0. はじめに
自作のDBからPythonで高速にデータを抽出する方法で彷徨ってましたが、現時点でかなり早いライブラリを見つけたので紹介しておきます。
- 動作環境
- OS : Windows10 pro
- Python : 3.10
- connectorx : 0.3.1
1. ConnectorXとは?
公式によると以下のようなライブラリらしいです。
ConnectorX は Rust で書かれており、最も高速でメモリ効率の良い方法でデータベースからPythonにデータをロードできます。これは一般的なデータベースコネクタへの高レベルインタフェースを提供するPythonパッケージです
Rustはよく高速化関連でも聞きますが、これにも使われてるみたいですね。
2. 自作DBデータで比較してみた
2-0.データに関して
Sqliteに格納している株価データで、shapeは(12529820, 35)となっています。(1250万行、35カラム)

2-1.従来の方法(read_sql_query)
ごちゃごちゃ書いているが、様子するにchunksizeを指定してメモリに乗り切らないような大容量データを用いるときに一回に読み込む量を指定する方法である(以下は以前書いた記事)
read_sql_query
import psutil
import pandas as pd
import sqlite3
import time
# 実行時間を計測開始
start_time = time.time()
dbname = "sample.db"
conn = sqlite3.connect(dbname)
# chunksizeを計算する
# 利用可能なメモリの量を取得
available_memory = psutil.virtual_memory().available
# データベースから1行分のデータを読み出し、そのサイズを取得
df_sample = pd.read_sql_query("SELECT * FROM price LIMIT 1", conn)
row_size = df_sample.memory_usage(deep=True).sum()
# 利用可能なメモリの量に基づいてchunksizeを計算(最大の25%とした)
chunksize_max = int(available_memory * 0.25 // row_size)
print(f"利用可能なメモリは{available_memory}")
print(f"設定するchunksizeは{chunksize_max}")
# dbをread_sqlを使用してpandasとして読み出す。
dfs = []
for chunk in pd.read_sql_query('SELECT * FROM price', con=conn, chunksize=chunksize_max):
dfs.append(chunk)
df = pd.concat(dfs)
# 実行時間を計測終了
end_time = time.time()
print(f"かかった時間は {end_time - start_time} 秒です")
結果506秒(約8.5分)かかっていた
(以下が実行スクショ)

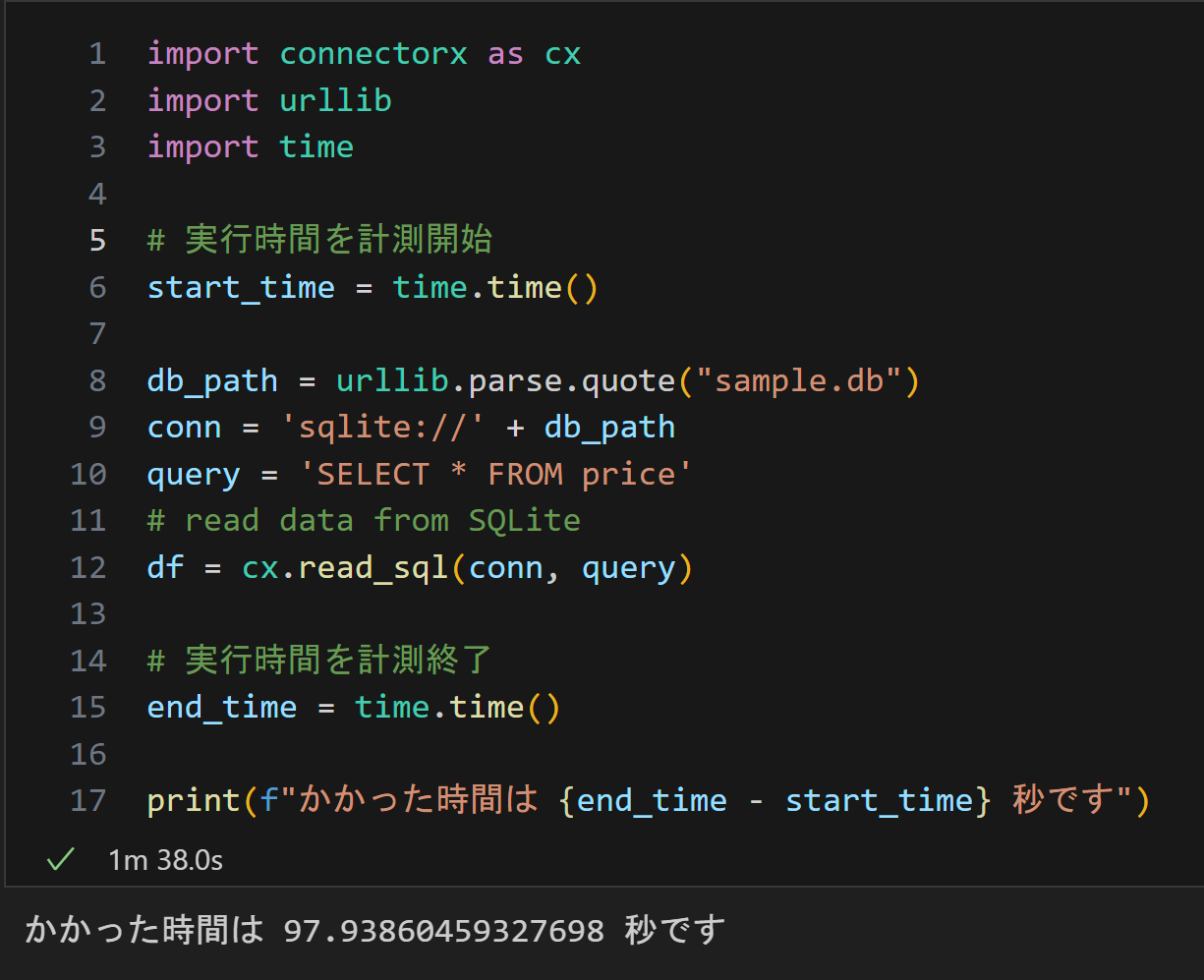
2-2.早い方法(ConnectorX)
今回紹介するライブラリを使用した結果を記します。
ConnectorX
import connectorx as cx
import urllib
import time
# 実行時間を計測開始
start_time = time.time()
db_path = urllib.parse.quote("sample.db")
conn = 'sqlite://' + db_path
query = 'SELECT * FROM price'
# read data from SQLite
df = cx.read_sql(conn, query)
# 実行時間を計測終了
end_time = time.time()
print(f"かかった時間は {end_time - start_time} 秒です")
結果は97秒(約1.5分)となっており、比較するとかなり早いことがわかる
(以下が実行スクショ)
3. おわりに
今回比較した結果だと約5倍読み込み速度が上がったことになります。無茶苦茶早くないですか?(さすがRUST!)
SQlite以外のDBでもかなり早いらしいので、色々試してみてみてはいかがでしょうか?
それでは今回はここまで。