背景
業務の都合上、CANのログをとる機会がそこそこあります。
よくある話ですが、皆さま同じ時期に忙しくなるわけで某V社のツールの争奪戦になりがちです。そのため、以前計測したデータを変換したくともなかなかできない、、それならツールを作ってしまえというのが背景です。
変換ツールの要件
要件はざっと、以下のような感じかと思います。
- GUIで感覚的に操作できること
- exe化配布できること(業界的にPythonに抵抗がある方が意外と多い)
- フォーマットを変換できること、最低限
BLF<->ASC(プロジェクトごとにどれかにしか対応してないことが多い(気がする)ため) - デコードした結果を
csvやmat形式に変換できること - お金がかからないこと
- データサイズが大きい場合はデータを分割できること
- 言語はPython(
プライベートでPython以外書きたくないCAN関連のライブララリが豊富なため)
早速成果物
クローンしてご利用ください。
依存パッケージ
CANConverterを使用するには、以下のPythonライブラリが必要です。
pip install python-can cantools pandas asammdf tkinterdnd2
実行方法
python ./src/ConverterGUI.py
操作方法
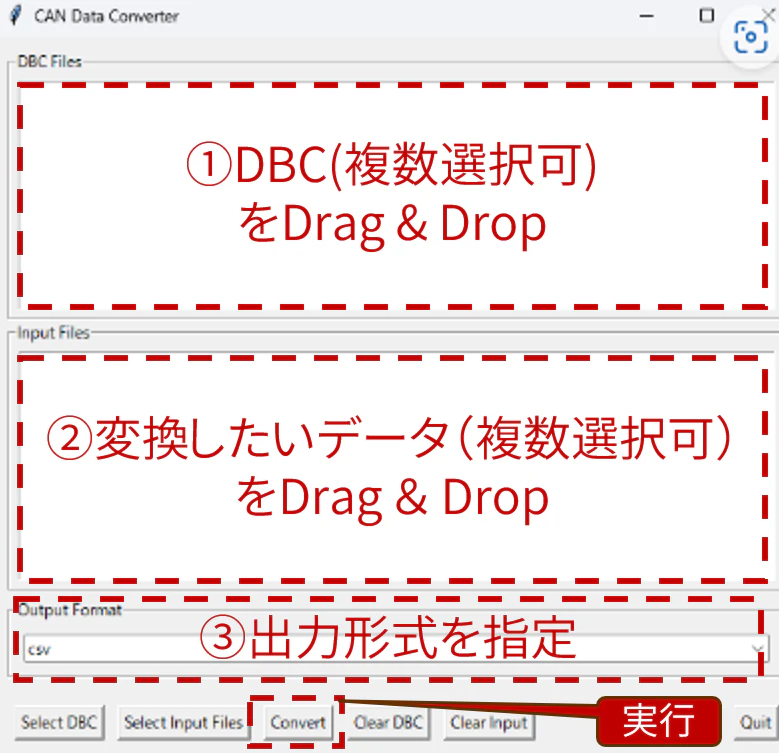
簡単に中身の紹介
大きくは以下の機能で構成されています。
- フォーマット間変換
- デコード処理
- csv出力機能
- +おまけのGUI
CANConverter.py
import can
import pandas as pd
import cantools
from glob import glob
import os
import scipy
from asammdf import MDF
class CANFormatConverter:
def __init__(self):
self.database = None
self.temp_data_set = {}
self.update_counter = 0
pass
def load_and_merge_dbc(self, dbc_files):
try:
# cantools を使用して複数のDBCファイルを結合
database = cantools.database.Database()
for dbc_file in dbc_files:
database.add_dbc_file(dbc_file)
self.database = database
return database
except Exception as e:
print(f"Error loading DBC files: {e}")
return None
# blf -> csv
def convert_blf_to_csv(self, input_pth, output_pth):
"""
BLFファイルをcsvに変換
ライブラリの都合上、CAN→csvの変換はBLFに一時的に変換しておく必要があります。
"""
# dbcが読み込まれていなければエラーを返す
if self.database == None:
print(fr"Databaseが読み込まれていません")
return
# blfファイルの読み込み()
blfdata=can.io.blf.BLFReader(input_pth)
# 保存用のデータベースの初期化
self.initialize_decoded_signal_list()
for msg in blfdata:
try:
# decode
decoded_signals = self.database.get_message_by_frame_id(msg.arbitration_id).decode(msg.data, decode_choices=False)
timestamp = msg.timestamp
print(fr"Succeed Converting can_id={msg.arbitration_id}")
# update database
self.update_decoded_signal_list(timestamp, decoded_signals)
except Exception as e:
print(fr"Cannot find id :{e}")
# デコード結果をcsvとして出力
self.save_decoded_signal_list(output_pth)
def initialize_decoded_signal_list(self):
self.temp_data_set = {"time":[]}
self.update_counter = 0
def update_decoded_signal_list(self, time, dec_sigs):
self.update_counter += 1
# すべての信号を前回値埋めしておく
if self.update_counter > 2:
for sig in self.temp_data_set:
old_sig = self.temp_data_set[sig]
self.temp_data_set[sig].append(old_sig[-1])
# 時間要素の更新
self.temp_data_set["time"][-1] = time
else:
# 時間要素の更新
self.temp_data_set["time"].append(time)
data_length = len(self.temp_data_set["time"])
# 入力信号要素を更新、なければ新規で要素を作っておく
for sig in dec_sigs:
# 信号が過去に受信されていた場合
if sig in self.temp_data_set:
self.temp_data_set[sig][-1] = dec_sigs[sig]
# 信号が過去に受信されていなかった場合
else:
self.temp_data_set[sig] = [0 for i in range(data_length)]
self.temp_data_set[sig][-1] = dec_sigs[sig]
def save_decoded_signal_list(self, output_pth, chunk_size=1000, down_sampling_rate=200):
"""
デコードした CAN データを CSV に保存(大容量データの場合は分割)
Args:
output_pth (str): 出力 CSV のパス
chunk_size (int): 1 ファイルあたりの最大行数
"""
# すべての信号の最大データ長を取得
max_length = max(len(values) for values in self.temp_data_set.values())
# 各リストを `max_length` に合わせて補完
for key in self.temp_data_set:
while len(self.temp_data_set[key]) < max_length:
self.temp_data_set[key].append(None) # 長さが足りない場合は `None` で埋める
# DataFrame に変換
df = pd.DataFrame(self.temp_data_set)
df = df[["time"] + sorted(self.temp_data_set.keys())] # カラム順を統一
# DataFrameをダウンサンプリング
df = df[::down_sampling_rate]
# データを `chunk_size` ごとに分割して保存
total_rows = len(df)
num_parts = (total_rows // chunk_size) + (1 if total_rows % chunk_size else 0)
base_name, ext = os.path.splitext(output_pth)
for i in range(num_parts):
start_idx = i * chunk_size
end_idx = min((i + 1) * chunk_size, total_rows)
df_chunk = df.iloc[start_idx:end_idx]
# ファイル名に `_part1`, `_part2`, ... を追加
chunk_file = f"{base_name}_part{i+1}{ext}"
# 拡張子がcsvの場合
if ext == ".csv":
df_chunk.to_csv(chunk_file, index=False)
# 拡張子がMATの場合
elif ext == ".mat":
mat_data = {col: df[col].values for col in df.columns}
scipy.io.savemat(chunk_file, mat_data)
else:
print("Error:inputed file ext is Wrong! Only 'csv' or 'mat' is acceptable")
print(f"Saved: {chunk_file} ({len(df_chunk)} rows)")
# mf4 -> csv
def convert_mf4_to_csv(self, input_pth, output_pth, down_sampling_rate=10):
# Load the MF4 file
mdf = MDF(input_pth)
# Convert the MDF object to a pandas DataFrame
df = mdf.to_dataframe()
# Chunk data(※この値は適当なのでもし変えたい場合はIFを変更のこと)
df = df.loc[::down_sampling_rate]
# 拡張子を判別して出力方法を変更
_, ext = os.path.splitext(output_pth)
if ext == ".csv":
df.to_csv(output_pth)
elif ext == ".mat":
mat_data = {col: df[col].values for col in df.columns}
scipy.io.savemat(output_pth, mat_data)
else:
print("Error:inputed file ext is Wrong! Only 'csv' or 'mat' is acceptable")
print(f"Saved: {output_pth}")
# asc -> blf
def convert_asc_to_blf(self, input_pth, output_pth):
try:
with open(input_pth, 'r') as f_in:
log_in = can.io.ASCReader(f_in)
with open(output_pth, 'wb') as f_out:
log_out = can.io.BLFWriter(f_out)
for msg in log_in:
log_out.on_message_received(msg)
log_out.stop()
except Exception as e:
print(fr"Fail to convert : code={e}")
# asc -> bf4
def convert_asc_to_mf4(self, input_pth, output_pth):
try:
with open(input_pth, 'r') as f_in:
log_in = can.io.ASCReader(f_in)
with open(output_pth, 'wb') as f_out:
log_out = can.io.MF4Writer(f_out)
for msg in log_in:
log_out.on_message_received(msg)
log_out.stop()
except Exception as e:
print(fr"Fail to convert : code={e}")
# blf -> asc
def convert_blf_to_asc(self, input_pth, output_pth):
try:
with open(input_pth, 'rb') as f_in:
log_in = can.io.BLFReader(f_in)
with open(output_pth, 'w') as f_out:
log_out = can.io.ASCWriter(f_out)
for msg in log_in:
log_out.on_message_received(msg)
log_out.stop()
except Exception as e:
print(fr"Fail to convert : code={e}")
# blf -> mf4
def convert_blf_to_mf4(self, input_pth, output_pth):
try:
with open(input_pth, 'rb') as f_in:
log_in = can.io.BLFReader(f_in)
with open(output_pth, 'wb') as f_out:
log_out = can.io.MF4Writer(f_out)
for msg in log_in:
log_out.on_message_received(msg)
log_out.stop()
except Exception as e:
print(fr"Fail to convert : code={e}")
# mf4 -> blf
def convert_mf4_to_blf(self, input_pth, output_pth):
try:
with open(input_pth, 'rb') as f_in:
log_in = can.io.MF4Reader(f_in)
with open(output_pth, 'wb') as f_out:
log_out = can.io.BLFWriter(f_out)
for msg in log_in:
log_out.on_message_received(msg)
log_out.stop()
except Exception as e:
print(fr"Fail to convert : code={e}")
# mf4 -> asc
def convert_mf4_to_asc(self, input_pth, output_pth):
try:
with open(input_pth, 'rb') as f_in:
log_in = can.io.MF4Reader(f_in)
with open(output_pth, 'wb') as f_out:
log_out = can.io.ASCWriter(f_out)
for msg in log_in:
log_out.on_message_received(msg)
log_out.stop()
except Exception as e:
print(fr"Fail to convert : code={e}")
# 入出力ファイルのファイル形式を判別してコンバータを選択する
def convert(self, input_pth, output_pth):
# Get input type
input_format = input_pth.split(".")[-1]
# Get output type
output_format = output_pth.split(".")[-1]
# Convert to other can format
if ( (input_format in ["asc"]) and (output_format in ["blf", "BLF"]) ):
self.convert_asc_to_blf(input_pth, output_pth)
elif ( (input_format in ["asc"]) and (output_format in ["mf4", "MF4"]) ):
self.convert_asc_to_mf4(input_pth, output_pth)
elif ( (input_format in ["blf", "BLF"]) and (output_format in ["mf4", "MF4"]) ):
self.convert_blf_to_mf4(input_pth, output_pth)
elif ( (input_format in ["blf", "BLF"]) and (output_format in ["asc"]) ):
self.convert_blf_to_asc(input_pth, output_pth)
elif ( (input_format in ["MF4", "mf4"]) and (output_format in ["blf", "BLF"]) ):
self.convert_mf4_to_blf(input_pth, output_pth)
elif ( (input_format in ["MF4", "mf4"]) and (output_format in ["asc"]) ):
self.convert_mf4_to_asc(input_pth, output_pth)
# Decode & Convert to csv
elif ( (input_format in ["MF4", "mf4"]) and (output_format in ["csv","mat"]) ):
self.convert_mf4_to_csv(input_pth, output_pth)
os.remove("./tmp.blf")
elif ( (input_format in ["asc"]) and (output_format in ["csv","mat"]) ):
self.convert_asc_to_blf(input_pth, "./tmp.blf")
self.convert_blf_to_csv("./tmp.blf", output_pth)
os.remove("./tmp.blf")
elif ( (input_format in ["blf", "BLF"]) and (output_format in ["csv","mat"]) ):
self.convert_blf_to_csv(input_pth, output_pth)
else:
print("Could not get format of input or output path")
if __name__ == "__main__":
dbc_pth = glob(fr"/path/to/dbc")
input_pth = "./output_sample.blf"
can_converter = CANFormatConverter()
#dbcを設定
can_converter.load_and_merge_dbc(dbc_pth)
# ひとまず、blfに変換する
#can_converter.convert(input_pth, "./temp.blf")
# デコードしてcsvにダンプする
can_converter.convert(input_pth, "./sample_output.csv")
今後の改修予定
データをいくつか変換してみましたが、うまく動いてはいます。が、とにかく重い。ChatGPTでC++とかに変換できないかしら。変換後のデータもサイズが大きいのでダウンサンプリングしてもいいでしょうね。
6/15 更新
上記問題があったため、変換が必要な信号のみ変換するモードを追加しました。
デコード対象を必要な信号に絞ったためそれなりの高速化が見込めます。
excelでIDリストを作成の上GUI画面からドラッグ&ドロップで入力ください。
もちろんこれまで通りIDのリストを作成しなくても利用可能です。
お問い合わせ
バグ報告や機能追加のリクエストは、GitHubのIssuesに投稿してください。
詳細な情報や最新の更新については、GitHubリポジトリをご覧ください。