はじめに
この記事は、datatech-jp Advent Calendar 2021の25日目の記事となります。
AWS re:Invent 2021で Reshift Serverlessが発表されました。
このサービスは、すでに大規模なデータ基盤をゴリゴリ使って価値を生み出しているぜ!という方には、うま味が少ないかもしれませんが、
これからデータ基盤を作っていきたいという0 → 1フェーズの方には、ぜひ利用を検討してほしいサービスです。
Redshift Serverlessの特徴
詳しくは公式ページを見るとよいのですが、
一番の特徴は、クエリの実行に費やしたコンピュート時間のみに課金されるようになったことでしょう。
それにより従来のRedshiftのように24時間365日コンピュートを稼働させなくてよくなったのは非常にありがたいです。
また、半構造化データのサポート、データ共有、機械学習機能、Amazon S3データレイクへのクエリ、フェデレーションクエリなどAmazonRedshiftSQL機能をサポートしているようです。リリースいきなりでこれはすごいですね。
対象者
私は中小規模Sierでお客様のBI/データ基盤の設計・構築・運用を支援しているのですが、やはりお客様によってデータ量、データ活用の成熟度、かけられる予算がまちまちです。それぞれの要件に合わしたデータ基盤を構築するのが重要なことだと感じています。
以下は独断と偏見によるレベル分けと、選択すべきDWHサービスの第一候補です。
実際には、求める適時性やガバナンスなども考慮にいれます。
| 規模レベル | 利用人数 | データ量 | GCP | AWS |
|---|---|---|---|---|
| 1 | ~ 5人 | ~ 10 GB | Bigquery(オンデマンド) | Athena |
| 2 | ~ 10人 | ~ 100 GB | Bigquery(オンデマンド) | Bigqueryに転送 |
| 3 | ~ 100人 | ~ 10 TB | Bigquery(定額制) | Redshift |
| 4 | 100人 ~ | 10 TB ~ | Bigquery(定額制)など | Redshiftなど |
クラウド基盤にGCPを利用していたら、レベル1 ~ 2はBigquryオンデマンド料金、BIはGoogle Data Portalでよいと思います。
レベル3以上では、Bigquryの定額料金を検討しましょう、BIはLookerとかtableauが選択肢に入ります。
一方AWSだと、
レベル1の場合、データはS3に格納して、Athenaでクエリかけて分析するようにして、BIはQuicksightかtableau、多少不安定でも無料がよかったらコネクターを作って (Google Data Studio Developer Relationsがコネクターを公開してた!)Google Data Portalのようなデータ基盤が選択肢に入ります。
レベル2だと、データをBigqueryに転送を検討します。クラウドの越境にかかる通信費やマルチクラウド構成により増える管理費よりも、空焚きしているRedshiftの費用の方が高くつく場合は多いからです。
レベル3以上でRedshift の利用を検討するとよいかと思います。
長くなりましたが、今回の新しいサービスであるReshift Serverlessで一番恩恵を受けるのは、AWSを活用していてかつ規模レベル2以下の企業かと思います。このように書くと、少ないように感じますが、これからデータ活用を推進したい中小企業のほとんどが該当するのではないでしょうか?
この記事は、そのような方々がデータ基盤の構成を考える上での一つの参考になればと思います。
触ってみた
環境構築
そう言うわけで、期待の新サービスRedshift Serverlessを触ってみましょう。
画面ピクチャするのを忘れていたのでないのですが、
Redshiftのコンソールから「Try Amazon Redshift Serverless (Preview)」というボタンをクリックして、サーバレスエンドポイントを作成します。設定はデフォルトです。また、previwe版のためかstarter base configrationを選択すると、低い性能のものを500ドル無料で使えるようで、今回はチェックをいれました。
Redshift query editor v2からクエリを実行してみる
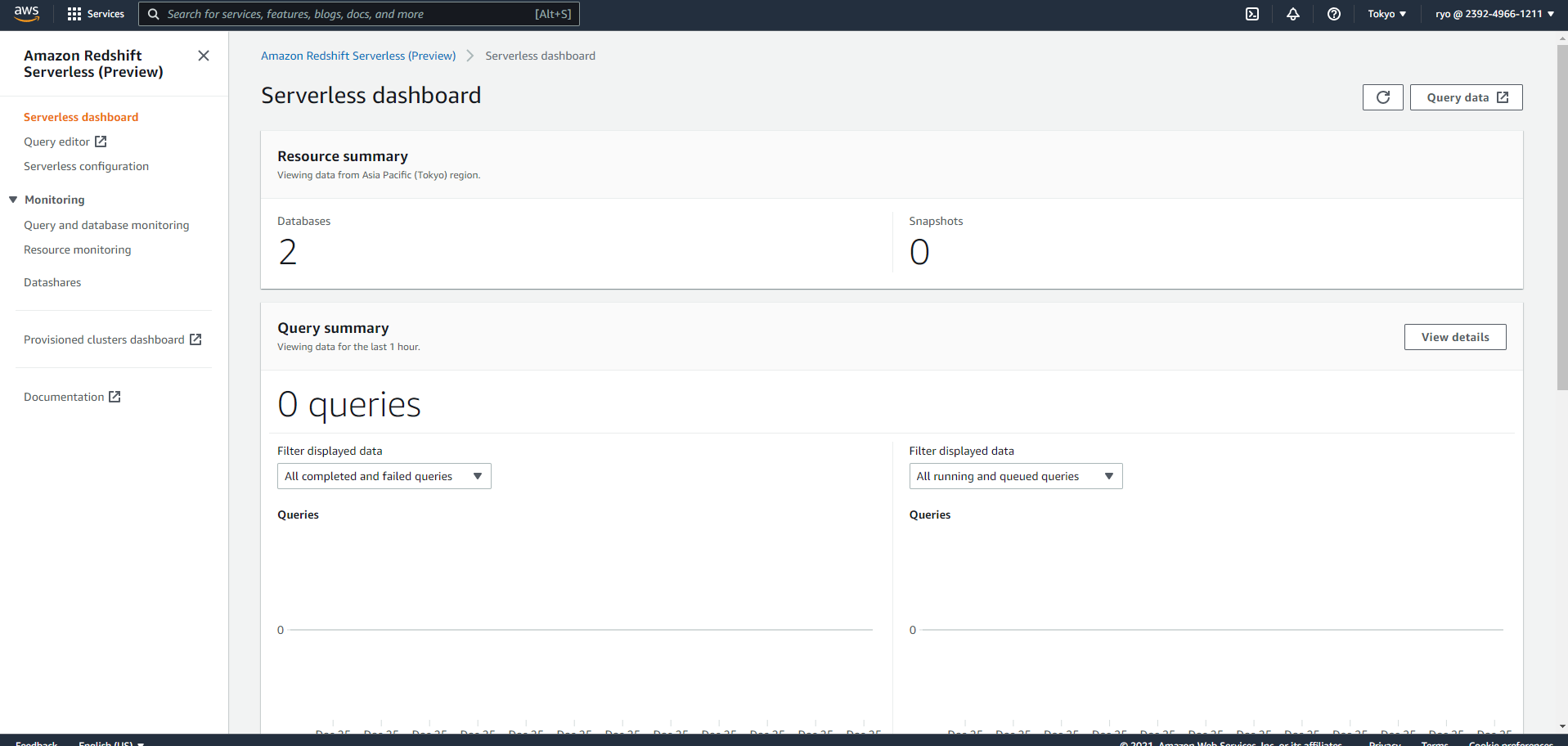
エンドポイントの作成が完了すると、下のようなダッシュボードがみれるようになります。
右上の「Query data」から実際にRedshift Serverlessでクエリを実行しましょう。せっかくですし、エディタはRedshift query editor v2を利用します。
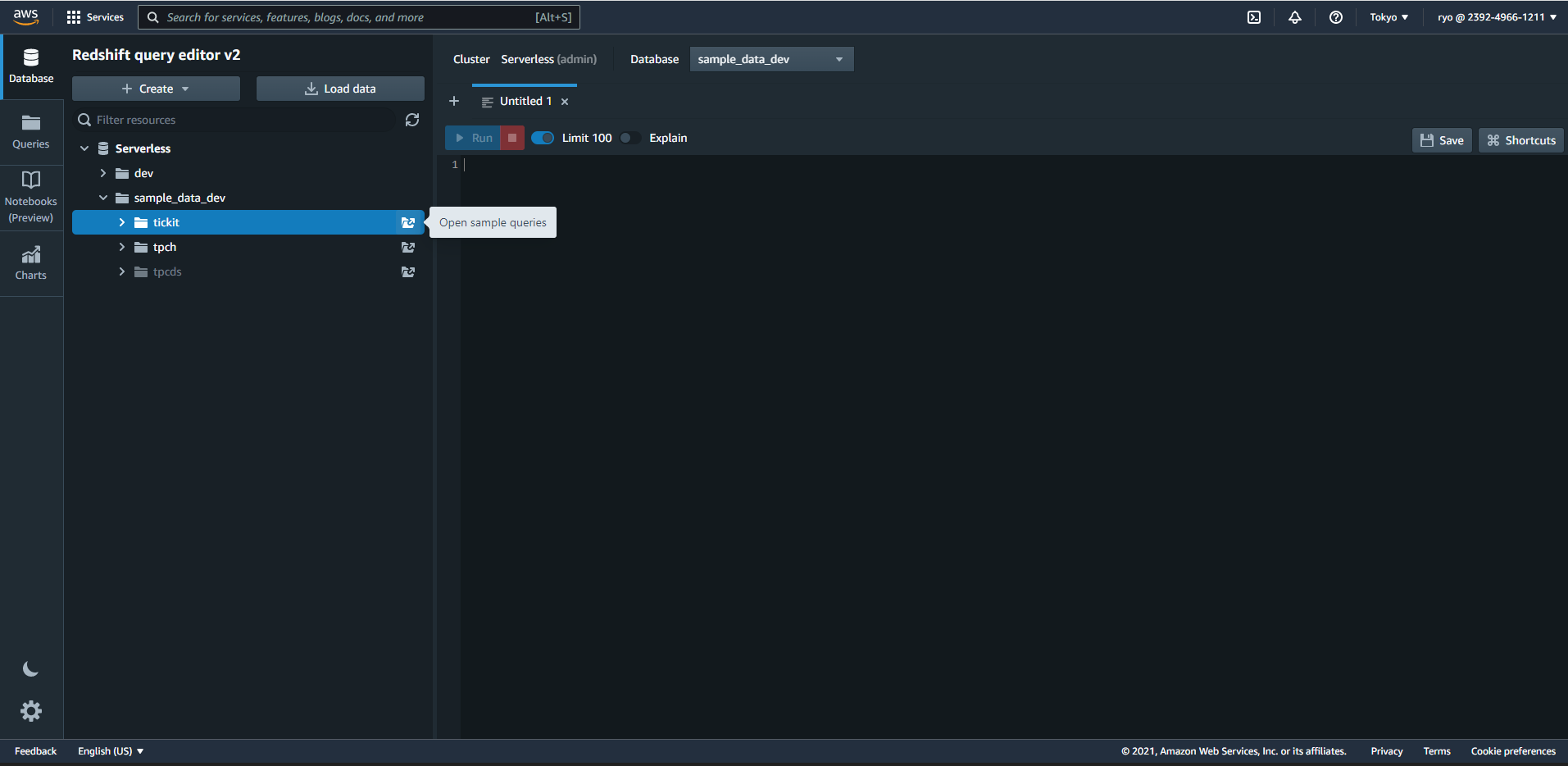
画面左側のDatabeseに Serverless/sample_data_dev/ticketのOpen sample queriesをクリックしましょう。
どうやらOpen sample queriesをクリックしたときにsampleデータがロードされるようです。
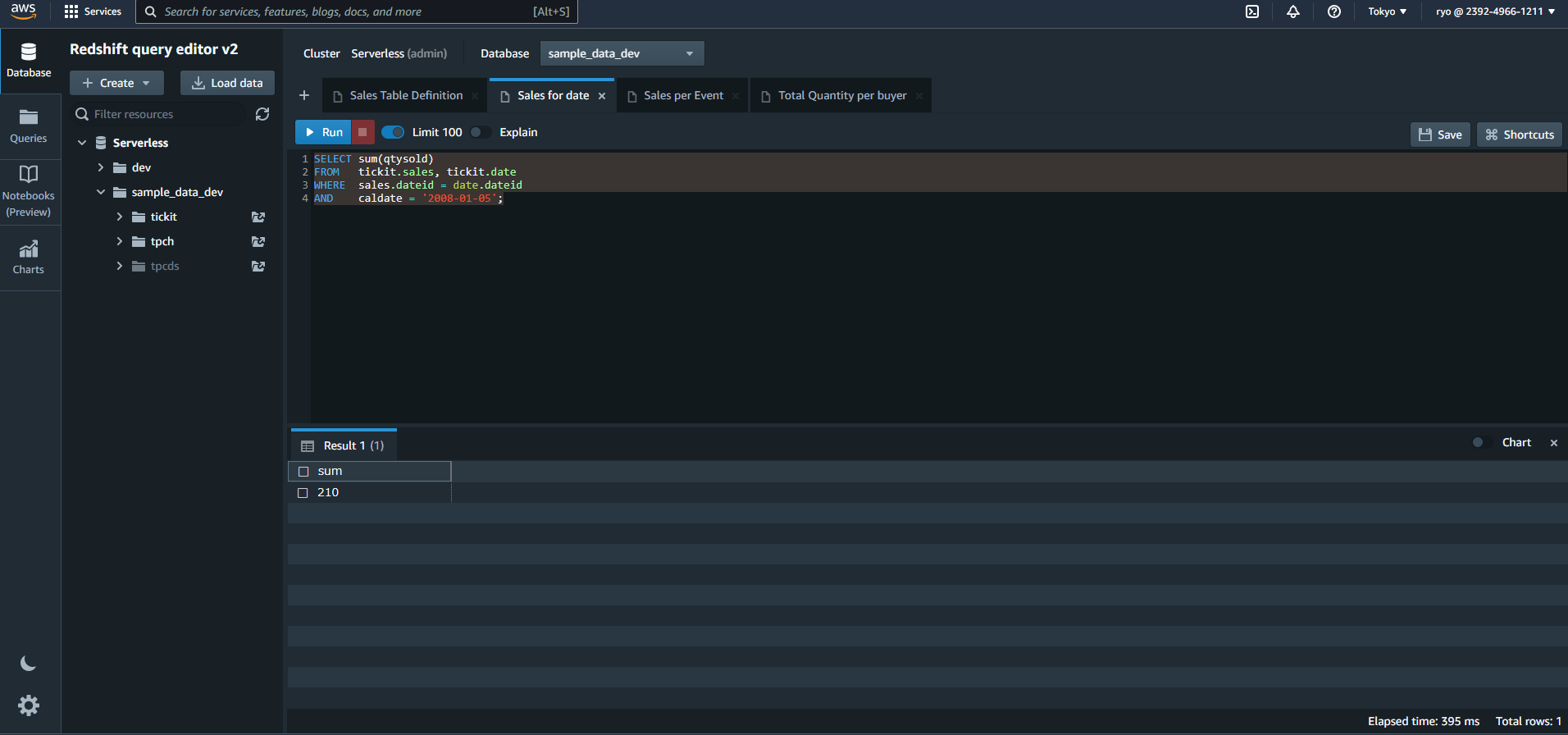
いくつかのサンプルクエリが生成されると思うので、そのまま実行してみましょう。
SELECT sum(qtysold)
FROM tickit.sales, tickit.date
WHERE sales.dateid = date.dateid
AND caldate = '2008-01-05';
ちゃんと実行結果がでてきました。
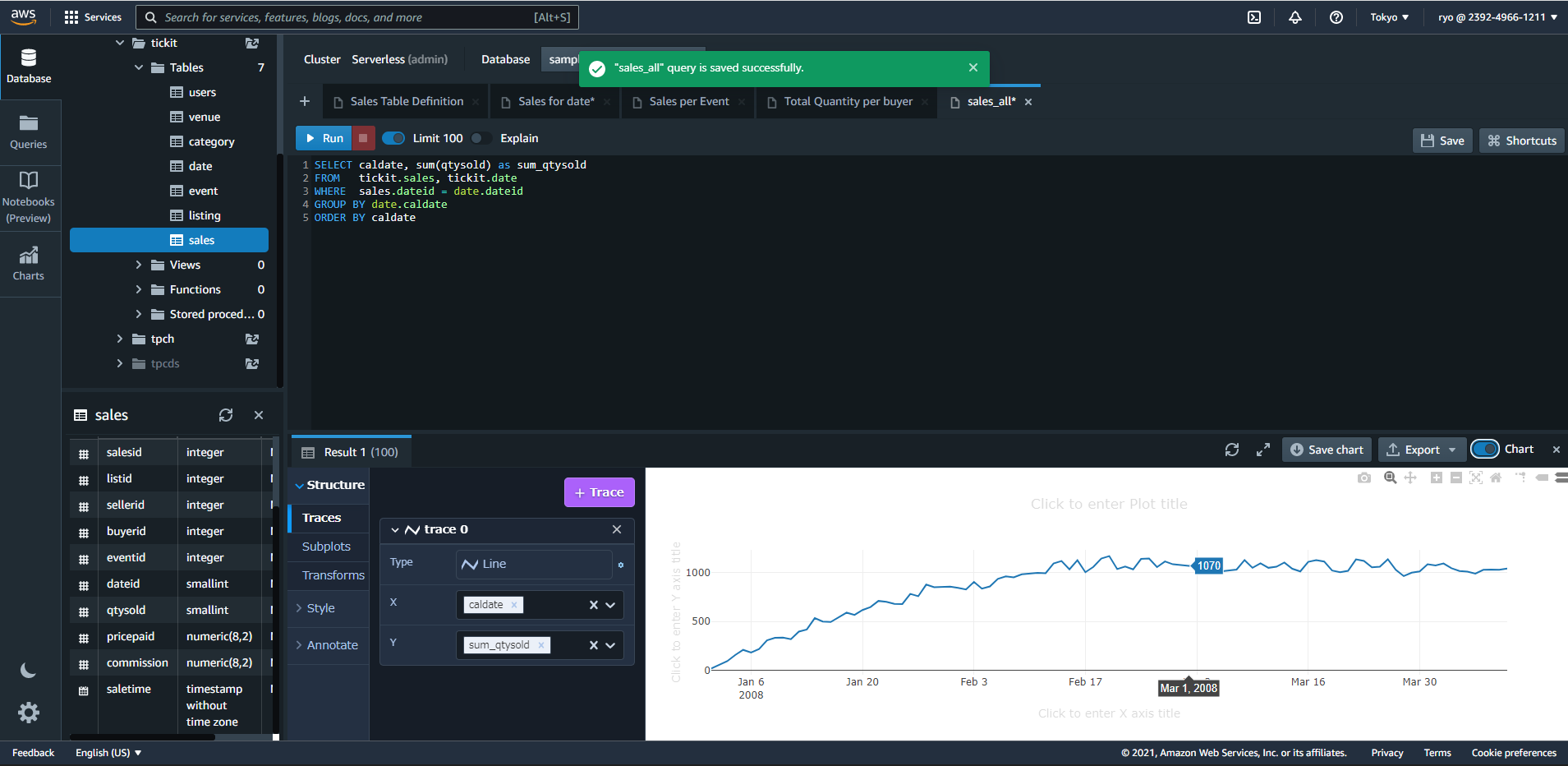
Chart機能
もう少し、それっぽいSQLを書いてみました。
qty(販売数量かな?)の日別の合計値を出してみます。
SELECT caldate, sum(qtysold) as sum_qtysold
FROM tickit.sales, tickit.date
WHERE sales.dateid = date.dateid
GROUP BY date.caldate
ORDER BY caldate
そして、結果の右に"Chart"を有効化すると、グラフがでてきました。
ちなみにサポートしているグラフのタイプは以下の通りです。主だったところはサポートされているので、簡単なSQLの結果を確認するにはこれで良いかもですね
Explain機能
Explainという機能があるようなので触ってみます。
Runボタンの右側にExplainボタンがあるのでOnにします。するとExplain graphも出てきたのでこちらもOnにします。
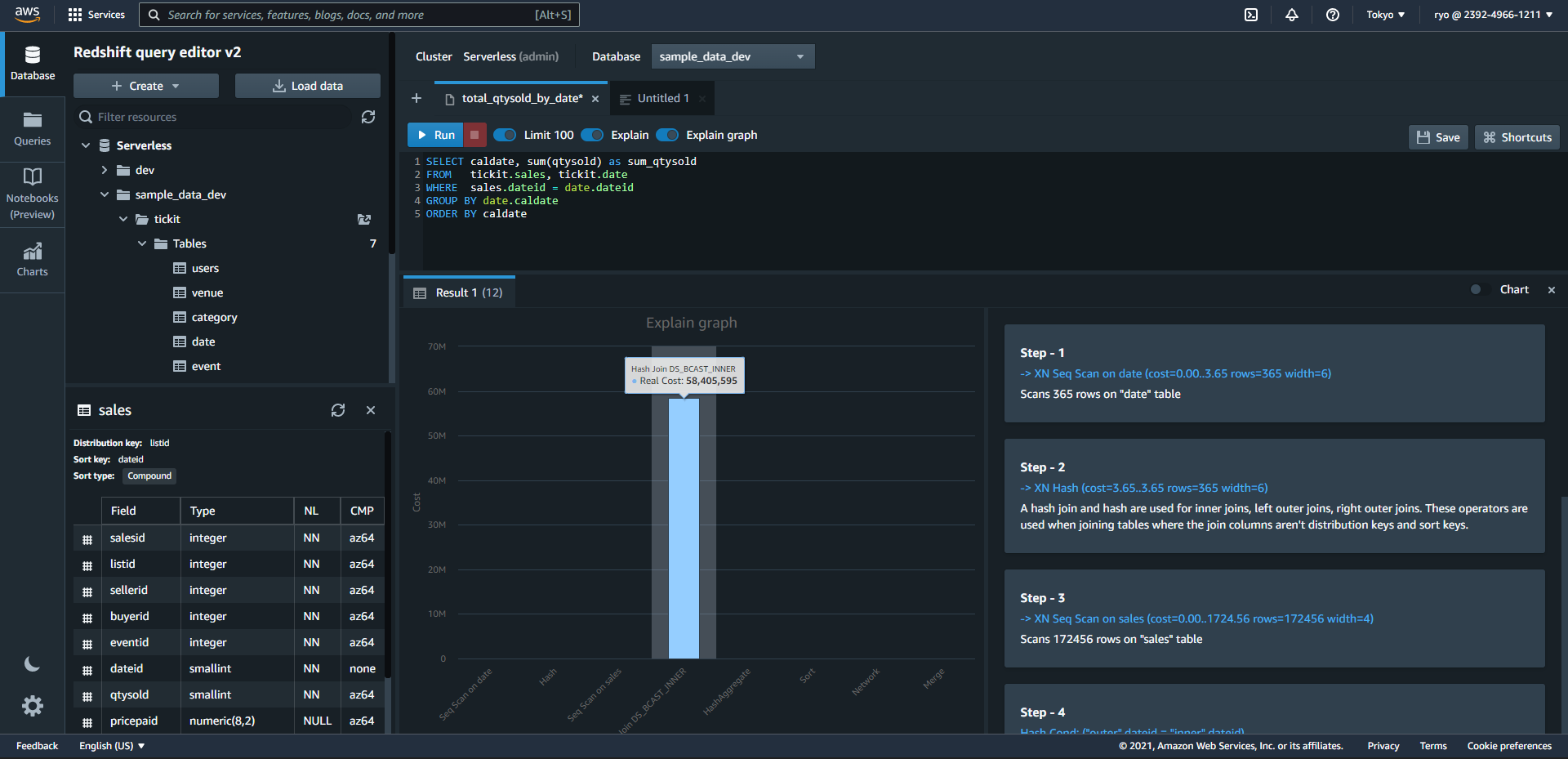
先ほどのクエリを実行してみましょう。
なぜか下の方が切れていますが、出てきました。Hash Join DS_BSCAST_INNERというSTEPが58M Costがかかっているようで圧倒的ですね。(※コストの単位を見つけられなかったのが気になります。RPU のマイクロ秒?)
グラフの右側の説明を見ると、「結合カラムが分配キーやソートキーでないテーブルを結合するときに使用されるinner joins, left outer joins, right outer joinsのこと」らしいです。つまり、cross join以外の普通のJoinですね。
次に、以下のようにSQLを直してみました。
Joinにコストがかかっているようでしたので、Joinをする前に集計することでjoinする行数を減らそうという試みです。
SELECT caldate, sum_qtysold
FROM (
SELECT dateid, sum(qtysold) as sum_qtysold
FROM tickit.sales
GROUP BY sales.dateid
) as pre, tickit.date
WHERE pre.dateid = date.dateid
ORDER BY caldate
結果として、Joinにかかるコストはほどんどなくなりました。
(ただ58M → 13 は効果がありすぎの気がします…。saleでは20480rowsでしたが、これが日別で集計され365rowsになった結果だと思いますが、それにしても効きすぎているような…。)
ちなみに、このクエリで一番コストがかかっている。Seq Scan on salesはsalesのテーブルを読み込むのにかかるコストのようです。
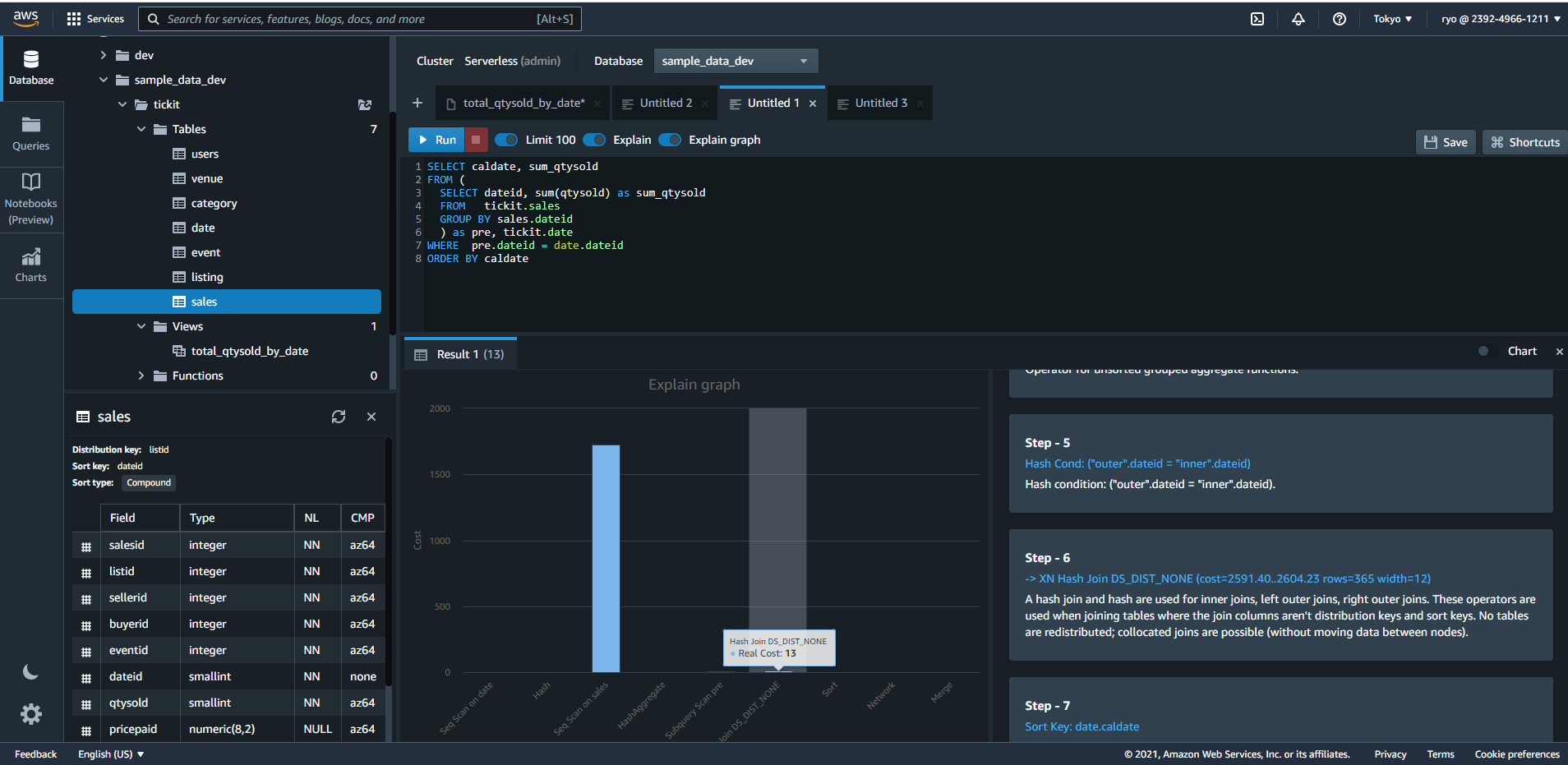
このように細かくコストが分かると、SQLのパフォーマンス改善もやりやすくてよいですね。
終わりに
今回は、まだプレビュー版ですが、Redshift Serverlessを触ってみました。
データ基盤の新しい選択枝が増えるのは良いことですね!
時間があれば、BigqueryやSnowflakeとの比較などもしていきたいと思います。
以上、読んでいただきありがとうございました!