目次
- はじめに
- 1. 簡単な例で理解するブロードキャスト
- 2. ブロードキャストのルール
- 3. よく使うブロードキャストのパターン
- 4. 実践的な応用例
- 5. 機械学習での活用
- 6. 注意点とよくある間違い
- まとめと次のステップ
はじめに
こんなコードを書いて、エラーに悩まされた経験はありませんか?
import numpy as np
# 2x2の行列とベクトルの足し算
matrix = np.array([[1, 2],
[3, 4]])
vector = np.array([10, 20])
result = matrix + vector # ValueError: operands could not be broadcast together!
「行列とベクトルの計算がうまくいかない」
「配列の形が違うとエラーになってしまう」
「もっと簡単に書く方法はないのかな」
そんな時は、NumPyのブロードキャスト(Broadcasting)機能を使えば解決できます。
ブロードキャストとは、異なる形状の配列間で演算を行うとき、NumPyが自動的に配列の形を調整してくれる機能です。この機能を使いこなすと、次のようなメリットがあります:
- 複雑なループ処理が簡単な演算子で書ける
- 処理が高速になる
- メモリ効率も良い
特に機械学習や科学技術計算では必須の機能といえるでしょう。
この記事では、ブロードキャストの使い方を基本から応用まで、具体例をたっぷり使って解説します。
- 基本的な使い方から丁寧に説明
- 実践的な例題で感覚をつかむ
- 機械学習での活用例も紹介
それでは、具体的な例を見ながら、ブロードキャストの仕組みを理解していきましょう。
1. 簡単な例で理解するブロードキャスト
ブロードキャストの基本概念
ブロードキャストとは、サイズや形状が異なる配列間の演算を可能にする仕組みです。通常、行列計算ではサイズを合わせる必要がありますが、NumPyではある条件下で異なるサイズの配列間でも計算できます。
簡単に言えば「小さい配列を自動的に拡張して大きい配列と同じ形にしてから計算する」機能で、ループを書かずに効率的な配列演算が可能になります。
スカラーと配列の演算
一番シンプルな例として、スカラー値(単一の数値)と配列の演算を見てみましょう。
import numpy as np
# 1次元配列を作成
arr = np.array([1, 2, 3, 4, 5])
# スカラー値との演算
print(arr + 10) # [11 12 13 14 15]
print(arr * 2) # [2 4 6 8 10]
print(arr / 2) # [0.5 1. 1.5 2. 2.5]
内部的には、10が[10, 10, 10, 10, 10]にブロードキャストされてから計算されています。実際にメモリ上で配列が作られるわけではありませんが、概念的にはこのようなイメージです。
異なる次元の配列間の演算例
もう少し複雑な例として、1次元配列と2次元配列の演算を見てみましょう。
# 2次元配列(3x4行列)
matrix = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
])
# 1次元配列(長さ4のベクトル)
vector = np.array([10, 20, 30, 40])
# 行列とベクトルの足し算
result = matrix + vector
print(result)
結果:
[[11 22 33 44]
[15 26 37 48]
[19 30 41 52]]
ここでNumPyはvectorを行方向に3回複製したかのように計算します:
[1, 2, 3, 4] [10, 20, 30, 40] [11, 22, 33, 44]
[5, 6, 7, 8] + [10, 20, 30, 40] = [15, 26, 37, 48]
[9, 10, 11, 12] [10, 20, 30, 40] [19, 30, 41, 52]
この拡張は実際のメモリ上で行われるわけではなく、NumPyは内部的なインデックス操作で効率的に計算します。
2. ブロードキャストのルール
NumPyのブロードキャストには、3つの基本ルールがあります。これらを理解すれば、どの配列の組み合わせでブロードキャストが可能かを判断できるようになります。
ルール1: 次元数を整える
1つ目のルールは、次元数が少ない配列の形状の先頭に1を追加して、両配列の次元数を整えるというものです。
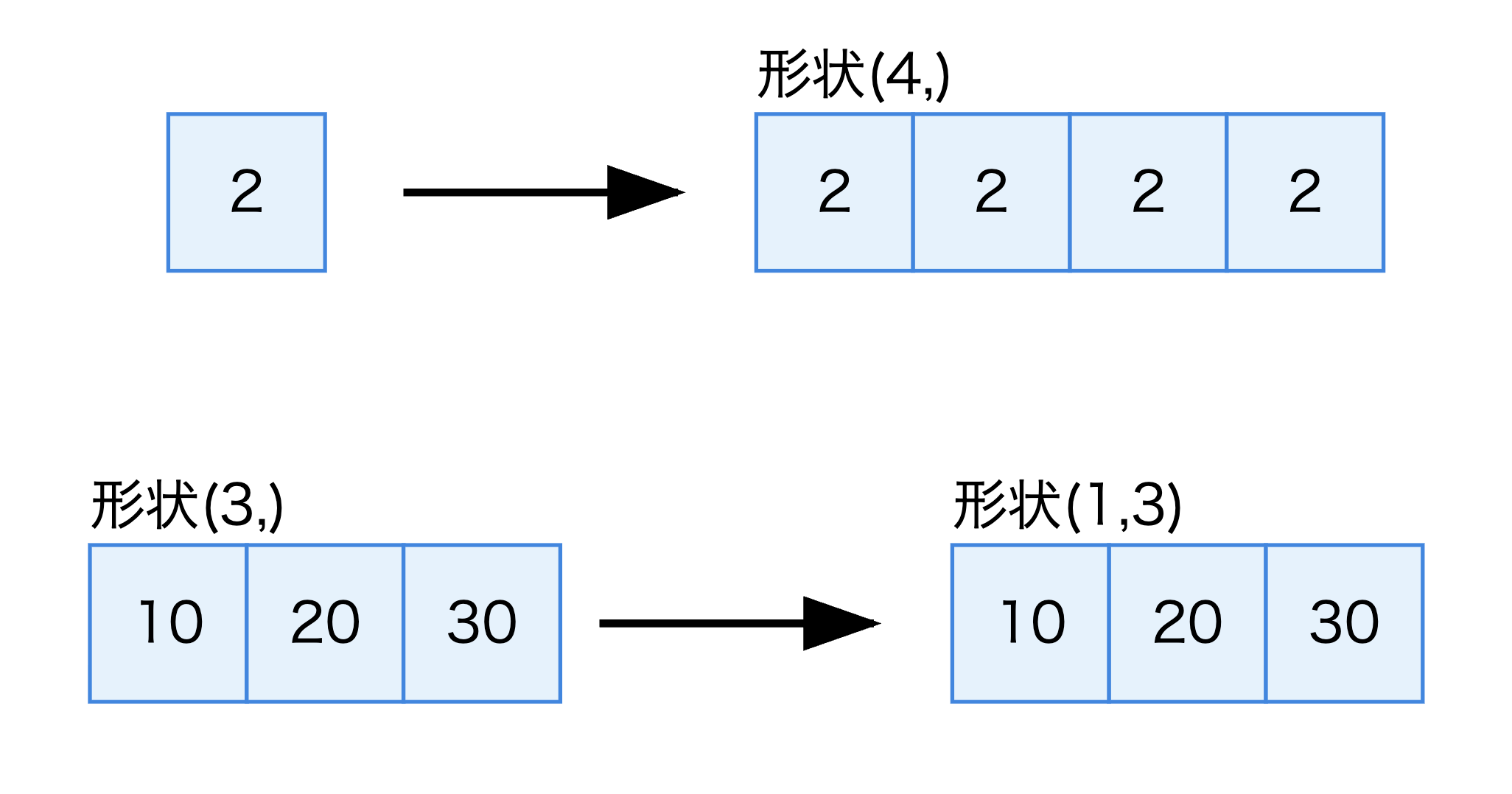
例えば、スカラー値(0次元配列)と1次元配列の演算では、スカラー値が1次元配列に拡張されます。
import numpy as np
# スカラーと配列の演算
a = np.array([1, 2, 3, 4]) # 形状: (4,)
b = 2 # スカラー値
result = a + b # 結果の形状: (4,)
print(result) # [3 4 5 6]
ここでスカラー値2は内部的に形状(1,)の配列として扱われ、さらにルール2によって(4,)に拡張されます。
同様に、1次元配列と2次元配列の演算では、1次元配列に新しい次元が追加されます。
# 1次元配列と2次元配列
a = np.array([[1, 2, 3], [4, 5, 6]]) # 形状: (2, 3)
b = np.array([10, 20, 30]) # 形状: (3,)
result = a + b # 結果の形状: (2, 3)
print(result)
# [[11 22 33]
# [14 25 36]]
この例では、bはまずルール1によって形状(1, 3)に変換され、続いてルール2によって(2, 3)に拡張されます。
ルール2: サイズ1の次元の拡張
2つ目のルールは、サイズが1の次元は、他方の配列の対応する次元のサイズに合わせて拡張されるというものです。
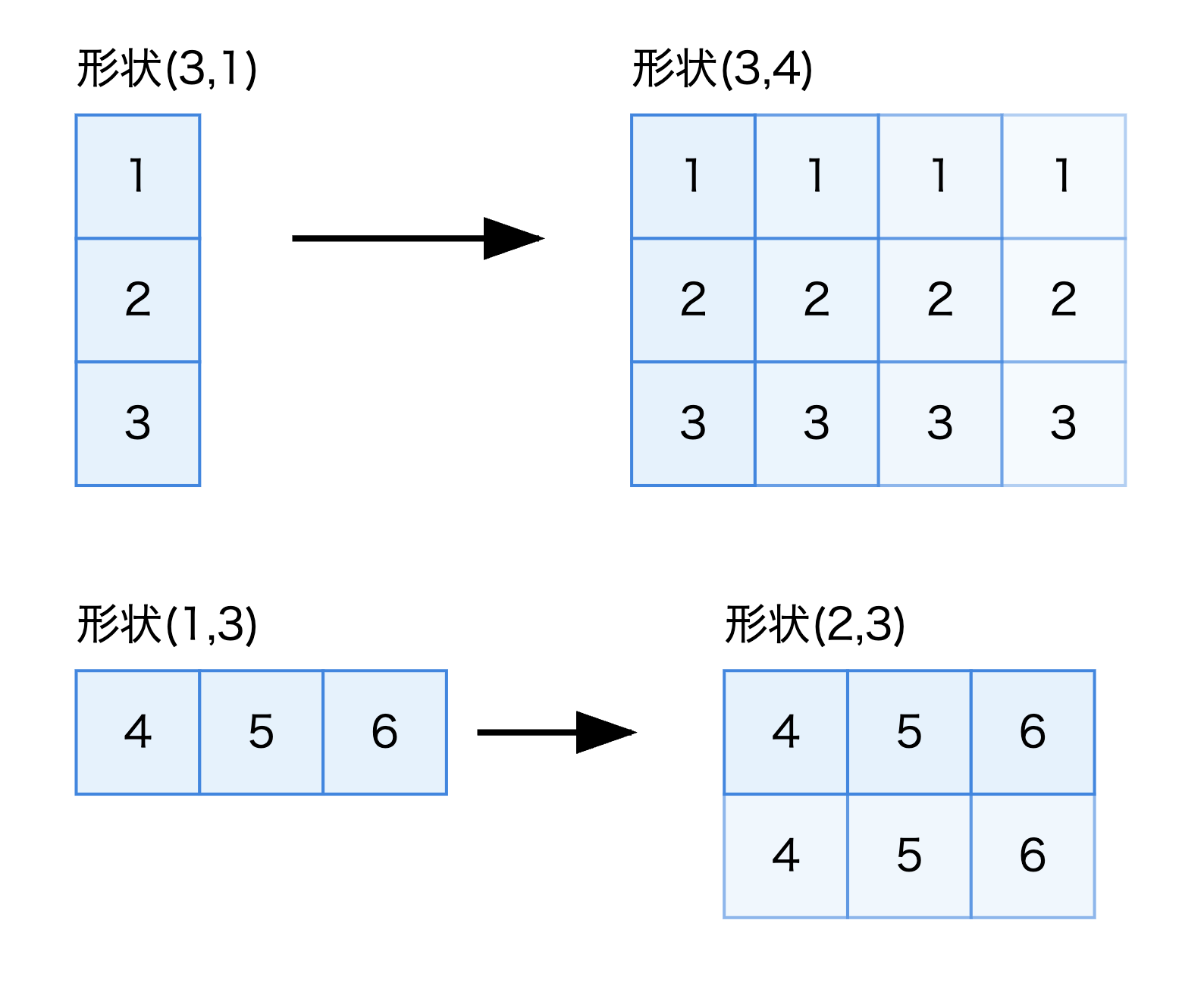
例えば、形状(3, 1)の配列(列ベクトル)と形状(3, 4)の配列の演算を考えてみましょう。
# サイズ1の次元の拡張例
a = np.array([[1], [2], [3]]) # 形状: (3, 1)
b = np.array([[10, 20, 30, 40],
[50, 60, 70, 80],
[90, 100, 110, 120]]) # 形状: (3, 4)
result = a + b # 結果の形状: (3, 4)
print(result)
# [[ 11 21 31 41]
# [ 52 62 72 82]
# [ 93 103 113 123]]
ここでaの2番目の次元(列)がサイズ1なので、ブロードキャストによってbの2番目の次元のサイズ4に合わせて拡張されます。
また、形状(1, 3)の配列(行ベクトル)と形状(2, 3)の配列の演算も見てみましょう。
# 行ベクトルの拡張例
a = np.array([[4, 5, 6]]) # 形状: (1, 3)
b = np.array([[100, 200, 300],
[400, 500, 600]]) # 形状: (2, 3)
result = a + b # 結果の形状: (2, 3)
print(result)
# [[104 205 306]
# [404 505 606]]
この場合、aの1番目の次元(行)がサイズ1なので、bの1番目の次元のサイズ2に合わせて拡張されます。
重要なのは、NumPyは実際にはこの「拡張」の際にメモリ上で配列のコピーを作成せず、計算時に必要な要素を繰り返し参照することで効率的に処理を行います。
ルール3: サイズの互換性
3つ目のルールは、対応する次元のサイズがどちらも1でない場合、同じサイズである必要があるというものです。
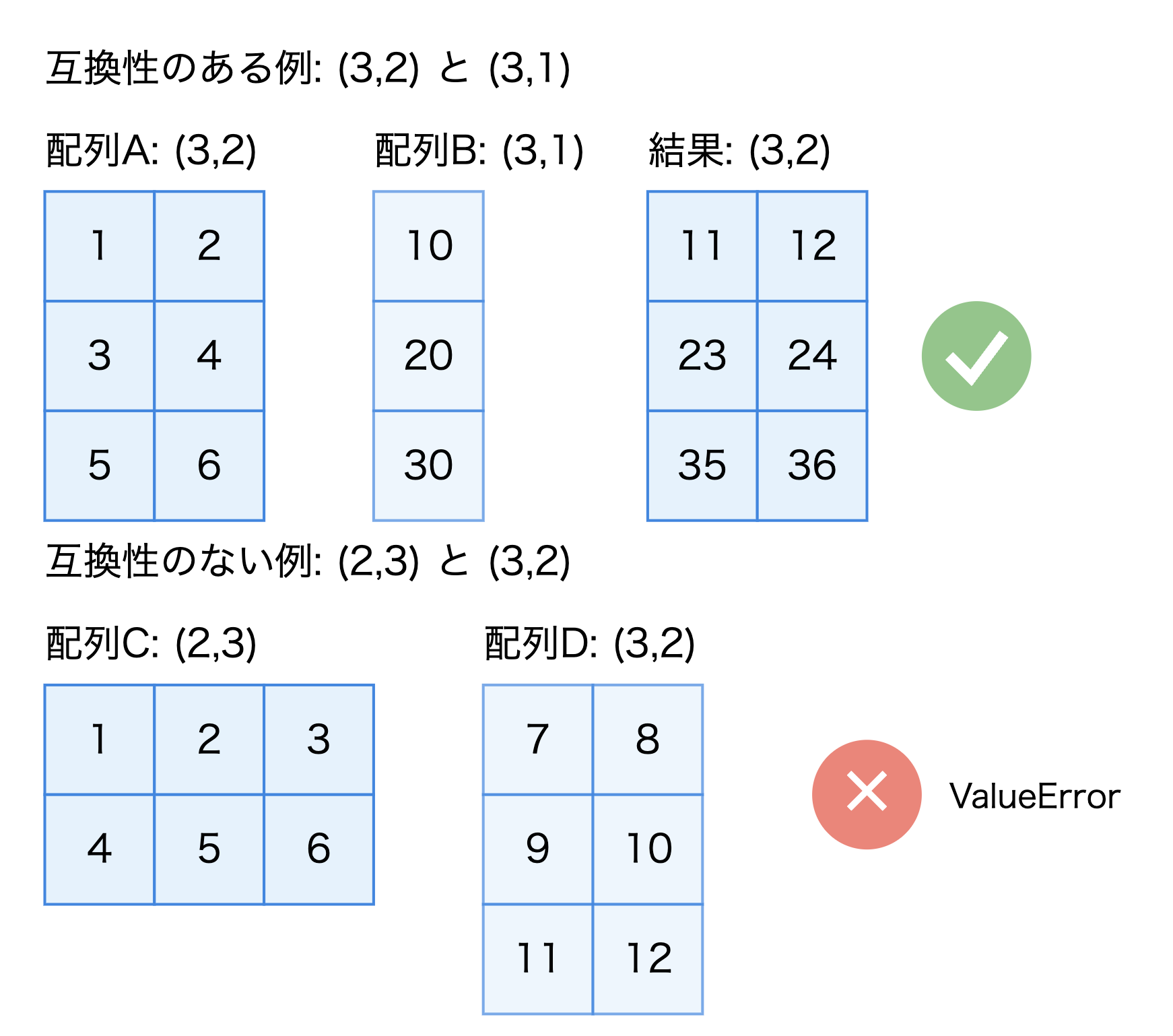
具体的な例を見てみましょう。形状(3, 2)の配列と形状(3, 1)の配列は互換性がありますが、形状(2, 3)の配列と形状(3, 2)の配列は互換性がありません。
import numpy as np
# 互換性のある例
a = np.array([[1, 2], [3, 4], [5, 6]]) # 形状: (3, 2)
b = np.array([[10], [20], [30]]) # 形状: (3, 1)
result = a + b # 結果の形状: (3, 2)
print(result)
# [[11 12]
# [23 24]
# [35 36]]
# 互換性のない例
c = np.array([[1, 2, 3], [4, 5, 6]]) # 形状: (2, 3)
d = np.array([[7, 8], [9, 10], [11, 12]]) # 形状: (3, 2)
try:
result = c + d
except ValueError as e:
print(f"エラー: {e}")
# エラー: operands could not be broadcast together with shapes (2,3) (3,2)
エラーメッセージから、互換性のない形状同士の演算を行おうとしたことがわかります。このようなエラーが発生した場合は、配列の形状を確認し、必要に応じて転置(.T)や次元の追加(np.newaxis)などの操作で形状を調整しましょう。
ルールの確認問題
以下の形状の配列の組み合わせがブロードキャスト可能かどうか考えてみましょう。
-
(2, 3)と(3,) -
(4, 1)と(1, 5) -
(3, 4)と(2, 1) -
(2, 3, 4)と(3, 4)
解答:
-
(2, 3)と(3,)→ 可能-
(3,)はルール1により(1, 3)となり、ルール2により(2, 3)に拡張される
-
-
(4, 1)と(1, 5)→ 可能-
(4, 1)の2次元目と(1, 5)の1次元目はサイズ1のためルール2により拡張され、結果は(4, 5)となる
-
-
(3, 4)と(2, 1)→ 不可能- 1次元目が
3と2で異なり、どちらもサイズ1ではないためルール3に違反する
- 1次元目が
-
(2, 3, 4)と(3, 4)→ 可能-
(3, 4)はルール1により(1, 3, 4)となり、ルール2により(2, 3, 4)に拡張される
-
自分でルールを適用して確認する練習をすると、ブロードキャストの挙動を理解するのに役立ちます。不明な場合は np.broadcast_shapes 関数を使って、複数の形状がブロードキャストされた後の形状を確認できます。
import numpy as np
# ブロードキャスト後の形状を確認
result_shape = np.broadcast_shapes((4, 1), (1, 5))
print(f"ブロードキャスト後の形状: {result_shape}") # ブロードキャスト後の形状: (4, 5)
# 互換性のない形状の場合はエラーになる
try:
result_shape = np.broadcast_shapes((3, 4), (2, 1))
except ValueError as e:
print(f"エラー: {e}") # エラー: shape mismatch: objects cannot be broadcast to a single shape
実際にコード例を自分で試してみると、エラーメッセージが出る条件や、正しい結果が得られる条件がより明確になるでしょう。
3. よく使うブロードキャストのパターン
ブロードキャストのルールを理解したところで、実践的によく使われるパターンを紹介します。これらのパターンを習得すれば、効率的なNumPyコードが書けるようになります。
配列の変形テクニック
ブロードキャストを効果的に使うには、配列の形状を適切に変更する必要があります。主要な変形テクニックを見ていきましょう。
1. 次元の追加 (np.newaxis / None)
import numpy as np
# 1次元配列
a = np.array([1, 2, 3, 4])
# 列ベクトルに変形 (4,) → (4,1)
col_vector = a[:, np.newaxis]
# または col_vector = a[:, None]
# または col_vector = a.reshape(-1, 1)
print(a.shape) # (4,)
print(col_vector.shape) # (4, 1)
print(col_vector)
# [[1]
# [2]
# [3]
# [4]]
# 行ベクトルに変形 (4,) → (1,4)
row_vector = a[np.newaxis, :]
# または row_vector = a[None, :]
# または row_vector = a.reshape(1, -1)
print(row_vector.shape) # (1, 4)
print(row_vector) # [[1 2 3 4]]
2. reshape関数による変形
# (4,) → (2,2)
matrix = a.reshape(2, 2)
print(matrix)
# [[1 2]
# [3 4]]
# -1を使うと自動的にサイズが決まる
# (4,) → (2,2)
matrix_auto = a.reshape(2, -1)
print(matrix_auto)
# [[1 2]
# [3 4]]
典型的なパターン集
よく使われるブロードキャストのパターンを紹介します。
1. 行ごと・列ごとの操作
各行または各列に同じ操作を適用する場合の例です。
# 3x4行列
matrix = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
])
# 各行から定数を引く(行ごとの操作)
row_means = np.array([3, 6, 9]) # 各行の平均値と仮定
row_centered = matrix - row_means[:, np.newaxis] # または row_means[:, None]
print(row_centered)
# [[-2 -1 0 1]
# [-1 0 1 2]
# [ 0 1 2 3]]
# 各列に定数を掛ける(列ごとの操作)
col_factors = np.array([10, 100, 1000, 10000])
col_scaled = matrix * col_factors
print(col_scaled)
# [[ 10 200 3000 40000]
# [ 50 600 7000 80000]
# [ 90 1000 11000 120000]]
2. グリッド生成
x座標とy座標から2次元グリッドを生成する例です。
# x座標とy座標
x = np.array([1, 2, 3, 4])
y = np.array([10, 20, 30])
# 2次元グリッド生成
# xを行方向、yを列方向に展開
grid = x[np.newaxis, :] + y[:, np.newaxis]
print(grid)
# [[11 12 13 14]
# [21 22 23 24]
# [31 32 33 34]]
# より簡単な方法(meshgrid関数)
X, Y = np.meshgrid(x, y)
grid2 = X + Y
print(grid2) # grid と同じ結果
3. バッチ処理での活用
機械学習でよく使われるバッチ処理での例です。
# バッチデータ(3サンプル x 4特徴量)
batch = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
])
# 特徴量ごとの平均と標準偏差
feature_means = np.array([5, 6, 7, 8])
feature_stds = np.array([2, 2, 2, 2])
# 標準化(各特徴量を平均0、標準偏差1に)
normalized = (batch - feature_means) / feature_stds
print(normalized)
# [[-2. -2. -2. -2. ]
# [ 0. 0. 0. 0. ]
# [ 2. 2. 2. 2. ]]
これは機械学習の前処理でよく行われる標準化の例です。各特徴量の平均を引いて標準偏差で割ることで、異なる単位やスケールの特徴量を統一的に扱えるようになります。
4. 実践的な応用例
ブロードキャストは理論だけでなく、実際の現場でも大いに役立ちます。特に有益な応用例を見ていきましょう。
画像処理での活用
デジタル画像は多次元配列(グレースケールなら2次元、カラー画像なら3次元)で表現されるため、ブロードキャストとの相性が抜群です。
例えば写真編集では、明るさ調整(全ピクセルに値を加算)、コントラスト調整(係数をかける)、カラーバランス調整(RGB各チャンネルに異なる係数を適用)などがあります。
画像認識の前処理でも、複数画像の一括正規化にブロードキャストが使われています。
気象データの分析
気象データは典型的な多次元データ(時間×地点×観測項目)です。各地点の平年値との気温差や季節変動の除去、異常気象の検出などに利用できます。
例えば全国1000地点の10年分の月別データがあっても、各地点の平均からの偏差計算が一行で完了します。気候変動研究では、このような膨大なデータの効率的な処理が不可欠です。
機械学習での前処理
機械学習では特徴量の標準化(平均0、標準偏差1に変換)が重要な前処理です。身長・体重・年齢などスケールの異なる特徴量を持つデータセットでは、各特徴量の平均と標準偏差で割る処理をしますが、ブロードキャストを使えば全サンプル・全特徴量を一度に変換できます。
特にミニバッチ学習など、複数サンプルの一括処理では必須のテクニックになっています。深層学習のモデル比較やハイパーパラメータ調整の際にも効率化に貢献します。
5. 機械学習での活用
ブロードキャストは機械学習の様々な場面で活躍します。ここでは、機械学習特有のブロードキャスト活用例を見ていきましょう。
データの前処理
機械学習では、生データをモデルに入力する前に様々な前処理を施します。ブロードキャストはこれらの処理を効率化します。
特徴量のスケーリング
特徴量のスケールを揃えることは、多くの機械学習アルゴリズムで重要です。標準化(Z-score正規化)や正規化(Min-Max正規化)は代表的な手法です。
例えば標準化では、各特徴量を平均0、標準偏差1に変換します。
標準化データ = (元データ - 平均) / 標準偏差
この計算は特徴量ごとに異なる平均・標準偏差を使うため、ブロードキャストが効果的です。データが1000サンプル×50特徴量の場合でも、一行で計算できます。
欠損値の補完
欠損値を特徴量ごとの平均や中央値で埋める場合も、ブロードキャストが役立ちます。各特徴量の代表値を計算し、欠損箇所だけを選択的に埋めることができます。
バッチ処理での利用
深層学習では、計算効率化のために複数サンプルをまとめて処理するバッチ処理が一般的です。ここでもブロードキャストが重要な役割を果たします。
ミニバッチ勾配降下法
ミニバッチ勾配降下法では、複数サンプルの勾配を同時に計算します。例えば以下のような処理がブロードキャストを使って効率化できます:
- バッチ内の全サンプルに対する予測計算
- 予測値と正解ラベルの差分計算
- 勾配の集計と重みの更新
データ拡張(Data Augmentation)
画像認識タスクでは、学習データを人工的に増やすデータ拡張がよく使われます。複数画像に対して同時に:
- ランダムな明るさ調整
- ランダムなコントラスト調整
- チャンネルごとの色調変更
などをブロードキャストを使って効率的に適用できます。
ニューラルネットワークでの計算
ニューラルネットワークの順伝播(forward propagation)と逆伝播(back propagation)計算でもブロードキャストは大活躍します。
全結合層(Dense Layer)の計算
全結合層での計算は本質的に行列演算ですが、バイアス項の加算ではブロードキャストが使われます:
出力 = 入力 @ 重み + バイアス
この「+ バイアス」の部分で、バイアスベクトルがバッチ内の全サンプルに対してブロードキャストされます。
バッチ正規化(Batch Normalization)
バッチ正規化は、ニューラルネットワークの学習を安定化・高速化するテクニックです。各層の出力を正規化する際に、チャンネルごと(または特徴量ごと)に異なるパラメータを使用します。この処理もブロードキャストを活用しています。
アテンション機構
Transformerなどで使われるアテンション機構では、クエリ・キー・バリューの間の類似度計算や、アテンションスコアの適用でブロードキャストが使われます。特に異なる長さのシーケンス間の計算でブロードキャストは威力を発揮します。
機械学習におけるブロードキャストの重要性は、モデルが複雑になるほど高まります。特に大規模データセットや深層モデルでは、効率的な計算の鍵となります。ブロードキャストを理解して使いこなすことで、より洗練されたモデル実装が可能になるでしょう。
6. 注意点とよくある間違い
ブロードキャストは強力な機能ですが、使い方を誤るとバグの原因になったり、パフォーマンスが低下したりすることがあります。ここでは、ブロードキャスト使用時の注意点とよくある間違いについて解説します。
形状の互換性エラー
最もよく遭遇するのが、形状が互換性のない配列間でブロードキャストを行おうとしたときのエラーです。
ValueError: operands could not be broadcast together with shapes (3,4) (5,)
このようなエラーが発生したら、両方の配列の形状を確認し、ブロードキャストのルールに従っているかチェックしましょう。
よくある間違い:
- 配列の次元順序を間違える(例:画像データでチャンネル×高さ×幅を高さ×幅×チャンネルと間違える)
- 行と列を取り違える(転置が必要な場合がある)
- 次元の追加場所を間違える(先頭に追加すべきところを末尾に追加するなど)
解決策:
-
array.shapeで形状を確認する - 必要に応じて
np.newaxisやreshapeで形状を変更する - 複雑な場合は紙に図を描いて次元を確認する
メモリ使用量の注意点
ブロードキャストの利点の一つは、実際にデータをコピーせずに演算ができることです。しかし、結果の配列は展開後の大きなサイズになることに注意が必要です。
注意が必要なケース:
- 小さな配列と非常に大きな配列のブロードキャスト演算
- ブロードキャスト結果の保存(一時的なメモリ使用量が増加)
- 複数の大きな多次元配列間のブロードキャスト
対策:
- 結果の配列サイズを事前に計算し、メモリ制約内に収まるか確認する
- 必要に応じて計算を小さなブロックに分割する
- メモリプロファイリングツールを使って使用量をモニターする
意図しないブロードキャスト
時に意図せずブロードキャストが発生し、気づきにくいバグになることがあります。
# 意図: 行ごとの合計を計算
# 実際: 全ての要素の合計が各行に適用される
row_sums = np.sum(data) # スカラー値になる
normalized = data / row_sums # 意図しないブロードキャスト
よくある間違い:
- 集計関数(sum, mean, max など)使用時に軸を指定し忘れる
- 形状の異なる配列を連結しようとする
- 行列演算(@)とブロードキャスト演算(*)を混同する
対策:
- 演算前後で配列の形状を確認する習慣をつける
- 複雑な計算では中間結果の形状も確認する
- コメントで意図した形状を明記する
トラブルシューティング
ブロードキャスト関連の問題に遭遇したら、以下のアプローチが役立ちます。
1. 形状の確認
まず、関連する全ての配列の形状を確認します:
print("配列1の形状:", array1.shape)
print("配列2の形状:", array2.shape)
print("結果の形状:", result.shape)
2. 小さなデータでテスト
問題が複雑な場合は、小さなサンプルデータで動作を確認します:
# 単純化したテストケース
small_array1 = np.array([[1, 2], [3, 4]])
small_array2 = np.array([10, 20])
test_result = small_array1 + small_array2
print(test_result)
3. 明示的な変形
ブロードキャストに頼らず、明示的に配列を変形することで問題を解決できることもあります:
# ブロードキャストの代わりに明示的に拡張
expanded_array2 = np.tile(array2, (array1.shape[0], 1))
result = array1 + expanded_array2
4. 次元の追加位置を調整
ブロードキャストの動作を変えるために、次元を追加する位置を調整します:
# 次元の追加位置を変更
array2_column = array2[:, np.newaxis] # 列ベクトル化
array2_row = array2[np.newaxis, :] # 行ベクトル化
ブロードキャストはNumPyの強力な機能ですが、正しく使うためには形状の概念をしっかり理解し、常に配列の形状を意識することが重要です。問題に直面したときは冷静に各配列の形状を確認し、ブロードキャストのルールに立ち返って考えてみましょう。
まとめと次のステップ
学んだことの振り返り
この記事では、NumPyのブロードキャスト機能について解説しました:
- 異なるサイズの配列間で自動的に次元を拡張する仕組み
- 次元を揃え、サイズ1の次元を拡張するというシンプルなルール
- 画像処理、気象データ分析、機械学習などでの実践的な活用法
- メモリ効率や計算速度を向上させる重要な機能
ブロードキャストをマスターすることで、効率的かつ読みやすいNumPyコードが書けるようになります。
練習問題
問題1: 基本的なブロードキャスト
以下の演算の結果として得られる配列の形状と値を予測してください。
A = np.array([1, 2, 3])
B = np.array([[10], [20], [30]])
C = A + B
問題2: 形状の互換性
次の配列のうち、互いにブロードキャスト可能な組み合わせをすべて選んでください。
A = np.zeros((3, 4))
B = np.zeros((3, 1))
C = np.zeros((4,))
D = np.zeros((1, 4))
問題3: スカラーとベクトルの演算
以下のコードの出力結果を予測してください。
x = np.array([1, 2, 3, 4])
y = 10
z = x * y
print(z)
解答:
問題1の解答
# 形状: (3, 3)
# 値:
# [[11 12 13]
# [21 22 23]
# [31 32 33]]
問題2の解答
ブロードキャスト可能な組み合わせ:
- A と B(結果の形状: (3, 4))
- A と D(結果の形状: (3, 4))
- B と D(結果の形状: (3, 4))
- C と A(結果の形状: (3, 4))
- C と D(結果の形状: (1, 4))
問題3の解答
# 出力: [10 20 30 40]
よくある質問(FAQ)
Q: ブロードキャストは遅くないですか?
A: むしろ逆です。ブロードキャストは内部的に最適化されており、Pythonのループを使うよりも大幅に高速です。実際のデータをコピーすることなく演算が行われるため、メモリ効率も良いです。
Q: ブロードキャストとreshapeの違いは何ですか?
A: reshapeは配列の形状を明示的に変更し、要素数は変わりません。一方、ブロードキャストは演算時に暗黙的に形状を拡張する機能で、実際にはデータをコピーしません。
Q: 大きな配列でブロードキャストを使う際の注意点は?
A: 結果の配列サイズが非常に大きくなる場合があるため、メモリ使用量に注意が必要です。特に小さな配列と巨大な配列の演算では、結果のサイズを事前に確認しましょう。
Q: ブロードキャストのデバッグのコツは?
A: 各配列の.shape属性を常に確認することが基本です。複雑な操作の前後で形状を出力して確認する習慣をつけましょう。小さなテストケースで動作を検証することも有効です。
次に学ぶべきトピック
ブロードキャストの基本を理解したら、以下のトピックに進むと良いでしょう:
- 高度な配列操作 - ファンシーインデキシング、ストライド操作、ビューとコピー
- ベクトル化関数 - NumPyのユニバーサル関数(ufunc)、カスタムufuncの作成
- パフォーマンス最適化 - メモリレイアウトの最適化、キャッシュフレンドリーな操作
- 科学計算ライブラリとの連携 - SciPy、Pandas、Scikit-learn
参考資料
- NumPy公式ドキュメント - ブロードキャスト
- Jake VanderPlas著「Python Data Science Handbook」
- SciPy Lectures - NumPyの高度な操作
以上でNumPyのブロードキャスト機能についての解説を終わります。この記事が皆さんのNumPyへの理解を深め、効率的なコードを書く手助けになれば幸いです。質問やフィードバックがあれば、コメント欄でお待ちしています。
P.S.
この記事は部分的にClaude 3.7 Sonnetを使って書かれています。
内容チェックはしたつもりですが、間違い等ありましたら、遠慮なくコメントいただけると助かります!
完全にAIに任せて書くことは難しかったため、AIとの共同作業(仮)のような形で執筆しました。この記事を執筆する中でのAI活用について、詳しくは別の記事にして公開したいと思っています。
ネタ決めや項目決めは、やっぱり人間の判断になりましたが、細かい文章構成はAIに任せることができました。その結果、すごく時短することができ、この分量の記事でも3時間で書くことができました。昔は丸1日の作業だったのに...懐かしいですね〜