PostgreSQL 9.4 で JSON 関連機能が強化された。
- jsonb 型の追加
- jsonb 関係演算子の追加
- GIN インデックスの jsonb サポート
- JSON サポート関数の拡充
以前 PostgresSQL 9.3 の JSON サポートについてまとめた。
本稿はその続編であり、PostgreSQL 9.4 になって JSON どう進歩したのかをユーザ視点で検証したい。(また長いんだこれが)
修正リクエストは歓迎します。
なお本稿では、大文字の JSON はその書式やデータを表し、PostgreSQL の型を指す場合に json や jsonb のように小文字を使って区別する。検証は素でソースビルドした beta2 版の PostgreSQL 9.4 を仮想環境上の CentOS 7 上で行った。
jsonb 見参
9.4 で追加された jsonb 型は JSON テキストをバイナリ表現に変換して保持するデータ型である。
これまでの json 型の実態は JSON テキストをそのまま文字列として保持しただけのものであった。JSON 内部のフィールド値を参照するたびに JSON テキストをパースする必要があり、非効率であった。
jsonb では入力時にのみ JSON テキストの解析し、正規化されたバイナリ書式でカラムに格納される。json よりもフィールドアクセス、値評価等の効率が格段に向上しているようだ。
新たに追加された関数 jsonb_typeof() で、jsonb の値の型を調べることができる。
SELECT value, jsonb_typeof(value)
FROM jsonb_array_elements(
'[1, 1.00, 10.0e-3, "1", true, "2014-01-01T12:34:56", null, "", {}, []]'
);
value | jsonb_typeof
-----------------------+--------------
1 | number
1.00 | number
0.0100 | number
"1" | string
true | boolean
"2014-01-01T12:34:56" | string
null | null
"" | string
{} | object
[] | array
(10 rows)
jsonb_typeof() が返すのは JSON 仕様の型名であって、jsonb の内部の実装型名ではない。ドキュメントによれば、JSON の基本型に対応して SQL の text、numeric、boolean が内部で使われているようだ。number では数値の精度が保存されている。
さっそく内部型の number で演算してみよう。
SELECT ('{"a":1}'::jsonb->>'a') + 1;
ERROR: operator does not exist: text + integer
SELECT ('{"a":1}'::jsonb->'a') + 1;
ERROR: operator does not exist: jsonb + integer
SELECT ('{"a":1}'::jsonb->'a') + ('{"a":1}'::jsonb->'a');
ERROR: operator does not exist: jsonb + jsonb
残念。
->> 系演算子で取り出した値はテキストに書き戻さる。jsonb の内部型にアクセスすることはできず、jsonb 型同士の演算もサポートされないようだ。
結局フィールド値を使うには、書き戻されたテキストからキャストなどで目的の型に変換する必要がある。
では、JSONデータを操作することはできるようになったのであろうか。
-- たとえば連結
SELECT '{"a":1}'::jsonb || '{"b":2}'::jsonb;
ERROR: operator does not exist: jsonb || jsonb
-- フィールドの更新
UPDATE hoge SET
jsonb_data->>'name' = '太郎'
WHERE id = 1;
ERROR: syntax error at or near "->>"
UPDATE hoge SET
jsonb_data->'name' = '"太郎"'::jsonb
WHERE id = 1;
ERROR: syntax error at or near "->"
残念。
jsonb でも json 同様、データの変更操作は許されていない。
ユーザからしてみれば、 内部型にアクセスできず、フィールド操作もできないのであれば jsonb となっても表面上これまでの json と変わらない。
jsonb と json の使い勝手に違いはあるのだろうか。
追記: jsonb の連結やフィールド削除は 9.5 でサポートされる。
jsonb vs json
まず jsonb は json や text型 JSON と相互に変換できる。
-- text to json
SELECT '{"name":"hoge","size":[1,2,3]}'::json;
json
--------------------------------
{"name":"hoge","size":[1,2,3]}
(1 row)
-- json to jsonb
SELECT '{"name":"hoge","size":[1,2,3]}'::json::jsonb;
jsonb
-------------------------------------
{"name": "hoge", "size": [1, 2, 3]}
(1 row)
-- text to jsonb
SELECT '{"name":"hoge","size":[1,2,3]}'::jsonb;
jsonb
-------------------------------------
{"name": "hoge", "size": [1, 2, 3]}
(1 row)
-- jsonb to text
SELECT '{"name":"hoge","size":[1,2,3]}'::jsonb::text;
text
-------------------------------------
{"name": "hoge", "size": [1, 2, 3]}
(1 row)
-- jsonb to binary 変換できない
SELECT '{"name":"hoge","size":[1,2,3]}'::jsonb::bytea;
ERROR: cannot cast type jsonb to bytea
ただし、完全な可逆ではない。
jsonb では入力時の JSON テキストをバイナリに変換するにあたって以下のような正規化を行う。
- フィールドのキーの重複を排除する。同じキーがあれば最後に現れたフィールドの値だけが採用され、それ以外は失われる(last win)
- フィールドはキー文字列でソートされる。その順序は辞書順ではない
- JSONテキストで整形用に入れた改行やインデントといった空白文字は失われる
- Unicode エスケープと指数表現は変換処理後の値で保存される
-- last win
SELECT '{"y":1, "x":2, "y":3}'::jsonb;
jsonb
------------------
{"x": 2, "y": 3}
(1 row)
-- 辞書順ではない
SELECT '{"aa":1, "x":2, "y":3}'::jsonb;
jsonb
---------------------------
{"x": 2, "y": 3, "aa": 1}
(1 row)
-- インデント意味なし
SELECT
'{
"conf":{
"name":"hoge",
"data":[3,2,1]
}
}'::jsonb;
jsonb
-----------------------------------------------
{"conf": {"data": [3, 2, 1], "name": "hoge"}}
(1 row)
-- Unicodeエスケープされた文字や数値の指数表現は保持されない。
SELECT '["\u3042", 0.1e-6]'::jsonb, '["\u3042", 0.1e-6]'::json;
jsonb | json
-------------------+--------------------
["あ", 0.0000001] | ["\u3042", 0.1e-6]
(1 row)
jsonb と json の使い分けを考えてみると、json をあえて使う積極的な理由があまりない。JSON 形式の設定やプレファレンスなど、JSON の内容を人間も読み、しかも DB 側で内容に関知しないようなデータ構造を格納するには json でいいかもしれない。
今後はほとんどの場合 jsonb の方が採用されていくだろう。
JSON 演算子
PostgreSQL 9.3 で定義された JSON 演算子(->, ->>, #>, #>>)は jsonb でも使える。
jsonb の -> 系演算子は jsonb 型で値を返し、->> 系演算子では文字列に書き戻された値を text 型で返す。
バイナリ化によってJSON演算子によるアクセス速度は向上しているはずだ。本稿では検証しないが、ググると json よりは 20 倍という数字もある。(参考資料参照)
9.3 では JSON リテラルから直接これらの演算子を使えたはず(?)だが、9.4ではエラーになる。明示的に json か jsonb でキャストして型を指定しなければならない。
SELECT '{"aaa":100}'->>'aaa';
ERROR: operator is not unique: unknown ->> unknown
SELECT '{"aaa":100}'::json->>'aaa';
SELECT '{"aaa":100}'::jsonb->>'aaa';
jsonb データも json 同様 immutable で内部のデータを変更することはできず、配列型や hstore 型にあるような操作演算子・関数も jsonb に提供されなかった。この点、将来の PostgreSQL で拡張されると期待していいのものだろうか。
そもそも JSON サポートはドキュメント指向レベルの NoSQL への対応を目指したものであり、単なる Key-Value ストアとは焦点が違う。NoSQL である JSON をわざわざ SQL で操作できるようにするのはおかしな話だ。
jsonb は hstore をベースに実装されているらしいので、操作関連の実装もやろうと思えばできたはずで、おそらく方針として今後も提供されることはないのだろう。
どうしてもと言うなら、むりやり文字列ベースの操作でなんとかできないこともないが、実用にはやっぱりちょっと無理があるw。
-- jsonb が正規化されることを利用して連結操作
SELECT replace(
concat_ws('!!',
'{"a":1, "b":2}'::text,
'{"a":2, "c":3}'::text
),
'}!!{', ', '
)::jsonb
;
replace
--------------------------
{"a": 2, "b": 2, "c": 3}
(1 row)
関係演算子
jsonb 型には比較演算子(=, <>, >, >=, <, <=)がサポートされ、さらに包含演算子(@>, <@)、存在演算子(?, ?|, ?&)が拡張されている。残念ながらこれら関係演算子は json 型には提供されない。
比較演算子
正規化された jsonb でデータの大小関係が定義され、比較演算子が適用できるようになった。
等号演算子で jsonb 同士の同値性を判定できる。jsonb の値は SQL 基本型と直接比較できず、どちらかの型を変換しなければならない。
SELECT '{"a":1, "b":2}'::jsonb = '{"b":2, "a":1}'; -- TRUE
SELECT '[1,2,3]'::jsonb = '[3,2,1]'; -- FALSE
SELECT '{"x":1}'::jsonb->'x' = 1; -- ERROR 残念
SELECT '{"x":1}'::jsonb->'x' = '1'::jsonb; -- TRUE
SELECT '{"x":1}'::jsonb->'x' = '1'; -- TRUE リテラルの暗黙変換
SELECT '{"x":1}'::jsonb->'x' = '1.00'; -- TRUE
SELECT '{"x":1}'::jsonb->>'x'::int = 1; -- TRUE
SELECT '{"x":1}'::jsonb->'x' = to_json(1)::jsonb; -- TRUE
SELECT '{"x":"a"}'::jsonb->'x' = 'a'; -- ERROR 残念
SELECT '{"x":"a"}'::jsonb->'x' = '"a"'::jsonb; -- TRUE
SELECT '{"x":"a"}'::jsonb->'x' = '"a"'; -- TRUE リテラルの暗黙変換
SELECT '{"x":"a"}'::jsonb->>'x' = 'a'; -- TRUE
SELECT '{"x":"a"}'::jsonb->'x' = to_json('a'::text)::jsonb; -- TRUE
SELECT ('{"x":null}'::jsonb->'x') IS NULL; -- FALSE
SELECT ('{"x":null}'::jsonb->>'x') IS NULL; -- TRUE
SELECT ('{"a":1}'::jsonb->'x') IS NULL; -- TRUE
SELECT jb_data->'category', count(*) FROM entries
WHERE jb_data->'tags' = '["PostgreSQL", "JSON"]'
AND (jb_data->>'stars')::int = 5
GROUP BY jb_data->'category'
不等号演算子で、jsonb の大小関係を判定することができる。
SELECT '{"x":1}'::jsonb < '{"x":2}'; -- TRUE フィールド値
SELECT '{"aa":100}'::jsonb < '{"x":1}'; -- TRUE フィールド名 辞書順
SELECT '{"xx":100}'::jsonb < '{"a":1, "b":1}'; -- TRUE フィールド数
SELECT '[1, 1]'::jsonb < '[1, 1, 1]'; -- TRUE 要素数
SELECT '{"x":1}'::jsonb->'x' < 2; -- ERROR 残念
SELECT '{"x":1}'::jsonb->'x' < '2'::jsonb; -- TRUE
SELECT '{"x":"a"}'::jsonb->'x' < '"2"'::jsonb; -- TRUE
SELECT '"a"'::jsonb < '1'::jsonb; -- TRUE string より number の方が"大きい"
SELECT '"aa"'::jsonb < '"b"'::jsonb; -- TRUE 辞書順で評価されている
SELECT max(json_data->'like') FROM entries; -- ERROR 残念
ERROR: function max(jsonb) does not exist
SELECT * FROM entries
WHERE jb_data->'follower' > jb_data->'favorite' -- OK
AND jb_data->'points' > to_json(10)::jsonb
ORDER BY jb_data->'like' DESC -- ソートにも使える
jsonb で定義された大小関係のルールは、アプリケーション的には意味を持たせにくい。
SELECT value FROM jsonb_array_elements(
'[2, 1, 1.0, "a", ["a"], true, "b", "aa", null, "", 0, {},
{"b":2}, {"b":1, "a":1}, {"b":2, "a":1}, {"aa":1, "b":1},
[2],[1,1,1],[1,2],[1,1],[],{"aa":1}]'
) order by value;
value
------------------
[] -- なぜか空配列が最も"小さい"
null -- [] < null
"" -- null < string
"a" --
"aa" -- 辞書順
"b" --
0 -- string < number
1.0 -- 1 = 1.0 だが、Unstable Sort のようで、結果順序は不定になる
1 --
2 --
true -- number < boolean
["a"] -- boolean < array
[2] -- array<string> < array<number>
[1, 1] -- 要素数順
[1, 2] -- 同要素数なら要素値順
[1, 1, 1] --
{} -- array < object
{"aa": 1} -- キーの辞書順 -- object 内のフィールドのソート順とは一致しない
{"b": 1} --
{"a": 1, "b": 1} -- フィールド数順
{"a": 1, "b": 2} -- フィールド数が同じなら値順
{"b": 1, "aa": 1} -- 正規化後のフィールド順で評価される
(22 rows)
包含演算子
PostgreSQL では、わりと自由に演算子を拡張することができるらしく、標準 SQL にない演算子が型によって多数定義されている。慣れない人には @> など、SQLの演算子としてはちょっと奇妙なスタイルに見える。配列型や hstore 型にも同様の演算子があり、意味が統一されているようなので、これらはポスグレ民にはおなじみの表現なのだろう。
@>と<@はJSON 内部構造の部分関係をチェックする。
jsonb @> jsonb ( L ⊃ R )
jsonb <@ jsonb ( L ⊂ R )
SELECT '{"a":1, "b":2, "c":3}'::jsonb @> '{"c":3, "a":1}'; -- TRUE
SELECT '{"a":1, "b":2, "c":3}'::jsonb @> '{"c":3, "a":100}'; -- FALSE
SELECT '{"a":1, "b":2, "c":3}'::jsonb <@ '{"c":3, "a":1}'; -- FALSE
SELECT '{"a":{"x":1, "y":2}}'::jsonb @> '{"x":1}'; -- FALSE 階層をたどらない
SELECT '{"a":{"x":1, "y":2}}'::jsonb @> '{"a":{"x":1}}'; -- TRUE 子階層も部分関係が評価される
SELECT '{"a":{"x":1, "y":2}}'::jsonb @> '{"a":{"x":1, "y":2}}'; -- TRUE
SELECT '[1, 2, 3]'::jsonb @> '[2, 1]'; -- TRUE 配列要素の順序を見ない
SELECT '[1, 2, 3]'::jsonb @> '[2, 4]'; -- FALSE
SELECT '[1, 2, 3]'::jsonb <@ '[2, 1]'; -- FALSE
SELECT '[1, 2, 3]'::jsonb @> '[1, 1]'; -- TRUE
SELECT '{"a":[1,2,3]}'::jsonb @> '{"a":[3]}'; -- TRUE
SELECT '{"a":[1,2,3]}'::jsonb @> '{"a":[3,2,1]}'; -- TRUE 配列要素の順序を見ない
存在演算子
存在演算子 ?、?|、?& はJSON内の要素の存在をチェックするのだが、クセがあるので注意が必要だ。
jsonb ? text (has a)
jsonb ?| text[] (any of)
jsonb ?& text[] (all of)
jsonb を text 型(の配列)と比較する。
JSON が object 型の場合はフィールド名の存在をチェックする。
JSON が array 型の場合は配列要素の値の存在をチェックし、しかも string 型の要素しかテストできない。
-- object
SELECT '{"a":1, "b":2, "c":3}'::jsonb ? 'a'; -- TRUE
SELECT '{"a":1, "b":2, "c":3}'::jsonb ? 'x'; -- FALSE
SELECT '{"a":1, "b":2, "c":null}'::jsonb ? 'c'; -- TRUE
SELECT '{"a":1, "b":2, "c":{"x":3}}'::jsonb ? 'x'; -- FALSE 階層をたどらない
-- array
SELECT '["a", 1, true]'::jsonb ? 'a'; -- TRUE
SELECT '["a", 1, true]'::jsonb ? 1; -- ERROR
SELECT '["a", 1, true]'::jsonb ? '1'; -- FALSE number は判定できない
SELECT '["a", 1, true]'::jsonb ? 1::text; -- FALSE number は判定できない
SELECT '["a", 1, true]'::jsonb ? true; -- ERROR
SELECT '["a", 1, true]'::jsonb ? 'true'; -- FALSE boolean は判定できない
SELECT '[{"a":1},[1]]'::jsonb ? '{"a":1}'; -- FALSE object は判定できない
SELECT '[{"a":1},[1]]'::jsonb ? '[1]'; -- FALSE array は判定できない
-- いずれか存在する
SELECT '{"a":1, "b":2, "c":3}'::jsonb ?| ARRAY['a', 'x']; -- TRUE
SELECT '{"a":1, "b":2, "c":3}'::jsonb ?| '{a, x}'; -- TRUE text配列のリテラル
SELECT '["a", "b", "c"]'::jsonb ?| '{a, x}'; -- TRUE
SELECT '[1, 2, 3]'::jsonb ?| '{1, 100}'; -- FALSE number は判定できない
SELECT '[1, 2, 3]'::jsonb ?| ARRAY[1, 100]; -- ERROR
-- すべて存在する
SELECT '{"a":1, "b":2, "c":3}'::jsonb ?& ARRAY['a', 'c']; -- TRUE
SELECT '{"a":1, "b":2, "c":3}'::jsonb ?& ARRAY['a', 'x']; -- FALSE
SELECT '{"a":1, "b":2, "c":3}'::jsonb ?& '{a, c}'; -- TRUE
SELECT '{"a":1, "b":2, "c":3}'::jsonb ?& '{a, a, a}'; -- TRUE
SELECT '["a", "b", "c"]'::jsonb ?& '{a, c}'; -- TRUE
SELECT '["a", "b", "c"]'::jsonb ?& '{a, x}'; -- FALSE
SELECT '["a", "b", "c"]'::jsonb ?& '{a, a, a}'; -- TRUE
SELECT '[1, 2, 3]'::jsonb ?& '{1, 2}'; -- FALSE number は判定できない
SELECT * FROM hoge
WHERE prof @> '{"gender":"Male", "class":"Programmer"}'
AND prof->'items' ? 'Mac'
AND prof->'skills' ?& '{PostgreSQL, Linux, Ruby, Driving, Cooking, Housekeeping}'
AND prof->'languages' ?| '{English, 日本語, tlhIngan Hol}'
JSON 関数
PostgreSQL 9.4 になって多くの JSON 関数が追加されている。
json 用 と jsonb 用の関数は別立てになっており、それぞれ json_to_record()、 jsonb_to_record() のように関数名のプレフィックスで区別される。
JSON 生成関数
基本型データから JSON を生成する関数がいくつか追加された。しかしこれらは json_*() 系のみで、jsonb_*() 系の生成関数は用意されなかった。基本型データから jsonb を生成したい場合には、to_json() などを使っていったん json 型データを作成後、jsonb 型に変換することになる。
json_build_array() と json_build_object() は可変長引数をとり、与えられた引数から json を作成する。
SELECT json_build_array(1, 2, 'Fizz', TRUE, array[1], '{"a": 1}'::jsonb, NULL);
json_build_array
-------------------------------------------
[1, 2, "Fizz", true, [1], {"a": 1}, null]
(1 row)
SELECT json_build_object('i', 1, 's', 'a"', 'a', array['x'], 'b', TRUE, 'c', '{"a": "b"}'::json, 'n', NULL);
json_build_object
--------------------------------------------------------------------------------
--
{"i" : 1, "s" : "a\"", "a" : ["x"], "b" : true, "c" : {"a": "b"}, "n" : null
}
(1 row)
json_object() は text 型配列で与えれらた要素から json を構築する。number と boolean を string 扱いするので注意。
SELECT json_object(array['a', '1', 'b', 'X,Y', 'c', 'true', 'd', '{"e
":1}', 'n', NULL]);
json_object
-----------------------------------------------------------------------
{"a" : "1", "b" : "X,Y", "c" : "true", "d" : "{\"e\":1}", "n" : null}
(1 row)
SELECT json_object('{a, 1, b, "X,Y", c, true, d, null}');
json_object
----------------------------------------------------
{"a" : "1", "b" : "X,Y", "c" : "true", "d" : null}
(1 row)
SELECT json_object('{{a, 1}, {b, X}, {c, true}, {d, null}}');
json_object
--------------------------------------------------
{"a" : "1", "b" : "X", "c" : "true", "d" : null}
(1 row)
SELECT json_object('{a, b, c, d}', '{1, X, true, null}');
json_object
--------------------------------------------------
{"a" : "1", "b" : "a", "c" : "true", "d" : null}
(1 row)
集約関数に json_object_agg() が追加されている。これは key と value を集約して json を構築する。
SELECT json_object_agg(key, value::json)
FROM (VALUES
('a', '1'), ('b', '"x"'), ('c', 'true')
) AS r(key, value);
json_object_agg
------------------------------------
{ "a" : 1, "b" : "x", "c" : true }
(1 row)
生成関数が増えて一見便利になったようだが、データを引数形式で用意するのは結構難しい。基本的にストアドプロシージャ内でしか使えないものと思ったほうがよさそうだ。
例外的なのは json_object_agg() 関数だ。これはクエリーでも使い出がある。
json_object_agg()
json_object_agg() を使うと、行から key と value を集約して JSON データを作成することができる。
もともと 9.3 に json_each() という JSON オブジェクトを key-value 行に分解する関数はあった。json_object_agg() はちょうど json_each() の逆変換をする関数にあたる。つまりこれで JSON データ内容を SQL で操作できるツールが揃ったこと意味する。
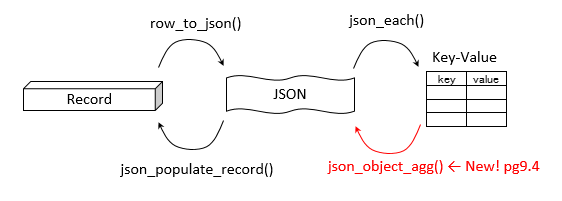
json_object_agg() と jsonb_each() の合わせ技を駆使すれば SQL で JSON フィールドの更新・追加・削除などができるだろう。
-- jsonb から指定したフィールドを削除する。
SELECT json_object_agg( key, value )::jsonb
FROM jsonb_each( '{"a":1, "b":"x", "c":true}' )
WHERE key <> 'b';
json_object_agg
---------------------
{"a": 1, "c": true}
(1 row)
JSON to Record
JOSN をレコードに変換する関数はだいぶ増えた。
9.3 では json_populate_record() / json_populate_recordset() の2個だけだったが、9.4 ではさらに json_to_record() / json_to_recordset() という関数が追加されており、それぞれ json_*() 系と jsonb_*() 系で合計8個の関数群となる。
- json_populate_record() 系
- json_populate_record() / jsonb_populate_record()
- json_populate_recordset() / jsonb_populate_recordset()
- json_to_record() 系
- json_to_record() / jsonb_to_record()
- json_to_recordset() / jsonb_to_recordset()
これまでの json_populate_record() 系と新たな json_to_record() 系はどう違うのか。
JSON データをレコードに展開するには、フィールド値をどのSQLデータ型に変換するかを指定する手段が必要になる。
これまでの json_populate_record() 系では、第1引数に型変換のひな形となるレコードを渡すようにしていた。基本的には NULL::table_name のようにNULLをテーブルや複合型でキャストして指定するが、これはトリッキーで分かりにくい。また事前に定義されているレコード型(テーブルや複合型)を必要とするという柔軟性の低さもあって、使い勝手もいまいちだ。
9.4 ではこの点を仕切り直したかったのか、json_to_record() 系関数を追加し、型指定の問題を SQL 構文の拡張によって解決することにしたようだ。
json_to_record() 系の関数では、AS 句を追加してレコードのカラム名と値の型を明示的に定義する。
SELECT * FROM jsonb_to_record (
'{"id":" 123", "name":"太郎", "passwd":"123456", "lastdt":"20140101", "pts":2, "tags":"{JSON, 9.4}", "premium":false}'
) AS acc (id int, name bytea, pts numeric(3,2), lastdt timestamptz, tags text[],
premium boolean)
;
id | name | pts | lastdt | tags | premium
-----+----------------+------+------------------------+------------+---------
123 | \xe5a4aae9838e | 2.00 | 2014-01-01 00:00:00+09 | {JSON,9.4} | f
(1 row)
確かに柔軟にカラムを指定できるようになったが、面倒くささもアップした感じだ。JSON データを入力とした INSERT 文などで、入力カラムの指定と明示的な型変換などが使い所になるだろう。
CREATE TABLE hoge (
id SERIAL PRIMARY KEY,
name varchar(256) NOT NULL,
email varchar(256),
code int
);
INSERT INTO hoge(name, email, code)
SELECT * FROM json_to_record(
'{"id":100, "name":"太郎", "code":"1234"}'
) AS (name varchar(20), email varchar(40), code int) -- キビシめ
);
json_populate_record() 系関数にも別の使いどころがあり、捨てられずに jsonb 系も拡充された。
json_populate_record() 系関数の第一引数に値の入ったレコードを渡したときに JSON の対応するフィールド値でカラムを上書できるのはいろいろと応用が利く。
-- カラム値の上書き
SELECT a.*
FROM accounts,
jsonb_populate_record(accounts, '{"passwd":"*****"}'::jsonb) AS a
;
id | name | ... | passwd | ...
------+------+-----+---------+---
1111 | hoge | ... | ***** | ...
1112 | piyo | ... | ***** | ...
-- アプリケーション定義のデフォルト値
DROP table hoge;
CREATE TABLE hoge (
id int PRIMARY KEY,
name text NOT NULL,
email text DEFAULT 'nobody@example.jp',
lastdt timestamptz DEFAULT CURRENT_TIMESTAMP,
interim boolean DEFAULT TRUE
);
INSERT INTO hoge
SELECT * FROM jsonb_populate_recordset(
ROW (NULL, '名無しさん', NULL, date_trunc('day', CURRENT_TIMESTAMP), FALSE)::hoge, -- set default values
'[
{"id":1,"name":"一郎", "email":"taro@example.jp", "lastdt":"2001/01/01"},
{"id":2, "email":"jiro@example.jp", "interim":true},
{"id":3,"name":"三郎", "tel":"01234567689", "interim":null}
]'::jsonb
)
;
SELECT * FROM hoge
;
id | name | email | lastdt | interim
----+------------+-----------------+------------------------+---------
1 | 一郎 | taro@example.jp | 2001-01-01 00:00:00+09 | f
2 | 名無しさん | jiro@example.jp | 2014-08-20 00:00:00+09 | t
3 | 三郎 | | 2014-08-20 00:00:00+09 |
(3 rows)
jsonb のインデックスサポート
PostgreSQL のインデックス周りのアーキテクチャは独特で新参者にはいまいち分かりにくい。
筆者が素人なりに理解したところを整理すると以下のようになる。誤解があったら指摘してほしい。
- PostgreSQL のインデックスは、拡張可能なモジュールであり、複数のインデックスタイプを使い分けることができる。
- 各インデックスタイプは、特定のアルゴリズムの実装であり、適用可能なデータ型とそれが備えるべき演算子の組を定義する。
- 標準で5種類のインデックスタイプ(B-tree、Hash、GiST、SP-GiST、GIN)が用意されていて、データの性質と検索ストラテジーによって適切なインデックスを選択し、必要あらばそれらをさらに拡張することができる。
- jsonb は比較演算子をサポートしたので、B-treeとHashのインデックスが使えるようになった。
- 汎用転置インデックスである GIN は jsonb を解析するように拡張された。
json を差し置いて jsonb を導入したのはパフォーマンスを優先したためであり、ある意味 JSON データのインデックス化を実現するための仕切り直しであったようだ。
jsonb 型カラムにインデックスを張る
jsonb は比較演算子が定義されているので、B-Tree か Hash によるインデックスを作成することができる。
CREATE INDEX idx01 ON my_table(jb_column); -- デフォルトは btree
CREATE INDEX idx02 ON my_table USING hash(jb_column);
しかしJSON データを丸ごと検索条件にする要件は少ない。
JSON データの順序や範囲指定もアプリケーション的にあまり意味を持たない。
-- jsonb をキーとして使ってみる
CREATE INDEX oauth_idx ON oauth(uid);
SELECT token FROM oauth WHERE uid = '{"provider":"GitHub", "login":"taro123"}';
やはり JSON のフィールドに対してインデックスを張りたい。-> 演算子でフィールドを個別に指定したインデックスは作成できる。しかしそのためにはデータベース管理者が、jsonb カラム内のスキーマまで承知していなければならない。また、たとえ JSON フィールドがインデックス化されても、実際のクエリでは使いづらいことこの上ない。
-- あくまで jsonb を使う
CREATE INDEX idx01 ON coupons(summary->'points');
SELECT * FROM coupons WHERE summary->'points' > to_json( 10 )::jsonb; -- めんどくさい
-- 値をキャストしてから使う
CREATE INDEX idx02 ON coupons((summary->>'points')::int); -- キャストに失敗する可能性あり
SELECT * FROM coupons WHERE (summary->>'points')::int > 10 ; -- めんどくさい
JSON データ内部をインデックス化したいのなら GIN を選択する。
GIN
汎用転置インデックス GIN は jsonb をサポートした。
この"汎用"というのは、GINが基本的に転置インデックスのエンジンのみの実装であり、データ型に固有の処理が外出しにされているということを意味している。
GIN に乗せたいデータ型は、インデックスキーの切り出しや比較評価のインターフェースを自前で実装し、拡張モジュールとしてインストールする。
そういう流儀からすると今回 GIN が新参の jsonb を組み込みとしてサポートしたのは破格の待遇にみえる。(中の人が同じらしい)
JSON データの中身をどう"捌いて"インデックスキーとするか、について jsonb_opt と jsonb_path_opt の2つのオプションが用意されている。
CREATE INDEX idx01 ON my_table USING gin(jb_column, jsonb_opt); -- デフォルト
CREATE INDEX idx02 ON my_table USING gin(jb_column, jsonb_path_opt);
技術的な説明はドキュメントに詳しいが、英語で読んでもよくわからないので日本語に翻訳されるのを待ちたいところだ。
追記:すでに日本語版公式ドキュメントが出ている。が、日本語で読んでもよく分からない。
あくまでイメージ的に表現すれば、json_opt は JSON を"ぶつ切り"し、json_path_opt は"裂いて"インデックス化する。
たとえば以下のような JSON があったとして
{"a":"x", "b":{"b1":"y", "b2":["z", 1, true]}}
jsonb_opt ではフィールド名と値をばらしてインデックスキーとして切り出す。
| key (想像) |
|---|
| a |
| b |
| b1 |
| b2 |
| "x" |
| "y" |
| "z" |
| 1 |
| true |
jsonb_path_opt では、各値について、階層パスを含めた表現(のハッシュ)をインデックスキーとして作成する。
| key (想像) |
|---|
| {"a":"x"} |
| {"b":{"b1":"y"}} |
| {"b":{"b2":["z"]}} |
| {"b":{"b2":[1]}} |
| {"b":{"b2":[true]}} |
上記の表は説明のための想像であり、実際の表現は異なるだろう。
jsonb_opt では、JSONデータの内容によってはインデックスとして十分なばらつきが得られない可能性がある。特にフィールド名についてほとんどのデータで被るはずで役に立たない。また jsonb_opt では、<@ 演算子がサポートされない。
jsonb_path_opt はフィールド名と値をキーに含むので十分なばらつきが得られ高速な検索が期待できるが、@> 演算子__しか__サポートしない。
どちらがいいかは JSON の内容と要件による。
使ってみるとわかるが jsonb で使える関係演算子ではクエリのパターンが意外と限られており、細かい指定に -> 演算子を駆使したところでインデックススキャンから外れる。アプリケーションの用としては機能的に不十分だ。
一方 PostgreSQL 開発陣としては柔軟な JSON のクエリー表現を実現するために、jsquery という新たなクエリー言語を導入する予定があるらしい。これはある意味 PostgreSQL なりの NoSQL への布石になるのかもしれない。
jsquery についてはすでに動く実装があるが、まだ PostgreSQL 本体に取り込まれておらず、公式のドキュメントもないので本稿では取り上げない。
ざっと見たところ、
- jsquery は JSON ではない
- JSON のフィールドパスをパターンで指定できる。しかしJSONPathではない
- 豊富な演算子。しかし正規表現なし
- GIN インデックスをそれ用に拡張する
- クエリはオプティマイザによって最適化される
気になる人は下記参考文献を参照してほしい。
jsquery で実用的で NoSQL ライクな検索ができるようになるわけだが、それはユーザにとってまた新たな DSL への対応が必要になり、しかもそれが正式導入されるとしても当分先で今後どうなるかわからない。しばらく様子見をしたほうがいいだろう。
全文検索したい
JSON でドキュメント指向を標榜するなら、全文検索あるいはフリーワード検索はでは避けて通れない要件だ。
もともと PostgreSQL では、全文検索専用のインデックスの仕組みは提供されておらず、汎用の GIN や GiST を活用する。GIN に供する解析済みのテキストデータを作成するのはユーザの責任であり、その解析方法は言語や要件によって適切なアルゴリズムを選択する。
英語のような分かち書きされた言語なら、テキストを組み込みの tsvector 型に変換するだけで足りる。
日本語はだいぶ事情が違うので、有志によって公開されている拡張モジュールをインストール設定する必要がある。いくつかの選択肢があるが、通常は bi-gram ベースのインデックス作成を支援する pg_bigm というモジュールを使用するのが定石らしい。
JSON のインデックス化ための拡張はない。検索対象のフィールドが決まっているのなら ->> 演算子で指定すればよい。
逆に文書データなど内部のテキストをすべて検索対象にしたいのなら、JSON テキストを丸ごとインデックス化するのが手っ取り早いだろう。
CREATE INDEX idx01 ON articles USING gin(to_tsvector('english', jb_body->>'abstract'));
CREATE INDEX idx02 ON articles USING gin(to_tsvector('english', jb_body::text));
CREATE INDEX idx03 ON articles USING gin(jb_body::text, gin_bigm_ops); -- pg_bigm module
フィールド名の混入を気にしないならこれで問題ない。
-- to_tsvector() では JSON の書式記号は無視される
ELECT to_tsvector('english', '{"a": "json to text", "the": [1, "a", true], "aaa": {"bbb": "bbb ccc"}}');
to_tsvector
---------------------------------------------------------------
'1':6 'aaa':9 'bbb':10,11 'ccc':12 'json':2 'text':4 'true':8
(1 row)
-- bi-gram
SELECT show_bigm('{"a": "寿限無寿限無五劫のry", "b": ["すももももももももち"]}');
show_bigm
--------------------------------------------------------------------------------
{すも,"ち ",のr,もち,もも,五劫,劫の,寿限,無五,無寿,限無," \""," ["," {","\"す",
"\"寿","\",","\":","\"]","\"a","\"b",", ",": ","[\"","]}","a\"","b\"",ry,"y\"","
{\"","} "}
(1 row)
ノイズの存在が許容できない潔癖主義者の場合、前処理で JSON 内部から string だけをきれいに抽出しておかなければならない。しかしJSON 内の値だけを再帰的に収集するような簡易な手段は 9.4 でも提供されない。
もちろんプログラマなら再帰関数でもちょろっと書いてオッケーな気分だろうが、INSERT 時にシステムに余計な負荷をかけることは確実なので、それが評価で着ないうちは慎重にならざるを得ない。
とりあえず正規表現でフィールド名を取り除くだけでもだいぶお茶を濁せるはずだ。
-- 正規表現でフィールド名だけ削除する
CREATE FUNCTION jsonb_crude_text(jb jsonb) RETURNS text
AS $$
SELECT regexp_replace(jb::text, '"[^"]+?[^\\]": ', '', 'g')
$$ LANGUAGE SQL;
-- string の再帰抽出
CREATE FUNCTION jsonb_strvals(jb jsonb) RETURNS text
AS $$
SELECT string_agg(
CASE jsonb_typeof(value)
WHEN 'string' THEN value::text
WHEN 'object' THEN jsonb_strvals(value)
WHEN 'array' THEN jsonb_strvals(value)
END, '\n'
)
FROM (
SELECT value FROM jsonb_each(jb) WHERE jsonb_typeof(jb) = 'object'
UNION ALL
SELECT value FROM jsonb_array_elements(jb) WHERE jsonb_typeof(jb) = 'array'
) AS strvals
$$ LANGUAGE SQL;
応用
★ 追記予定 ★
別稿 → PostgreSQL JSON の応用メモ
まとめ
- JSON ストアとして json 型とは別に jsonb 型が追加された
- jsonb はバイナリの JSON ストアであり、高速アクセス、インデックス化が可能
- jsonb は immutable でありフィールドの操作、変更はできない
- GIN が jsonb のインデックス化をサポート
- json はいらない子
- jsquery をおたのしみに
参考
PostgreSQL: Documentation: 9.4: JSON Functions and Operators
http://www.postgresql.org/docs/9.4/static/functions-json.html
Jsonb has committed ! | или внеочередные заметки
http://obartunov.livejournal.com/177247.html
jsonb Deep Dive by Peter Geoghegan
https://speakerdeck.com/peterg/jsonb-deep-dive
PGCon2014: CREATE INDEX ... USING VODKA
Alexander Korotkov, Oleg Bartunov, Teodor Sigaev
http://www.pgcon.org/2014/schedule/events/696.en.html
http://www.pgcon.org/2014/schedule/attachments/318_pgcon-2014-vodka.pdf
PGCon2014: Json - what's new in 9.4, and what's left to do.
Andrew Dunstan
http://www.pgcon.org/2014/schedule/events/715.en.html
http://www.pgcon.org/2014/schedule/attachments/328_9.4json.pdf
SRA PostgreSQL 9.4 最新情報セミナー:
Schema-less PostgreSQL
Oleg Bartunov
http://www.sraoss.co.jp/event_seminar/2014/20140911_pg94_schemaless.pdf
PostgreSQLガイダンス(1):PostgreSQL 9.4 GINインデックスの評価、JSONBデータ型の使い方 (1/2) - @IT
高塚遥,SRA OSS, Inc.
http://www.atmarkit.co.jp/ait/articles/1409/04/news005.html