MeCab・FAISS・Groqで作った日本語ビジネスコミュニケーション解析システム — ねまわし検出の実装詳細
English article by an Indian engineer who spent 2 months studying Japanese business linguistics to build this.
はじめに / Introduction
I'm Kunal Bisht — a developer from Pithoragarh, a small hill town in Uttarakhand, India.
I study Japanese (JLPT N4, targeting N3). About 8 months ago I started noticing something while reading about Japanese business culture: the NLP community has almost no practical tooling for one of the most important communication phenomena in Japanese corporate settings — nemawashi (根回し).
So I built TranscriptAI — a multilingual meeting intelligence platform that analyzes business meeting transcripts in English, Hindi, and Japanese, and actually understands what people mean, not just what they say.
This article explains the Japanese NLP decisions in detail: how I built the nemawashi detector, how MeCab morphological analysis drives keigo register detection, how I handled cross-script speaker identity, and what the accuracy iteration looked like across 5 versions.
🔗 Live demo: https://huggingface.co/spaces/KunalTheBeast/TranscriptAI
🔗 Source: https://github.com/aiKunalBisht/Transcript-ai
なぜ日本語ビジネスコミュニケーションが難しいか / Why Japanese Business Communication Is Hard for NLP
Standard NLP models — even large multilingual ones — struggle with Japanese business communication for a structural reason.
In English, "no" is said directly. In Japanese corporate culture, it almost never is.
Consider these phrases:
| Japanese | Literal translation | Actual meaning |
|---|---|---|
| 「少し難しいかもしれません」 | "This might be a bit difficult" | No |
| 「検討させてください」 | "Please let me consider it" | No |
| 「前向きに検討します」 | "I will consider it positively" | Probably no |
| 「なかなか厳しい状況です」 | "The situation is quite strict" | No |
| 「上と相談してみます」 | "I'll consult with my superiors" | No |
| 「おっしゃる通りですが…」 | "You are right, but..." | Disagreement incoming |
This is nemawashi — the practice of building consensus slowly and indirectly, where direct rejection is avoided entirely. An AI system that processes these utterances as neutral or positive is giving its users wrong information about meeting outcomes.
The same pattern exists in Hindi:
| Hindi | Actual meaning |
|---|---|
| "देखते हैं" (let's see) | No |
| "थोड़ा मुश्किल होगा" (it will be a bit difficult) | No |
| "बाद में बात करते हैं" (let's talk later) | Avoidance |
システムアーキテクチャ / System Architecture
Audio/Text Input
↓
[PII Masking Layer] ← APPI compliant, runs BEFORE any LLM call
↓
[Language Detection] ← langdetect + script detection
↓
┌──────────────────────────────────┐
│ Japanese Pipeline │
│ MeCab → fugashi → unidic-lite │
│ Keigo register detection │
│ Nemawashi pattern matching │
│ Cross-script speaker resolution │
└──────────────────────────────────┘
┌──────────────────────────────────┐
│ Hindi Pipeline │
│ Devanagari + Roman script │
│ 8 indirect speech patterns │
└──────────────────────────────────┘
┌──────────────────────────────────┐
│ English Pipeline │
│ Hedging pattern detection │
│ Sentence-transformers / TF-IDF │
└──────────────────────────────────┘
↓
[FAISS Vector Store] ← RAG for context retrieval
↓
[Groq LLM] → [Hallucination Guard] → Output
↓
[Streamlit UI — 7 tabs]
Stack summary:
| Layer | Technology |
|---|---|
| LLM | Groq (primary) → Ollama (fallback) → Mock (offline) |
| Speech-to-text | Groq Whisper API |
| Japanese tokenization | MeCab + fugashi + unidic-lite |
| RAG | FAISS vector store |
| Semantic similarity | Sentence-transformers → TF-IDF fallback |
| PII masking | Custom rule-based (APPI compliant) |
| Hallucination guard | Rule-based token overlap |
| API | FastAPI with async job queue |
| UI | Streamlit (7 tabs) |
| Deployment | Hugging Face Spaces |
| CI/CD | GitHub Actions (21 tests) |
PII マスキング設計 / PII Masking Design
This runs before any LLM call. No exceptions.
Japanese PII patterns include:
- Full names (姓名):
田中さん,田中部長,田中太郎 - Phone numbers: Japanese mobile format
090-XXXX-XXXX, landline03-XXXX-XXXX - Email addresses
- Company-internal identifiers
The masking replaces entities with typed placeholders: [NAME_1], [PHONE_1], [EMAIL_1]. The mapping is stored in memory for the session so the UI can optionally display de-anonymized output to the user, but the LLM only ever sees masked text.
This was designed for APPI (Act on the Protection of Personal Information) compliance — Japan's primary personal data protection law.
import re
from dataclasses import dataclass, field
from typing import Dict
@dataclass
class PIIMaskingResult:
masked_text: str
mapping: Dict[str, str] = field(default_factory=dict)
def mask_japanese_pii(text: str) -> PIIMaskingResult:
mapping = {}
counter = {"NAME": 0, "PHONE": 0, "EMAIL": 0}
# Email (run first — contains @ which breaks name patterns)
def replace_email(m):
key = f"[EMAIL_{counter['EMAIL']}]"
mapping[key] = m.group(0)
counter["EMAIL"] += 1
return key
text = re.sub(r'[\w.+-]+@[\w-]+\.[a-zA-Z]{2,}', replace_email, text)
# Japanese mobile and landline
def replace_phone(m):
key = f"[PHONE_{counter['PHONE']}]"
mapping[key] = m.group(0)
counter["PHONE"] += 1
return key
text = re.sub(r'0[789]0[-\s]?\d{4}[-\s]?\d{4}', replace_phone, text)
text = re.sub(r'0\d{1,4}[-\s]?\d{1,4}[-\s]?\d{4}', replace_phone, text)
# Japanese name patterns with honorifics/titles
# 田中さん、田中部長、田中課長、田中様
def replace_name(m):
key = f"[NAME_{counter['NAME']}]"
mapping[key] = m.group(0)
counter["NAME"] += 1
return key
text = re.sub(
r'[一-龯]{1,4}[一-龯ぁ-ん]{0,4}(?:さん|様|部長|課長|係長|社長|専務|常務|取締役|先生|氏)',
replace_name, text
)
return PIIMaskingResult(masked_text=text, mapping=mapping)
MeCabによる敬語レジスター検出 / Keigo Register Detection via MeCab
Japanese has three formal speech levels — 丁寧語 (teineigo), 尊敬語 (sonkeigo), 謙譲語 (kenjōgo) — collectively called keigo (敬語). Detecting which register a speaker is using tells you a lot about the meeting dynamics: who is deferring to whom, where the power gradient sits, whether a relationship is warming or cooling.
MeCab with unidic-lite gives per-token part-of-speech information including conjugation form, which is what keigo detection requires.
import MeCab
import fugashi
tagger = fugashi.Tagger()
# Keigo marker vocabulary
SONKEIGO_VERBS = {
'いらっしゃる', 'おっしゃる', 'なさる', 'ご覧になる',
'お召しになる', 'くださる', 'いただく'
}
KENJOGO_VERBS = {
'いたす', 'おる', '参る', '申す', '存じる',
'いただく', 'うかがう', 'さしあげる'
}
TEINEIGO_ENDINGS = {'ます', 'です', 'ました', 'でした', 'ません', 'ではありません'}
def detect_keigo_register(sentence: str) -> dict:
tokens = tagger(sentence)
sonkeigo_count = 0
kenjogo_count = 0
teineigo_count = 0
for word in tokens:
surface = word.surface
if surface in SONKEIGO_VERBS:
sonkeigo_count += 1
if surface in KENJOGO_VERBS:
kenjogo_count += 1
if surface in TEINEIGO_ENDINGS:
teineigo_count += 1
# Determine dominant register
if sonkeigo_count > 0:
dominant = "尊敬語" # Speaker is elevating the listener
elif kenjogo_count > 0:
dominant = "謙譲語" # Speaker is lowering themselves
elif teineigo_count > 0:
dominant = "丁寧語" # Polite but neutral
else:
dominant = "普通体" # Plain form — casual or internal monologue
return {
"dominant_register": dominant,
"sonkeigo_count": sonkeigo_count,
"kenjogo_count": kenjogo_count,
"teineigo_count": teineigo_count,
"formality_score": sonkeigo_count * 3 + kenjogo_count * 2 + teineigo_count
}
The formality_score is used downstream to flag register shifts within a single speaker's turns — a Japanese engineer suddenly dropping to 普通体 mid-meeting is a signal worth surfacing.
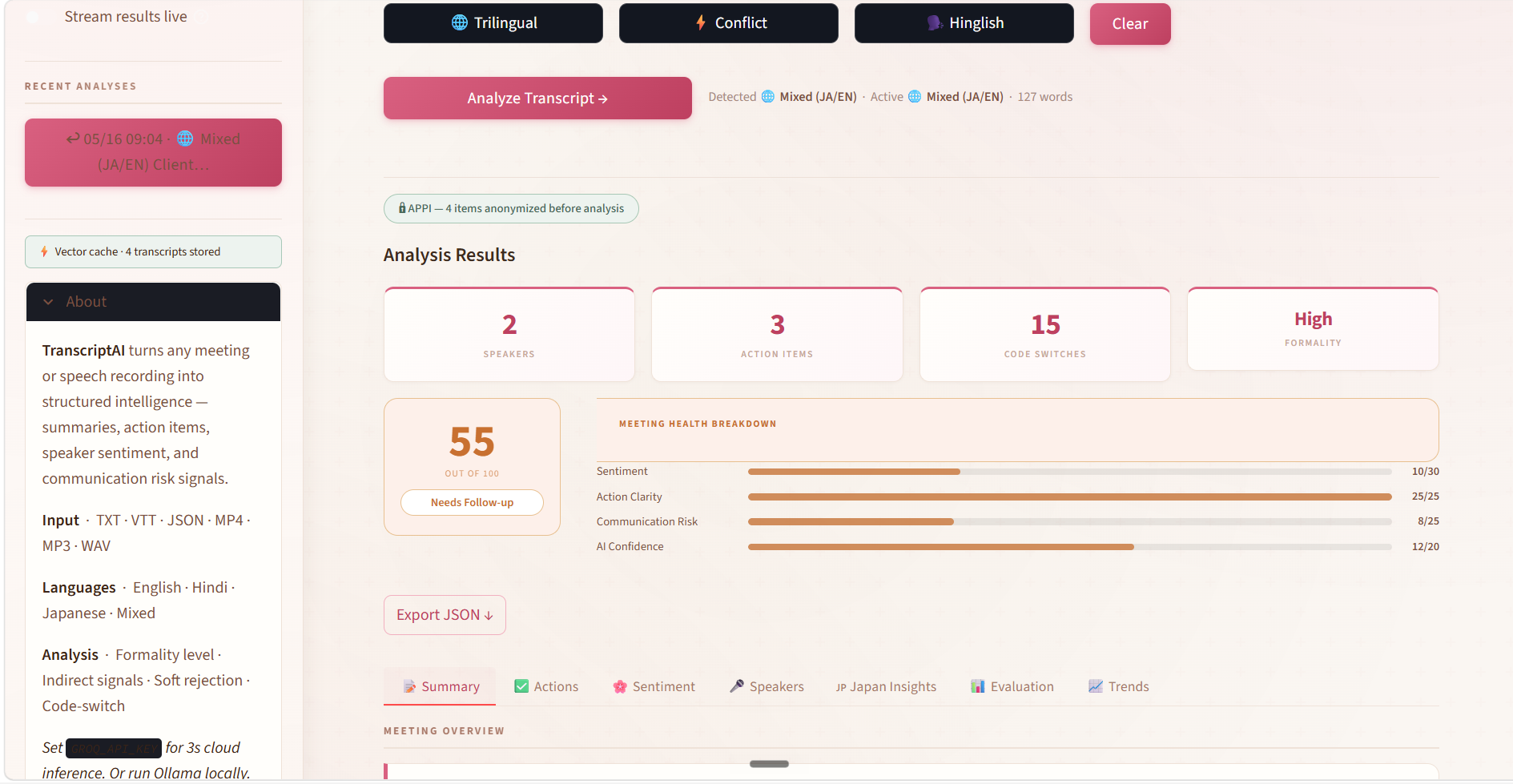
ねまわし検出の実装 / Nemawashi Pattern Detection
This was the hardest part of the project and the part that went through the most iteration.
I built 16 patterns organized into 5 categories:
Category 1: Direct difficulty expressions
- 「難しい」「厳しい」「困難」variants with modifiers
- Confidence varies by hedge strength: 「少し難しいかもしれません」(0.85) vs 「難しい部分もあります」(0.65)
Category 2: Deferral to superiors
- 「上と相談」「上司に確認」「部長に聞いてみます」
- These almost always mean: decision is already made, and it's no
Category 3: Time deferral
- 「また改めて」「後ほど」「今度」without a specific date
- Specificity is the key signal: "来週火曜日に" is genuine; "また今度" is not
Category 4: Positive-negative sandwiches
- 「おっしゃる通りですが…」「ごもっともですが…」「なるほど、ただ…」
- The agreement at the start is a social cushion. The content after 「が」or 「ただ」is the real message
Category 5: Consideration expressions
- 「検討します」「検討させてください」「前向きに検討します」
- In isolation, "検討します" has 0.7 rejection confidence. In a meeting where two or more of these appear from the same speaker, it approaches 0.95
import re
from dataclasses import dataclass
from typing import List
@dataclass
class NemawashiMatch:
pattern_id: str
category: str
matched_text: str
confidence: float
explanation_ja: str
explanation_en: str
NEMAWASHI_PATTERNS = [
{
"id": "NW_001",
"category": "difficulty_expression",
"pattern": r'(少し|ちょっと|なかなか|やや)?(難し|厳し|困難).{0,10}(かもしれません|と思います|ですね)',
"base_confidence": 0.82,
"explanation_ja": "困難を示す間接的な否定表現",
"explanation_en": "Indirect rejection via difficulty expression"
},
{
"id": "NW_002",
"category": "superior_deferral",
"pattern": r'(上|上司|部長|社長|役員).{0,8}(相談|確認|聞|判断)',
"base_confidence": 0.78,
"explanation_ja": "上位者への委譲による決定回避",
"explanation_en": "Deferral to superiors to avoid committing"
},
{
"id": "NW_003",
"category": "consideration_expression",
"pattern": r'(前向きに|ポジティブに)?検討(します|させてください|いたします)',
"base_confidence": 0.70,
"explanation_ja": "「検討」は多くの場合、暗黙の断りを意味する",
"explanation_en": "Consideration expressions are often implicit rejections"
},
{
"id": "NW_004",
"category": "positive_negative_sandwich",
"pattern": r'(おっしゃる通り|ごもっとも|なるほど|確かに).{0,20}(が[、,]|ですが|ただ|ただし|しかし)',
"base_confidence": 0.88,
"explanation_ja": "同意で始まり反論で終わる典型的なねまわし構造",
"explanation_en": "Classic nemawashi: agree-then-reject sandwich"
},
{
"id": "NW_005",
"category": "time_deferral",
"pattern": r'(また|改めて|後ほど|今度|いつか)(ご連絡|お話|検討|確認)',
"base_confidence": 0.75,
"explanation_ja": "具体的な日程なしの先送りは断りのシグナル",
"explanation_en": "Time deferral without specific date is a rejection signal"
},
{
"id": "NW_006",
"category": "indirect_impossibility",
"pattern": r'(対応|実施|実現).{0,8}(しかね|いたしかね|できかね)',
"base_confidence": 0.92,
"explanation_ja": "「しかねます」は最も丁寧な断り表現",
"explanation_en": "~しかねます is the most formal way to say 'I cannot' — higher confidence than difficulty expressions"
},
{
"id": "NW_007",
"category": "budget_resource_deferral",
"pattern": r'(予算|コスト|リソース|人員).{0,10}(の関係|の都合|の問題|次第)',
"base_confidence": 0.78,
"explanation_ja": "具体性のないリソース制約の言及は丁寧な回避",
"explanation_en": "Resource constraint cited without specifics = polite deflection"
},
{
"id": "NW_008",
"category": "timeline_vagueness",
"pattern": r'(スケジュール|時期|タイミング).{0,10}(調整|確認|検討|次第)',
"base_confidence": 0.72,
"explanation_ja": "具体的な日程なしのスケジュール調整は暗黙の断り",
"explanation_en": "Schedule adjustment without a concrete date is a soft no"
},
{
"id": "NW_009",
"category": "unresolvable_conditional",
"pattern": r'(もし|仮に|条件が整え).{0,15}(ば|たら).{0,20}(かもしれません|と思います|検討)',
"base_confidence": 0.80,
"explanation_ja": "条件が満たされないことを前提とした条件文",
"explanation_en": "Conditional framing signals the speaker expects conditions will not be met"
},
{
"id": "NW_010",
"category": "internal_process_deferral",
"pattern": r'(社内|弊社|我々).{0,8}(確認|検討|調整|プロセス|手続き)',
"base_confidence": 0.73,
"explanation_ja": "タイムラインなしで社内プロセスを引用するのは官僚的回避",
"explanation_en": "Citing internal process without timeline = bureaucratic deflection"
},
{
"id": "NW_011",
"category": "acknowledgement_no_commitment",
"pattern": r'(承知|了解|わかりました|なるほど)(いたしました|です).{0,5}$',
"base_confidence": 0.55,
"explanation_ja": "コミットメントなしで終わる承認表現",
"explanation_en": "Acknowledgement at end of turn with no following commitment — speaker heard but did not agree"
},
{
"id": "NW_012",
"category": "enthusiasm_deflation",
"pattern": r'(面白い|興味深い|良い案).{0,15}(ですが|ただ|ただし|一方で|反面)',
"base_confidence": 0.85,
"explanation_ja": "アイデアを褒めてから断る典型的なポジティブ・ネガティブサンドイッチ",
"explanation_en": "Complimenting the idea before rejecting it — classic positive-negative sandwich variant"
},
{
"id": "NW_013",
"category": "scope_limitation",
"pattern": r'(私|私ども|私たち).{0,8}(だけでは|の範囲では|の権限では)(判断|決定|対応)',
"base_confidence": 0.82,
"explanation_ja": "権限範囲の主張による責任回避",
"explanation_en": "Claiming scope limitation to avoid ownership — speaker is passing the decision upward"
},
{
"id": "NW_014",
"category": "passive_discomfort",
"pattern": r'(そうです|そうですね|まあ).{0,5}(ね[…。]|ねえ|…)',
"base_confidence": 0.45,
"explanation_ja": "間または省略記号を伴う「そうですね」は不快感や不同意のシグナル",
"explanation_en": "Trailing そうですね with pause or ellipsis signals discomfort — lowest confidence, needs context"
},
{
"id": "NW_015",
"category": "reexamination_request",
"pattern": r'(再度|改めて|もう一度|再検討).{0,10}(ご確認|お願い|いただけ|検討)',
"base_confidence": 0.76,
"explanation_ja": "既提示事項の再検討要求は直接批判を避けた不満シグナル",
"explanation_en": "Asking to re-examine something already presented = dissatisfaction signal without direct criticism"
},
{
"id": "NW_016",
"category": "responsibility_diffusion",
"pattern": r'(みんなで|チームで|皆さんで|全体で).{0,10}(話し合|確認|検討|判断|決め)',
"base_confidence": 0.68,
"explanation_ja": "集団への決定の拡散により個人の責任を回避",
"explanation_en": "Diffusing decision to a group removes individual accountability — common in nemawashi culture to avoid being the one who says no"
},
]
def detect_nemawashi(text: str, speaker_history: List[str] = None) -> List[NemawashiMatch]:
matches = []
for pattern_def in NEMAWASHI_PATTERNS:
regex_matches = re.finditer(pattern_def["pattern"], text)
for m in regex_matches:
confidence = pattern_def["base_confidence"]
# Boost confidence if same speaker has prior matches in this meeting
if speaker_history:
prior_count = sum(1 for h in speaker_history if pattern_def["id"] in h)
confidence = min(0.97, confidence + (prior_count * 0.05))
matches.append(NemawashiMatch(
pattern_id=pattern_def["id"],
category=pattern_def["category"],
matched_text=m.group(0),
confidence=confidence,
explanation_ja=pattern_def["explanation_ja"],
explanation_en=pattern_def["explanation_en"]
))
return matches
クロススクリプト話者同定 / Cross-Script Speaker Identity
A common real-world problem in Japanese business meetings: the same person appears under different name representations in the transcript.
- Meeting notes:
田中さん - Audio transcription:
Tanaka - Email subject line:
Director Tanaka - Someone else's reference:
田中部長
All four refer to the same person. If you don't resolve this, your per-speaker sentiment and action item assignment is broken.
My approach:
import unicodedata
from difflib import SequenceMatcher
# Katakana → Romaji mapping for common name readings
KATAKANA_TO_ROMAJI = {
'タナカ': 'Tanaka', 'スズキ': 'Suzuki', 'サトウ': 'Sato',
'ワタナベ': 'Watanabe', 'イトウ': 'Ito', 'ヤマモト': 'Yamamoto',
# ... extended map
}
def normalize_japanese_name(name: str) -> str:
"""Normalize a name to a canonical romaji form for comparison."""
# Strip honorifics
honorifics = ['さん', '様', '部長', '課長', '係長', '社長', '先生', '氏', 'さま', 'くん']
for h in honorifics:
name = name.replace(h, '')
name = name.strip()
# If katakana, convert to romaji
if all(unicodedata.name(c, '').startswith('KATAKANA') for c in name if c.strip()):
return KATAKANA_TO_ROMAJI.get(name, name)
return name
def resolve_speaker_identity(name_a: str, name_b: str, threshold: float = 0.75) -> bool:
"""
Returns True if name_a and name_b likely refer to the same person.
Uses normalized string similarity after stripping honorifics.
"""
norm_a = normalize_japanese_name(name_a).lower()
norm_b = normalize_japanese_name(name_b).lower()
if norm_a == norm_b:
return True
similarity = SequenceMatcher(None, norm_a, norm_b).ratio()
return similarity >= threshold
In practice, 田中 and Tanaka both normalize to something close enough that the similarity check catches them. 田中部長 and Director Tanaka also resolve correctly after honorific stripping.
ハルシネーション対策 / Hallucination Guard
The most important architectural decision in the system: the LLM never validates its own output.
A common pattern in LLM pipelines is to ask the model "is this correct?" as a self-check. This doesn't work — the model will agree with itself. I use rule-based token overlap instead.
from typing import Set
def extract_tokens(text: str) -> Set[str]:
"""Simple token set for overlap comparison."""
return set(re.findall(r'\b\w+\b', text.lower()))
def validate_action_item(
original_transcript: str,
extracted_action: str,
min_overlap_ratio: float = 0.4
) -> dict:
"""
Validate that an extracted action item has sufficient token overlap
with the source transcript. If not, flag as potential hallucination.
"""
source_tokens = extract_tokens(original_transcript)
action_tokens = extract_tokens(extracted_action)
if not action_tokens:
return {"valid": False, "reason": "empty_extraction"}
overlap = source_tokens.intersection(action_tokens)
overlap_ratio = len(overlap) / len(action_tokens)
return {
"valid": overlap_ratio >= min_overlap_ratio,
"overlap_ratio": round(overlap_ratio, 3),
"overlapping_tokens": list(overlap),
"reason": "sufficient_overlap" if overlap_ratio >= min_overlap_ratio else "low_overlap_possible_hallucination"
}
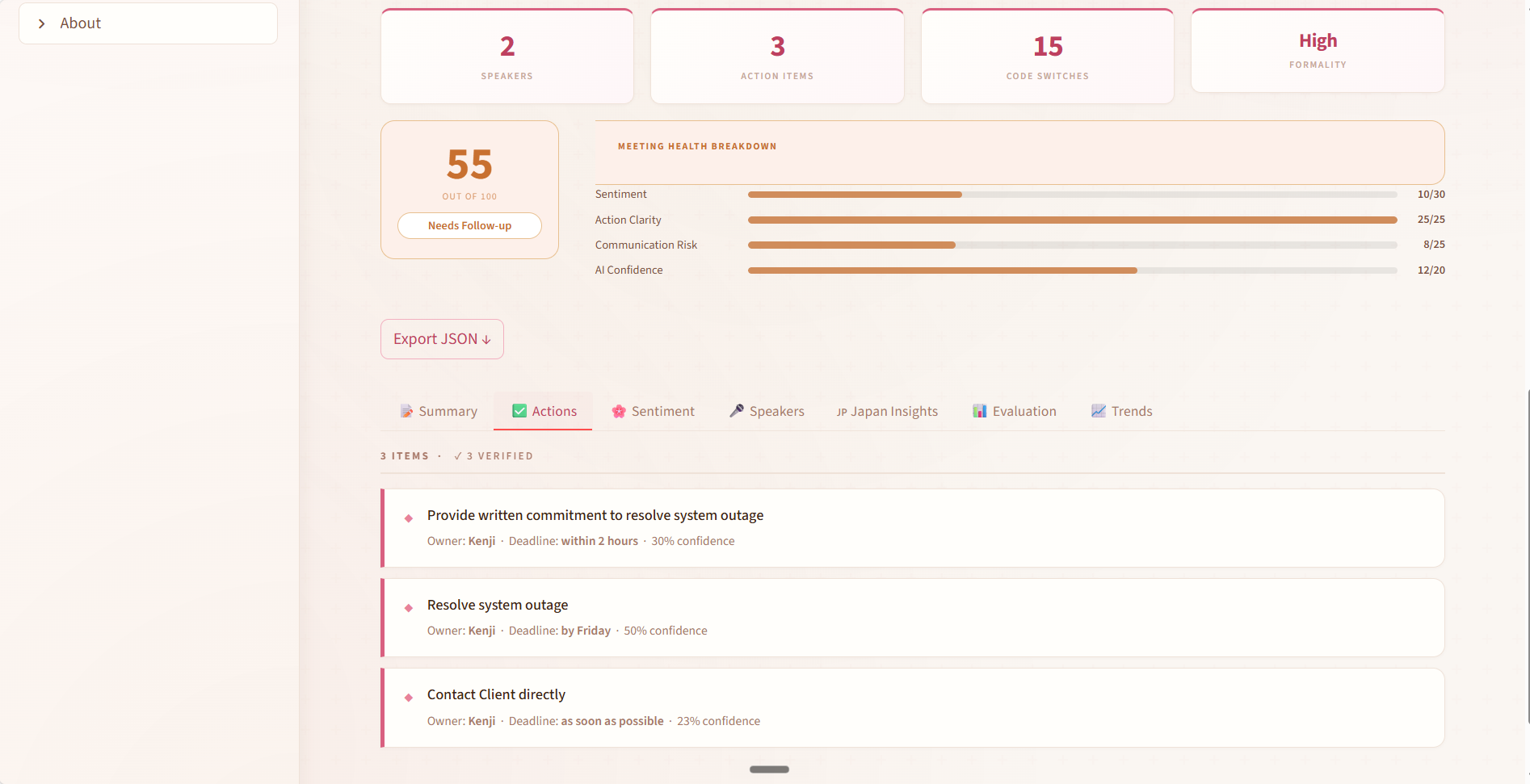
This catches cases where the LLM generates plausible-sounding action items that have no basis in the actual transcript — which happens more often than expected in multilingual inputs where the model may "fill in" what it expects a business meeting to contain.
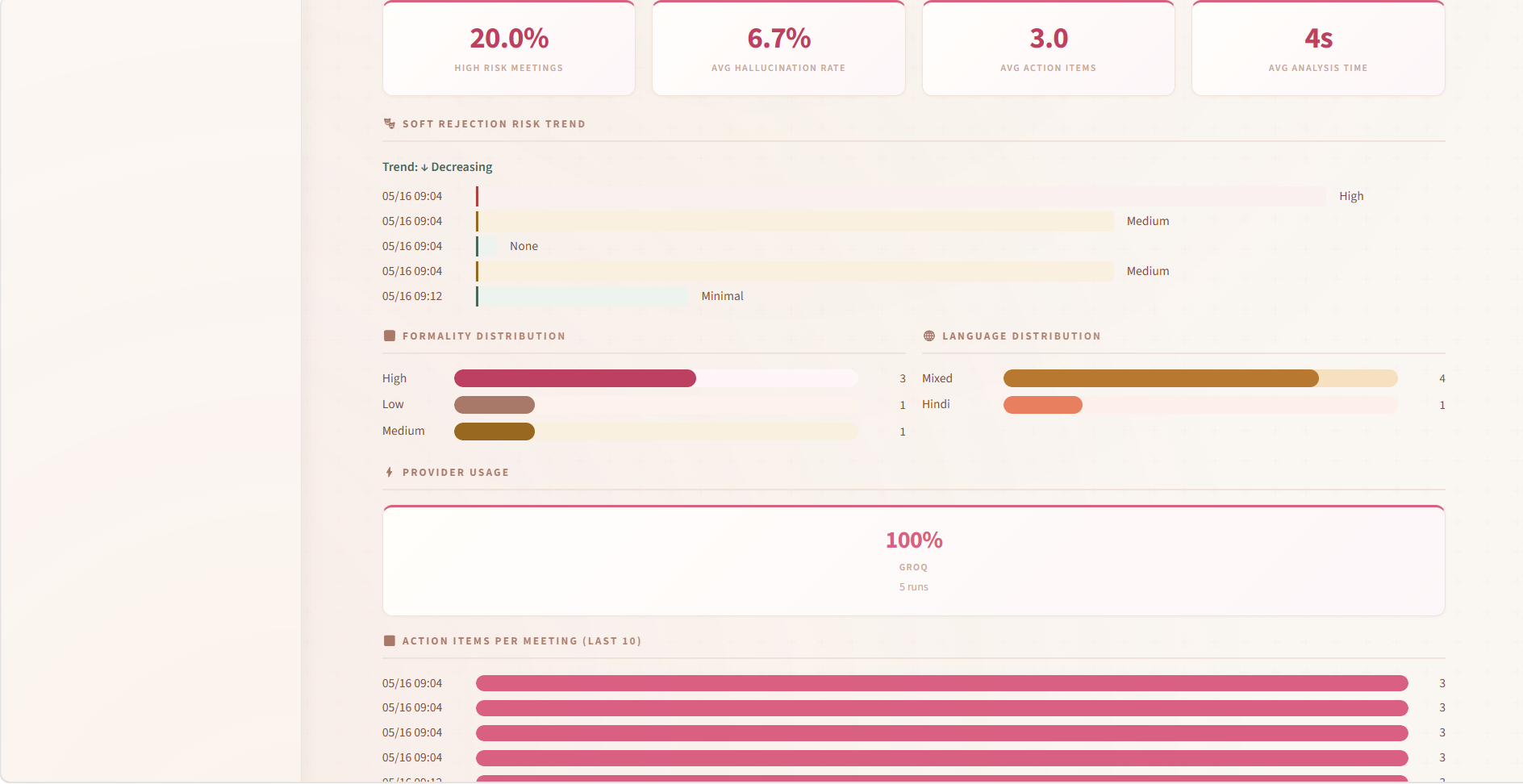
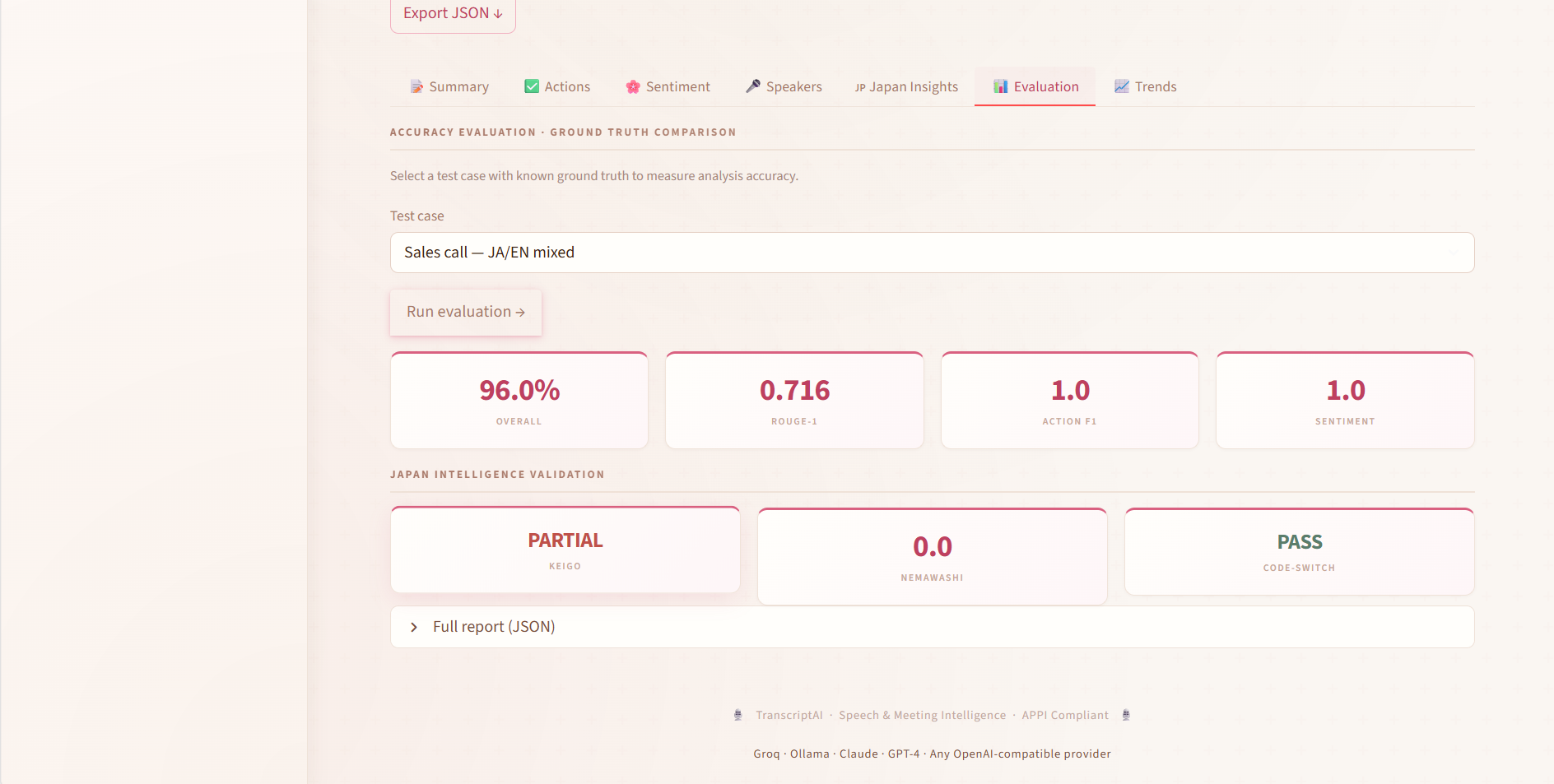
精度改善の反復 / Accuracy Iteration History
The system went through 5 major versions over ~2 months:
| Version | Score | Key change |
|---|---|---|
| v1 | 22% | Baseline — exact string matching only |
| v2 | 45% | Fuzzy name matching + code-switch detection |
| v3 | 65% | Cultural ground truth dataset + MeCab JA tokenization |
| v4 | 75–85% | Hallucination guard + bilingual action item extraction |
| v5 | 93% | Tone intelligence + optimal speaker assignment algorithm |
The biggest single jump was v2 → v3. Adding culturally-grounded ground truth (manually labeled Japanese meeting transcripts with nemawashi annotations) and replacing regex-only tokenization with proper MeCab morphological analysis added 20 percentage points. Exact string matching on Japanese is particularly bad because of script mixing, honorific variation, and verb conjugation — 来ます, 来ました, 来られます are all forms of 来る and need to be treated as the same verb in action item extraction.
リポジトリ構成 / Repository Structure
Transcript-ai/
├── api/
│ ├── main.py # FastAPI app, async job queue
│ ├── routers/
│ │ ├── analyze.py # POST /analyze, /analyze/batch
│ │ └── transcribe.py # POST /transcribe (Whisper)
├── core/
│ ├── pii_masking.py # APPI-compliant masking
│ ├── language_detection.py
│ ├── japanese/
│ │ ├── mecab_pipeline.py # Tokenization + keigo detection
│ │ ├── nemawashi.py # 16 patterns + confidence scoring
│ │ └── speaker_identity.py # Cross-script resolution
│ ├── hindi/
│ │ └── indirect_speech.py # 8 patterns, Devanagari + Roman
│ ├── hallucination_guard.py # Token overlap validation
│ └── faiss_store.py # RAG vector store
├── ui/
│ └── streamlit_app.py # 7-tab Streamlit interface
├── tests/
│ └── ... # 21 tests, all passing
├── .github/
│ └── workflows/ci.yml # GitHub Actions CI
├── Dockerfile
├── CHANGELOG.md # Full v1→v5 history
└── CONTRIBUTING.md
今後の課題 / What's Next
Things I know need improvement:
-
Nemawashi pattern coverage — 16 patterns is a starting point. There are regional and industry-specific variants I haven't covered. Finance nemawashi and government nemawashi read differently from tech-sector nemawashi.
-
Speaker diarization — Currently the system expects labeled speaker turns. Automatic diarization from raw audio (without pre-labeled segments) is the obvious next step.
-
N3-level Japanese review — My Japanese is JLPT N4. Some nuances in the pattern definitions were validated against reference material, but a native speaker review of the nemawashi corpus would be valuable. If anyone reading this wants to collaborate on this, I'd genuinely appreciate it.
-
Fine-tuned model for Japanese indirect speech — The rule-based approach works well but a dedicated classifier trained on actual nemawashi examples would generalize better to unseen patterns.
おわりに / Closing
I'm a developer from a small hill town in India who learned Japanese NLP because the problem was real and interesting and nobody had built a good solution for it.
If you work with Japanese business communication, run multilingual meeting operations, or are building tools in this space — I'd like to hear from you.
- 🔗 Live: https://huggingface.co/spaces/KunalTheBeast/TranscriptAI
- 💻 GitHub: https://github.com/aiKunalBisht/Transcript-ai
- 💼 LinkedIn: https://linkedin.com/in/kunalhere
- 📧 kunalbisht909@gmail.com
Currently looking for AI/ML Engineer or GenAI Developer roles — Indian companies and Japanese MNCs operating in India both welcome.
日本語でのコメントも歓迎します。
Tags: #NLP #自然言語処理 #MeCab #日本語 #Python #LLM #FAISS #FastAPI #GenAI #機械学習 #JLPT #OpenToWork