この記事は,以下の論文の解説です.
A Distributional Perspective on Reinforcement Learning (ICML 2017)
記事内容では,強化学習の基礎的な知識を前提としています.
また,記事中の図は全て論文からの引用です.
不備がございましたら,ご指摘頂けると幸いです.
概要
この論文は,価値分布を推定し,その期待値を最大化する分布型強化学習の手法を提案した論文になります.
従来の強化学習の手法の多くは,ベルマン方程式によって,将来的な(割引した)報酬または価値の「期待値」の推定を行います.つまり,この行動をとったら将来的にどのくらいの報酬が得られるかなぁ,という期待値の推定を行なっています.
一方,「この行動をとると大体の確率ではうまくいくけど,稀にヤバイことが起こるかもしれない」など,期待値だけでは表現しきれない情報(リスクなど)も多く存在します.従って,主にリスク考慮型強化学習の文脈において,価値を確率変数とみなし,期待値だけでなく価値の分布そのものを推定しようというモチベーションが存在します.
この論文では,まず
- 価値分布に関するベルマン方程式(=分布ベルマン方程式)が,固定した方策のもとで,ある計量(p-Wasserstein距離の上界)において縮小写像であること
- 最適分布ベルマン方程式が,期待値に関しては収束するが,分布に関してはいかなる計量においても縮小にならないこと
を示します.その後,価値分布を近似的に学習する手法,Categorical DQNまたはC51を提案し,Atariの環境において,価値分布の推定を行う分布型強化学習の重要性を検証していきます.
準備
以下では,通常のMDP $(\mathcal X, \mathcal A, R, P, \gamma)$ を想定します.ただし,この論文では,報酬関数 $R$ は明示的に確率変数として扱います.
収益 $Z^{\pi}$ は,状態 $x$ で行動 $a$ を行なった後,方策 $\pi$ に従って行動した際の(割引)累積報酬和を表します.価値関数 $Q^{\pi}$ は収益の期待値を表し,以下の関係が成り立ちます.
Q^\pi (x,a) = \mathbb E[Z^\pi (x,a)] = \mathbb E[\sum_{t=0}^\infty \gamma^t R(x_t, a_t)]
従来の強化学習では,以下のベルマン方程式により再帰的に価値関数を記述します.
Q(x, a) = \mathbb E [R(x,a)] + \gamma \mathbb E_{P, \pi} [Q(x', a')]
このベルマン方程式は唯一の不動点をもち,方策 $\pi$ のもとでの価値関数 $Q^\pi$ に一致します.多くの場合,本来の目的は価値を最大化する方策を求めることなので,以下の最適ベルマン方程式を考えます.
Q^*(x,a) = \mathbb E [R(x,a)] + \gamma \mathbb E_P [\max_{a'} Q^* (x', a')]
この最適ベルマン方程式は,唯一の不動点 $Q^*$ を持ちます.この $Q^*$ は,最適な方策に従って行動し続けた時の価値関数,最適価値関数に一致します.
また,ベルマン方程式,最適ベルマン方程式に対応したベルマンオペレータ $\mathcal T^\pi$,最適ベルマンオペレータ $\mathcal T$ を導入します.
\mathcal T^\pi Q(x,a) = \mathbb E[R(x,a)] + \gamma \mathbb E_{P, \pi}[Q(x',a')] \\
\mathcal T Q(x,a) = \mathbb E[R(x,a)] + \gamma \mathbb E_{P}[\max_{a'} Q(x',a')]
これらのオペレータは,(関数近似誤差が生じない場合) それぞれ $Q^\pi, Q^*$ に指数関数的に収束することが証明されています.すなわち,近似した価値関数 $Q_{0}$ に関して,これらのオペレータ $\mathcal T^\pi,\mathcal T$ を繰り返し適用していくことで,$Q_0$ がそれぞれ $Q^\pi, Q^{*}$ に収束していくことがわかっています.
分布ベルマンオペレータ
この論文では,前述のベルマンオペレータから期待値操作を取り除き,確率変数 $Z^\pi$ の分布自体を考えていきます.以下では,$Z^\pi$ を状態行動ペアから収益に関する分布への写像とし,価値分布と呼びます.
p-Wasserstein距離
以下では,ある確率変数 $U$ の累積分布関数を $F_U(y) = Pr\{U \le y\}$ と表します.よって,累積分布関数の逆関数である分位点関数(quantile function)は $F_U^{-1}(q) = \inf \{y: F_U(y) \ge q\}$ と表すことができます.また,両辺の確率変数が同じ確率分布に従うことを,$=_D$ で表します.
分布型強化学習では,p-Wasserstein距離( $d_p$ )が大きな役割を果たします.以下では,p-Wasserstein距離を単に $d_p$ と表します.実数空間上の確率分布間の $d_p$ は,分位点関数間の $L_p$ノルムで定義されます( $p\in [1,\infty]$ ).つまり,$U,V$の累積分布関数をそれぞれ$F,G$ とし,$[0,1]$の一様分布に従う確率変数を $\mathcal U$とすると,以下の式で表されます.
d_p(U,V) = ||F^{-1}(\mathcal U) - G^{-1}(\mathcal U)||_p
$p < \infty$ の場合には,以下のように書き下すことができます.
d_p(U,V) = \left(\int_0^1 \mid F^{-1}(u) - G^{-1}(u)\mid^p du\right)^{1/p}
$\mathcal Z$ を価値分布の確率空間とし,確率変数 $Z_1, Z_2 \in \mathcal Z$ の $d_p$ の上界を以下のように表します.
\bar d_p(Z_1, Z_2) = \sup_{x,a} d_p(Z_1(x,a), Z_2(x,a))
証明は省略しますが,$\bar d_p$ は価値分布に関する計量(距離)となっていることが示されています(論文付録参照).
方策評価
以下では,分布ベルマンオペレータ $T^\pi$ を考えていきます.
方策 $\pi$ に従った時の価値分布に関する遷移写像 $\mathcal P^\pi : \mathcal Z \to \mathcal Z$ を以下のように定義します.ただし,大文字の変数は,確率変数であることを陽に表し,$(X',A')$ は次の状態行動ペアを表しています.($X'$ は環境の確率性,$A'$ は方策の確率性により確率変数となります.)
P^\pi Z(x,a) =_D Z(X', A')
これを用いて,分布ベルマンオペレータ $\mathcal T^\pi$ を以下のように定義します.
\mathcal T^\pi Z(x,a) =_D R(x,a) + \gamma P^\pi Z(x,a)
初期報酬分布 $Z_0 \in \mathcal Z$ から, $Z_{k+1}=\mathcal T^\pi Z_k$ の操作を繰り返すことを考えます.(分布型ではない)通常のベルマンオペレータでは,価値の期待値 $Q_0$ が指数関数的に $Q^\pi$ に収束することが証明されていました.
証明は省略しますが,分布型ベルマンオペレータ $\mathcal T^\pi: \mathcal Z \to \mathcal Z$ は計量 $\bar d_p$ において $\gamma$-縮小であることが示されています(論文付録参照).すなわち,分布型ベルマン方程式 $Z(x,a) = \mathcal T^\pi Z(x,a)$ は唯一の不動点 $Z^\pi$ をもち, $\mathcal T^\pi$ を適用していくことで,初期報酬分布 $Z_0$ は $Z^\pi$ に指数関数的に収束することが証明されています.
方策改善
前述の方策評価では,固定した方策のもとでの分布ベルマンオペレータ $\mathcal T^{\pi}$ を考えてきました.ここからは,Q学習のように,価値関数を最大化するように方策を改善するような操作,最適分布ベルマンオペレータ $\mathcal T$ を考えていきます.
まず,最適価値分布 $Z^*$ を最適方策 $\pi^*$ における価値分布 $Z^{\pi^*}$ と定義します.ここで,期待値が $Q^*$ となる価値分布は,必ずしも最適価値分布 $Z^*$ ではないことに注意します.
また,最適分布ベルマンオペレータ $\mathcal T$ を以下のように定義します.
\mathcal T Z(x,a) =_D R(x,a) + \gamma Z(X', arg\max_{a'} \mathbb E[Z(X', a')])
ただし,$Q(x',a')=\mathbb E[Z(x',a')]$ なので,最適分布ベルマンオペレータ $\mathcal T$ は価値関数 $Q$ を最大にする行動を選択する貪欲方策に従ったときの分布ベルマンオペレータを意味します.方策評価と同様に,$Z_{k+1} = \mathcal T Z_k$ を適用して行った際の挙動に興味があります.計量 $\bar d_p$ において不動点 $Z^*$ に指数関数的に収束するのではないかと期待してしまいますが,残念ながらいかなる計量においても収束は保証されていません.また,最適分布ベルマンオペレータ $\mathcal T$ は,必ずしも不動点 $Z^*$ を持つわけではないことがわかっています.
論文では,最適分布ベルマンオペレータ $\mathcal T$ を $Z_0$ に適用していくことで,$Z_0$ の期待値は最適価値 $Q^{*}$ に指数関数的に収束することが証明されています(論文付録参照).つまり,分布全体を見ると収束は保証できませんが,期待値は収束していくことが保証されています.
分布型強化学習(C51)
以下では,最適分布ベルマンオペレータに基づいて,近似的に最適価値分布を推定するアルゴリズムを見ていきます.
価値分布のパラメトライズ
ここでは,以下のパラメータでパラメトライズされた離散分布を使って,価値分布をモデル化していきます.
- $N \in \mathbb N$: ビンの数
- $V_{\min}, V_{\max} \in \mathbb R$: 価値の下限・上限
また,$z_i = V_{\min} + i \Delta Z$,$\Delta Z = \frac{V_{\max} - V_{\min}}{N-1}$ とします.
このモデル $\theta: \mathcal X \times \mathcal A \to \mathbb R^N$ を用いて,価値が$[z_{i}, z_{i+1}]$ となる確率 $p_i(x,a)$ を,以下のように表します.
p_i(x,a) = \frac{e^{\theta_i(x,a)}}{\sum_j e^{\theta_j(x,a)}}
このモデルでは,$N$ 個のビンで離散化した価値分布を表現しています.このモデルを利用することで,ガウス分布などでモデル化した場合に比べ,複雑な分布(i.e. 多峰な分布)を表現することができます.
射影ベルマンオペレータ
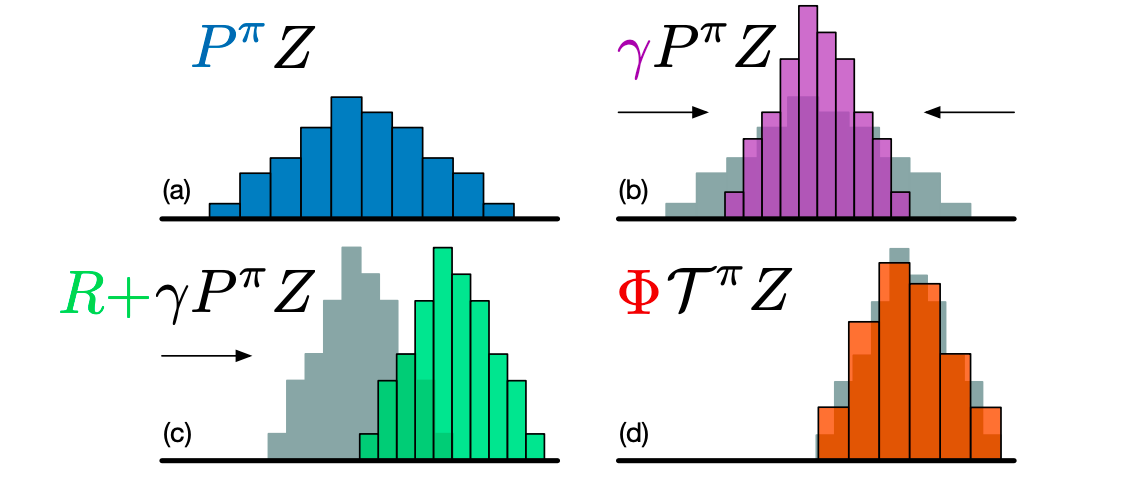
これまでの議論から,$\bar d_p (\mathcal T Z_\theta, Z_\theta)$ を損失関数として最小化するように $\theta$ を更新していけば,$Z_\theta$ の期待値は最適価値関数に収束していくので,自然なアプローチに思えます.しかし,以下に示すような問題が生じます.
前述のような離散分布を用いることで,$Z_\theta$ や $\mathcal T Z_\theta$ は異なる台を持ってしまいます.つまり,分布ベルマンオペレータは割引率 $\gamma$ によって分布の形を狭める作用を持つので(上図上の2つ),離散的なビンの境界の位置が $Z_\theta$ と $\mathcal T Z_{\theta}$ で異なってしまいます.
この問題を解決するために,$\mathcal T^{\pi} Z_\theta$ が $Z_\theta$ と同じ台を持つように,$\Phi$ で射影してあげます(上図下の2つ).射影後の $[z_{i}, z_{i+1}]$ に含まれる確率 $(\Phi {\mathcal T} Z_{\theta}(x,a))_i$ は以下のように表すことができます.ただし,$[\cdot]_a^b$ は,$[a,b]$ でクリップする操作を表します.
(\Phi {\mathcal T} Z_\theta(x,a))_i = \sum_{j=0}^{N-1} \left[1-\frac{|[\mathcal T z_j]_{V_\min}^{V_{\max}} - z_i|}{\Delta z}\right]_0^1 p_j(x',\pi(x'))
数式で見るとイカツイですが,これは単に,上図の左下から右下のように,分布の形を変えないようにもとのビンに割り当て直していると考えることができます.
(注: $d_p$ は異なる台を持っていても計算可能なのですが,次にみるようにC51では $d_p$ ではなくKLダイバージェンスの最小化を行うので,ここは解決する必要がありました.)
また,証明は省略しますが,経験分布との $d_p$ を最小化しても,真の分布との $d_p$ は最小にならないという問題が生じます.すなわち,過去の遷移データのサンプリングから学習を行う設定では, $d_p$ (もしくは $\bar d_p$ )を損失関数として,最小化することは不可能であることが示されています(論文付録参照).
この問題を解決するために,$d_p$ (もしくは $\bar d_p$)ではなくKLダイバージェンスを最小化することを行います.ターゲットネットワーク(重み: $\theta'$)を利用すると,最小化するべき損失関数は以下の式で表せます.
\mathcal L(\theta) = D_{KL}(\Phi\mathcal T Z_{\theta'}(x,a)||Z_\theta(x,a))
アルゴリズム
まとめると,以下のようなアルゴリズム(Categorical Algorithm)になります.ネットワーク構造にDQNを用いたとき Categorical DQN,加えてパラメータ $N=51$ を用いたとき,C51 と呼びます.

検証
AtariのArcade Learning Environment(ALE)で検証していきます.
提案手法では,ネットワーク構造にDQNアーキテクチャを用い(Categorical DQN),$V_{\max} = - V_{\min} = 10$ としました.
結果
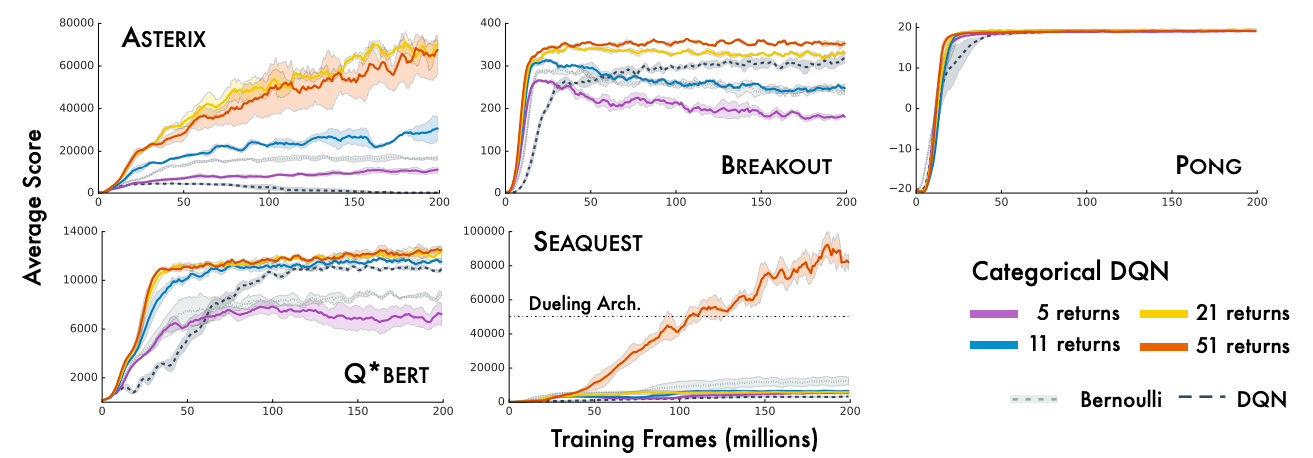
上図では,ビンの数 $N$ を変化させた際のCategorical DQNの結果を示しています.この結果から,特に $N=51$ のとき,他の設定を上回る性能を示していることが読み取れます.この $N=51$ でDQNアーキテクチャを用いた際の手法をC51と呼びます.
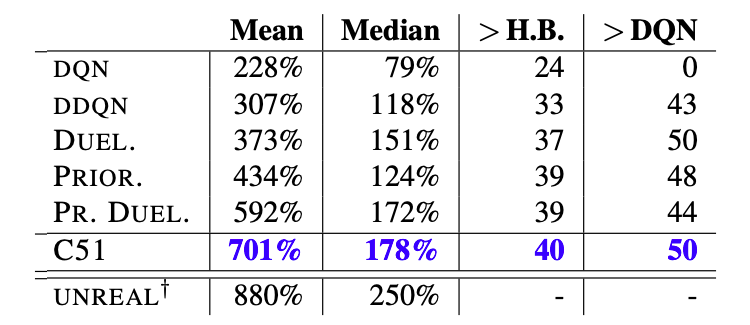
また上表では,C51をDQN,Double DQNなどの他の手法と比較検証しています.この表から,C51はALEにおいて,他の手法を大きく上回る性能を示していることがわかります.
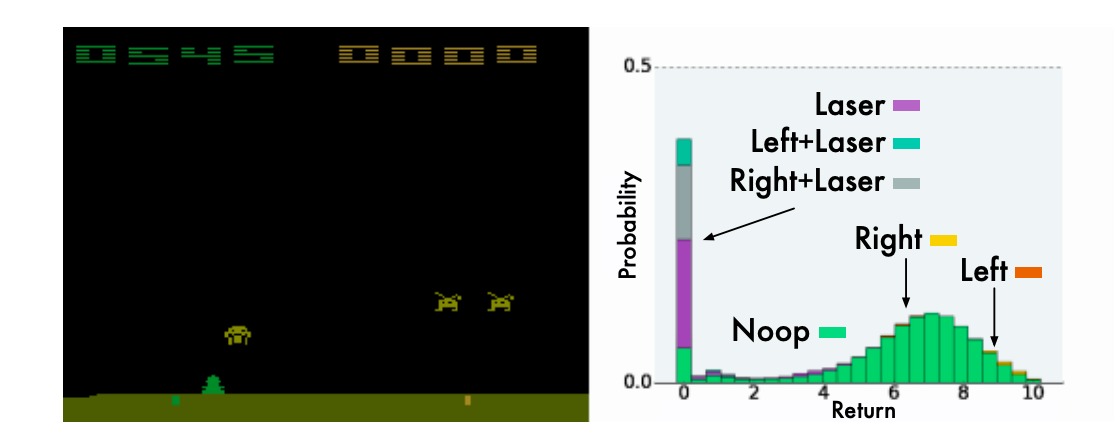
上図は,得られた価値分布の例を示しています.ほとんどの行動は,レーザーを放つタイミングが早すぎるため,ほとんどの確率を報酬0に割り当てています.一方,レーザーを放たない行動(Noop,Right,Left)では,同じような分布の形を示しています.このように,期待値だけでなく分布全体を推定することで,より多くの情報を得ることができると言う大きな利点があると考えられます.

また,Pongの環境では「得点の入る正確なタイミングは観測不可能である」と言う不確実性を持っています.上図は,得点の入る瞬間の5フレームの価値分布を示していますが,ボールが相手側に近づくにつれ分布のモードが2つに分かれていき,得点が入る直前にはプラスの報酬付近で大きなモードを持っていることが読み取れます.すなわち,価値分布はPongが持つ内在的な不確実性を表現できていることがわかります.
まとめ
この論文では,価値分布を推定しその期待値を最大化する分布型強化学習の手法,Categorical DQNまたはC51を提案しました.
このアルゴリズムの課題として,
- 価値分布の下限,上限: $V_{\min}, V_{\max}$ がハイパーパラメータである点
- 学習がp-Wasserstein距離の上界ではなく,KLダイバージェンスの最小化により行われている点
などが挙げられます.