本記事でやること
Elasticsearchに1件ずつデータを登録する「Single Insert」とまとめて一括登録する「Bulk Insert」に関して、以下の2つの観点からパフォーマンスの比較をします。
- どれだけ早くインデキシングできるか
- インデキシングしてから検索可能になるまでどれだけ時間がかかるか
つまり、「Single Insert」・「Bulk Insert」x refreshオプションの有無を組み合わせた4つのシナリオでベンチマークを測定します。
今回実装した内容は以下のレポジトリにまとめられています。
対象読者
- Elasticsearchへのインデキシング時のパフォーマンスに課題を感じている方
- Elasticsearchの
refreshの仕組みについて理解を深めたい方
使用言語・技術
- 言語: Go(1.24.2)
- ライブラリ: go-elasticsearch/v8
- 環境構築: Docker
ベンチマーク環境の準備
1. Elasticsearchクラスタの構築
docker-compose.ymlを使いローカルにElasticsearchを起動します。
version: '3.8'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.14.1
container_name: elasticsearch
ports:
- "9200:9200"
- "9300:9300"
environment:
- discovery.type=single-node
- xpack.security.enabled=false
- ES_JAVA_OPTS=-Xms512m -Xmx512m
2. Elasticsearchへインデキシングする処理の実装
今回4つのシナリオに合わせて以下の関数を実装しました。
-
SingleInsert- ドキュメントを1件ずつ登録する関数。
refreshは指定せずにスループットのみを測定します
- ドキュメントを1件ずつ登録する関数。
-
BulkInsert- 複数のドキュメントをまとめて登録する関数。
refreshは指定せずにスループットのみを測定します
- 複数のドキュメントをまとめて登録する関数。
-
SingleInsertWithRefresh- 1件登録するごとに
refresh: "true"を指定し、即時検索可能にするまでの時間を測定します
- 1件登録するごとに
-
BulkInsertWithRefresh- 一括登録の後に
refresh: "true"を指定し、全件が即時検索可能になるまでの時間を測定します
- 一括登録の後に
func (c *Client) SingleInsert(ctx context.Context, index string, docs []map[string]interface{}) error {
for i, doc := range docs {
_, err := c.typedClient.Index(index).
Id(fmt.Sprintf("%d", i+1)).
Request(doc).
Do(ctx)
if err != nil {
return fmt.Errorf("failed to insert document %d: %w", i+1, err)
}
}
return nil
}
func (c *Client) BulkInsert(ctx context.Context, index string, docs []map[string]interface{}) error {
bulkCfg := esutil.BulkIndexerConfig{
Client: c.baseClient,
Index: index,
}
indexer, err := esutil.NewBulkIndexer(bulkCfg)
if err != nil {
return fmt.Errorf("failed to create bulk indexer: %w", err)
}
for i, doc := range docs {
data, err := json.Marshal(doc)
if err != nil {
return fmt.Errorf("failed to marshal document %d: %w", i+1, err)
}
err = indexer.Add(
ctx,
esutil.BulkIndexerItem{
Index: index,
Action: "index",
DocumentID: fmt.Sprintf("%d", i+1),
Body: strings.NewReader(string(data)),
},
)
if err != nil {
return fmt.Errorf("failed to add document %d to bulk indexer: %w", i+1, err)
}
}
if err := indexer.Close(ctx); err != nil {
return fmt.Errorf("failed to close bulk indexer: %w", err)
}
return nil
}
func (c *Client) SingleInsertWithRefresh(ctx context.Context, index string, docs []map[string]interface{}) error {
for i, doc := range docs {
_, err := c.typedClient.Index(index).
Id(fmt.Sprintf("%d", i+1)).
Request(doc).
Refresh(refresh.True).
Do(ctx)
if err != nil {
return fmt.Errorf("failed to insert document %d: %w", i+1, err)
}
}
return nil
}
func (c *Client) BulkInsertWithRefresh(ctx context.Context, index string, docs []map[string]interface{}) error {
bulkCfg := esutil.BulkIndexerConfig{
Client: c.baseClient,
Index: index,
Refresh: "true",
}
indexer, err := esutil.NewBulkIndexer(bulkCfg)
if err != nil {
return fmt.Errorf("failed to create bulk indexer: %w", err)
}
for i, doc := range docs {
data, err := json.Marshal(doc)
if err != nil {
return fmt.Errorf("failed to marshal document %d: %w", i+1, err)
}
err = indexer.Add(
ctx,
esutil.BulkIndexerItem{
Index: index,
Action: "index",
DocumentID: fmt.Sprintf("%d", i+1),
Body: strings.NewReader(string(data)),
},
)
if err != nil {
return fmt.Errorf("failed to add document %d to bulk indexer: %w", i+1, err)
}
}
if err := indexer.Close(ctx); err != nil {
return fmt.Errorf("failed to close bulk indexer: %w", err)
}
return nil
}
![]()
refresh: "wait_for"ではなく"true"を採用した理由
-
refresh: "wait_for"はインデックスのrefresh_intervalの設定に依存するためベンチマークの実行時間が不安定になり、場合によっては数時間かかる可能性がありました。 - 今回は「リクエスト完了時点でデータが確実に検索可能になっている」状態を測定するためリクエストごとに強制的にリフレッシュをかける
refresh: "true"を採用
ベンチマークテストの実装
Goの標準パッケージであるtestingを使いベンチマークテストを実装しました。
今回はドキュメント件数(10, 100, 1,000, 10,000)と先で説明した4つの関数を組み合わせて網羅的にテストケースを作成します。
unc BenchmarkInsert(b *testing.B) {
// Elasticsearch クライアントのセットアップ
cfg := elasticsearch.Config{
Addresses: []string{"http://localhost:9200"},
}
client, err := NewClient(cfg)
if err != nil {
b.Fatalf("failed to create client: %v", err)
}
// ベンチマーク対象のドキュメント件数
docCounts := []int{10, 100, 1000, 10000}
for _, count := range docCounts {
// SingleInsert のベンチマーク
b.Run(fmt.Sprintf("SingleInsert/%d_docs", count), func(b *testing.B) {
docs := generateDocs(count)
indexName := fmt.Sprintf("test-single-%d", count)
b.ResetTimer()
for i := 0; i < b.N; i++ {
// タイマーを停止してテストごとのセットアップ(インデックス作成)を行う
b.StopTimer()
err := client.CreateIndex(context.Background(), indexName)
if err != nil {
b.Fatalf("failed to create index: %v", err)
}
b.StartTimer()
// 実際の挿入処理を計測
err = client.SingleInsert(context.Background(), indexName, docs)
if err != nil {
b.Fatalf("SingleInsert failed: %v", err)
}
}
})
// BulkInsert のベンチマーク
b.Run(fmt.Sprintf("BulkInsert/%d_docs", count), func(b *testing.B) {
docs := generateDocs(count)
indexName := fmt.Sprintf("test-bulk-%d", count)
b.ResetTimer()
for i := 0; i < b.N; i++ {
// タイマーを停止してテストごとのセットアップ(インデックス作成)を行う
b.StopTimer()
err := client.CreateIndex(context.Background(), indexName)
if err != nil {
b.Fatalf("failed to create index: %v", err)
}
b.StartTimer()
// 実際の挿入処理を計測
err = client.BulkInsert(context.Background(), indexName, docs)
if err != nil {
b.Fatalf("BulkInsert failed: %v", err)
}
}
})
// SingleInsertWithRefresh のベンチマーク
b.Run(fmt.Sprintf("SingleInsertWithRefresh/%d_docs", count), func(b *testing.B) {
docs := generateDocs(count)
indexName := fmt.Sprintf("test-single-refresh-%d", count)
b.ResetTimer()
for i := 0; i < b.N; i++ {
b.StopTimer()
err := client.CreateIndex(context.Background(), indexName)
if err != nil {
b.Fatalf("failed to create index: %v", err)
}
b.StartTimer()
err = client.SingleInsertWithRefresh(context.Background(), indexName, docs)
if err != nil {
b.Fatalf("SingleInsertWithRefresh failed: %v", err)
}
}
})
// BulkInsertWithRefresh のベンチマーク
b.Run(fmt.Sprintf("BulkInsertWithRefresh/%d_docs", count), func(b *testing.B) {
docs := generateDocs(count)
indexName := fmt.Sprintf("test-bulk-refresh-%d", count)
b.ResetTimer()
for i := 0; i < b.N; i++ {
b.StopTimer()
err := client.CreateIndex(context.Background(), indexName)
if err != nil {
b.Fatalf("failed to create index: %v", err)
}
b.StartTimer()
err = client.BulkInsertWithRefresh(context.Background(), indexName, docs)
if err != nil {
b.Fatalf("BulkInsertWithRefresh failed: %v", err)
}
}
})
}
}
ベンチマークテストの実行と結果
テストを実行し結果を以下にまとめます。
go test -bench=. -benchmem- 4つのシナリオと4つのドキュメント件数の全16パターンの測定結果を以下にまとめます。処理時間はミリ秒(ms)単位です。
| ドキュメント数 | SingleInsert(ms) | BulkInsert(ms) | SingleInsertWithRefresh(ms) | BulkInsertWithRefresh(ms) |
|---|---|---|---|---|
| 10 | 12.1 | 5.9 | 41.1 | 17.3 |
| 100 | 113.8 | 8.6 | 372.6 | 22.3 |
| 1,000 | 1,181.5 | 13.3 | 4,026.2 | 35.9 |
| 10,000 | 11,009.0 | 55.1 | 37,227.8 | 86.0 |
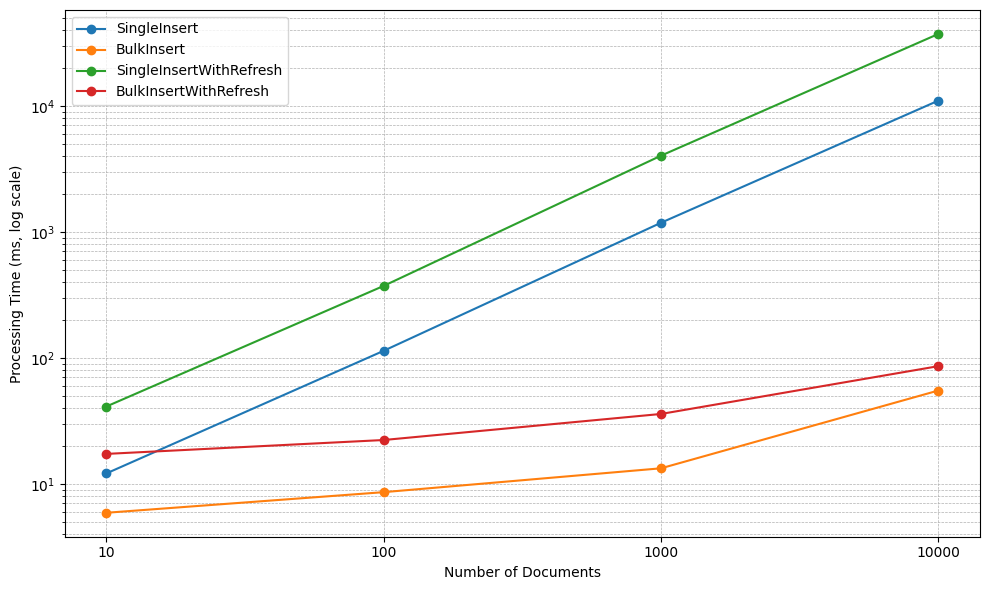
- BulkInsertがSingleInsertを圧倒(10,000件で約200倍)
- 即時検索可能に反映するためにBulkInsertWithRefreshが唯一の選択肢(SingleInsertWithRefreshの約433倍)
 なぜ
なぜSingleInsertWithRefreshは壊滅的に遅いのか
今回、SingleInsertWithRefreshのパフォーマンスが極端に低いことがわかりました。10,000件登録するのに37秒以上かかっています。これほどまでに遅くなってしまう理由は、Elasticsearchがデータを検索可能にするまでの内部的な仕組みにあります。
- Elasticsearchに登録されたデータは即座に検索可能になるわけではなく、まずインメモリバッファに保持され、「リフレッシュ(refresh)」の操作を経て、ディスクに書き出され検索可能になります。
- 「リフレッシュ(refresh)」の操作は軽い処理ではない
- メモリ上のデータをディスク上に書き出すためI/Oが生じる
- 内部的なキャッシュ構造を更新・再構築する必要がある
SingleInsertWithRefreshの場合
高コストなリフレッシュ処理がSingleInsertWithRefreshではドキュメント1件登録するたびに発生しています。
[リクエスト1]Doc1 -> メモリへ -> 即時リフレッシュ(ディスク書き込み & キャッシュ更新)
[リクエスト2]Doc2 -> メモリへ -> 即時リフレッシュ(ディスク書き込み & キャッシュ更新)
[リクエスト3]Doc3 -> メモリへ -> 即時リフレッシュ(ディスク書き込み & キャッシュ更新)
BulkInsertWithRefreshの場合
高コストな処理は最後の一度きりで、1件あたりのコストは劇的に小さくなります。
[リクエスト1]
Doc1 -> メモリへ
Doc2 -> メモリへ
...
Doc10000 -> メモリへ
-> 最後に一度だけリフレッシュ(ディスク書き込み & キャッシュ更新)
この根本的なメカニズムの違いが、両者の間に400倍以上もの圧倒的なパフォーマンス差を生み出しています。
まとめ
今回の検証から得られた結論を簡潔にまとめます。
-
スループットが最優先なら:
BulkInsertを使い、refresh_intervalは長めに設定するのが最適 -
即時検索性が必要なら:
BulkInsertWithRefreshが唯一の現実的な選択肢 -
アンチパターン:
SingleInsert、特にSingleInsertWithRefreshを大量データに対して使用することは避けるべき