はじめまして。
私は今年からpythonを実際に書けるように勉強し、とっつき易さからDeepLearningのフレームワークとしてKerasを使用してきました。
今後はPyTorchを勉強していこうと思ってますが、その前に碌なプログラム経験も無いままプロジェクト内で四苦八苦して覚えてきたKeras(python)画像系知見を共有できればと思い初投稿に至りました。
自分も調べた時に、(基礎知識がなさ過ぎてこのQiitaはじめ解説サイトに書かれている意味が読み取れずに)結果色んなサイト巡り巡って大変だったので
(MNISTとかはもういいんだよ。。自分のデータセットなんだよ・・・って心情)
後で見返す自分への記録用も兼ねてまとめておきます。
第1回目の今回は画像の取り込み方の基礎と、自前データセットをどう作ればいいか?をまとめていきます。
いつかどこの誰かも知らない初学者のお役に立てることを願って・・・
(他の同じような記事よりも日本語コメント多めにしたつもりです)
なお、Qiita初投稿なので体裁とかはお察しです。。。徐々に勉強しますのでご勘弁を。
その①(本記事)
画像の取り込み
自前データセットの作り方
その②(次回書く予定)
作ったデータセットをNNに入れてみよう
1.Keras専用の画像の読み込み手法Load_img
pythonでは、pillow(PIL)やOpenCVを使用して画像を取り込む手法もあるが、せっかくKerasの記事なのでここはload_imgに絞って解説をする。
ここではまず例としていらすとや君の画像(A.png)をプログラムデータ(.py)と同じ階層(ディレクトリ)に置いたときにどう取り込むか?を説明する。
# 画像を表示させるのに使用するmatplotlibとjupyterNotebookで画像を出力させるおまじない
import matplotlib.pyplot as plt
%matplotlib inline
# Kerasで簡単に画像を扱えるライブラリkeras.preprocessing.image
from keras.preprocessing.image import load_img
# そのまま(カラーで)読み込む(いらすとやの元画像サイズは(646,839)の3次元pngカラー画像)
# .pyと同じ階層に画像があるので、そのままA.pngで読み込める
img1 = load_img('A.png')
# グレースケール(1次元)で読み込む場合
img2 = load_img('A.png', grayscale=True)
# リサイズして読み込む場合
img_shape = (256, 256, 3) # 縦横256のカラー画像にリサイズしてみる
img3 = load_img('A.png', grayscale=False, target_size=img_shape)
次にmatplotlibを用いてそれぞれ画像を表示させてみましょう
plt.imshow(img1) #img1の個所にimg2,3を入れ替えて試してみる
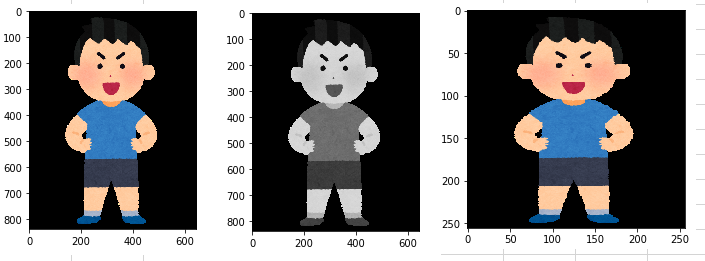
どうだろうか?きちんと表示できていることがわかると思う。
さて、一般的に画像をNN(ニューラルネット)にインプットする為には次の処理が必要になる
# リサイズして読み込む
img_shape = (256, 256, 3) # 縦横256のカラー画像
img = load_img('A.png', grayscale=False, target_size=img_shape)
# ニューラルネットワークに入れる為にnumpyのarray型に変換する
img_array = img_to_array(img)
# 255で割り算をして正規化する
img_array /= 255
# img_array = img_array / 255でもOK
これでNNにインプットする準備はできました。が、1枚だけ入力することなんてないですよね・・
ふつうは学習させるのは複数枚ですよね。。。
そこで今度は単体の画像ではなく、複数枚の画像を取り込むにはどうすればいいのでしょうか?
import numpy as np
import glob
from keras.preprocessing.image import load_img, img_to_array
# ディレクトリ(path)名称
dir_name = 'picture'
# 画像拡張子
file_type = 'png'
# glob.globで全画像のpath情報を取得する
# /*.pngで、pngの拡張子全てという意味
img_list_path = glob.glob('./' + dir_name + '/*.' + file_type )
# img_list_path = glob.glob('./picture./*.png' ) でも当然可
# 読み込んだ画像を格納する空のリストを作成
img_list = []
img_shape = (256, 256, 3)
# for文で1枚ずつpath情報を取り出して、それをload_imgで読み込んでいき、リストに格納していく
for img in img_list_path:
temp_img = load_img(img, grayscale=False, target_size=img_shape)#PIL形式で画像読み込み
temp_img_array = img_to_array(temp_img) / 255 #PIL⇒配列化 + 255で割って正規化
img_list.append(temp_img_array) #用意したリストに追加する
# 学習画像として、リストをさらに配列化して、(n, width, haight, ch)の形に変換
x_train = np.array(img_list)
試しにこのリストのshapeを確認し、試しとして0番目の画像を表示してみる
print(x_train.shape)
plt.imshow(x_train[0]) #リストの0番目(1枚目)の要素にアクセスして表示させてみる
ここでは表示させてないが、きちんと(n,256,256,3)の形と0番目の画像が確認できると思う。
これで入力画像の準備は完了となる。
また本来は、画像を読み込むだけではなく正解ラベルも同時に付与する必要がある。
これはやり方がいろいろあるのだが、img_list_pathの中の画像が全て同じ分類タグの場合は同じfor文の中で加えてやってもいい。
※学習分類毎にフォルダ分けしている場合は、img_list_path単位で同じ学習タグなはずなので
img_list = []
y = []
img_shape = (256, 256, 3)
for img in img_list_path:
temp_img = load_img(img, grayscale=False, target_size=img_shape)
temp_img_array = img_to_array(temp_img) / 255
img_list.append(temp_img_array)
y.append('いらすとや')#img_list_pathにある画像は全部いらすとやなので、分類タグを加える
# x_train とy_train は並び順的にペアになっている
x_train = np.array(img_list)
y_train = np.array(y)
2.メモリに乗りきらない大量画像を捌くImageDataGenerator
さて、上記で学習画像をリストとして格納したのでそれをそのまま学習に使おうとすると問題が生じてしまうケースがある。
それはとんでもなく大量の画像をリストとして保存するとPCのメモリがパンパンになってそもそも学習できないという問題である。
最初のお試しや少量の場合は上述のリストでやってもいいと思うが、実務では例えばサイズ(256,256,3)を1万枚とか学習。。とかも普通に実務では出てくると、PCがブーーーーンとか唸りだして困ったことになる(笑)
と、、こういう時に活躍するのが、KerasのImadeDataGeneratorである。
事前準備として、学習の分類別にフォルダを分けておく必要がある。
※画像はKaggleのデータセットから拝借しました。これをダウンロードして使えば同じことが試せます
https://github.com/Horea94/Fruit-Images-Dataset
フォルダ構造は以下の様にしていて、例として使用するプログラムはpictureフォルダと同じ階層で実行する。
trainは学習用。valは検証用の画像を入れることとする。
'''
picture -╷- train -╷- Apple(分類1) -╷- **.png #学習用
╎ ╎ ╎ (多数の画像・・省略)
╎ ╎ ╵- **.png
╎ ╵- Mango(分類2) - (略)
╎
╵- val -╷- Apple(分類1) - (略) #学習検証用
╵- Mango(分類2) - (略)
'''
さて、リンゴとマンゴーの画像を分類する為のデータセット作りを見てみましょう。
from keras.preprocessing.image import ImageDataGenerator
# 設定
classes = ['Apple', 'Mango']#リンゴとマンゴーを分類するように学習させたい場合
train_data_dir = './picture/train'#クラス分類の親フォルダを指定する(Apple,Mangoの上位フォルダ)
img_height = 100
img_width = 100
# バッチサイズ(一度にNNで学習させる枚数。2のn乗が多い)
batch_size = 16
# トレーニングデータを作成する
# 255で割ってスケーリングする
train_datagen = ImageDataGenerator(rescale = 1.0 / 255) #水増し等の設定もできるが、今回は省略する
# 学習のgeneratorを設定する。
# generatorとはざっくり言えば都度(ここではバッチサイズ毎に)画像を生成するということ
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size = (img_height, img_width), #次元は不要
color_mode = 'rgb', #グレーの場合、'grayscale'と入力
classes = classes,
class_mode = 'binary', #2つなのでbinary。3つ以上の場合は、'categorical'
batch_size = batch_size,
shuffle = True)
学習用データセットの作成はこれで完了です。さっきのリストのやつよりこっちのが簡単??
これでバッチ毎に画像を読み込むので、メモリがパンクせずにすみます。
ただ、本当にこんなので画像が読めてるのか心配な場合は一度generatorの中身の画像を出力させてみましょう
# 表示用に取り出すバッチサイズを1にする
batch_size_show = 1
# 表示用に先程とは別のgeneratorを用意
train_generator_show = train_datagen.flow_from_directory(
train_data_dir,
target_size = (img_height, img_width), #次元は不要
color_mode = 'rgb', #グレーの場合、'grayscale'と入力
classes = classes,
class_mode = 'binary', #2つなのでbinary。3つ以上の場合は、'categorical'
batch_size = batch_size_show,
shuffle = True)
# 表示用として画像とラベルを格納するリストを用意
imgs = []
labbels = []
# 100は表示させたい枚数を適当に指定。全画像枚数に設定してもいい
for i in range(100):
x,y = train_generator_show.next() #next()でgeneratorの要素を順番に取り出す
imgs.append(x[0])
labbels.append(y)
次に画像とラベルを実際に表示させてみる
# generatorクラスのクラス分類確認
print(train_generator_show.class_indices)
# 表示設定
fig = plt.figure(figsize=(12,12))
fig.subplots_adjust(hspace=0.5, wspace=0.5)
row = 10
col = 10
for i, img in enumerate(imgs):#インデックス番号, 要素をenumerateで取得できる
plot_num = i+1
plt.subplot(row, col, plot_num,xticks=[], yticks=[])
plt.imshow(img)
plt.title('%d' % labbels[i])
plt.show():

これで何となく画像と分類タグが正しそうなことがわかって学習データの設定ができてそうなので、
後は同じようにValidationのデータセットを用意するなりして学習の準備を整えておく。
(同じようにvalフォルダに対してアプローチする)
# val設定
classes = ['Apple', 'Mango']
val_data_dir = './picture/val'
img_height = 100
img_width = 100
batch_size = 16
# バリデーションデータを作成する
val_datagen = ImageDataGenerator(rescale = 1.0 / 255)
# バリデーションのgeneratorを設定する。
val_generator = val_datagen.flow_from_directory(
val_data_dir,
target_size = (img_height, img_width),
color_mode = 'rgb',
classes = classes,
class_mode = 'binary',
batch_size = batch_size,
shuffle = True)
今回はいったんここで終わり。
後で追記するかもですが