以下関連記事です。
- 🌟Getting Started With Application Development(Datastore, Bigtable, Cloud Spanner, etc)
- Securing and Integrating Components of your Application(IAM, IAP, Pub/Sub, Cloud Endpoint, Cloud Function, etc)
- App Deployment, Debugging, and Performance(Cloud Build, App Engine, Cloud Monitoring, etc)
Cloud SDK, Cloud Client Libraries, & Firebase SDK
- Cloud SDK
- gcloudコマンド(create/manage GCP resources) e.g.
gcloud compute instances list - bqコマンド
- gsutilコマンド(for cloud storage)
- gcloudコマンド(create/manage GCP resources) e.g.
- Client Libraries
- Google API Client Libraries should only be used if your programming language of choice isn't supported by the Google Cloud Client Libraries
- Cloud SDKのみ、gRPC通信を採用
- Firebase SDK
Billing
意図せぬ超過を防ぐために、
- budgets and alerts
- 予算を金額で設定する。その50%, 90%, 100%使用時にアラートが飛んでくる
- billing exports
- Cloud StorageやBQに吐き出せる
- reports
- GCP上で確認できる。
- quotas
- Projectレベルでリソースごとにリソースの使用料で指定する。指定量に達するとリソースが使用できなくなるという認識。
- rate quotas (その時点から一定期間以内の使用量が一定値をを超えているか)
- allocation quotas (その時点までの全使用量が一定値を超えているか)
- Projectレベルでリソースごとにリソースの使用料で指定する。指定量に達するとリソースが使用できなくなるという認識。
Databases
Cloud Datastore
- NoSQLで、スキーマレス
- 保持するデータの大きさによって自動でスケールする
- Data がsemi-structured/hierarchical の時におすすめ
- shardingとreplicationを自動でやってくれる
- ACID transaction, SQL like query, Indexes
- 元々はBigtableの拡張版として誕生したが、今ではFireStorの中の1モードとなっている。(FireStoreDataStore mode)
- ちなみに、FireStoreは、DataStoreモードとNativeモードの二つがある
- 一度モードを選択すると、そのプロジェクト内ではそのモードしか使えなくなる
- クエリ言語はGQL
- serializable isolationに対応しているらしい。
データの持ち方に関して。
- data objectはentityと呼ばれている。
- entityはuniqueなkeyを持つ。key=
namespace+entity kind+identifier+ancestor path(optional) - トランザクションとは、最大で 25 個のエンティティグループ内の 1 つ以上のエンティティに対する一連の Datastore オペレーションです。(= 複数のエンティティーをひとまとめにして、transactionが有効になるという認識、またtransactional commitを有効にする必要があるという認識)
- entityは他のentityをparentとしてもてる。親を持たないentityはrootと呼ばれる。自分より親側はancestors, 子側はdescendantsと呼ばれる。entityと他のentityとの間のpathは、
entity pathと呼ばれる。 - 同一のkind(RDBでいうテーブル)内でもentityによって異なるpropertyを持つことが可能
- entityはuniqueなkeyを持つ。key=
- datastoreに、
built-in indexと、composite indexesという二種類のindexを持つ。- 事前にindexを貼ったpropertyを指定したクエリしか実行できない
- built-in indexは、GCP上に表示されない、entityのそれぞれのpropertyにデフォルトではっつけられる
- composite indexを新しく作成するするには、
index.yamlを編集し、$ gcloud indexes createを実行する - composite indexを削除するためには、
index.yamlを編集して不要なものを削除し、$ gcloud datastore indexes cleanupを実行する(put操作)

シャーディングに関して。
(sharding = vertical partitioning)
- Datastoreでは、一つのentityに対する操作は、マックスで毎秒一回にしたい。
- 超えると、latencyが大きくなったり、contention errorが発生したりする
- Datastoreでは、データサイズによって自動でシャーディング(=スケーリング)してくれる
シャーディングして嬉しいのwriteヘビーなケース。 引用。確かに、readヘビーなのだったらレプリケーションで良いな。

あくまで、「単体のread処理やwrite処理を高速化する」のが目的ではなく、「特定のentityへのreadやwriteが過剰に行われる事によるホットスポットが発生するのを防ぐ」のが目的だという認識。
![]() DataStoreに関しては、書き込みでhotspotの発生を考慮する必要はなさそう
DataStoreに関しては、書き込みでhotspotの発生を考慮する必要はなさそう

クエリに関して
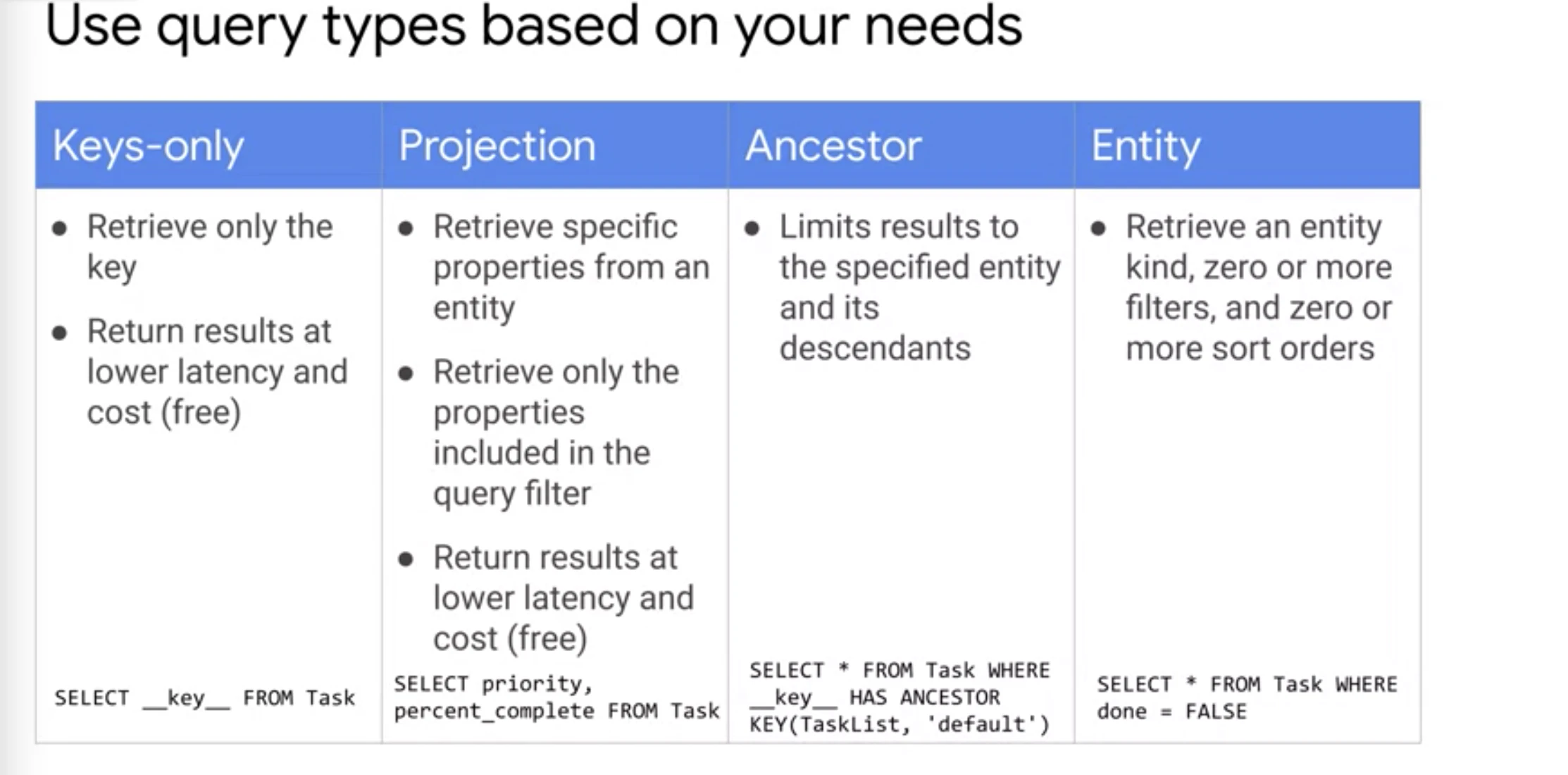
- (クエリのバッチオペレーション)Batch operations allow you to perform multiple operations on multiple objects with the same overhead as a single operation.
500/50/5 rule (Ramping up traffic)
Gradually ramp up traffic to new kinds or portions of the keyspace.
You should ramp up traffic to new kinds gradually in order to give Firestore in Datastore mode sufficient time to prepare for the increased traffic. We recommend a maximum of 500 operations per second to a new kind, then increasing traffic by 50% every 5 minutes. In theory, you can grow to 740K operations per second after 90 minutes using this ramp up schedule. Be sure that writes are distributed relatively evenly throughout the key range. Our SREs call this the "500/50/5" rule.

Cloud Bigtable
- high performance, NoSQL database service, 列指向DB
- sparsely populated table (列を使用していない行では、列による空間の消費はありません)
- can scale to billions of rows and 1000s of columns.
- can store terabytes to petabytes of data.
- built for fast key value lookup and scanning over a defined key range. (keyによる検索はできるがカラム指定による条件検索はできない、key-value)
- データの結合(JOIN etc)はできない
- key updates to individual rows are atomic.(行ごとにしかatomicにならない、、)
- offers seamless scaling. Changes to the deployment configuration are immediate so there's no downtime during reconfiguration.
- 行と列の交差には、タイムスタンプ付きのセルを複数含めることができます。各セルには、その行と列のデータに付けられた、タイムスタンプ付きの一意のバージョンが格納されます。
- HBase(BigTable を元に設計されたOSS)と同じAPIを持つ。 Bigtableの方がHBaseを自前で立てるよりも優れている点は以下。
- マシンが簡単に増やせるのでscalabilityに優れている
- upgradeやrestartを自分でしなくて良い。
- データが暗号化されているのでよりsecureである。
- IAMポリシーを利用して誰がどのデータにアクセスできるかをコントロールできる。
- Dataの持ち方はCassandraに似てる
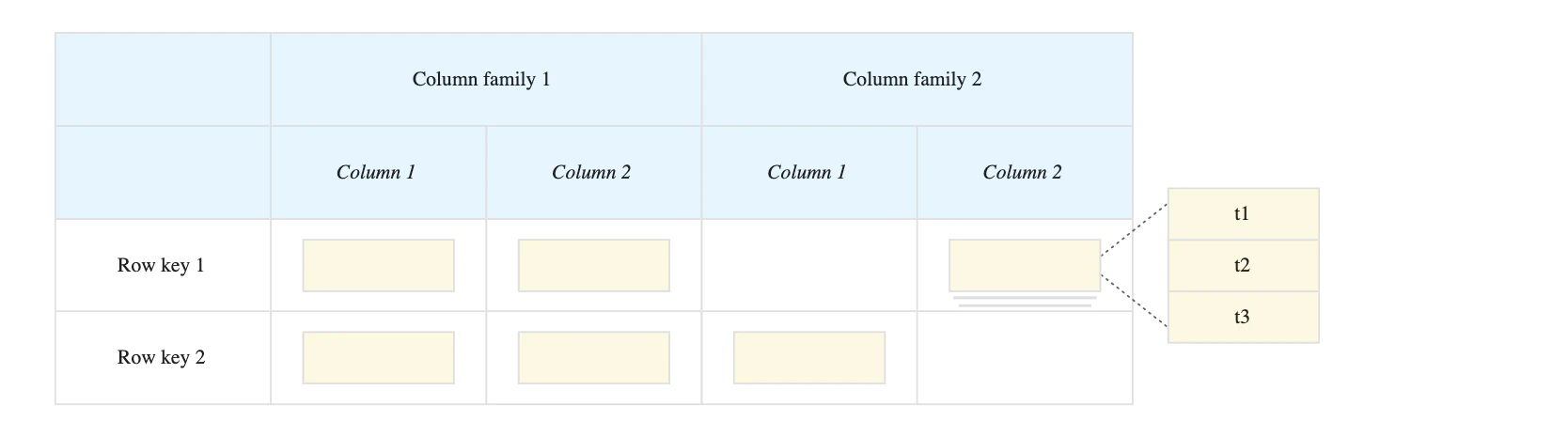
(関連する列は列ファミリーとしてまとめられる)

行キーは、データの取得に使用するクエリに基づいて設計します。
適切に設計された行キーは、Bigtable のパフォーマンスを最大限に高めます。
Bigtable のクエリでは、次のいずれかを使用してデータを取得するのが最も効率的です。
- 行キー
- 行キーの接頭辞
- 開始行キーと終了行キーで定義された行の範囲
その他のクエリでは全テーブル スキャンが行われるため、効率が大幅に低下します。
設計の段階で正しい行キーを選択すれば、後で面倒なデータ移行処理を行わずに済みます。
ベストプラクティス
See: https://cloud.google.com/bigtable/docs/schema-design#best-practices
行キー は特に要チェック🔥
わかりやすいものだけ以下に抜粋。
-
小さなテーブルを多数作成することは、Bigtable ではアンチパターンになります。
-
1 つの行に 100 MB を超えるデータを保存しないでください。
- この上限を超える行があると、読み取りパフォーマンスが低下する可能性があります。
- 保存可能な上限は 256MB
-
1 つの行キーは 4 KB 以下にする必要がある
-
エンティティのすべての情報を 1 行に保存します。 <-
行をまたいだtransactionは作成できないので -
関連するエンティティは隣接する行に保存して、読み取り効率を高めてください。
-
読み取りと書き込みは(テーブルの行スペース全体に)均等に分散されるのが理想的です。<-
書き込み時にも、行keyを元に挿入場所を探すことに注意 -
行キーに関して以下は避けるべし
-
先頭がタイムスタンプである行キー- writeが単一のnodeに集中する
-
関連データをグループにまとめられない行キー- 言わずもがな、行範囲が連続していないと、まとめて読み取ることが非効率になります。)
-
ハッシュ値- デバッグしづらい
- (c.f. [CloudSpannerでは、主キーをハッシュにするのは推奨されている方法の一つ]
-
シーケンシャル数値 ID- user idとか、新規のユーザーのほうがアクティブなユーザーになる可能性が高いため、このような方法では、大半のトラフィックがごく少数のノードに集中してしまいます
- 数値を反転させたらOK.(https://cloud.google.com/spanner/docs/schema-and-data-model))
-
頻繁に更新される識別子- 使用頻度の高い行が格納されているテーブルが過負荷状態になります。また、ガベージ コレクションの際にセルが削除されるまで列の以前の値が容量を消費するため、行のサイズが上限を超えてしまう可能性もあります。
- 代わりに、新しく読み取るごとに新しい行に保存します。
-

Cloud Spanner
-
分散RDB
-
locationは、multi-regionかregionのいずれかを選択できる
-
親子テーブル関係
-
外部キー(言わずもがな、RDBですので) テーブル インターリーブ
-
-
Cloud Spanner は、主キーの値の順序で行を格納し、連続する行は同一nodeに保存される。(ここはBigtableと共通)
-
ゆえに、hotspotとなるnodeを作らないように、キーはランダムになる様にする。このための方法として考えられるのは、以下。
-
キーをハッシュして列に格納する。主キーとしてハッシュ列を使用します(またはハッシュ列と一意のキー列を一緒に使用します)。
-
主キーの列の順序を入れ替える。
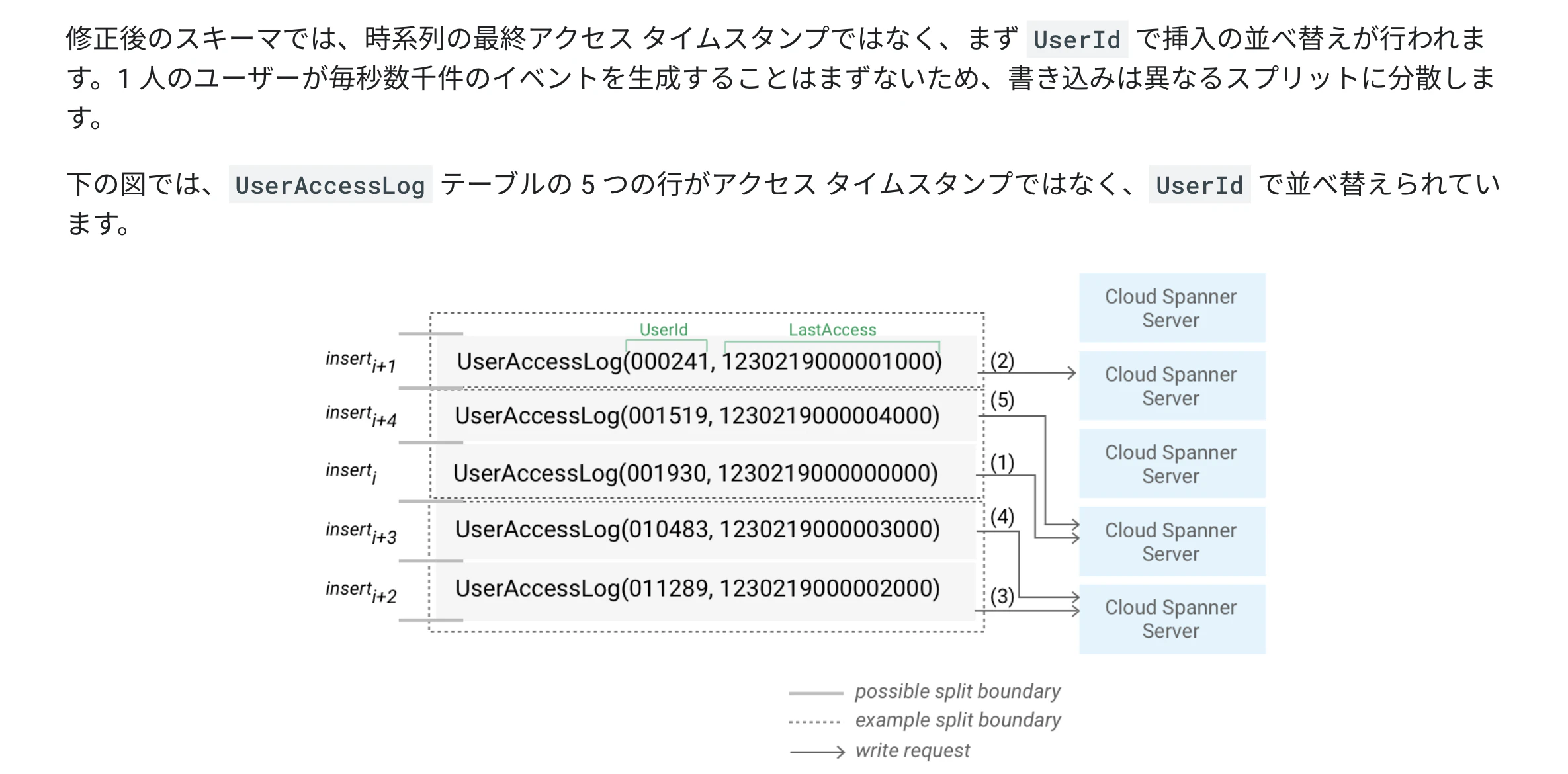
- 上の例だとユーザーidによる偏りが生じるからまずい気がする。というか、Bigtableでは、ユーザーidを行キーにするとhot spotが生じるのでダメと怒られた。リクエスト数の問題だろうか。
-
Universally Unique Identifier(UUID)を使用する。
- 上位ビットのランダム値が使用されるため、バージョン 4 の UUID をおすすめします。
- 上位ビットにタイムスタンプを格納する UUID アルゴリズム(バージョン 1 UUID など)は使用しないでください。
-
連続した値をビット反転する。
-

Cloud SQL
-
RDB, (ゆえに)行指向DB
-
簡単にCloud SQL Proxyが使用できる
- The proxy uses a secure tunnel to communicate with its companion process running on the server. Cloud SQL proxy provides secure access to your Cloud SQL second generation instances without your having to allow IP addresses or configure SSL. The proxy uses the Cloud SQL API to authenticate with Google Cloud. You must enable the API before using the proxy, and you must provide the proxy with a valid user account.
- クライアント側のマシン
cloud_sql_proxyコマンドを実行することでlocalhost:3306に接続すると、指定された Cloud SQLに繋がる。 - https://qiita.com/cognitom/items/c6b2ccb6e6b0f731850a がわかりやすい
-

Cloud Storage
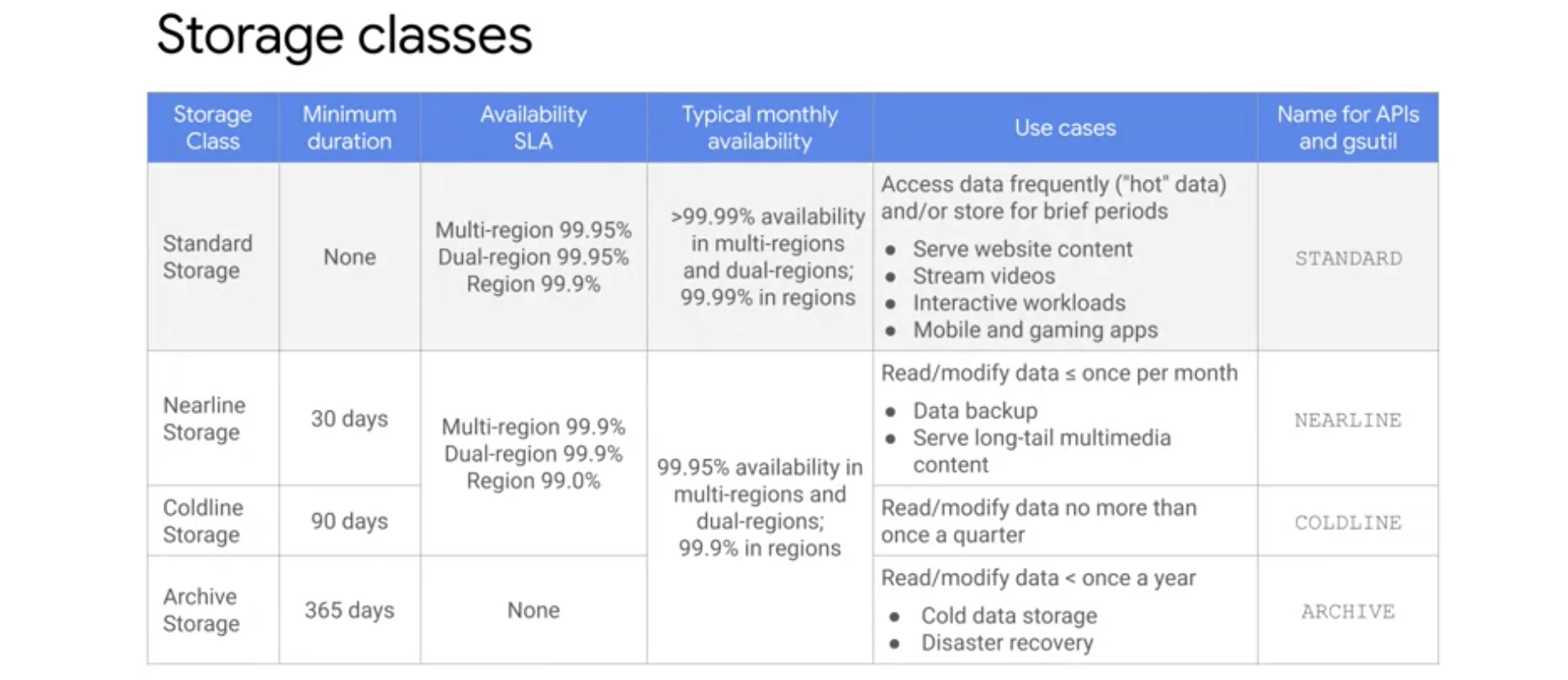
(minimum storage durationとは、 -> A minimum storage duration applies to data stored using one of the above storage classes. You can delete the file before it has been stored for this duration, but at the time of deletion you are charged as if the file was stored for the minimum duration.)
Consistency
以下はstrong consistency
- Read-after-write
- read-after-metadata-update
- read-after-delete
- bucket listing
- object listing
- granting access to resources.
以下はeventual consistency
- revoking access (1分くらいかかる)
- accessing publicly readable cached objects (キャッシュのライフサイクルが期限切れになるまでは変わらない)
endpoint

(cnameレコードには、ドメイン名に付けたあだ名が書いてある)
Composite Objects
-
最大32のobjectをconcatanateして、一つの新たなobjectを作成することができる
- 新しくできたobjectは元のobjectを参照しているわけではなくコピーしているので、元のオブジェクトは削除して良い
- これにより、大きなobjectをchunkに分けてparallelにアップロードすることができる。
-
ただし、一回でentire objectをuploadできるのなら、そちらの方が、costはかからないし、overheadも少なくて済む
trafficのbest practice
- retryポリシー
- gsutil, client libraryを使ったリソース取得のretryポリシーは、 truncated exponential backoffを採用すべし。
- cloud consoleでのリソース取得は、実は内部でbackoffをするように実装されている。
- gsutil, client libraryを使ったリソース取得のretryポリシーは、 truncated exponential backoffを採用すべし。
truncated exponential backoff とは
- request rate
- 1000 write per sec, 5000 read per secを超える場合には、20分にリクエスト2倍を上限にリクエストを増やしていく。
retention policy
retention policyとは?(以下GCPの説明ではないけど、一番わかりやすかったので引用)
- objectごとに指定される。
- objectにretention policyが貼っつけられている場合、そのリソースを削除、変更することはできない。このpolicyをlockすることで、保持期間の削除、短縮化ができないようにできる。
- bucketは、その中の全てのobjectがretention periodを超えるまで削除できない。
GCSのリソースのエンドポイントのCORS有効化
[cross origin request sharingを許可するオリジンを指定したjsonファイル]を手元に用意し、$ gsutil cors set xxx.jsonを実行すればよい。
s3のエンドポイントを叩いたリクエストのレスポンスのheaderには、Access-Control-Allow-Originとして、リクエストしたページのオリジンのホスト名がちゃんと指定されると考えていいのだろう(?)
GCSのアクセスコントロール(granting permission)
- uniform bucket-level accessが理想。
- これを使用すると、domain restricted sharingや、IAM conditionsを使用することができるようになる。
転送時の data validation
(validationは必須ではない)
-
アップロード時には、クライアントサイドで計算したCRC32c hash か MD5 hashをアップロードのリクエストに含める。Cloud Storageは、このハッシュ値と受け取ったオブジェクトから計算したハッシュ値が一致する場合のみ、そのオブジェクトを作成する。
-
ダウンロード時には、レスポンスに含まれているrepoted hashと、受け取ったオブジェクトから計算されたハッシュ値を比較してオブジェクトのデータが損失なく受け取れたかを確認できる。
(注意) MD5 hashは、entire objectから一つの値が算出されるので、composite objectの転送時には使用できない。
ハッシュ値の計算方法
以下の方法が存在する。
-
gsutil hashコマンド`を使い、ローカルのファイルのhash値を計算することができる。 - CRC32c hashの計算は、Boost(C++), crcmod(Python), digest-crc(Ruby)などを使用することでできる。
まとめ


データの保存ロケーション
|cloud storage | datastore | bigtable | cloud sql| spanner |
|---|---|---|---|---|---|
|regional/multi-regional|regional/multi-regional|zonal|regional|global|
ここら辺のDB比較は, https://cloud-ace.jp/column/detail95/ がわかりやすそう。
メモ
transient errorとlong lasting errorの対応の設計パターン
- Transient Errors → Exponential Backoffで対応
- Service Availability Errors → Circuit Breaker Patternで対応
リージョンの選び方
データベースのロケーションは、費用と可用性に影響します。書き込みレイテンシと費用を抑える場合はリージョン ロケーションを選択し、コストは上昇しても可用性を高める場合はマルチリージョン ロケーションを選択します。