NRQLでJOINを使ってデータを結合し、可視化・分析する方法をご紹介します。
はじめに
NRQL(New Relic Query Language)はNew Relicに収集したデータをいい感じで可視化し、分析するためのクエリ言語です。ビルトインで提供されているUIで十分に分析をすることはできますが、複雑な条件でデータ分析をしたい場合やビルトインのUIではカバーされていないような可視化をしたい場合にはNRQLによる可視化は非常に強力な手段となります。
SQLやその類のクエリ言語を一度でも使ったことある人がどうしてもNRQLでやりたくなってしまうこと、そう、それはサブクエリやJOINです。New Relicはエンドツーエンドでシステム全体から多様なデータを収集するので、時に異なる種類のデータを組み合わせたりしたくなりますがその際にJOINは有効です。
今回は、以下のことが理解できるようにJOINの使い方を紹介します。
- JOINの構文
- 使い方の例
JOINの構文
JOINはイベントデータ(やサブクエリ)同士を結合するためのクエリで、構文としては以下の通りになります。
FROM Event
[INNER|LEFT] JOIN (subquery)
ON [key =] key
SELECT ...
最初のFROMに書かれたEventと、subqueryの結果をJOINしており、ONの後に指定されたkeyがJOINで結合する際のキーになっています。ほぼSQLと同じなのでSQLを使ったことある方はすんなり入ってくるのではないでしょうか。
構文に関する注意点は以下です。
- JOIN句はFROM句のすぐ後にくる必要がある
- 結合の種類はINNER(内部結合)かもしくはLEFT(左外部結合)のみがサポートされています。何も指定されない場合は、INNERとして動きます
- サブクエリを含む括弧、つまり (subquery) の部分はJOIN句のすぐ後に書く必要があります
- ON句はサブクエリの後に続く必要があります
その他にもいくつか制約がありますが詳細は公式ドキュメントを参照してください。
JOINの構文(発展系)
先ほどはシンプルなJOINの構文を紹介しましたが、もう少し複雑な構文もサポートされています。
サブクエリ同士をJOINする
JOINする前に一旦フィルターしたり集計したい場合には左の表もsubqueryにすることができます。
FROM (subquery1)
[INNER|LEFT] JOIN (subquery2)
ON [key =] key
SELECT ...
JOINで3つ以上のサブクエリを結合する。
3つ以上繋げたいケースはそこまでないとは思いますが仕様上は可能です。
FROM Event
[INNER|LEFT] JOIN (
FROM Event
[INNER|LEFT] JOIN (
subquery
)
ON [key =] key
SELECT key, ….
)
ON [key =] key
SELECT ...
では、実際のJOINの使用例を見ていきましょう。
JOINの使用例
例1: KubernetesのコンテナのリソースRequests/Limits合計をノード単位に集計
PodのRequests/Limitsが指定されている場合、その値はK8sContainerSampleというコンテナ単位に保存されるイベントに格納されて取得できるので、その情報をノード単位で確認できることは以下の記事でご紹介しました。
サブクエリだけを使ったクエリ的には以下の通りとなります。
FROM (
FROM K8sContainerSample
SELECT latest(cpuLimitCores) as cpuLimitCores,
latest(cpuRequestedCores) as cpuRequestedCores,
latest(memoryLimitBytes) as memoryLimitBytes,
latest(memoryRequestedBytes) as memoryRequestedBytes
FACET podName, nodeName, clusterName
)
SELECT sum(cpuLimitCores),
sum(cpuRequestedCores),
sum(memoryLimitBytes),
sum(memoryRequestedBytes)
FACET nodeName, clusterName
一方、これをノードのキャパシティに対してどのぐらい締めているか、割合を出したい場合はどうでしょうか?ノードのキャパシティの情報と合わせないといけないので上記のクエリだけでは不十分で、コンテナの情報(K8sContainerSample)とノードの情報(K8sNodeSample)を組み合わせる必要があります。
そこでJOINの出番です。JOINを使うと例えば以下のようなクエリで実現できます。
- 1つ目のサブクエリでは、ノード単位のデータ(K8sNodeSample)からCPU/Memoryのキャパシティをノードごとに取得しています。
- 2つ目のサブクエリでは、コンテナに指定されているRequests/Limitsを取得し、ノード単位に合計(sum)しています。
- そして、それらをJOINし、外側でノードのキャパシティに占める、Requests/Limitsの合計の割合を出すことで、目的のクエリを実現しています。
FROM (
FROM K8sNodeSample
SELECT latest(capacityCpuCores) as capacityCpuCores,
latest(capacityMemoryBytes) as capacityMemoryBytes
FACET nodeName, clusterName
) JOIN (
FROM K8sContainerSample
SELECT latest(cpuLimitCores) as cpuLimitCores,
latest(cpuRequestedCores) as cpuRequestedCores,
latest(memoryLimitBytes) as memoryLimitBytes,
latest(memoryRequestedBytes) as memoryRequestedBytes
FACET podName, nodeName, clusterName
) on nodeName
SELECT 100 * sum(cpuLimitCores)/latest(capacityCpuCores) as 'CPU Limits (%)',
100 * sum(cpuRequestedCores)/latest(capacityCpuCores) as 'CPU Requests (%)',
100 * sum(memoryLimitBytes)/latest(capacityMemoryBytes) as 'Memory Limits (%)%',
100 * sum(memoryRequestedBytes)/latest(capacityMemoryBytes) as 'Memory Requests(%)'
FACET nodeName, clusterName
こんな感じで表示することができます。チャートのオプションを使うと値によって色も変えられます。

いきなり複雑すぎましたね (汗)
例2: スロークエリが発生しているAPIを確認
アプリケーションのどのトランザクション/APIでスロークエリが発生しているかの方法は、以下の記事でご紹介しました。
クエリ的には以下のようになります。これでどのAPIでスロークエリが発生しているかがわかります。
FROM Transaction
SELECT appName, name, traceId
WHERE traceId in (
FROM Span
SELECT trace.id
WHERE category='datastore' and duration > xxxx
)
一方、APIと、発生しているクエリ、どのエンドポイントに対するクエリなのかなど、一緒に見たくないでしょうか?その場合はTransactionとSpanをJOINで結合すると良いです。
例えばこんな感じです。
FROM Transaction
JOIN (
FROM Span
SELECT duration, db.instance, db.statement, traceId
WHERE duration > xxxx and category='datastore'
) ON traceId
SELECT appName, name, duration, db.instance, db.statement
トランザクションの情報とDBクエリに対応したSpanの情報を一緒に出すことができました。
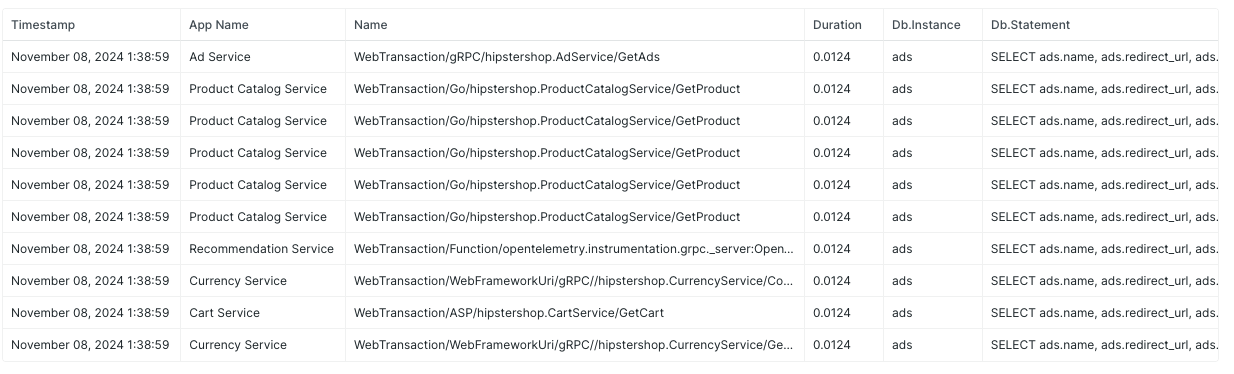
TransactionやSpanデータはサンプリングされるので、全てのスロークエリが抽出されるわけでは無い点は注意が必要です。全体的な傾向を捉えて問題がある場合に詳細を深ぼるという、面から点への分析の流れが良いでしょう。
例3: Lookupテーブル(外部のデータソース)とJOINして値を引っ張る
収集しているデータにはIDなどの記号しか入っておらず、人間が識別可能なラベルに変換したい場合はlookupテーブルが利用できます。lookupテーブルの値をJOINする対象として利用することで、収集したデータをlookupテーブルの値とマッピングさせることができます。
例えば、以下の例では、lookupテーブルに店舗IDと店舗名のマッピングが登録されています。StoreEventには店舗IDしかありませんが、lookupテーブルとJOINすることで店舗IDから店舗名を引いているというカラクリです。
FROM StoreEvent
JOIN (
FROM lookup(storeNames)
SELECT store_ID as storeId, storeName AS name LIMIT 10000
) ON shopId = storeId
SELECT shopId, storeName, totalSales
lookup テーブルの詳細については以下をご参照ください。
以上、いくつかサンプルとともにJOINの使い方をご説明しました。
まとめ
NRQLでサポートされる様々な機能のうちJOINご紹介しました。異なるデータを組み合わせた分析や複雑な分析はビルトインのUIの出番ですが、そこではサポートされていないケースがある場合は是非JOINを使ってみてください。
構文や活用方法の例については公式ブログもご参照ください。
その他
New Relicでは、新しい機能やその活用方法について、QiitaやXで発信しています!
無料でアカウント作成も可能なのでぜひお試しください!
New Relic株式会社のX(旧Twitter) や Qiita OrganizationOrganizationでは、
新機能を含む活用方法を公開していますので、ぜひフォローをお願いします。
無料のアカウントで試してみよう!
New Relic フリープランで始めるオブザーバビリティ!
NRQLマスターになろうシリーズはこちら