はじめに
ただいまグラフ埋め込みを勉強中なので、Neo4jのグラフデータサイエンスのグラフ埋め込みのチュートリアルを頑張りたいと思います!
Neo4jのサイトをGoogle翻訳で変換しつつ進める過程で、つまづいたところ、よくわからなかったところ等の備忘録も兼ねております。
この記事がどなたかのお役に立つ日が来れば嬉しいです😆
※初学者なりに理解した内容ですので温かい目で見守ってください。
目次
- チュートリアルについて
- チュートリアルを始める前の準備
- グラフ埋め込みとは
- チュートリアルをやっていく
- まとめ
チュートリアルについて
こちらのチュートリアルを行なっていきます。
このチュートリアルは、Neo4jのデータサイエンスライブラリのnode2Vecでグラフ埋め込みを行うことを目標としています。
チュートリアルを始める前に
始めるには、PythonのインストールとNeo4j (バージョン 4.0 以降)をダウンロードしてインストールする必要があります。
前回と前々回の記事でJupyterNotebookのインストールとデスクトップ版Neo4jのインストールをしました。ぜひ参考にしてみてください!
グラフ埋め込みとは
私自身もまだ深く理解できておりません…
ここに書いても恥ずかしくないくらいに理解ができたら追記します!
チュートリアルをやっていく
デスクトップ版Neo4jを立ち上げて新しいプロジェクトを作成しておきます。
立ち上げる際に設定するパスワードは後で使うので必ずメモしておきましょう!!!
データセットの読み込み
このチュートリアルではヨーロッパの道路のデータセットを用いています。
39カ国の894町を結ぶ1250の道路についてのデータセットです。
それでは、Neo4jにてデータセットの読み込みを行うために以下を実行します。
CREATE CONSTRAINT places IF NOT EXISTS FOR (p:Place) REQUIRE p.name IS UNIQUE;
CREATE CONSTRAINT countries IF NOT EXISTS FOR (c:Country) REQUIRE c.code IS UNIQUE;
LOAD CSV WITH HEADERS FROM "https://github.com/neo4j-examples/graph-embeddings/raw/main/data/roads.csv"
AS row
MERGE (origin:Place {name: row.origin_reference_place})
SET origin.countryCode = row.origin_country_code
MERGE (destination:Place {name: row.destination_reference_place})
SET destination.countryCode = row.destination_country_code
MERGE (c_origin:Country {code: row.origin_country_code})
MERGE (c_destination:Country {code: row.destination_country_code})
MERGE (origin)-[eroad:EROAD {number: row.road_number}]->(destination)
SET eroad.distance = toInteger(row.distance), eroad.watercrossing = row.watercrossing
MERGE (origin)-[:IN_COUNTRY]->(c_origin)
MERGE (destination)-[:IN_COUNTRY]->(c_destination);
最初のCREATE CONSTRAINTの2文が、大元のチュートリアルでは、
CREATE CONSTRAINT places IF NOT EXISTS ON (p:Place) ASSERT p.name IS UNIQUE;
CREATE CONSTRAINT countries IF NOT EXISTS ON (c:Country) ASSERT c.code IS UNIQUE;
となっていますがこの記述では動かなかったので変えてあります。
以下のクエリを実行すると、作成したヨーロッパの道路のグラフデータのスキーマを出力してくれます。
CALL db.schema.visualization()
結果

グラフ埋め込みの実行
こちらのセクションにて行なっていることについても、
ここに書いても恥ずかしくないくらいに理解ができたら随時追記していきます…
まずは以下を実行します。
CALL gds.graph.project(
'places_undir',
'Place',
{EROAD: {orientation: 'UNDIRECTED'}}
)
次に
CALL gds.fastRP.stream('places_undir',
{
embeddingDimension: 10
}
)
YIELD nodeId, embedding
RETURN gds.util.asNode(nodeId).name AS place, embedding
LIMIT 5
実行結果
| Place | embedding |
|---|---|
| "Larne" | [0.5786177515983582,-0.4012638330459595,-0.16752511262893677,-0.7087218761444092, 0.37056204676628113,-0.9627646803855896,-0.17660734057426453, 0.5529423356056213, -0.1881837546825409, 0.20178654789924622] |
| "Belfast" | [0.5153923034667969, -0.22510990500450134, -0.199273020029068, -0.6573874354362488, 0.2203015387058258, -1.0398733615875244, -0.19496142864227295, 0.49318426847457886, -0.024694180116057396, 0.08109953254461288] |
| "Dublin" | [0.19724464416503906, -0.21975931525230408, 0.019983142614364624, -0.5070462822914124, 0.13303154706954956, -0.8911266326904297, -0.278847873210907, 0.6584466695785522, -0.21137264370918274, -0.22576412558555603] |
次に
CALL gds.fastRP.write(
'places_undir',
{
embeddingDimension: 256,
writeProperty: 'embedding'
}
);
グラフ埋め込みの視覚化
ここからはPythonを用いて、Neo4j側で作成したグラフ埋め込みを視覚化していく。
またまた、こちらのセクションにて行なっていることについても
ここに書いても恥ずかしくないくらいに理解ができたら随時追記していきます…
パッケージのインポート
from neo4j import GraphDatabase
from sklearn.manifold import TSNE
import numpy as np
import altair as alt
import pandas as pd
先ほどのNeo4j環境と繋げる
class Neo4jConnection:
def __init__(self, uri, user, pwd):
self.__uri = uri
self.__user = user
self.__pwd = pwd
self.__driver = None
try:
self.__driver = GraphDatabase.driver(self.__uri, auth=(self.__user, self.__pwd))
except Exception as e:
print("Failed to create the driver:", e)
def close(self):
if self.__driver is not None:
self.__driver.close()
def query(self, query, parameters=None, db=None):
assert self.__driver is not None, "Driver not initialized!"
session = None
response = None
try:
session = self.__driver.session(database=db) if db is not None else self.__driver.session()
response = list(session.run(query, parameters))
except Exception as e:
print("Query failed:", e)
finally:
if session is not None:
session.close()
return response
uri = ''
pwd = ''
conn = Neo4jConnection(uri=uri, user="neo4j", pwd=pwd)
conn.query('MATCH (n) RETURN COUNT(n) AS count')
作成してあるリレーションをPython側に持ってくる
query = '''MATCH (p:Place)-[:IN_COUNTRY]->(country)
WHERE country.code IN ["E", "GB", "F", "TR", "I", "D", "GR"]
RETURN p.name AS place, p.embedding AS embedding, country.code AS country
'''
df = pd.DataFrame([dict(_) for _ in conn.query(query)])
df.head()
X,y座標の取得
X_embedded = TSNE(n_components=2, random_state=6).fit_transform(list(df.embedding))
places = df.place
tsne_df = pd.DataFrame(data = {
"place": places,
"country": df.country,
"x": [value[0] for value in X_embedded],
"y": [value[1] for value in X_embedded]
})
tsne_df.head()
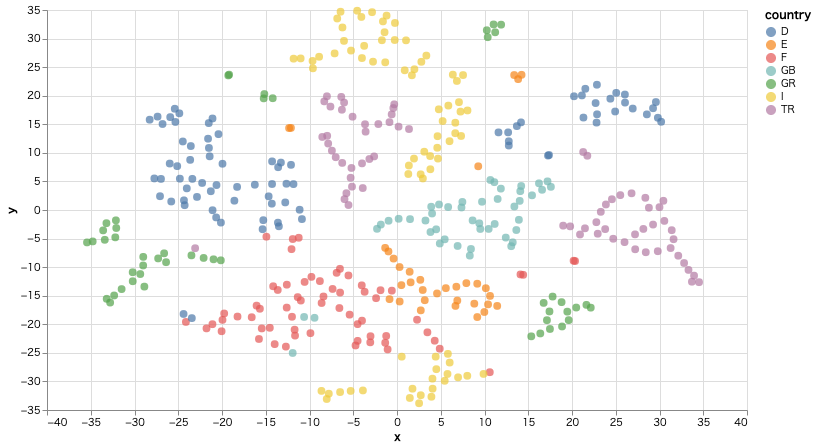
以上のデータを基に散布図を作成してビジュアライズする。
alt.Chart(tsne_df).mark_circle(size=60).encode(
x='x',
y='y',
color='country',
tooltip=['place', 'country']
).properties(width=700, height=400)
散布図
まとめ
最後まで読んでいただきありがとうございます!
説明不足な点、実行結果を載せただけな点、ご容赦ください😭
頑張ってみての率直な感想は、
チュートリアルはできたけど、やってることの中身の理解が難しい!!!泣
理解を深めるために文献や参考書を漁ろうと思います。
.
.
.
.
.
.
.
.
.
本当に難しい、、、こころ折れそう😖