概要
Darknet(AlexeyAB版)を用いて学習させたYolov3のモデルをC#で動かしたいと思い、OnnxRuntimeを使ったのでそのメモ。
なお、筆者は機械学習などは素人に毛が生えた程度なので間違っていたら優しく教えてくれると嬉しいです。
手順
1. 学習済みの重みの変換
直接変換するのがイマイチ上手くいかなかったので、こちらの記事を参考に.h5形式を経由して変換した。
詳細な手順は省きますが、以下のライブラリを使用しました。
.weights -> .h5の変換
qqwweee/keras-yolo3
https://github.com/qqwweee/keras-yolo3
.h5 -> .onnxの変換は先ほどの記事のコードを使用しました。
2. OnnxRuntimeを用いて重みファイルを読み込む
YoloV3をOnnxRuntimeを用いて実装している公式サンプルがあったのだが、出力される形式が合わない....
https://github.com/microsoft/onnxruntime-inference-examples/tree/main/c_sharp/OpenVINO_EP/yolov3_object_detection
公式サンプルの出力は、矩形データとスコアとインデックスが出力されているっぽい。
しかし、今回変換したモデルの出力は、以下のような[1x13x13x3x(class+5)], [1x26x26x3x(class+5)], [1x52x52x3x(class+5)]の3つのテンソルである。
(以下の図では、classが2つのモデルだったため、各テンソルの最後の要素数は3x(2+5)=21となっている)
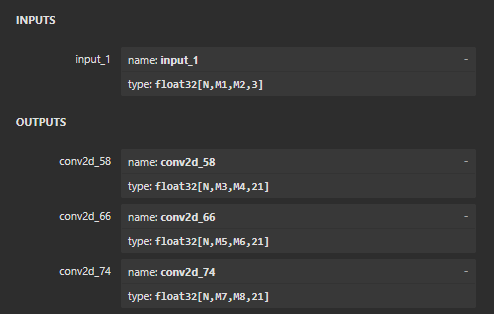
これらの出力の意味は、こちらの記事が分かりやすい。
ということで、この3つのテンソル用に上記のコードを書き換える。
PredToBox関数は推論結果の座標をx,yの最小最大の座標に変換する関数である。(この際の座標は416x416における座標)
static Box PredToBox(float tx, float ty, float tw, float th, float col, float row, int box, int boxSize)
{
var stride = 416f / boxSize;
float pw = (float)Math.Exp(tw) * Anchors[(int)(stride / 16) * 3 + box, 0];
float ph = (float)Math.Exp(th) * Anchors[(int)(stride / 16) * 3 + box, 1];
float px = (col + Sigmoid(tx) * Xyscale[box] - (Xyscale[box] - 1.0f)/2) * stride;
float py = (row + Sigmoid(ty) * Xyscale[box] - (Xyscale[box] - 1.0f)/2) * stride;
float min_x = px - pw / 2;
float min_y = py - ph / 2;
float max_x = px + pw / 2;
float max_y = py + ph / 2;
return new Box(min_x, min_y, max_x, max_y);
}
GetPredictList関数は推論結果の入ったベクトルから、一定の信頼度を超えた検出対象の座標・スコア・クラスを取得しリスト化して返す関数である。
// 3D tensor Dimension
// N x N x [3 x (M + 1 + 2)]
// 3 : Boxes : (each grid predict 3 boxes)
// 4 : Box cordinate
// 1 : objectness score
// M : classes
static List<Prediction> GetPredictList(float[] data, int boxSize)
{
var predictionList = new List<Prediction>();
for (int b = 0; b < 3; ++b){
for (int y = 0; y < boxSize; ++y) {
for (int x = 0; x < boxSize; ++x)
{
var offset = (y * boxSize * (LabelMap.Labels.Length + 5) * 3) + (x * (LabelMap.Labels.Length + 5) * 3) + (b * (LabelMap.Labels.Length + 5));
// one data
var pbox = data.Skip(offset).Take((LabelMap.Labels.Length + 5)).ToArray();
var conf = Sigmoid(pbox[4]);
if (conf > 0.5)
{
var classConf = pbox.Skip(5).Select(x => Sigmoid(x)).ToList();
var bestScore = classConf.Max();
var classIdx = classConf.IndexOf(bestScore);
if (bestScore > 0.5)
{
var res = new Prediction();
res.Box = PredToBox(pbox[0], pbox[1], pbox[2], pbox[3], x, y, b, boxSize);
res.Class = Labels[classIdx];
res.Score = conf * bestScore;
predictionList.Add(res);
}
}
}
}
}
return predictionList;
}
最後に検出結果を画像に描き出す部分。
座標のスケールを元の画像に合わせて描き出す。
(本当はこの前に、同一の対象を示していると思われる複数の検出結果のBoxを統合する必要があります。今回は実装していない。。。)
foreach (var p in predictions)
{
// predict point => original point
var dw = (416f - scale * imageOrg.Width) / 2;
var dh = (416f - scale * imageOrg.Height) / 2;
var min_x = (p.Box.Xmin - dw) / scale;
var max_x = (p.Box.Xmax - dw) / scale;
var min_y = (p.Box.Ymin - dh) / scale;
var max_y = (p.Box.Ymax - dh) / scale;
imageOrg.Mutate(x =>
{
x.DrawLines(Color.Red, 2f, new PointF[] {
new PointF(min_x, min_y),
new PointF(max_x, min_y),
new PointF(max_x, min_y),
new PointF(max_x, max_y),
new PointF(max_x, max_y),
new PointF(min_x, max_y),
new PointF(min_x, max_y),
new PointF(min_x, min_y),
});
x.DrawText($"{p.Class}, {p.Score:0.00}", font, Color.White, new PointF(min_x, min_y));
});
}
imageOrg.Save(outputImage, format);
これらをまとめたのが以下のコードになります。
https://gist.github.com/kumasan1011/6dcba7d210c81baf101f24ae5f9b28cb
まとめ
OnnxRuntimeを用いるとC#でも機械学習のモデルが使えて楽しい。
ただ、ML.NETもだけど参照できる文献が少ないのがネック....