今回は、MNISTの手書き画像を用いて3と7を判別するという、超簡単な判別器を作るというベーシックな内容で書いてみました。この記事はfast.aiのライブラリを使ってみようかという人の入門になるだろうと思います。
内容を具体的に言うと、fastbookのサンプルコードにある04_mnist_basics.ipynbをベースに自分の実験を入れながら理解したところを解説します。結果から言うと、判別器の正解率は3の検証画像については91.7%、7の検証画像については98.5%でした。
この記事で参照したサンプルコードについての解説は、公式ページのlesson3後半からlesson4前半で行われていますので、興味があれば見てください。英語ですが詳細な解説はサンプルコード自体にもあります。
訓練/検証データのダウンロード
まず、Googleドライブに必要なライブラリをインストールし、必要なモジュールをインポートします。基本はサンプルコードと同じですが、Googleドライブのマウントが面倒なので、fastbook.setup_book()をコールしないよう不要な部分をコメントアウトしました。
# !pip install -Uqq fastbook
# import fastbook
# fastbook.setup_book()
! [ -e /content ] && pip install -Uqq fastbook # upgrade fastai on Google Colab
from fastai.vision.all import *
from fastbook import *
matplotlib.rc('image', cmap='Greys')
次は、untar_data関数でMNISTサンプルデータをダウンロードして解凍します。データが格納されたディレクトリを知るために戻り値を変数pathに代入しておきます。URLs.MNIST_SAMPLEの定義については、External dataを参照してください。
path = untar_data(URLs.MNIST_SAMPLE)
Path.BASE_PATH = path
変数pathの型はpathlib.PosixPathでいろいろ便利に使えますが、上記のようにPath.BASE_PATH = pathとすると、画像を展開したディレクトリ以下のディレクトリは相対パスみたいに参照できるようになります。実装が気になって調べたら、次のようになっていましたので、カレントディレクトリそのものが移動してしいるわけではありません。(https://github.com/fastai/fastcore/blob/28721554e0eab1f2974237c502912f8ba42a44a0/fastcore/xtras.py)
@patch
def __repr__(self:Path):
b = getattr(Path, 'BASE_PATH', None)
if b:
try: self = self.relative_to(b)
except: pass
return f"Path({self.as_posix()!r})"
この実装を見る限り、Path.BASE_PATHというクラス変数が存在する(設定する)とそのディレクトリ以下が相対表示されるようです。たとえば、pathを表示するとPath('.')とカレントディレクトリのごとく表示されます。(未設定で参照するとエラーになります。)
ここまでを実行した結果が次の図です。
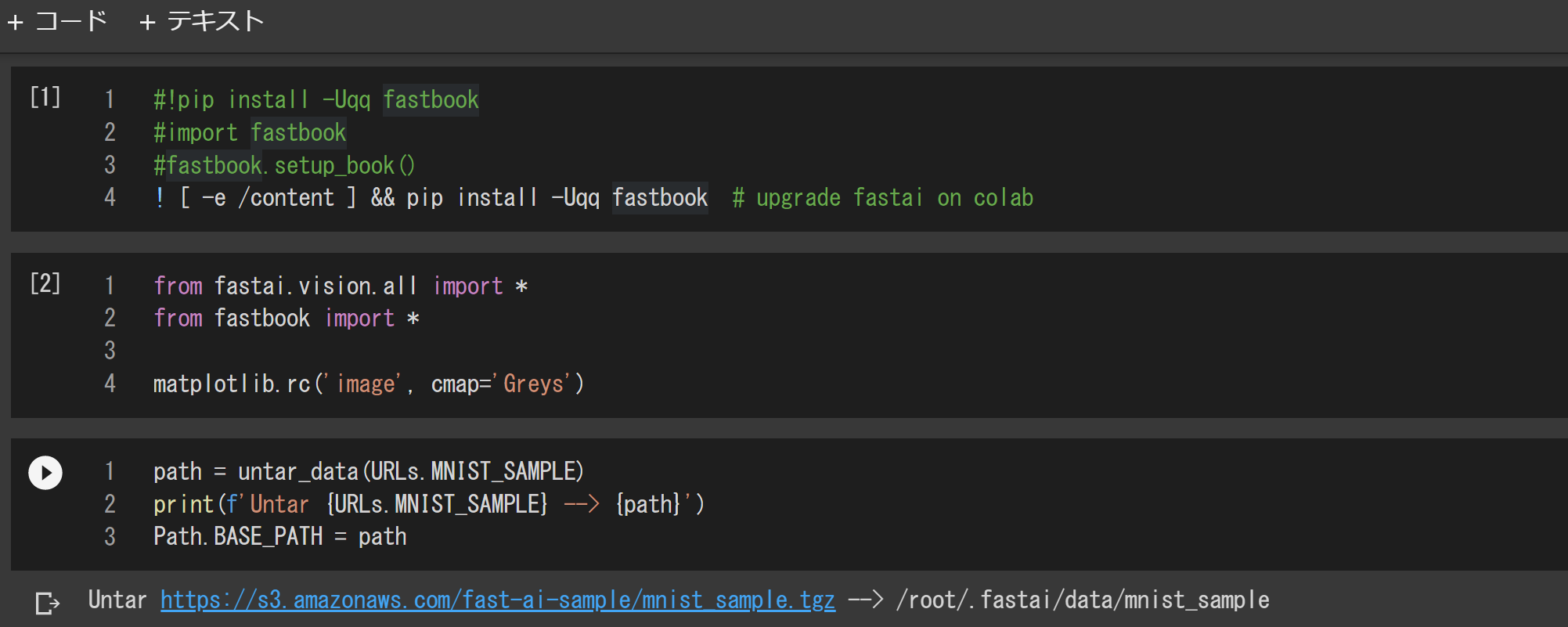
見てのとおり、ダウンロード元を指す定数URLs.MNIST_SAMPLEはhttps://s3.amazonaws.com/fast-ai-sample/mnist_sample.tgzで、画像は圧縮ファイルになっています。そして、untar_data関数が画像を展開したディレクトリを指すpathは/root/.fastai/data/mnist_sampleとなっていました。
訓練/検証データの読み込み
次に、画像を展開したディレクトリの直下を調べて訓練/検証データの場所を確認し、画像ファイルのパスリストを作成します。path.ls()を表示するとtrainとvalidという2つのサブディレクトリが見つかりました。さらに、(path/'train').ls()を表示すると3と7という2つのサブディレクトリがあります。validも同じです。
次のコードは、訓練データのパスリストを取得するもので、threesとsevensはそれぞれ3と7の手書き文字画像のパスリストです。
threes = (path/'train'/'3').ls().sorted()
sevens = (path/'train'/'7').ls().sorted()
訓練画像の一つを適当に選び、その画像をImage.open関数で読み込んで表示します。データ型はこの時点でPIL.PngImagePlugin.PngImageFileになっており、画像のサイズは(28,28)です。
im3_path = threes[1]
im3 = Image.open(im3_path)
im3
ここまでを実行すると次のようになります。ちゃんと3という数字が表示されるのが確認できますね。いちいちmatplotlibなどを使ってコードを書かなくても適当に表示しくれます。
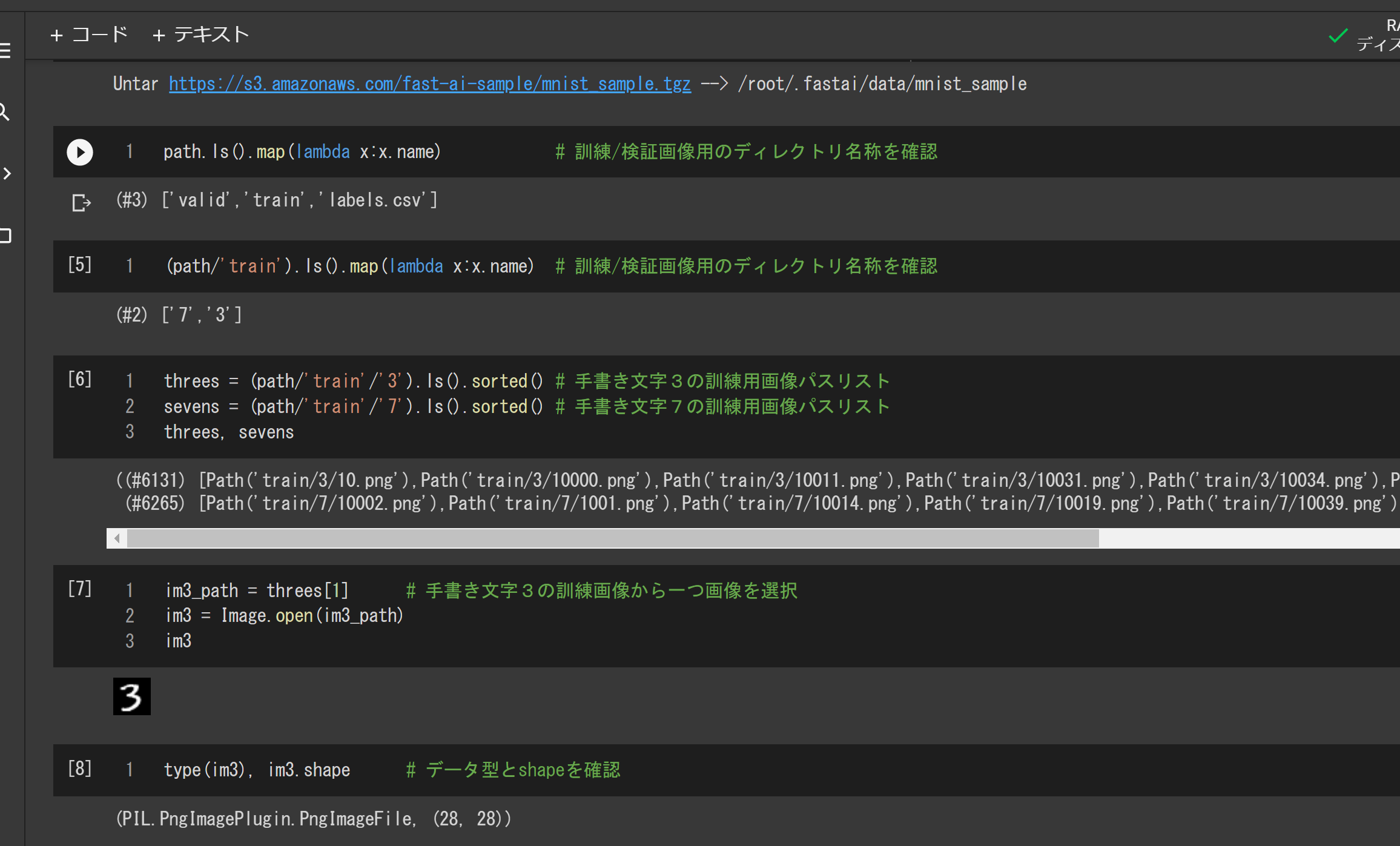
3と7の訓練画像はそれぞれ6131枚、6265枚であることが分かりますね。
テンソルへの変換
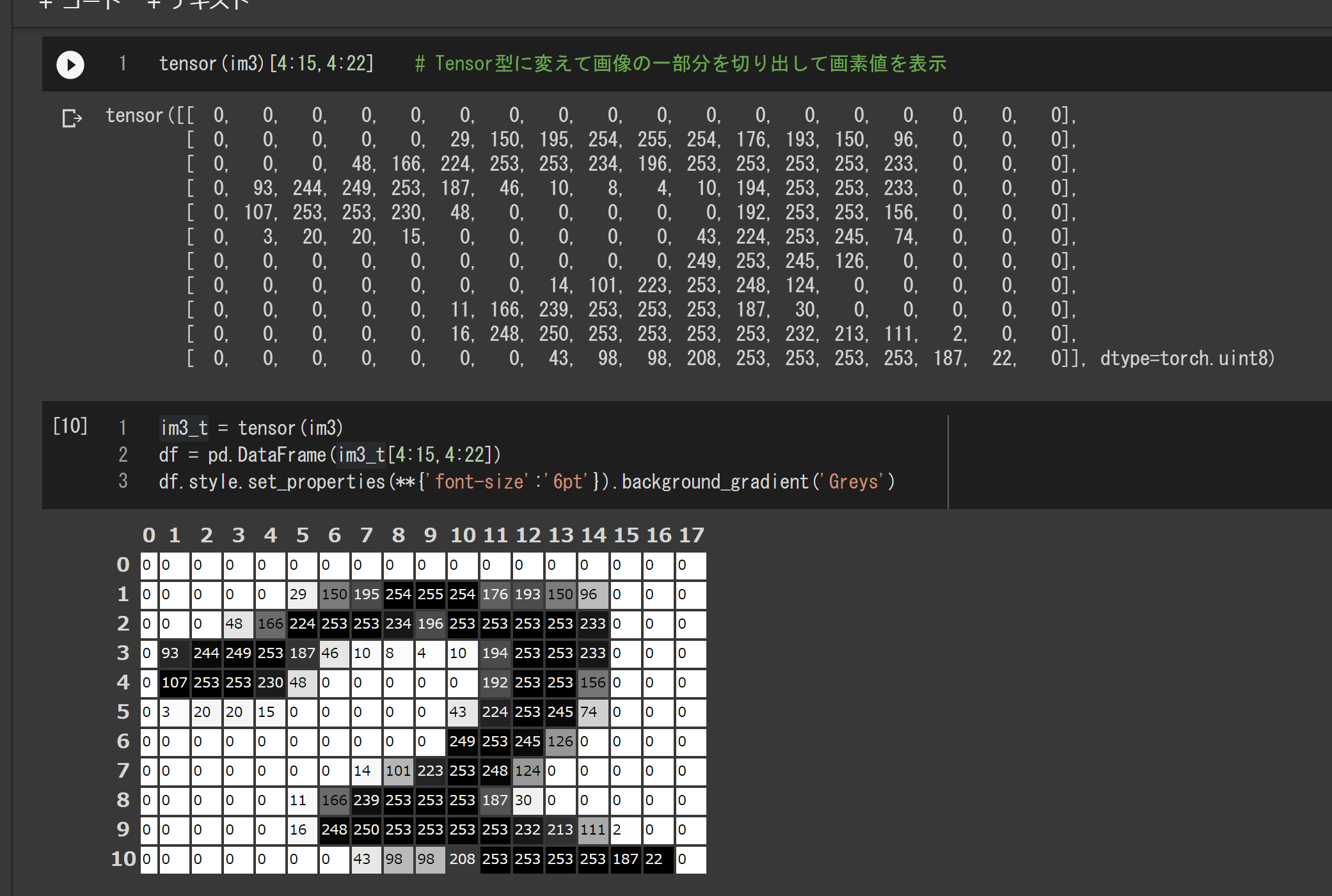
画像をテンソル(PyTorchのTensor)に変えると、画像の演算や切り出しが、Numpyと同じ形式で行えるようになります。たとえば、画像の一部を切り出すには次のようにします。ここでは、pythonのPandasライブラリを使って画素値を視覚的に確認しています。
im3_t = tensor(im3)
df = pd.DataFrame(im3_t[4:15,4:22])
df.style.set_properties(**{'font-size':'6pt'}).background_gradient('Greys')
ということで、先ほどのパスリストからテンソル型の画像のリストを作成します。three_tensorsとseven_tensorsは、それぞれ3と7の手書き数字画像のリストです。
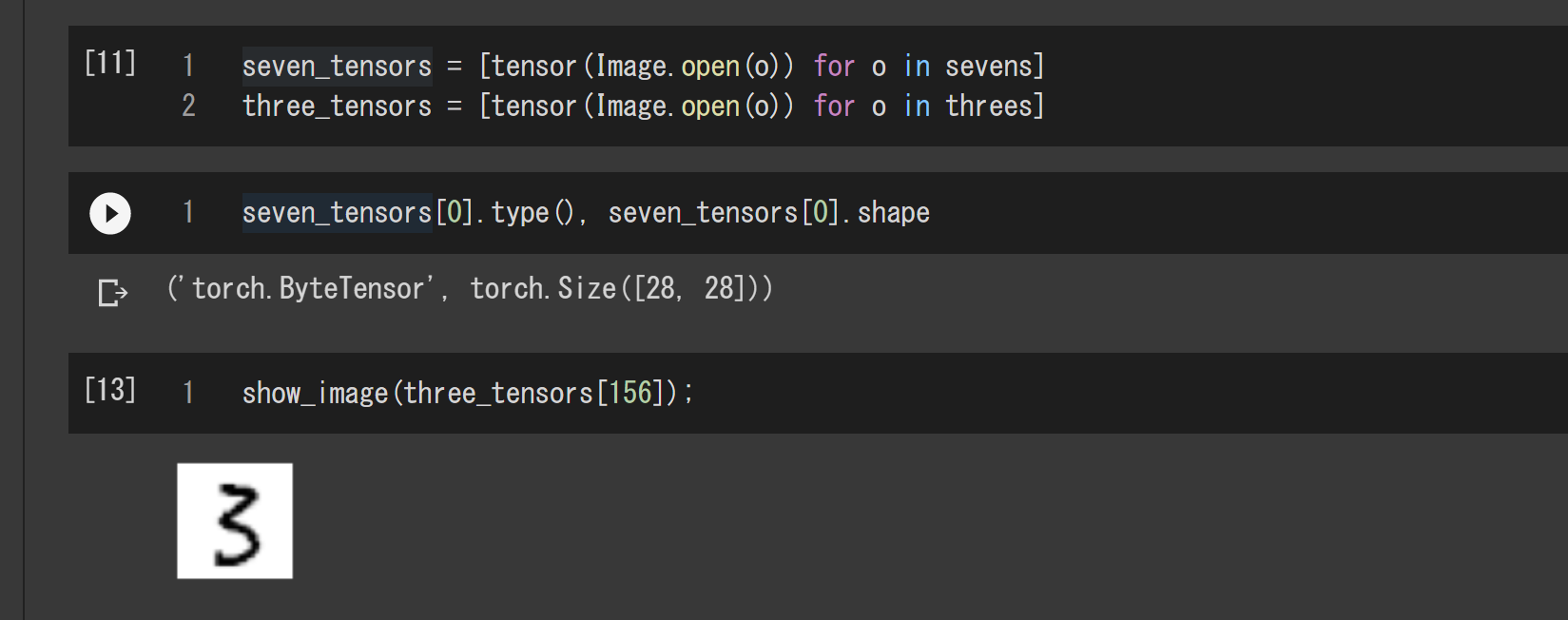
seven_tensors = [tensor(Image.open(o)) for o in sevens]
three_tensors = [tensor(Image.open(o)) for o in threes]
このコードでは、先のパスリストの各要素をテンソル型の画像に変換したリストを作成しています。下の実行結果から分かるとおり、新しいリストの要素はtorch.ByteTensor型で、画像として表示するには先ほどと同じではダメなのでshow_image関数を使います。
画像と画像の差異を測る
与えられた画像が3なのか7なのかを区別するには、どちらに近いか測ればよい。そこで、一つのアイデアとして、3と7の手書き文字の訓練画像それぞれの平均画像を求めて、3と7それぞれのお手本とします。そうすると、与えられた画像がどちらのお手本に近いかという問題に置き換わったことになります。
平均画像の計算
準備として、3と7の訓練画像のリストを各々(サンプル数,高さ,幅)の3次元テンソルにします。これはリストの全要素を縦に積み重ねて一つのテンソルにするイメージです。torch.stack関数はそれをしています。このとき序に、画素値も0~255から0.0~1.0に規格化しておきます。
stacked_sevens = torch.stack(seven_tensors).float()/255
stacked_threes = torch.stack(three_tensors).float()/255
次は平均画像の計算です。これは各々1ステップで計算できます。平均画像は第0次元で平均した(高さ,幅)2次元のテンソルであり一つの画像です。
mean3 = stacked_threes.mean(0)
mean7 = stacked_sevens.mean(0)
下の図はここまでを実行した結果です。画像はtorch.FloatTensor型の3次元テンソルになっており、先と同様に、この平均画像を画像として表示するのにshow_image関数を使っています。
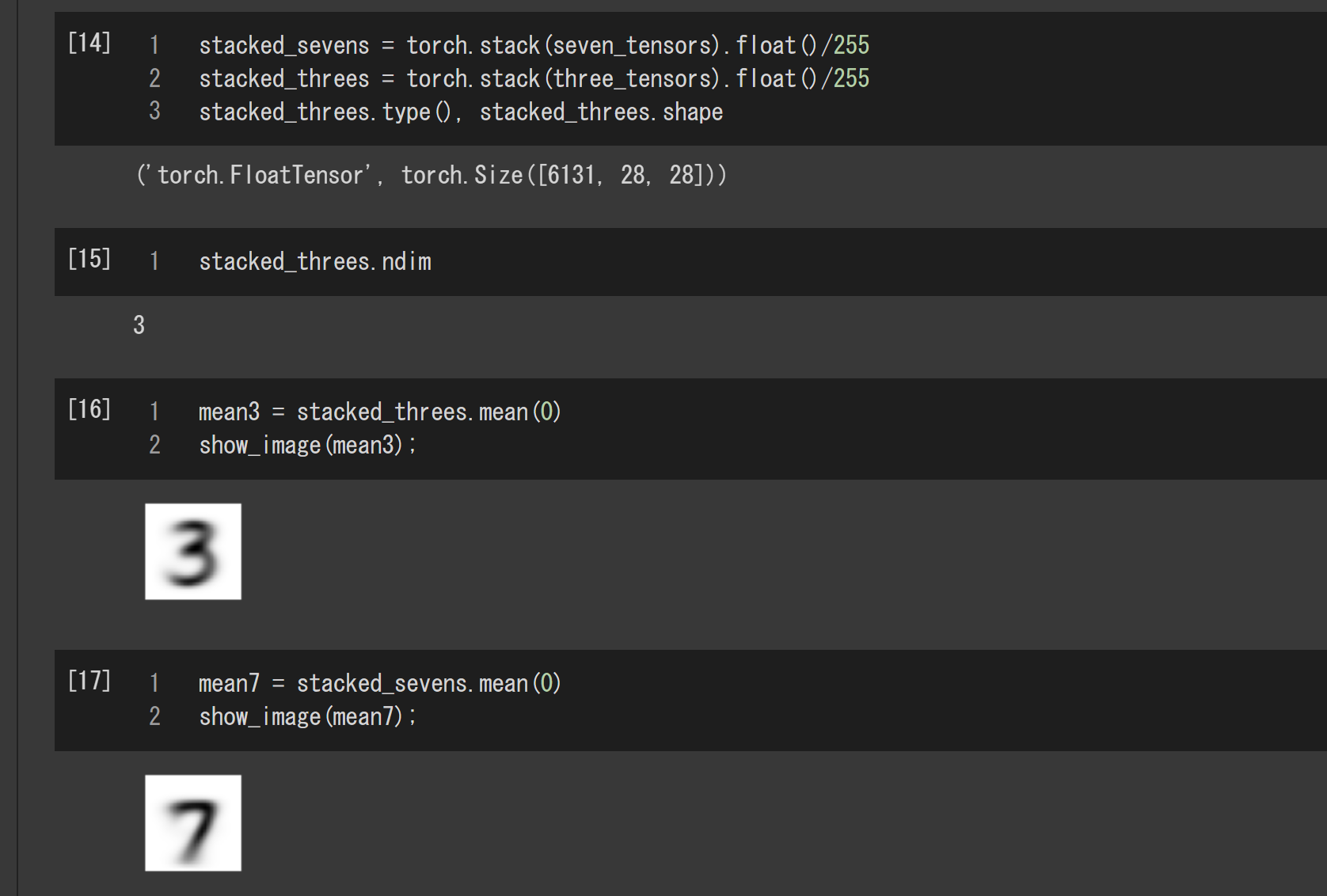
ちょっとぼやけてますが、これが手書き文字の3と7の訓練データを代表する画像ということになります。
画像の差異
次のコードは画像の差異を計算する関数です。l1_distance_fromは画素の差の絶対値の平均を計算します。一方、rmse_distance_fromは画素の差の2乗の平方根を計算します。ちなみに、@patchは、第一引数の型を持つオブジェクトのメソッドのように振る舞わせるお呪いです。(取っ払って普通に使っても問題ありません。)
@patch
def l1_distance_from(self:Tensor,origin:Tensor): return (self-origin).abs().mean((-1,-2))
@patch
def rmse_distance_from(self:Tensor,origin:Tensor): return ((self-origin)**2).mean((-1,-2)).sqrt()
次の図は、手書き文字3の訓練画像の一つをピックアップして、3の平均画像mean3および7の平均画像mean7との差異を表示した結果です。
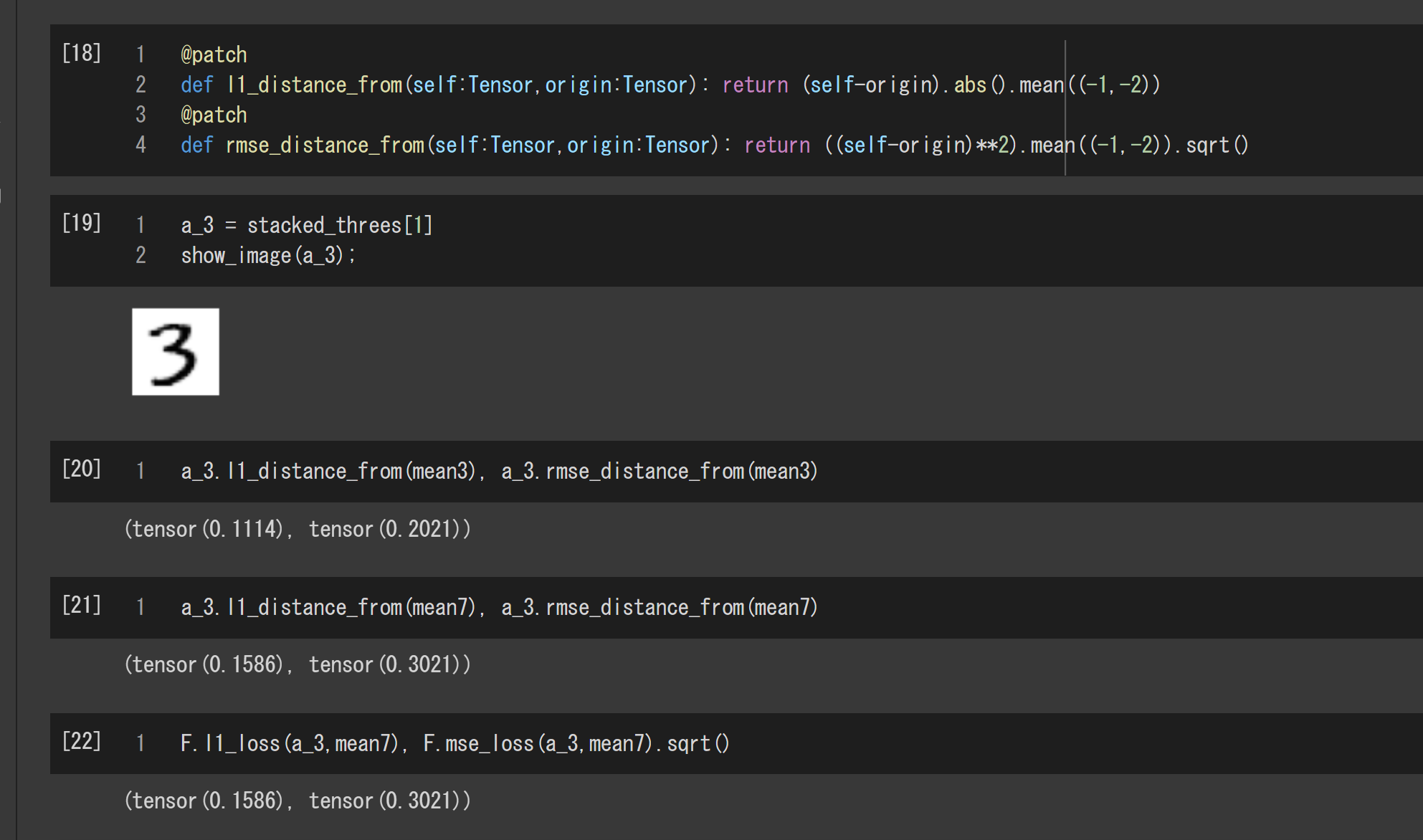
どちらの関数で比較しても、3の平均画像に近いと分かりますね。ちなみに、最後のセルの結果を見れば分かるとおり、l1_distance_fromとrmse_distance_fromの計算は、fastaiが提供するPyTorchのラッパー関数F.l1_lossとF.mse_lossを使っても実装できます。
上記の2つの関数は最後の2つの次元が(高さ,幅)であることを前提としていることに注意してください。また、テンソルのブロードキャスティングに依存しているのでその条件に従っている必要があります。テンソルのブロードキャスティングの条件に興味がある方は「NumPyのブロードキャスト(形状の自動変換)」または「BROADCASTING SEMANTICS」を参照ください。
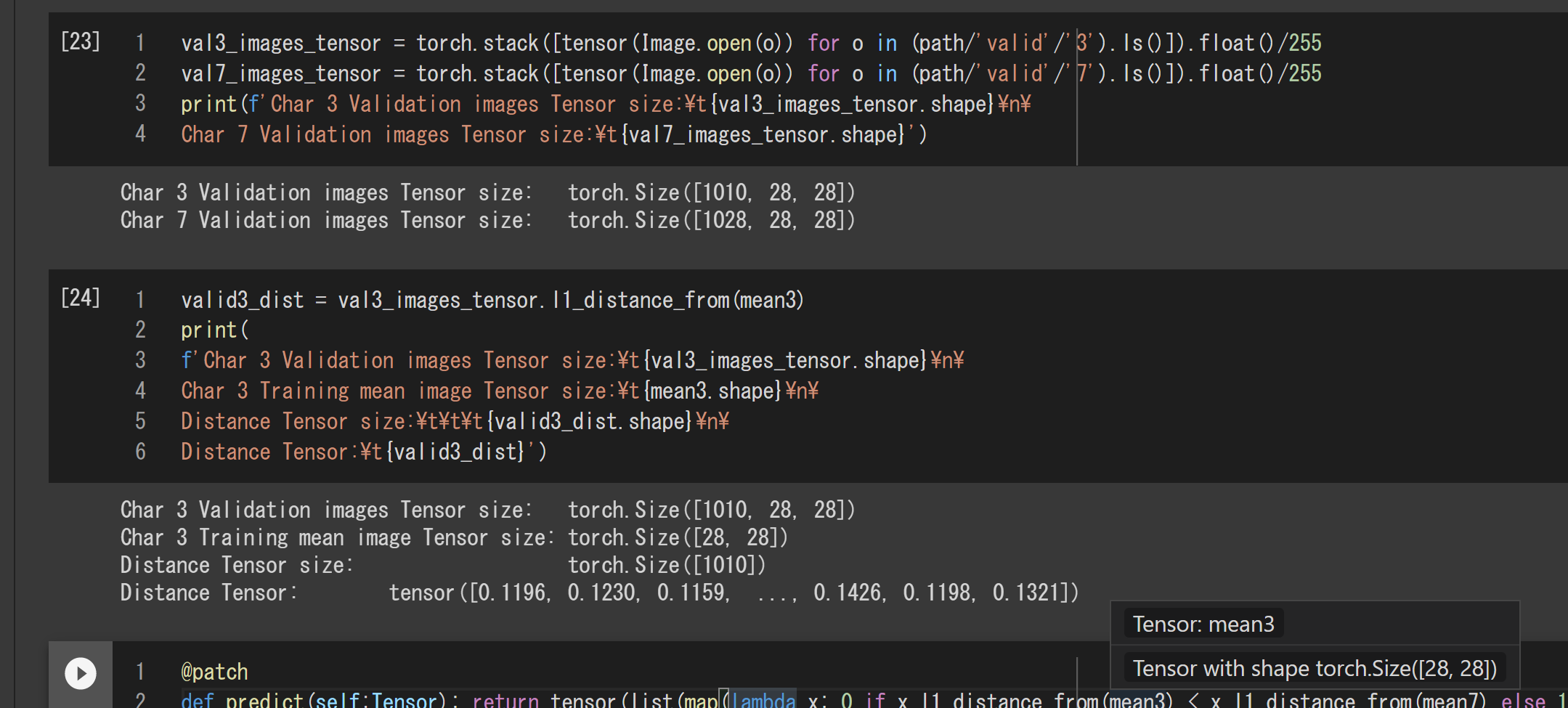
判別器の性能を確認するには訓練用画像に含まれない検証用画像を使いますので、検証用画像の方も3次元テンソルに変換しておきます。ここでは途中を飛ばして一気に変換します。
val3_images_tensor = torch.stack([tensor(Image.open(o)) for o in (path/'valid'/'3').ls()]).float()/255
val7_images_tensor = torch.stack([tensor(Image.open(o)) for o in (path/'valid'/'7').ls()]).float()/255
テンソルのブロードキャスティングが実際どう働くかは、上記で3次元テンソル化した検証用画像の類似度計算の結果をみれば分かります。
valid3_dist = val3_images_tensor.l1_distance_from(mean3)
結果は次のとおりです。サイズ(1010, 28, 28)の3次元テンソルval3_images_tensorと
サイズ(28, 28)の2次元テンソルmean3の類似度の計算結果は、サイズ(1010)の1次元テンソルになっていて、ちゃんと1010枚の画像それぞれの類似度が計算されています。
超簡単3-7判別器の作成と評価
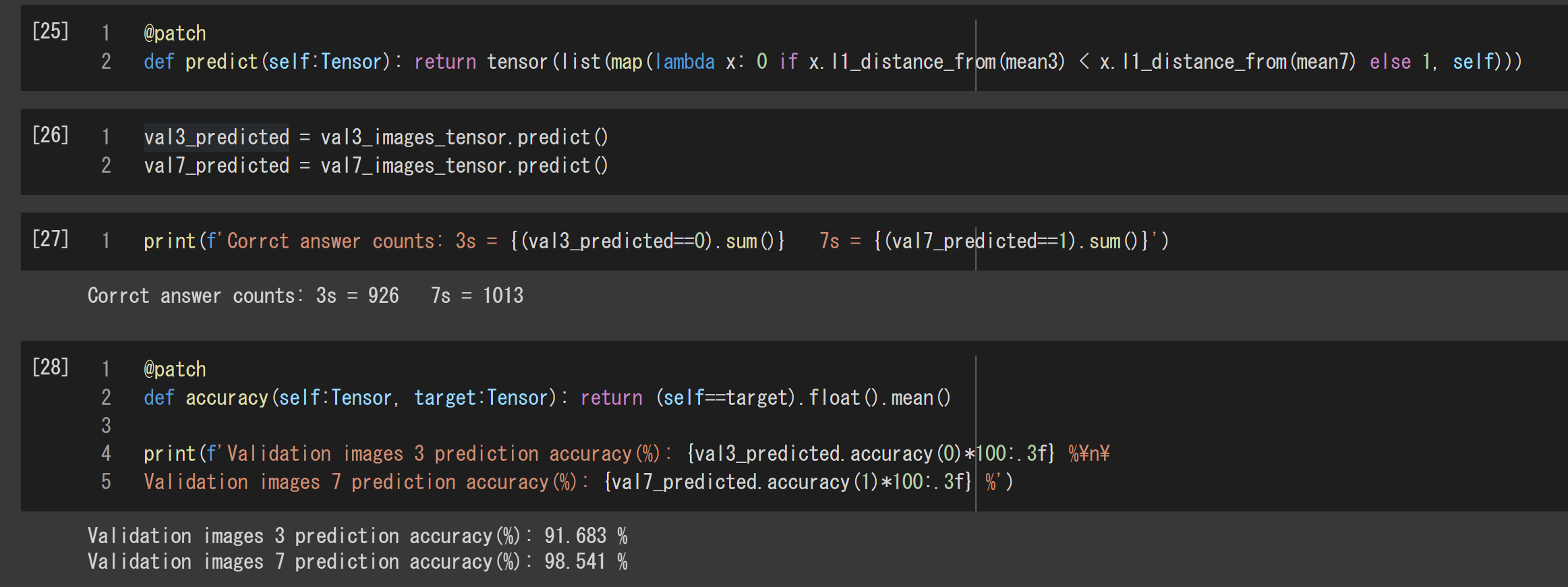
与えられた手書き数字の画像が3か7かの判別器は、デコレーション@patchを含めてたった2行です。やっていることは簡単で、mean3との差異がmean7との差異より小さければ0、そうでなければ1を返すだけです。
@patch
def predict(self:Tensor): return tensor(list(map(lambda x: 0 if x.l1_distance_from(mean3) < x.l1_distance_from(mean7) else 1, self)))
val3_predicted = val3_images_tensor.predict()
val7_predicted = val7_images_tensor.predict()
print(f'Corrct answer counts: 3s = {(val3_predicted==0).sum()} 7s = {(val7_predicted==1).sum()}')
次は正解率を計算する関数です。
@patch
def accuracy(self:Tensor, target:Tensor): return (self==target).float().mean()
print(f'Validation images 3 prediction accuracy(%): {val3_predicted.accuracy(0)*100:.3f} %\n\
Validation images 7 prediction accuracy(%): {val7_predicted.accuracy(1)*100:.3f} %')
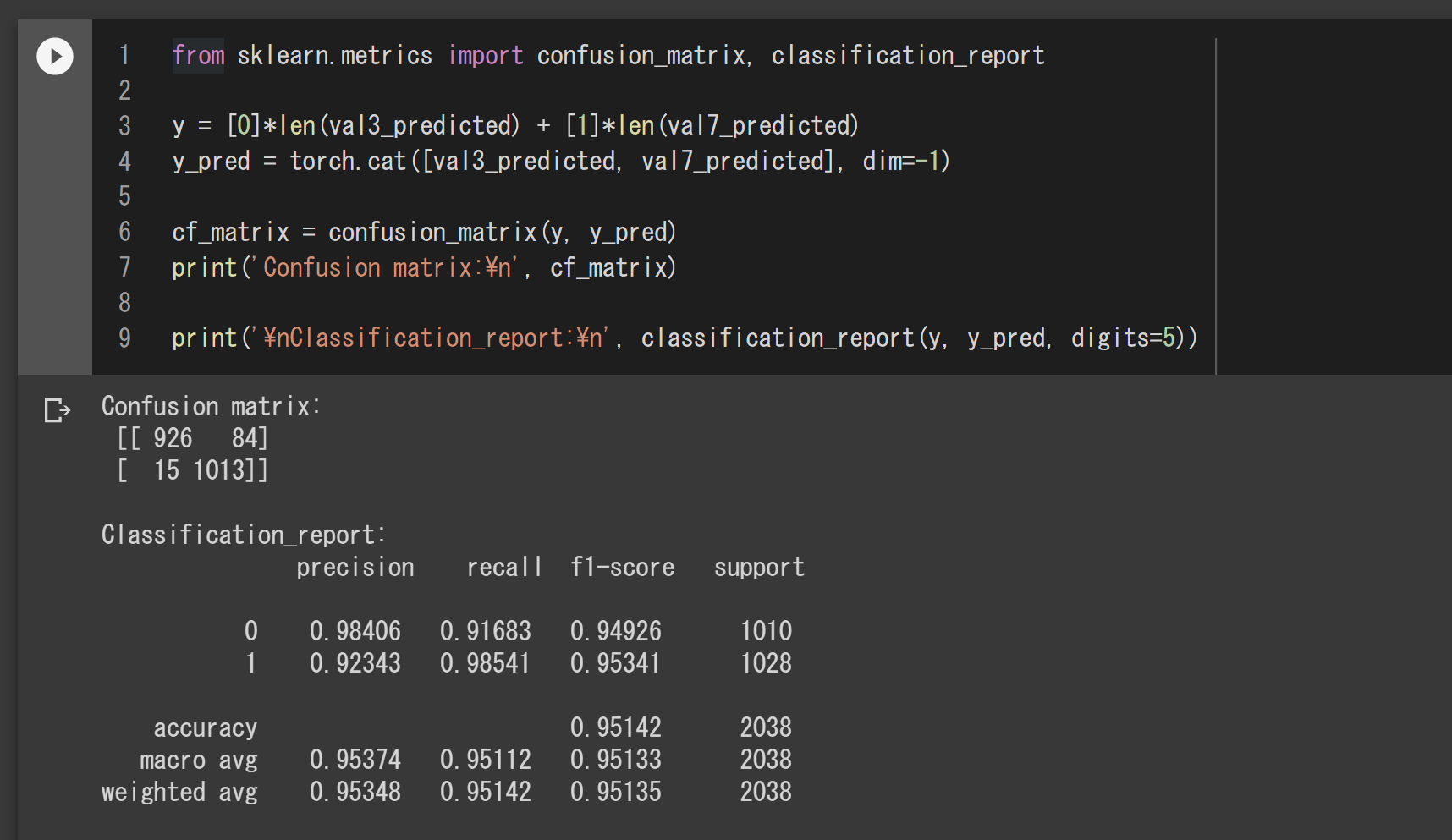
混同行列とクラシフィケーション・レポートの表示
下記のコードで、変数yとy_predは、3と7両方の検証画像を合わせた正解ラベルと予測したラベルです。
from sklearn.metrics import confusion_matrix, classification_report
y = [0]*len(val3_predicted) + [1]*len(val7_predicted)
y_pred = torch.cat([val3_predicted, val7_predicted], dim=-1)
cf_matrix = confusion_matrix(y, y_pred)
print('Confusion matrix:\n', cf_matrix)
print('\nClassification_report:\n', classification_report(y, y_pred, digits=5))
次の図はこのコードを実行した結果です。混同行列の表示から、3の検証画像では、1010件中正解が926件で誤判別は84件、7の検証画像では、1028件中正解が1013件で誤判別が15件だと分りますね。クラシフィケーション・レポートのrecallは、accuracy関数と同じ値になっています。
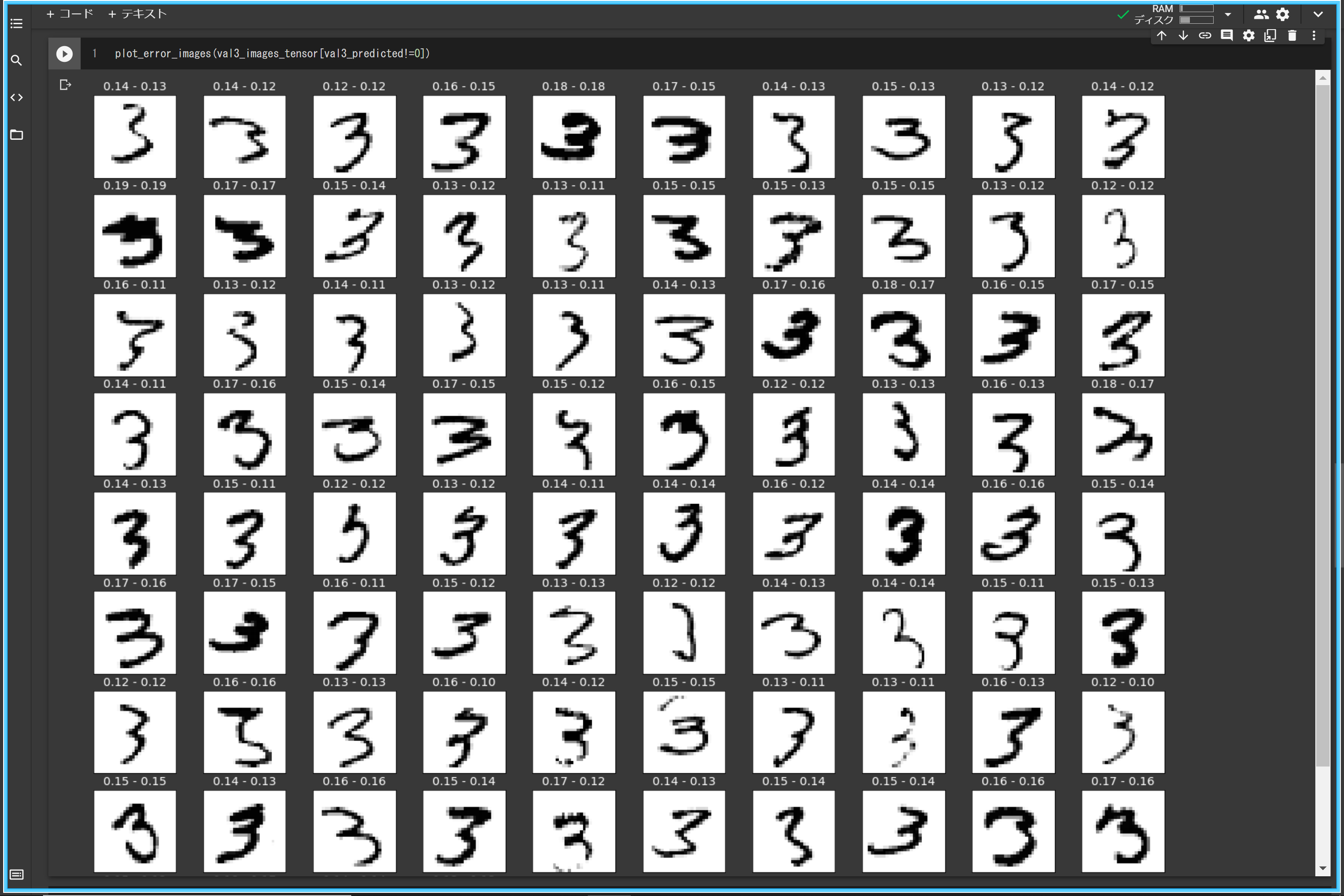
誤判定の画像の表示
def plot_error_images(err_imgs):
plt.figure(figsize=(24, 20))
for i in range(len(err_imgs)):
ax = plt.subplot(9,10, i+1)
ax.set_title(f'{err_imgs[i].l1_distance_from(mean3):.2f} - {err_imgs[i].l1_distance_from(mean7):.2f}', color='w')
ax.axes.xaxis.set_visible(False)
ax.axes.yaxis.set_visible(False)
plt.imshow(err_imgs[i])
3の検証画像の中で誤判定された画像を表示するには、次のように判定結果が0ないものを選んで表示すればOKです。
plot_error_images(val3_images_tensor[val3_predicted!=0])
上記のコードを実行した結果です。タイトルに表示した平均画像との差異をみると、エラーになったものは差異が拮抗していますね。
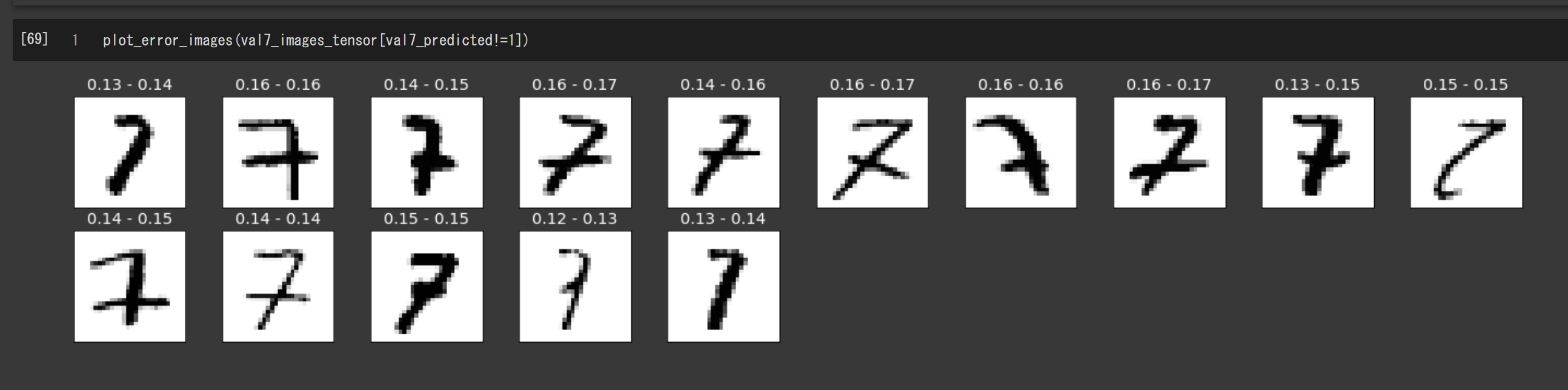
同様に、7の検証画像の中から判定結果が1でないものを選んで表示すればOKです。こちらも平均画像との差異が拮抗しています。
ということで、平均画像との差を画像として表示してみました。これをみると、大きさや太さはもちろん、ちょっとした平行移動や回転に対しても非常に弱いように感じます。まあ、画素値の差だけを使ってるだけなんで、仕方ないと言えば仕方ないですが、あらためてそれを確認できたということです。
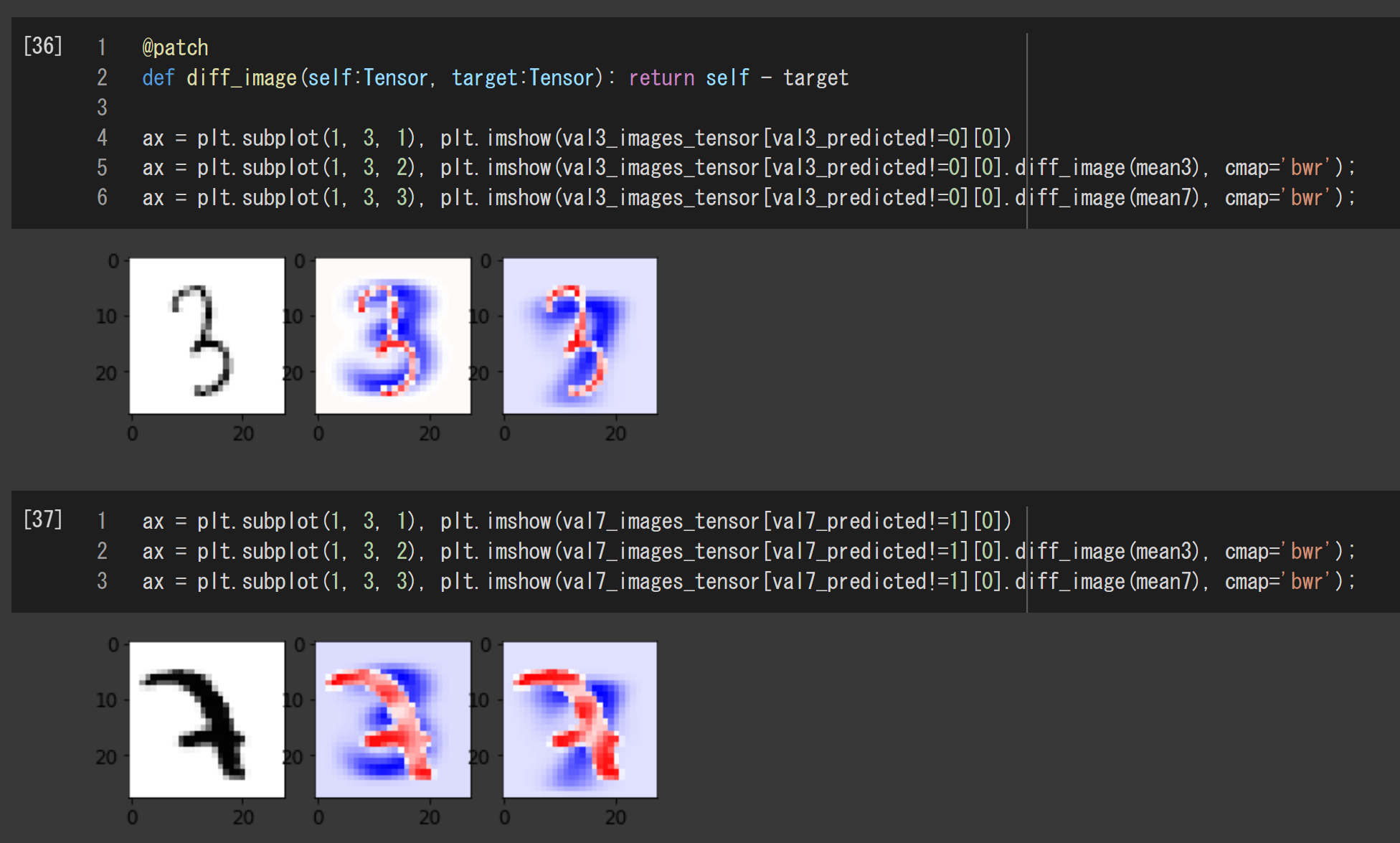
画像の引き算の結果は、正のところは赤、負のところは青、そして、0のところは白で表示されます。
関連記事
参考になるサイト
Deep Learning等の精度評価において、F値(Dice)とIoU(Jaccard)のどちらを選択するべきか?
fast.ai公式ページ
Practical Deep Learning for Coders
Lesson 3 - Deep Learning for Coders (2020)
Lesson 4 - Deep Learning for Coders (2020)