run()
おわりに
普段はAWSを使っていますが、GCPのサービスについて触れる機会があったのでML関係のサービスについてまとめてみました。MLのワークフローについて悩まれている方の参考になれば幸いです。
MLEngineでtrainingしたmodelをそのままdeployする箇所がありますが、あまりオススメできません。なにがしか学習したモデルの精度を測る/比較する機構を作り、そのタスクを挟んでからdeployすることをオススメします。