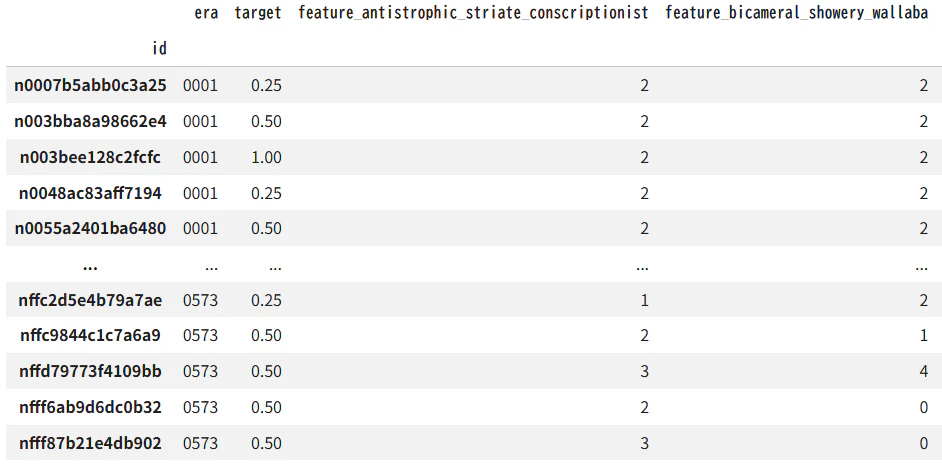
Numeraiの概要
Numeraiは金融商品予測モデルの性能を競うコンペです。参加者が提出したモデルを束ねたメタモデルでヘッジファンドを運用しています。提出したモデルに賭け金を払うと、ヘッジファンドへの貢献度に応じて仮想通貨 Numeraire(NMR)が配当/焼却されます。
用語
-
era: ある時点のこと -
symbol: ある銘柄のこと -
token: era・銘柄ごとのデータのこと。1行が 1 token に対応 -
id: tokenの識別子。日付・銘柄を特定できないように暗号化 -
feature: 特徴量。テクニカル指標、市場データなど。標準一様分布に変換し、{0,1,2,3,4}にビン化 -
target: ターゲット。20営業日後の対数収益率の線形回帰の残差を標準一様分布に変換、標準正規分布に変換、{0, 0.25, 0.5, 0.75, 1.0}にビン化
コンセプト
アルファの追求
市場全体の傾向(ベータ)を予測するだけのモデルに価値はありません。インデックスファンドを買えば済むからです。
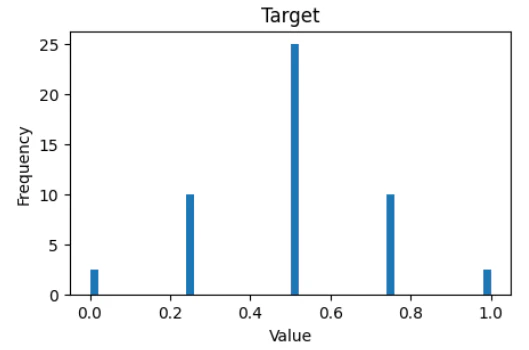
Numeraiが目指すのは市場平均を上回るリターン(アルファ)をあげること1です。そのためターゲットはベータを取り除いた状態で参加者に提供されます。アルファは相対的なリターンを意味するため、ターゲットはリターンのランク(を標準正規分布に変換し、ビン化したもの)です。
ターゲットは中間が50%、その次が40%、端が10%となるように変換されています。これはおそらく、実運用では信頼度の高い上位/下位が優先して売買されるからだと思います。
日付と銘柄の隠蔽
日付と銘柄は完全に隠蔽されています。それぞれの特徴量も何を意味するのかさえ理解できないように設計されています。
これは、高価な金融データを無料で提供できないという大人の事情2によるところが大きいようです。
一方で、こうした隠蔽はモデルの過学習を抑制します。重要なのは特定のera・特定の銘柄のリターンの予測ではなく、すべてのera・すべての銘柄に共通する「普遍的な統計パターン」を見つけ出すことです。
この記事のモチベーション
堅牢性を追求するNumeraiのテクニックが、ビジネスの現場のモデル構築に役立つでしょう(たぶん)。
警告
私はNumeraiに一度も参加したことがありません。
Numeraiのテクニック
特徴量エンジニアリング
標準一様分布への変換・ビン化
金融時系列データはノイズまみれです。
私は過去に、min-maxスケーリングしただけのほぼ生の金融データをTransformerに入力し、株価のリターンを予測しようとしたことがあります。結果、外れ値の影響で損失値がNaNになり学習が停止しました。外れ値を取り除き最後まで学習しても、精度は恐ろしいほど低かったです。
特徴量をera単位で標準一様分布に変換・ビン化すると、外れ値の影響を抑制し、ノイズへの過剰反応を防ぐ正則化の一種として機能します。
また、特徴量が8ビット整数であることは、マシンコスト削減・学習速度向上にもつながります。
学習
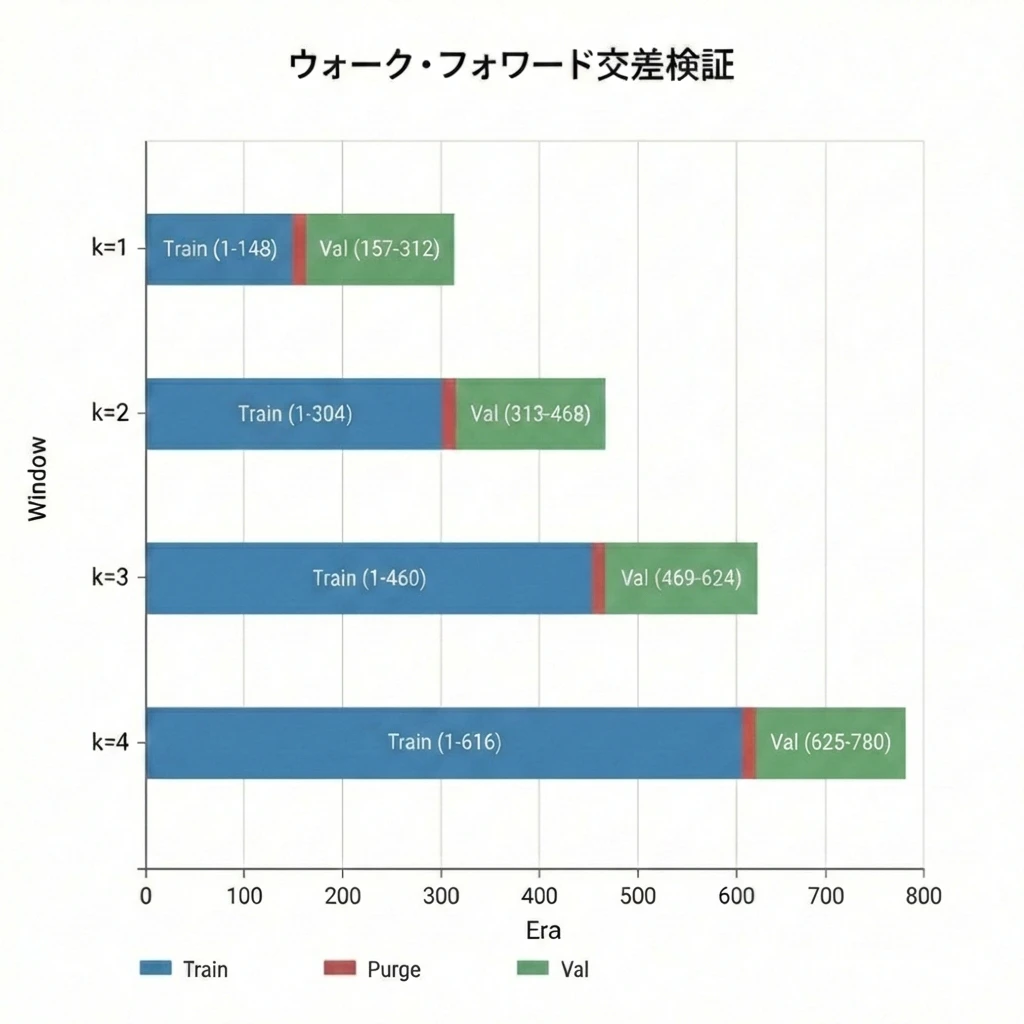
ウォーク・フォワード交差検証(Walk Forward Cross Validation)
Numeraiはベンチマークとなるモデルを公開しています。これらのモデルはすべてウォーク・フォワード交差検証を通して作成されます3。ウォーク・フォワード交差検証は未来の情報がリークするのを防ぎ、実運用に近い方法でモデルの性能を検証できます。
パージ(Purge)
リーケージを確実に防ぐため、学習データと検証データの間にパージ(除外)期間が設けられています。20営業日後のリターンの予測の場合は 8 era、60営業日後の場合は 16 era をパージします3。
中立化(Neutralization)
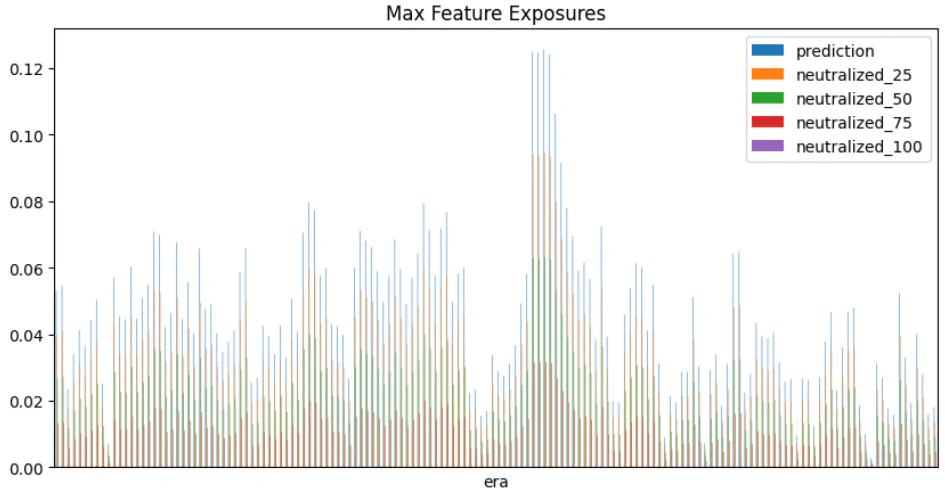
中立化は、モデルが相関の高い特徴量から曝されているリスク(エクスポージャー)を減らす処理であり、予測値に対する特徴量の線形回帰の残差を新たな予測値とします。中立化の割合(α)は0.0~1.0です。エクスポージャーの減少とパフォーマンスの向上はトレードオフの関係にあり、適切なαを探索する必要があります。
$$
\hat{\mathbf{y}}_{new} = \frac{(I - \alpha X X^+) \cdot \text{GaussRank}(\hat{\mathbf{y}})}{| (I - \alpha X X^+) \cdot \text{GaussRank}(\hat{\mathbf{y}}) |}
$$
アンサンブリング
異なるターゲット(例:20営業日後のリターンと60営業日後のリターン)で学習した複数のモデルの予測値を、平均または加重平均します3。
評価
エクスポージャー
エクスポージャーは予測値と特徴量の、era単位のピアソンの積率相関係数です。特徴量選択に役立つでしょう。
$$\rho = \frac{\operatorname{cov}(\hat{y}, y)}{\sigma_{\hat{y}}\sigma_{y}}$$
Numerai CORR
Numerai CORRは予測値とターゲットの絶対値を1.5乗したときの、era単位のピアソンの積率相関係数です。1.5乗するのは上位/下位のスコアを強調するためです。
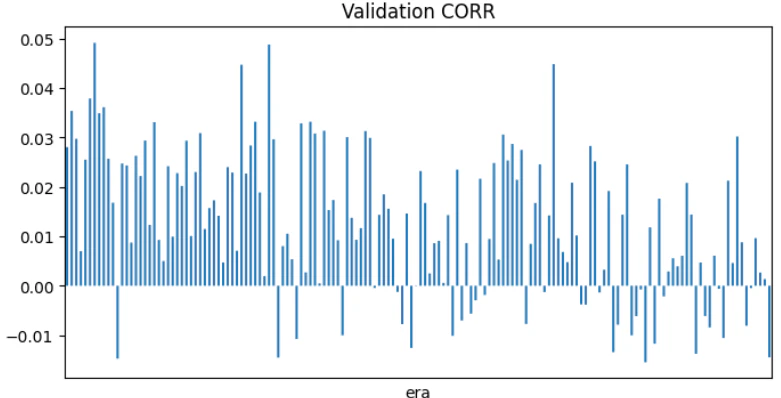
累積値
他のモデルと比較するときはCORRの累積値が見やすいでしょう。
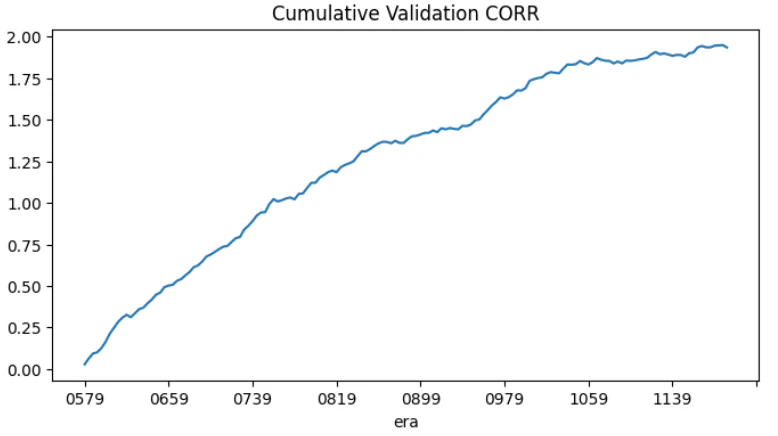
平均
長期的なパフォーマンスはCORRの平均値で測ります。
シャープレシオ(Sharpe)
SharpeはCORRの平均を標準偏差で割って計算します。標準偏差が小さいほど高い値になり、モデルの一貫性を測る指標です。
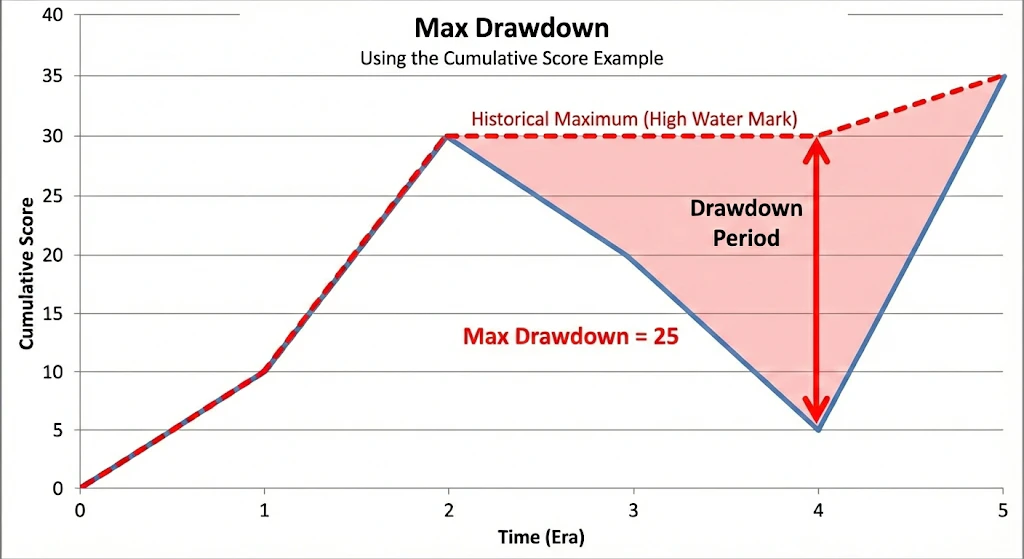
Max Drawdown
CORRの累積値の最大の下落幅であり、リスクの指標となります。
所感
eraごとの相対的な値に関心があるというのは、割と特殊な条件なので、標準一様分布に変換・ビン化をセットで適用するのは難しいかもしれません。
一方、過学習を防ぐために連続値をビン化するのはよく行われる手法で、非常に取り入れやすいと思います。
ウォーク・フォワード交差検証や各評価方法はスケジュールに余裕があり、モデルの性能をより厳密に評価したい場合に実施するとよいでしょう。
参考資料
- 公式サイト: https://numer.ai/
- 公式ノートブック:https://github.com/numerai/example-scripts
- Medium公式アカウント: https://medium.com/numerai