この記事は,以下の論文の解説です.
Distributional Reinforcement Learning with Quantile Regression (AAAI 2018)
記事内容では,強化学習の基礎的な知識を前提としています.
また,記事中の図は全て論文からの引用です.
不備がございましたら,ご指摘頂けると幸いです.
また,この論文で提案する手法(QR-DQN)の再現実装をGithubで公開しています.アルゴリズムがわかりやすいように工夫して,コメントも詳しく書いていますので,理解の助けになればと思います.ぜひ参照してみてください.
概要
この論文は,「分位点回帰を用いることで,$\infty$-Wasserstein距離(の上界)の最小化に基づいた分布型強化学習の手法を提案した」論文になります.主にC51の論文の結果がベースになっているので,ご存知ない方は,まずC51の解説をご覧になることをお勧めします.
C51の論文では,分布ベルマンオペレータは,p-Wasserstein距離の上界( $\bar d_p$ )に関して縮小であることを示しました.しかし,確率的勾配法では,一般的に $\bar d_p$ を「損失関数として」最小化することはできないことも示されています.そのため,C51では $\bar d_p$ ではなくKLダイバージェンスの最小化を行なっており,理論と実装のギャップが存在していました.また,C51 では価値分布の上限・下限を,ハイパーパラメータとして設定する必要があるという課題も存在しました.
この論文では,この理論と実装のギャップを埋め,$\bar d_\infty$ の最小化に基づく学習アルゴリズムを提案していきます.
準備
以下では,通常のMDP $(\mathcal X, \mathcal A, R, P, \gamma)$ を考えます.$R$ は確率変数です.また,方策 $\pi$ に従ったときの収益を $Z^\pi = \sum_{t=0}^\infty \gamma^t R_t$ と表します.確率変数 $Z^\pi$ の従う確率分布を価値分布と呼びます.また,価値分布のことも単に $Z^{\pi}$ と表すことにします.
分布ベルマンオペレータ $\mathcal T^\pi$ は,以下の式で表されます.ただし,$=_D$ は両辺の確率変数が従う確率分布が等しいことを表します.
\mathcal T^\pi Z(x,a) =_D R(x,a) + \gamma Z(x', a')
同様に,最適分布ベルマンオペレータ $\mathcal T$ は,以下の式で表されます.これは,状態 $x$ で行動 $a$ を選択したあとは,$Z$ に基づく貪欲方策に従って行動選択し続けたときの将来的な価値を表していると考えることができます.
\mathcal T Z(x,a) =_D R(x,a) + \gamma Z(x', arg\max_{a'} \mathbb E[Z(x', a')])
また,$Z(x) = \mathbb E_a[Z(x,a)]$ と表すことにします.
p-Wasserstein距離
p-Wasserstein距離: $W_p (p\in [1,\infty])$ は,累積分布関数の逆関数(=分位点関数)の間の$L_p$ノルムで表されます.よって,確率分布 $U, Y$ の間の$W_p$は,以下の式で表されます.ただし,$F_Y^{-1}(\omega)=\inf \{y \in \mathbb R : \omega \le F_Y(y)\}$ は,確率変数 $Y$ の分位点関数を表します.
d_p(U,V) = \left(\int_0^1 \mid F_Y^{-1}(\mathcal \omega) - F_U^{-1}(\omega)\mid^p d\omega\right)^{1/p}
以下では,p-Wasserstein距離を単に $W_p$ と呼びます.
分布ベルマンオペレータ
以下では,$\mathcal Z$ は有限モーメントの価値分布空間を表します.
\mathcal Z = \{Z: \mathcal X \times \mathcal A \to \mathcal P(\mathcal R) \mid
\mathbb E[|Z(x,a)|^p] < \infty, \forall(x,a), p \ge 1
\}
2つの価値分布 $Z_1, Z_2 \in \mathcal Z$ に関して,$W_p$の上界を以下のように表します.
\bar d_p(Z_1, Z_2) = \sup_{x,a} W_p(Z_1(x,a), Z_2(x,a))
C51の論文では,この $\bar d_p$ が価値分布に関する計量になっていることが示されています.さらに,以下の補題1が成り立ちます.
補題1:
分布ベルマンオペレータ $\mathcal T^{\pi}$ は,任意の $Z_1,Z_2 \in \mathcal Z$ について,$\bar d_p$ に関して$\gamma-$縮小である.
\bar d_p(\mathcal T^\pi Z_1, \mathcal T^\pi Z_2) \le \gamma \bar d_p(Z_1, Z_2)
従って,分布ベルマンオペレータ $\mathcal T^\pi$ は唯一の不動点 $Z^\pi$ を持ち,$\bar d_p (\mathcal T^{\pi} Z^\pi(x,a), Z^\pi(x,a)) = 0$ となります.理想的には $\bar d_p (\mathcal T^{\pi} Z_\theta(x,a), Z_\theta(x,a))$ の勾配を求め,パラメータ $\theta$ を更新していくことで,$Z_{\theta}$ は方策 $\pi$ での価値分布 $Z^\pi$ に(関数近似誤差を無視すると)収束していくことが期待できます.
しかし,以下の**定理1**により,**$W_p$ (もしくは $\bar d_p$ )を損失関数として,経験分布上の勾配降下法で最小化することは一般的には不可能である**ことが示されています.
>**定理1**:
>ベルヌーイ分布 $B$ からのサンプル $Y_1,\cdots,Y_m$ を用いた経験分布を $\hat Y_m = \frac{1}{m}\sum_{i=1}^{m}\delta_{Y_i}$ とする.また,$B_\mu$ を,確率変数が1となる確率 $\mu$ でパラメトライズしたベルヌーイ分布とする.このとき,サンプルから計算した分布との$W_p$の最小値と,真の$W_p$の最小値は一般的に異なる.
>```math
arg\min_{\mu} \mathbb E_{Y_{1:m}}[W_p(\hat Y_m, B_\mu)] \neq arg\min_{\mu} W_p(B, B_\mu)
このことから,C51は $W_p$ (もしくは $\bar d_p$ )ではなくKLダイバージェンスの最小化を行っており,理論と実装のギャップが存在しています.
p-Wasserstein距離の最小化
価値分布は,状態と行動が入力されたとき,定義域に価値,値域に確率を持つ関数(=確率密度関数)で表されます.C51では,価値($z_1\le\cdots\le z_N$)を固定し,その点での確率($q_1,\cdots,q_N$)をモデル化していました.
この論文では,逆に確率を固定し,その価値を予測するアプローチを取ります.つまり,累積分布関数の逆関数(=分位点関数)を考え,累積確率 $\tau_i = \frac{i}{N} (i=1,\cdots,N)$ を一様に固定し,その累積確率での分位点関数の値(=価値)をモデル化します(ただし $\tau_0 = 0$ とする).ここで,分位点関数の値を分位点と呼びます.また,この価値分布を分位点分布と呼び,$N$ を固定した時の分位点分布空間を $\mathcal Z_Q$ とします.
分位点分布を近似するモデルを $\theta: \mathcal X \times \mathcal A \to \mathbb R^N$ とします.分位点分布 $Z_\theta \in \mathcal Z_Q$ は,状態行動対 $(x,a)$ から,$\{\theta_i(x,a)\}$ の台を持つ離散一様分布への写像とします.だたし,$\delta$ はディラックのデルタを表します.
Z_\theta(x,a) = \frac{1}{N} \sum_{i=1}^N \delta_{\theta_i(x,a)}
C51での定式化に比べ,分位点分布をモデル化することのメリットは3つあります.
- 価値の下限,上限を設定する必要がなくなり,価値の範囲が状態によって大きく異なる時など,より精度の高い推定が可能になると期待される
- C51の不自然な射影変換が必要なくなる
- 分位点回帰を用いることで,バイアス無しで$W_1$の最小化を行うことができる
特に,3つ目のメリットにより,理論と実装のギャップを大きく狭めることができます.
分位点の近似
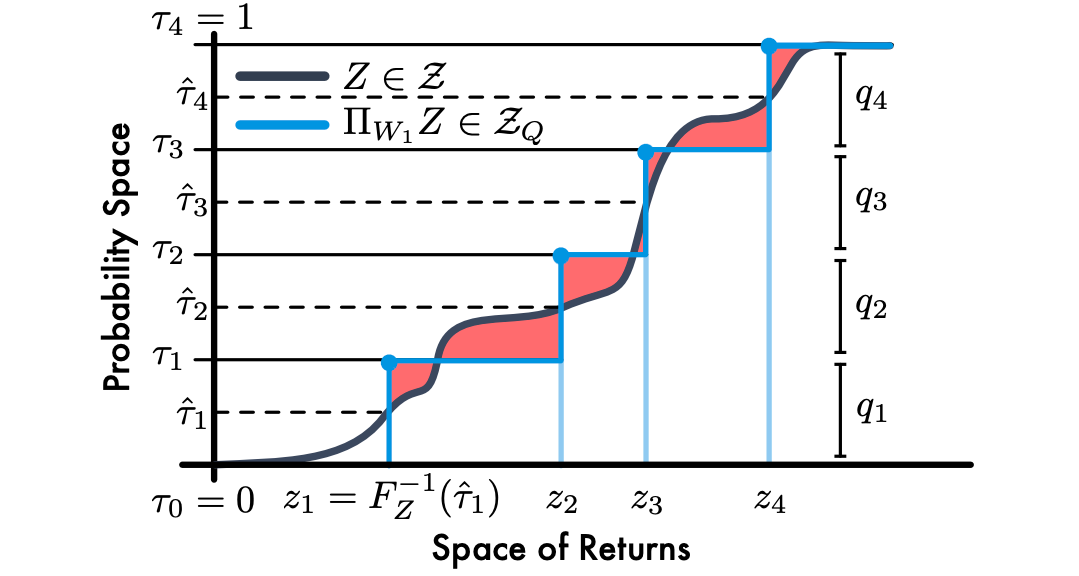
以下では,「台 $\theta_i$ を持つ一様な離散分布 $U$ と,分位点関数 $F_Z^{-1}$ を持つ価値分布 $Z$ の間の $W_1$ は,$\theta_i = F_Y^{-1}(\frac{\tau_{i-1}+\tau_i}{2})$ のときに最小化されること」を示していきます.
まず,元の分布との $W_1$ を最小化するような,ある価値分布 $Z \in \mathcal Z$ から分位点分布空間 $\mathcal Z_Q$ への射影 $\Pi_{W_1}$ を考えます.
\Pi_{W_1}Z = arg\min_{Z_\theta \in \mathcal Z_Q} W_1(Z, Z_\theta)
次に,$Y$ を1次モーメントが有界な確率分布,$U$ を以下のような $\{\theta_1,\cdots,\theta_N\}$ の台を持つ離散一様分布とします.
U = \frac{1}{N} \sum_{i=1}^N \delta_{\theta_i}
すると,確率分布 $Y,U$ の間の$W_1$は,以下のように表せます.
W_1(Y,U) = \sum_{i=1}^N\int_{\tau_i-1}^{\tau_i} | F_Y^{-1}(\omega)-\theta_i | d\omega
補題2:
任意の $\tau, \tau' \in [0,1] (\tau < \tau')$ と累積分布関数 $F$ について.
\int_\tau^{\tau'} \mid F^{-1}(\omega)-\theta\mid d\omega
>を最小化する $\theta \in \mathbb R$ の集合は,以下の式で与えられる.
>
>```math
\{\theta \in \mathbb R \mid F(\theta) = \left( \frac{\tau + \tau'}{2} \right) \}
特に,$F^{-1}$ が分位点関数であれば,$\theta = F^{-1}((\tau+\tau')/2)$ のときに最小値をとり,$(\tau+\tau')/2$で連続であれば,唯一の最小値をとる.
補題2から,一様な累積確率の中点を $\hat \tau_i = \frac{\tau_{i-1} + \tau_i}{2} (1\le i \le N)$ とすると,$W_1(Y,U)$ を最小化する分位点は $\theta_i = F_Y^{-1}(\hat \tau_i)$ であることがわかります.上図は,$N=4$ の時の $Z$ (灰色)と,$W_1$ を最小化するように分位点分布空間に射影した $\Pi_{W_1}Z$ (水色)を表しています.ただし,累積分布関数の形で表しています.
しかし,以下の命題1から,経験分布との $W_1$ を最小化しても,真の分布との $W_1$ は最小にならないという問題が生じます.
命題1:
$Z_\theta$ を分位点分布とし,$\hat Z_m$ を $Z$ からの$m$個のサンプルからなる経験分布とする.このとき,すべての$p\ge1$ について,以下の式を満たす $Z$ が存在する.
arg\min \mathbb E[W_p(\hat Z_m,Z_\theta)] \neq arg\min W_p(Z,Z_\theta)
### 分位点回帰
以下では,「分位点回帰を用いることで,経験分布からバイアスなしで $W_1(Z,U)$ を最小化できること」を示していきます.
経済の分野において,バイアスなしで分位点関数を確率的に近似する手法,**分位点回帰**が存在します.そこでは,累積確率 $\tau \in [0,1]$ の分位点の回帰には,過大評価を $\tau$ で,過小評価を $1-\tau$ で重みづけして罰します.つまり,確率分布 $Z$ とその累積確率 $\tau$ が与えられたとき,分位点 $\theta = F_Z^{-1}(\tau)$ は,以下の損失関数を最小化することで得られます.
```math
\mathcal L_{QR}^{\tau}(\theta) = \mathbb E_{z' \sim Z}[\rho_\tau (z' - \theta)]
ただし,$\rho_\tau(u)$ は以下の式で表されます.
\rho_\tau(u) = u(\tau - \delta_{\{u<0\}}), \forall u \in \mathbb R
つまり,真の分布からのサンプル(ターゲット)を $z'$ ,予測値を $\theta$ とすると,$z' > \theta$ のときは $\tau (z'- \theta)$ ,$z' < \theta$ のときは $(1-\tau) (z'- \theta)$ とします.
この分位点回帰を用いると,任意の累積確率 $\tau$ における分位点を推定できます.よって,補題2から $\hat \tau_i = \frac{\tau_{i-1}+\tau_i}{2}$ における分位点を推定することで,$W_1(Z,Z_\theta)$ を最小化する分位点 $\{\theta_1,\cdots,\theta_N \}$ を求めることができます.すなわち,以下の目的関数を最小化します.
\sum_{i=1}^N \mathbb E_{z' \sim Z}[\rho_{\hat \tau_i}(z'-\theta_i)]
この目的関数はバイアスなしの勾配を持つので,確率的勾配降下法によって $W_1$ を最小化することができます.しかし,$0$付近で滑らかではないため,下記のquantile Huber lossと呼ばれる,滑らかな損失関数を提案しています.
\rho_\tau^\kappa(u) = |\tau - \delta_{\{u<0\}}| \frac{\mathcal L_\kappa(u)}{\kappa}
ただし,$\mathcal L_\kappa(u)$ はHuber lossを表し,以下の式で表されます.
\mathcal L_\kappa(u)= \begin{cases}\frac{1}{2} u^2 \;\;\;\;\;\;\;\;\;\;\:\;\;\;\;\; |u| \le \kappa \\\kappa(|u|-\frac{1}{2}\kappa) \;\;\;\;\;{\rm otherwise}\end{cases}
$\kappa$ が $0$ に近づくにつれ,元の損失関数に近づくことがわかります.
オペレータの収束性
前述の議論により,分位点回帰を用いることで,$W_1$ を最小化しつつ,価値分布空間から分位点分布空間への射影を行えることがわかりました.以下では,「その射影を組み合わせることで,分布ベルマンオペレータが $\bar d_\infty$ に関して縮小である」ことを示します.
命題2:
$\Pi_{W_1}$ を $W_1$ を最小化するような価値分布から分位点分布空間への射影とする.そのとき,離散状態行動空間MDPにおける任意の価値分布 $Z_1,Z_2 \in \mathcal Z$ について,以下の式が成り立つ.
\bar d_\infty (\Pi_{W_1}\mathcal T^\pi Z_1,\Pi_{W_1}\mathcal T^\pi Z_2) \le \gamma \bar d_\infty (Z_1, Z_2)
よって,射影と分布ベルマンオペレータを合わせた操作 $\Pi_{W_1}\mathcal T^{\pi}$ は,唯一の不動点 $\hat Z^\pi$ を持ちます.また,$\bar d_p \le \bar d_\infty$ なので,任意の$p\in [1,\infty]$ について $\bar d_p$ は収束することが示されます.(縮小性は自明ではありません.)
## QR-DQN
### 方策評価
**補題2**では,適切に選んだ累積確率 $\hat \tau \in (0,1) $ について分位点を計算することで,$W_1$を最小化する分位点分布への射影を計算できることを示しました.また,分位点回帰を用いることで,その射影を経験分布からバイアスなしで計算することができました.さらに,分布ベルマンオペレータとその射影を組み合わせた操作 $\Pi_{W_1}\mathcal T^\pi$ は,唯一の不動点を持ちました.
まとめると,分位点分布 $Z_{\theta}(x, a) \in \mathcal Z_Q$ において,分位点回帰を用いて $W_1(\mathcal T^\pi Z_{\theta'}, Z_\theta)$ を最小化する($Z_\theta = \Pi_{W_1}\mathcal T^\pi Z_{\theta'}$ となる)ように $\theta$ を更新していくことで,$\bar d_\infty$ に関して縮小となり,$Z_\theta$ が方策 $\pi$ における価値分布(を離散化した分布)へと収束していきます.ただし,$\theta'$ はターゲットネットワークのパラメータを表します.
### 方策改善
Q学習では,最適ベルマンオペレータに従う,すなわち,貪欲方策によって選択した行動に関する価値をターゲットとして用いていました.同様に,最適分布ベルマンオペレータを用いることで,貪欲方策に基づいた更新を行うことができ,**価値分布の期待値が最適価値関数に収束する**ことが保証されます.すなわち,分位点回帰を用いて $W_1(\mathcal T Z_{\theta'}, Z_\theta)$ を最小化するように $\theta$ を更新していきます.
### アルゴリズム
まとめると,以下のようなアルゴリズムになります.特にDQNのアルゴリズムに以下の3つの修正を加えたアルゴリズムを**QR-DQN**と呼びます.
- ネットワークの出力を $|\mathcal A|$ 次元から,$|\mathcal A| \times N$ 次元に変更($N$ は分位点の数)
- DQNのHuber lossを,quantile Huber lossに変更
- RMSPropからAdamに変更

## 検証


AtariのArcade Learning Environment(ALE)で検証します.比較対象はDQNと**C51**で,**QR-DQN**は $\kappa=0,1$ の時をそれぞれ**QR-DQN-0**,**QR=DQN-1**とします.その他の詳細な設定は,論文を参照してください.
上図は,100万サンプルごとに評価した際の平均収益(左)と学習時の平均収益(右)を表しています.また,上表は2億サンプル学習したときの,途中評価のベストスコアを表しています.
これらの結果から,**QR-DQN**(特に**QR-DQN-1**)が,他の手法を上回る性能を示していることがわかります.
## まとめ
この論文では,**C51**の課題であった理論と実装のギャップを埋め,価値分布間の$\infty$-Wasserstein距離(の上界)の最小化に基づいた分布型強化学習の手法**QR-DQN**を提案しました.
課題としては,固定した累積確率上での分位点をモデル化しているため,表現できる価値分布のクラスが制限されてしまうことなどがあげられます.