はじめに
私は、エンタープライズ向けの会計システムの操作マニュアルを元にしたチャットボットを開発しています。RAGベースでチャットボットを開発しているのですが、精度向上に限界を感じていました。このチャットボットの精度向上の施策として、Fine-tuning を選択し、トライしてみたのですが、失敗に終わりました。この経験を共有したいと思います。
Fine-tuningに挑戦しようと思った背景
既存のチャットボットの仕組み
既存のシステムは、Webマニュアルのコンテンツをデータベースで管理していました。このマニュアルコンテンツを活用してチャットボットを実現するため、コンテンツDBからベクトルデータベースを構築し、RAG(Retrieval-Augmented Generation)アーキテクチャを採用しました。ユーザーからの質問に対して、ベクトルDBから関連するマニュアル情報を検索し、それをLLMに渡すことで回答を生成する仕組みです。

課題1:複数の機能をまたぐ質問の対応
複数の機能が密接に関連しているシステムの操作マニュアルでは、正確な回答を生成するためにシステム全体の知識を網羅的に把握することが不可欠です。
推論の難しさ:A=B、B=CからA=Cを導く必要がある
この問題を抽象化すると、以下のような構造になります:
- コンテンツ1: A=Bである
- コンテンツ2: B=Cである
RAGで「A=Cである」という回答を得るためには、コンテンツ1とコンテンツ2が同時にLLM側に渡される必要があります。しかし、これはユーザーのクエリと検索精度に依存するため、必ずしも両方のコンテンツが取得できるとは限りません。
具体例:会計システムの操作マニュアル
会計システムの操作マニュアルでは、このような推論が必要なケースが頻繁に発生します。
例えば、「仕訳入力で使用した勘定科目は損益計算書に表示されるか?」という質問に答えるには:
- マニュアルページ1(仕訳入力の手順):仕訳入力では「売上高」勘定科目を使用する
- マニュアルページ2(勘定科目の説明):「売上高」勘定科目は「損益計算書」に表示される
この2つのページの情報を同時に参照して推論する必要があります。しかし、RAGではユーザーのクエリと検索精度に依存するため、必ずしも両方のページが取得できるとは限りません。
このような推論が必要なケースでは、RAGの限界を感じざるを得ませんでした。
課題2:会話が続いた場合の RAG の検索が難しい
ユーザーとチャットボットの会話が続いた場合、過去の会話履歴を踏まえた文脈を理解した上で、適切な情報をRAGから検索する必要があります。しかし、会話の文脈をベクトル検索のクエリに適切に反映させることは容易ではありません。会話履歴を単純にクエリに追加しても、検索精度が低下する可能性があり、また会話が長くなるほど検索対象となる情報が曖昧になっていきます。このようなマルチターン会話における文脈の維持と検索精度の両立は、RAGアーキテクチャの大きな課題の一つです。
Fine-tuningなら解決できるのではないかという期待
Fine-tuningは一般的に「最終手段」と位置づけられることが多いですが、RAGの限界を感じていた私にとって、期待値的にはFine-tuningが良いのではないかと考えていました。
Fine-tuningなら、特定のドメイン(会計システムなど)に特化したモデルを作成できる可能性があります。RAGのContext取得精度のボトルネックを回避できる可能性も期待できます。
Fine-tuning を実現できると思った背景
Fine-tuningを実現するには、大量の教師データ(入力-出力のペア)が必要です。
RAGに使用している Webマニュアルのコンテンツデータを元に、生成AIを使って教師データを作れば、Fine-tuning に十分な教師データを生成できると考えました。
Fine-tuning トライアル
Azure OpenAI の Azure AI Foundryを使ったFine-tuningの検証をしました。
教師データの作成
既存のマニュアルコンテンツを章ごとに分割し、その章の範囲内で DeepSeek-V3 に教師データとなる Q&A データを作成させました。
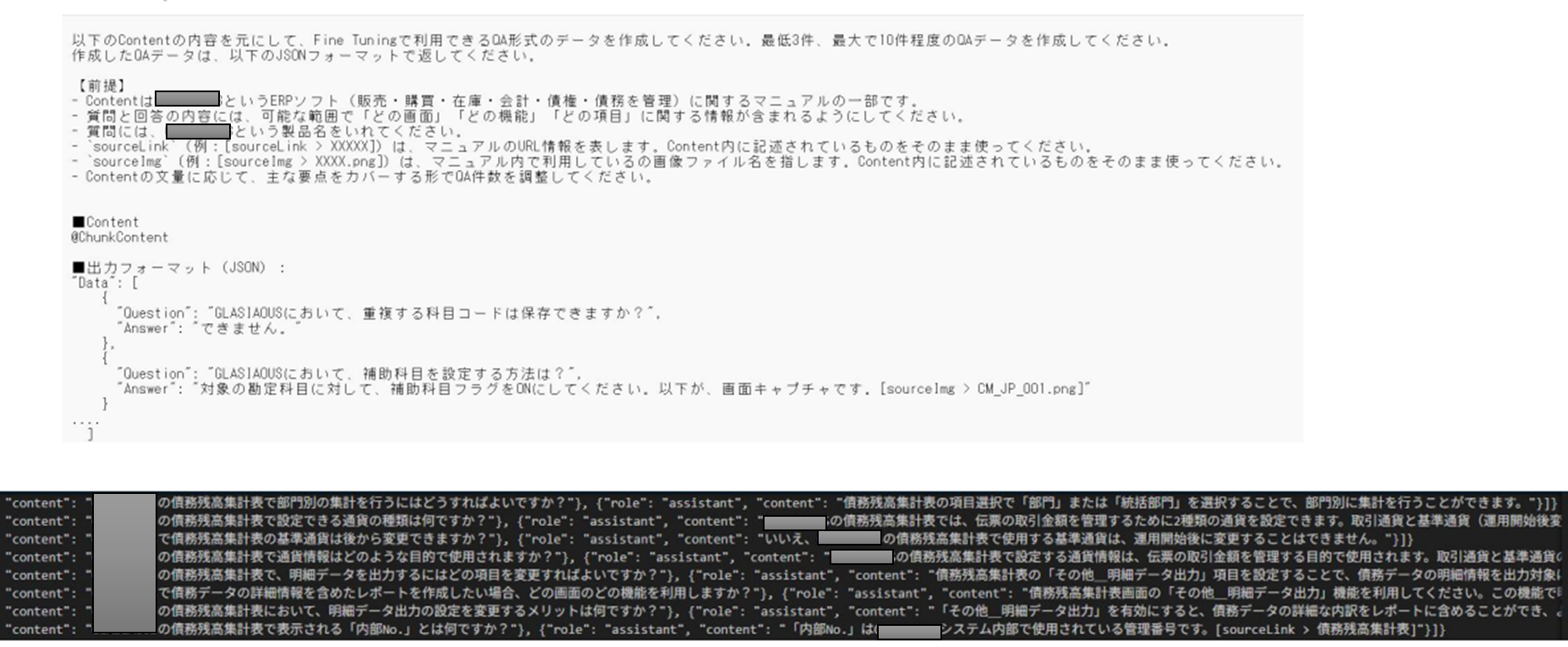
なお、教師データは 8.6万件ほど作成し、かかった費用は、約1万円でした。
Fine-tuningの実行
GPT-4.1とGPT-4.1 miniを基本モデルとしてFine-tuningを実施しました。
実行時間は数時間、コストはGPT-4.1で約4万円、GPT-4.1 miniで約1万円弱でした。なお、微調整したモデルをホスティングすると1日約6,000円の固定コストがかかります(Tokenの消費量とは無関係)。
結果(良かった点)
- 用意した教師データとほぼ同じ質問には正確に回答していた
- レスポンスが非常に速い(1秒未満)
- チャットボット実装する場合、RAGを使用する場合は、RAGの検索処理において、以前の会話の履歴を加味した検索するなどの対応が必要だが、それが不要になる(会話の履歴を渡せば良いだけになる)ため実装が楽になる
結果(課題):ハルシネーションが大量発生
Fine-tuning済みモデルと純粋なGPTに対して、同じ質問をしてみました。
未Fine-tuningモデルの回答例(明らかな不正確):
質問:【担当している製品名】って何ですか?
回答:【担当している製品名】は、日本のスマートフォンゲーム『白猫プロジェクト』に登場するキャラクターの一人です。
Fine-tuning済みモデルの回答例(部分的に正確、部分的に不正確):
質問:【担当している製品名】って何ですか?
回答:【担当している製品名】は、エンタープライズ向けの業務管理ソフトウェアです。販売、購買、在庫、会計、人事などの業務を統合的に管理できます。
良い点として、Fine-tuning済みモデルでは、学習した内容をもとに回答してくれるようになりました。しかし、悪い点として、「人事」の機能は存在しないにもかかわらず、ハルシネーション(幻覚)を起こして回答に含めてしまいました。
他の質問に対しても大量のハルシネーションが発生し、既存のFine-tuningなしのLLMモデル+RAGの方が回答精度が良かったという結果になりました。
この検証を通じて、推論でハルシネーションが出ないようにする難しさを体感できました。Fine-tuningによってモデルが学習した内容に基づいて回答するようになる一方で、推論が必要な複雑な質問に対しては、正確性を保ちながら適切な回答を生成することが非常に困難であることがわかりました。
原因の考察:良質なデータが足りなかった
MITのDeep learningの動画を見て、良質なデータが足りないことが判明しました。
良質なデータには以下の3つの要件が必要です:
- 多様性 (Diversity):幅広いトピック・表現形式・ドメインを含むデータを用意すること。モデルが様々な状況や文脈に対応できるようになる。
- 正確性 (Accuracy):データが事実に基づき、誤りや誤解を含まないこと。不正確なデータで訓練すると、モデルが誤った情報を生成するリスクが高まり、信頼性が損なわれる。
- 複雑性 (Complexity):多層的で高度な情報や推論を必要とするデータを含めること。モデルが高度な推論や専門的なタスクに対応できるようになる。
一方で私は 8.6万件の教師データを作成しましたが、以下の問題がありました:
-
多様性 (Diversity) の不足:
- Webマニュアルから教師データを作成したため、表現形式が画一的でした。
- Webマニュアルの章単位に教師データを作ったため、複数の機能にまたがるトピックの教師データが少なかったです。
- 「できないこと」を明示する教師データがありませんでした(作るのが困難)。
-
正確性 (Accuracy) の不足:
- LLMで大量に教師データを作成したため、教師データの精査ができていませんでした。不正確なデータが含まれている可能性がありました。
-
複雑性 (Complexity) の不足:
- Webマニュアルの章単位に教師データを作ったため、複数の章にまたがるような推論が必要な教師データが少なかったです。
具体例:
複雑性の低い教師データ(実際に作成したもの):
- Q: 「重複する科目コードは保存できますか?」
- A: 「できません。」
複雑性の高い教師データ(必要だったもの):
- Q: 「会計年度末に在庫評価を実施する際、複数の倉庫に分散している在庫の評価方法と、評価損の計上タイミングは?」
- A: 「各倉庫の在庫を個別に評価し、評価損は会計年度末の決算処理時に一括計上します。ただし、期中に異常な価格変動があった場合は、その時点で中間評価を行う必要があります。評価方法は、[画面名]の[機能名]から設定できます。詳細は[sourceLink > XXXXX]を参照してください。」
このような良質なデータを十分に用意できなかったことが、ハルシネーションの原因だと考えました。
まとめ(学び)
Fine-tuning の良かった点:
- 用意した教師データとほぼ同じ質問には正確に回答していた
- レスポンスが非常に速い(1秒未満)
- チャットボット実装する場合、RAGを使用する場合は、RAGの検索処理において、以前の会話の履歴を加味した検索するなどの対応が必要だが、それが不要になる(会話の履歴を渡せば良いだけになる)ため実装が楽になる
Fine-tuning の課題:
- コスト増が多い(教師データ作成:約1万円、Fine-tuning実行:約4万円/約1万円弱、ホスティング:1日約6,000円)
- ハルシネーションを防ぐための教師データの用意が大変。
- 教師データが用意できても明確に成功する保証がない。→投資対効果の期待値が低い
Fine-tuning に必要な教師データ:
単に「データの量」だけでなく、「データの質」が重要です。良質なデータには以下の3つの要件が必要です:
- 多様性 (Diversity):幅広いトピック・表現形式・ドメインを含むデータ
- 正確性 (Accuracy):事実に基づき、誤りや誤解を含まないデータ
- 複雑性 (Complexity):多層的で高度な情報や推論を必要とするデータ
「マニュアルから生成する」というアプローチだと上記の性質をみたす教師データを作成するのは、難易度が高いです。
おそらく、お客様から寄せられた大量の製品サポートQ&A のデータをもとに 教師データとして使えたら 回答精度の高い Fine-tuning ができるかもしれないと思いました。