本記事では,Amazon SageMakerを用いて機械学習モデルの学習・デプロイを行うための必要最低限の知識を説明します.普段,仕事や学業で機械学習プロジェクトに携わっているけどAWSにあまり馴染みのないという方のお役に立てば幸いです.
また本記事は,AWSの3daysインターンシップで取り組んだことを題材に,インターンシップでチームを組んだ中田勇介さん(nakata_yusuke)と一緒に作成しました.コードはgithub上で公開しています.
Amazon SageMakerとは
Amazon SageMakerとは,機械学習モデルを高速に開発・学習・デプロイするためのマネージドサービスです.よく利用されるEC2は,主にインフラ(やフレームワーク等)を提供するためのサービスなので,EC2の1つ上のレイヤのサービスとなります.
Amazon SageMakerを利用することで,以下のような作業を簡単に行うことができます.
- 開発・学習環境の用意や環境構築
- 実験結果の管理
- 推論用のAPIサーバー構築やデプロイ
より詳細な説明は他に譲ることにして,以下ではAmazon SageMaker上でのモデルの学習・デプロイの仕方を説明していきます.(参考)
今回行うタスク
本記事で取り組むタスクは,レビュー・概念に基づく商品検索システムの構築です.インターンシップでは,Amazon Customer Review Datasetを使って自由にタスクを設定してよかったので,「利用者の意見を参考にしたい」「よりフワッとした商品検索をしたい」という検索システムの課題を想定し,このようなタスクを設定しました.
この検索システムでは,クエリに近い意味を持つレビューを探し出し,そのレビューに対応する商品を返します.レビューをもとに検索を行うことで利用者の意見をもとにした検索が,文の意味(分散表現)を用いることでより柔軟な検索が可能になると考えました.検索システムのイメージを下図に示します.

検索システムの構築は,以下の流れで行います.
- 学習
- レビューデータの前処理・文の分割を行う
- 学習済みのSentence-BERT(Nils and Iryna, EMNLP 2019)で文をベクトル化する
- ベクトルに関して,推論時の近傍探索を高速化するためにk-NNグラフを構築する
- 推論
- クエリ文を同様にベクトル化する
- 近傍探索を行い,クエリ文に意味が近いレビュー文を返す
- 後処理として,そのレビュー文に対応する商品のメタデータを取得する
処理の流れ全体のイメージを下図に示します.
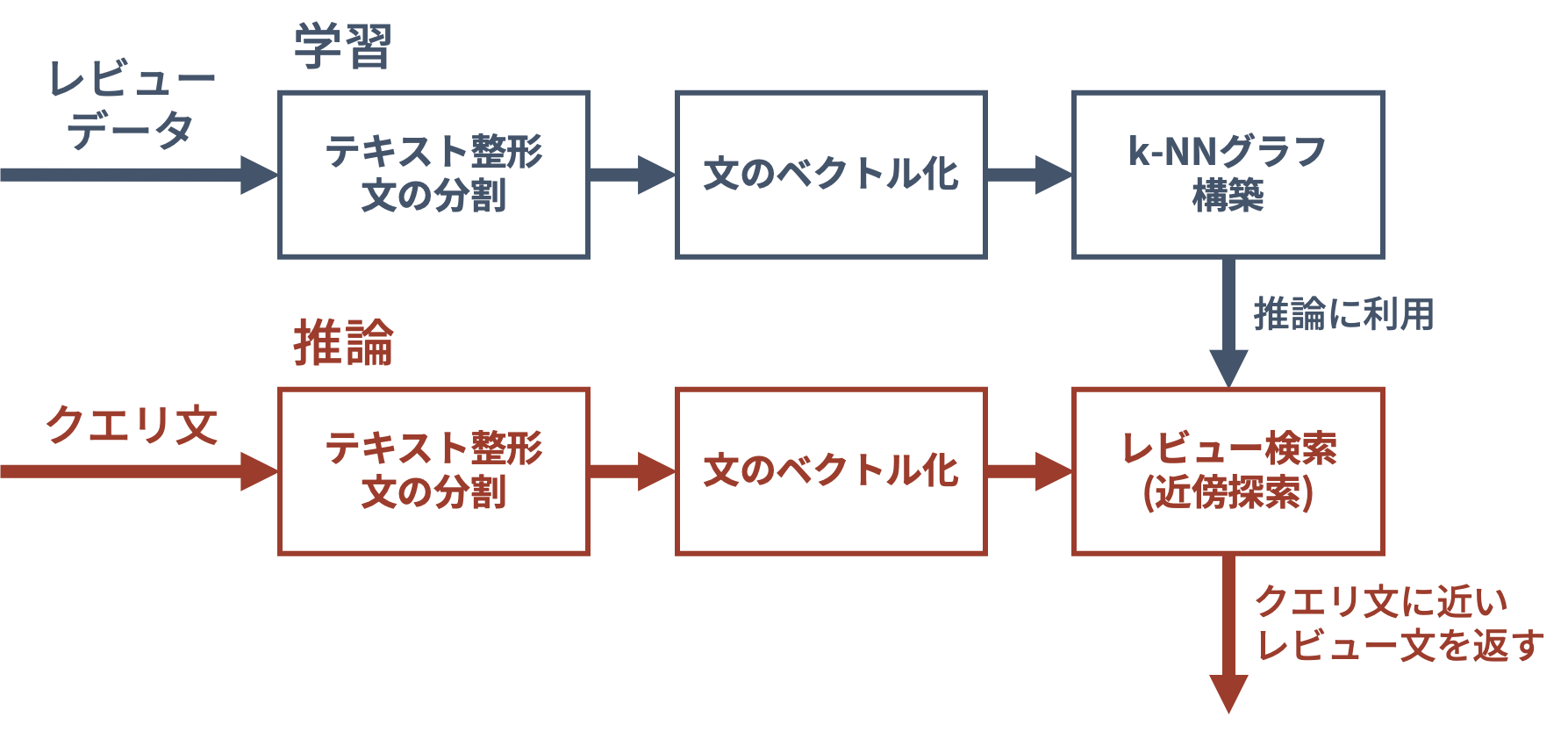
以下では,簡単のため,Amazon Customer Review DatasetのうちToyカテゴリ,1万件のレビューのみを用いました.
Amazon SageMakerでの学習・デプロイ
ここでは,Amazon SageMaker上で機械学習モデルの学習・デプロイを行う方法を説明します.
Amazon SageMakerでは,環境構築や学習・推論の実行にDockerコンテナを利用します.本記事では,Amazon SageMakerが提供するデフォルトのコンテナ(参考)を扱い,独自のコンテナを利用する方法については触れません.
以下では,AWSアカウントを持っていることを前提とし,
- IAMロールの作成
- データセットの準備
- 学習
- デプロイ & 推論
の順に説明をしていきます.
また,ノートブックに実際のコードを載せていますので,参照してみてください.
IAMロールの作成
Jupyter Notebook上からAmazon SageMakerを扱うためには,AmazonSageMakerFullAccessを持ったIAMロールを作成する必要があります.これには,Amazon SageMakerが提供するノートブックインスタンスを利用する方法と,ローカルのJupyter Notebookを利用する方法の2つがあります.
ノートブックインスタンスを利用する

AWSマネジメントコンソールから,Amazon SageMakerのサービスページに飛び,左側のノートブックインスタンスを選択します(上図).ノートブックインスタンスの作成を選択し,インスタンスタイプ・IAMロールを適切した上でノートブックインスタンスを作成します(作成には数分かかります).
デフォルトのIAMロールは,SageMakerが指定するS3バケットにアクセス可能で,難しいことを考えずにデータセットを置くことができます(おすすめ).IAMロール選択時に新しいロールの作成を選び,利用したいS3バケットへのアクセス権を与えることもできます.
ノートブックインスタンス上で下記を実行することで,ノートブックインスタンスに紐づけられたIAMロールを取得することができます.
from sagemaker import get_execution_role
role = get_execution_role()
ローカルのJupyter Notebookを利用する
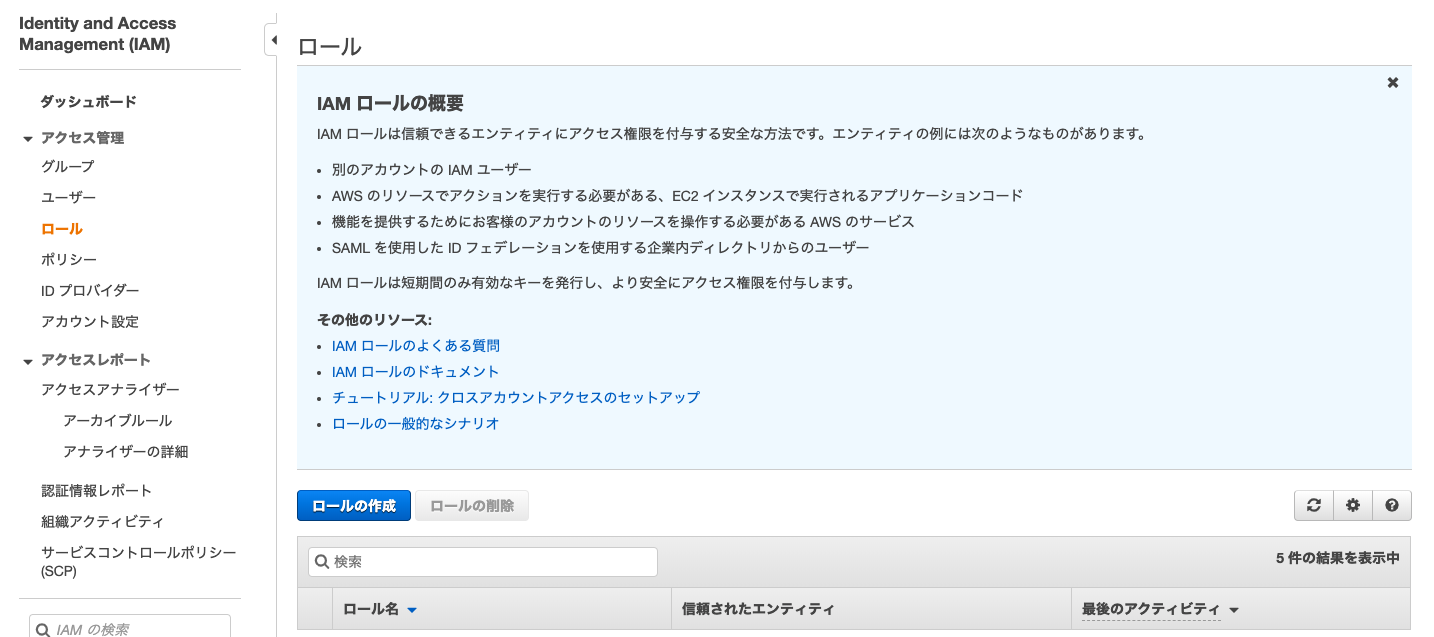
ローカルでJupyter Notebookを利用する場合,AWSマネージメントコンソール上でAmazonSageMakerFullAccessを許可したIAMロールを作成する必要があります.IAMのサービスページからロールの作成を選択し,サービスを選択する画面でSageMakerを選択すれば,必要なIAMロールを作成することができます.
IAMロールを作成後は,自分のAWS IDと作成したロール名を用いて下記を実行することで,作成したIAMロールを取得することができます.
role = 'arn:aws:iam::[12桁のAWS ID]:role/[ロール名]'
データセットの準備
学習に利用するデータセットを準備する最も簡単な方法は,データをS3にアップロードすることです.ノートブックインスタンスを利用している場合には,下記の例のように,SageMakerが指定するS3バケットに簡単にアップロードすることができます.S3では,パスではなくキーによってファイルを管理するため,本来は階層構造が存在しません.キーに/を含めることで,階層構造を持つように管理することも可能です.
import sagemaker
sess = sagemaker.Session()
s3_dataset_path = sess.upload_data(
path='./dataset', # ディレクトリまたはファイルのパス
key_prefix='data/train' # S3でのキー
)
ローカルの場合には,boto3を用いてアップロードすることができます.ただし,S3を扱える適切なIAMロールを発行しておくことが必要です(参考).
学習
SageMakerの学習・推論は,それぞれ学習・推論用のインスタンス上でコンテナを走らせることで行われます.今回はデフォルトで提供されているPyTorchコンテナを利用しますが,TensorFlowやKerasでも同様の手順で学習・デプロイを行うことが可能です.
以下では,データセット(S3にアップロード済み),自作モジュール(searchモジュール),その他学習に必要なファイル(modules.pickle)を利用して,モデル(Sentence-BERTとkNNグラフ)を学習することを想定します.
Estimatorの作成
学習・デプロイ(推論)を行うためには,まずEstimatorインスタンスを作成します.Estimatorには,学習・推論時の環境構築や処理内容などの情報をが含まれており,下記のように作成します.
from sagemaker.pytorch import PyTorch
# Create estimator.
estimator = PyTorch(
entry_point='entry_point.py', # 学習・推論処理を記述したスクリプト(`source_dir`以下に配置しておく)
source_dir='source_dir', # 学習用インスタンスにコピーしたいファイルを配置しておく
dependencies=['search'], # 独自モジュールのリストを指定
role=role, # 作成したIAMロールを指定
framework_version='1.3.1', # torch>=1.3.1を推奨
train_instance_count=1,
train_instance_type='ml.m4.xlarge')
この例では,以下の構成のファイルを利用しています.
.
├── search # kNNグラフ用のモジュール
│ ├── __init__.py
│ └── ...
├── source_dir
│ ├── modules.pickle # 学習時にはコピーされる.推論時にはコピーされない.
│ ├── requirements.txt # 依存ライブラリ
│ └── entry_point.py # 学習・推論処理を記述したスクリプト
...
source_dir以下には,学習用のEC2インスタンスにコピーして欲しいファイル(modules.pickle)に加えて,学習・デプロイ時の依存ライブラリを記したrequirements.txt,学習・推論処理を記述したコードentry_point.pyを置きます.source_dir以下のファイルは,学習時にはカレントディレクトリ以下にコピーされます.ただし,推論用インスタンスにはコピーされないので注意が必要です.また,自作モジュールはdependenciesにリスト形式で指定します.
学習を行うためには,学習コードと推論のための4つの関数を記述したentry_point.pyを作成する必要があります.以下では,entry_point.pyの中身について詳しく説明していきます.また,ここに実際の例を載せておきます.
学習コード
学習では,entry_point.pyのmain部分を実行し, os.environ['SM_MODEL_DIR']以下に学習済みモデルや推論時に必要なファイル全てを保存します.そうすることで,推論時に保存したモデルを利用することができます.学習用のデータセットは,os.environ['SM_CHANNEL_TRAIN']におくことにします(後述).
下記の例では,Sentence-BERTのネットワーク構造と重みを保存したファイルmodules.pickleをそのままコピーし,近傍探索するためのインスタンスproduct_searchを保存しています.本来はSentence-BERTを学習させたりするのですが,簡単のため学習済みモデルをそのままコピーしています.モデルを学習させる処理は,main部分で実行されるように記述する必要があります.
# You can train Sentence-BERT or kNN graph here.
def train(args):
# Copy the pretrained Sentence-BERT model.
subprocess.call([
'cp', 'modules.pickle',
os.path.join(args.model_dir, 'modules.pickle')])
# Load datasets.
reviews = pd.read_csv(os.path.join(args.train, '10000_review.csv'))
sentences = pd.read_csv(os.path.join(args.train, '10000_sentence.csv'))
embeddings = np.load(os.path.join(args.train, '10000_embedding.npy'))
# Construct and train search engine.
product_search = ProductSearch(reviews, sentences, embeddings)
product_search.save(
os.path.join(args.model_dir, 'product_search.pickle'))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--model-dir', type=str, default=os.environ['SM_MODEL_DIR'])
parser.add_argument('--train', type=str, default=os.environ['SM_CHANNEL_TRAIN'])
parser.add_argument('--current-host', type=str, default=os.environ['SM_CURRENT_HOST'])
parser.add_argument('--hosts', type=list, default=json.loads(os.environ['SM_HOSTS']))
train(parser.parse_args())
model_fn 関数
この関数は学習したモデルを読み込む関数で,model_dirを引数として受け取り,学習済みのモデルを返します.この関数の返り値はどのような形式でもよく,この返り値がそのままpredict_fnの引数(model)となります.
下記の例では,Sentence-BERTとProductSearchのインスタンスを辞書形式で返しています.
def model_fn(model_dir):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Load the trained Sentence-BERT.
with open(os.path.join(model_dir, 'modules.pickle'),'rb') as f:
modules = pickle.load(f)
vectorizer = SentenceTransformer(modules=modules).eval().to(device)
# Load the trained search engine.
product_search = ProductSearch(
index_path=os.path.join(model_dir, 'product_search.pickle'))
return {
'vectorizer': vectorizer,
'product_search': product_search
}
input_fn 関数
この関数はクライアントからのリクエストを前処理する関数で,引数はinput_dataとcontent_typeの2つです.
リクエストの形式は引数content_typeで与えられ,NPY形式(application/x-npy),JSON形式(application/json),CSV形式(text/csv)のみ利用可能です.この関数の返り値はどのような形式でもよく,この返り値がそのままpredict_fnの引数(data)となります.
下記の例では,JSON形式のみ受けつけ,JSONオブジェクトを読み込み,convert_text_into_sentencesで前処理を行った上で返しています.
def input_fn(input_data, content_type):
assert content_type == 'application/json'
request = json.loads(input_data)
return {
'query': convert_text_into_sentences(request['query']),
'n_items': request['n_items']
}
predict_fn 関数
この関数は推論を行う関数です.引数はdataとmodelの2つで,それぞれinput_fnとmodel_fnの返り値が入っています.ここで,リクエストに関する推論を行い,推論結果を返します.この関数の返り値はどのような形式でもよく,この返り値がそのままoutput_fnの引数(prediction)となります.
下記の例では,Sentence-BERTによるベクトル化,kNNグラフによる近傍探索を行い,結果を辞書形式にして返しています.
def predict_fn(data, model):
sentences, n_items = data['query'], data['n_items']
vectorizer, product_search = model['vectorizer'], model['product_search']
# Vectorize.
with torch.no_grad():
embeddings = np.array(vectorizer.encode(sentences), dtype=np.float32)
# Search.
prediction = product_search.search(embeddings, n_items=n_items)
# Convert list into dict.
prediction = {f'pred{str(i)}': pred for i, pred in enumerate(prediction)}
return prediction
output_fn 関数
この関数は推論結果を後処理し,レスポンスを返す関数です.引数はpredictionとacceptの2つで,predictionにはpredict_fnの返り値が入っています.ここで,推論結果を指定された形式のオブジェクトに永続化して返します.レスポンスの形式はinput_fnと同様の3つの形式のみ可能で,引数acceptで与えられます.
下記の例では,辞書をJSONオブジェクトに変換しています.
def output_fn(prediction, accept):
return json.dumps(prediction), accept
学習の実行
entry_point.pyを作成できたら,Estimatorのfitメソッドを呼び出すことで学習を行うことができます.fitメソッドの引数には,学習用データセットを辞書形式で指定します.
ここでは,trainキーにデータセットを指定しているので,'SM_CHANNEL_TRAIN'という環境変数にデータセットのパスが格納されます.検証用データセットを用意したい場合は,evalキーにS3のURLを指定することで,'SM_CHANNEL_EVAL'という環境変数に検証用データセットのパスが格納されます.
# Train.
estimator.fit({'train': '[s3://から始まるデータセットのURL]'})
デプロイ & 推論
下記で学習したモデルをデプロイすることができます.これには時間がかかります(10-15分程度).
# Deploy the trained model.
predictor = estimator.deploy(
endpoint_name='[エンドポイントの名前]'
initial_instance_count=1,
instance_type='ml.m4.xlarge')
推論エンドポイントをデプロイしたら,APIを通じて推論リクエストを送ることができます.下記の例では,リクエストはBodyにJSON形式で指定しています.
import boto3
client = boto3.client('sagemaker-runtime')
# Query and number of results.
request = {
'query': 'My children liked it',
'n_items': 1
}
# Request.
response = client.invoke_endpoint(
EndpointName=[エンドポイントの名前],
ContentType='application/json',
Accept='application/json',
Body=json.dumps(request)
)
例えば,今回デプロイしたモデルでは,以下のようなレスポンスがJSON形式で返ってきます.
review_id: R2XKMLHEG7Z402
product_id: B00IGNWYGQ
product_title: Play-Doh Mix 'n Match Magical Designs Palace Set Featuring Disney Princess Aurora
star_rating: 4.0
review_headline: Inventive and fun, some parts hard to do
product_search_score: 0.9600517749786377
matched_sentence: my kids loved this.
review_body: My kids loved this. Lots of sparkly play doh and tons of molds. One star comes off because it's hard to get play do to press out of the skirt, and once you're done with that it's tough to get the skirt to come off the little pedestal.
推論エンドポイントは,起動している間ずっと課金され続けてしまうので,不要になった時には削除するようにしましょう.
predictor.delete_endpoint()
まとめ
今回はAmazon SageMakerでの学習・デプロイのチュートリアルを行いました.ログの管理や分散学習,独自コンテナによる柔軟な開発など,今回説明していない便利な機能が多々存在します.今後もこのようなチュートリアルや解説を積極的に発信していこうと思います.
最後まで読んでいただき,ありがとうございました.