この記事は DENSO アドベントカレンダー 2020 の 15 日目の記事です。
バイクツーリングの記録を収集・可視化する仕組みを個人開発で構築し、社内の LT 大会で発表しました[記事]。Web アプリによるスマホ IoT への取り組みについてはこちらで公開しています。この記事では、AWS サービスを使って収集した情報を地図上に可視化するサービスを構築した際の、使用したコードや苦労した点についてまとめます。
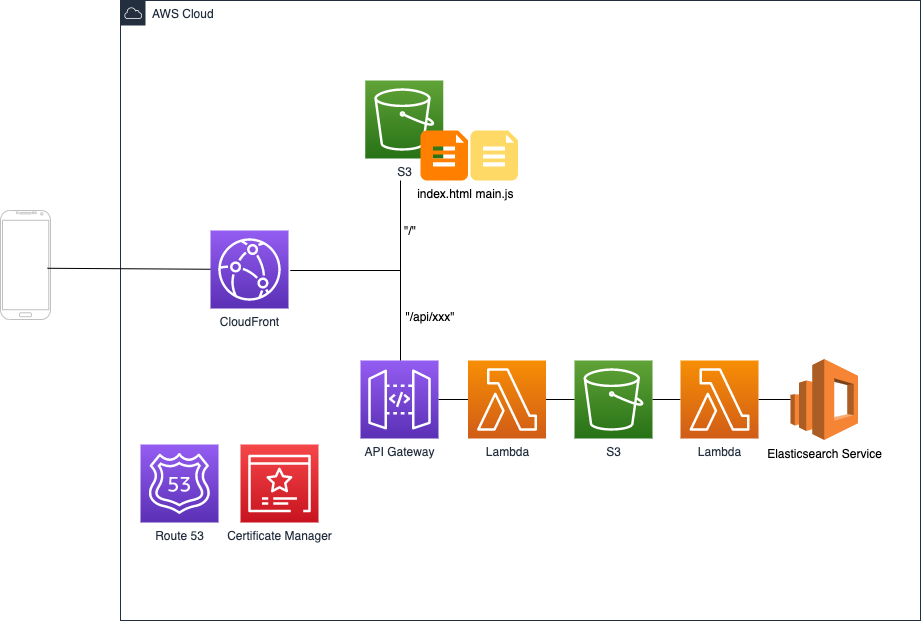
構成
全体構成は下記のとおりです。今回は標題通り クラウドサービス側を扱います。
デモ
前回構築した Web アプリです。ホーム画面上のアイコンから Web アプリを起動し、付近の Bluetooth センサをスキャン・接続してデータを取得・アップロードします。

AWS のマネージドサービス( Elasticsearch )で構築した可視化のデモです。高度に比例して色付けされたマーカーが地図上に表示されます。

Web アプリの配信
ホスティング
Web アプリは静的コンテンツを S3 に置いて配信します。ただし、PWA(Progressive Web Apps)として配信するには https での提供が必須です。このため、Route53 を利用して独自ドメインを、ACM を利用して証明書を取得し、CloudFront に導入します。具体的な内容は AWS でのハンズオン動画[AWS 上で静的な Web サイトを公開しよう!]や他の方が書かれた記事が多数あるので割愛しますが、今回の構成で工夫した点について二点だけ言及します。
クロスオリジンの回避
データアップロード用の API エンドポイントを Web アプリの URL と同一ドメインとし CloudFront でリクエストを振り分ける構成とすることで、面倒な CORS 対応を回避しました。
Basic 認証
開発中のサービスは非公開としたいです。とはいえ個人開発でそこまで神経質になる必要はないため、 Basic 認証を導入しました。CloudFront と Lambda@Edge の組み合わせで S3 コンテンツを Basic 認証で保護する記事が多数あるのでこちらも詳細は割愛しますが、PWA で利用しようとすると画像や manifest.json が上手くダウンロードできないことがありました。その際、こちらの記事を参考にしました。manifest.json と画像コンテンツに対するリクエストに対し、認証確認を不要としています。
S3 へのデータアップロード
Web アプリからアップロードされるデータ
スマホアプリから POST メソッドでアップロードされるデータは下記の構造を想定しています。
{
"sensorData": [
["タイムスタンプ", "緯度", "経度", "高度(m)", "温度(℃)", "湿度(%)"]
]
}
実際に送信されるデータの例です。
{
"sensorData": [
[
"2020-12-14T07:17:08.819Z",
"35.0000000",
"139.000000",
"43.500000",
"25.375",
"37.75"
],
[
"2020-12-14T07:17:18.819Z",
"35.0000000",
"139.000000",
"42.299999",
"25.375",
"37.70"
],
[
"2020-12-14T07:17:28.820Z",
"35.0000000",
"139.000000",
"43.899998",
"25.375",
"37.75"
]
]
}
Lambda で S3 へデータを格納する
API Gateway を通して Lambda に到達したデータには、通信量削減のために除去していたラベルを付与し下記構成に変換した上で S3 に格納します。
{"timestamp": "2020-12-14T07:17:08.819Z", "latitude": "35.000000", "longitude": "139.000000", "altitude": "43.500000", "temperature": "25.375", "humidity": "37.75"}
{"timestamp": "2020-12-14T07:17:18.819Z", "latitude": "35.000000", "longitude": "139.000000", "altitude": "42.299999", "temperature": "25.375", "humidity": "37.70"}
{"timestamp": "2020-12-14T07:17:28.820Z", "latitude": "35.000000", "longitude": "139.000000", "altitude": "43.899998", "temperature": "25.375", "humidity": "37.75"}
Lambda が実行するコードは下記です。ランタイムは python3.8 です。S3 バケットのキー名を生成する際に Hive 形式にしています。Athena などを利用する際インデックスを利用できて便利です。 データは容量削減のため gzip 圧縮します。一見使い勝手が悪そうですが、Athena は圧縮されたデータでも検索・表示が可能です。 ファイル名にエポック秒の suffix をつけているのは1分間にデータを2度取得したときなどにデータを上書きしないようにするためです。
import boto3
import json
from datetime import datetime
import time
import gzip
import logging
import glob
import os
s3 = boto3.resource("s3")
bucket = "Place S3 bucket here"
sensor_code = "sensorData"
def lambda_handler(event, context):
try:
print(json.loads(event["body"]))
lists = json.loads(event["body"])[sensor_code]
# データを分毎にファイルにまとめて圧縮する
for list in lists:
file_contents = (
json.dumps(
{
"timestamp": list[0],
"latitude": list[1],
"longitude": list[2],
"altitude": list[3],
"temperature": list[4],
"humidity": list[5],
}
)
+ "\n"
)
base_filename = (
datetime.fromisoformat(list[0].replace("Z", "+00:00")).strftime(
"%Y-%m-%d-%H-%M"
)
+ ".log.gz"
)
temp_filename = "/tmp/" + base_filename
with gzip.open(temp_filename, "ab") as f_out:
f_out.write(file_contents.encode("utf-8"))
# 圧縮ファイルをS3に格納する
file_list = sorted(glob.glob("/tmp/" + "*.gz"))
for file in file_list:
file_name = os.path.basename(file)
file_name_wo_extension = file_name.split(".")[0]
names = file_name_wo_extension.split("-")
# 同一分(minute)のファイルを区別するためエポック秒を付与
key = "sensor={0}/year={1}/month={2}/day={3}/{4}-{5}-{6}.log.gz".format(
sensor_code, *names, int(time.time())
)
obj = s3.Object(bucket, key)
obj.upload_file(file)
os.remove(file)
return {
"statusCode": 200,
"body": json.dumps({"status": "accepted"}),
"isBase64Encoded": False,
"headers": {},
}
except Exception as e:
logging.error(e)
raise Exception("[ErrorMessage]: " + str(e))
Elasticsearch Service を使った可視化
位置情報を地図上に表示するために AWS の Elasticsearch Service (以下、ES)を利用しました。今回使用したバージョンは 7.9 です。後方互換性がない変更が計画・進行しているようで、旧バージョンの環境での記事を参考にして作業するとうまくいかないことがありました。使用するバージョンには注意が必要です[参考]。
ES インスタンスを準備する
まずインスタンスを作成します。開発用、バージョンは 7.9 を選択します。

ドメイン名を決め、インスタンスタイプは t3.small を選択。個人開発用なので、リソースは最小限とします。

パブリックアクセスを選択し、ログインのためのマスタユーザを作成しました。セキュリティ対策として IP 制限 でアクセス制限をしておきます。



インスタンスが使用可能となるまで時間がかかるので、S3 から Elasticsearch へデータを格納する Lambda を設定します。
Lambda で S3 から ES へデータを格納する
S3 にデータが格納されたことをトリガとして ES にデータを格納する処理です。
注意点としては、
- Lambda にアタッチするロールに S3 readonly ポリシーを付与
- Hive 形式にしたことで S3 オブジェクトのキー名にイコールが含まれるため、urllib.parse を使いパース
- ファイルが gz 形式に圧縮されているため gzip で解凍
- geo_point 型として ES に認識させるため位置情報を location として定義
- Lambda のランタイムがサポートしていないライブラリは、ローカル環境でパッキング、zip 化してアップロード
サポート外のライブラリを使用する方法は、こちらの記事を参考にしました。今回は requests と requests_aws4auth のライブリが必要です。
コードは公式サイトを参考に必要となる処理を追加しています。
import boto3
import gzip
import json
import urllib.parse
import requests
import logging
from requests_aws4auth import AWS4Auth
logger = logging.getLogger(__name__)
region = "ap-northeast-1"
service = "es"
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(
credentials.access_key,
credentials.secret_key,
region,
service,
session_token=credentials.token,
)
host = "Place Elasticsearch endpoint here"
index = "iot-index"
url = host + "/" + index + "/_doc"
headers = {"Content-Type": "application/json"}
s3 = boto3.client("s3")
# Lambda execution starts here
def lambda_handler(event, context):
try:
for record in event["Records"]:
# Get the bucket name and key for the new file
bucket = record["s3"]["bucket"]["name"]
key = urllib.parse.unquote_plus(
record["s3"]["object"]["key"], encoding="utf-8"
)
# Get, read, and split the file into lines
obj = s3.get_object(Bucket=bucket, Key=key)
body = obj["Body"].read()
bytes_data = gzip.decompress(body)
data = bytes_data.decode("utf-8")
lines = data.splitlines()
# index the JSON
for line in lines:
json_dict = json.loads(line)
timestamp = json_dict["timestamp"]
latitude = float(json_dict["latitude"] or "0")
longitude = float(json_dict["longitude"] or "0")
altitude = float(json_dict["altitude"] or "0")
temperature = float(json_dict["temperature"] or "0")
humidity = float(json_dict["humidity"] or "0")
document = {
"timestamp": timestamp,
"location": {"lat": latitude, "lon": longitude},
"altitude": altitude,
"temperature": temperature,
"humidity": humidity,
}
r = requests.post(url, auth=awsauth, json=document, headers=headers)
print(r.text)
except Exception as e:
logger.error(e)
raise Exception("[ErrorMessage]: " + str(e))
Lambda のパッケージをアップロードする間に、ES インスタンスの準備が完了していると思います。ES のダッシュボードからドメインを選択してエンドポイントを確認し、上記の Lambda コードの host = "Place Elasticsearch endpoint here" の部分を書き換えます。
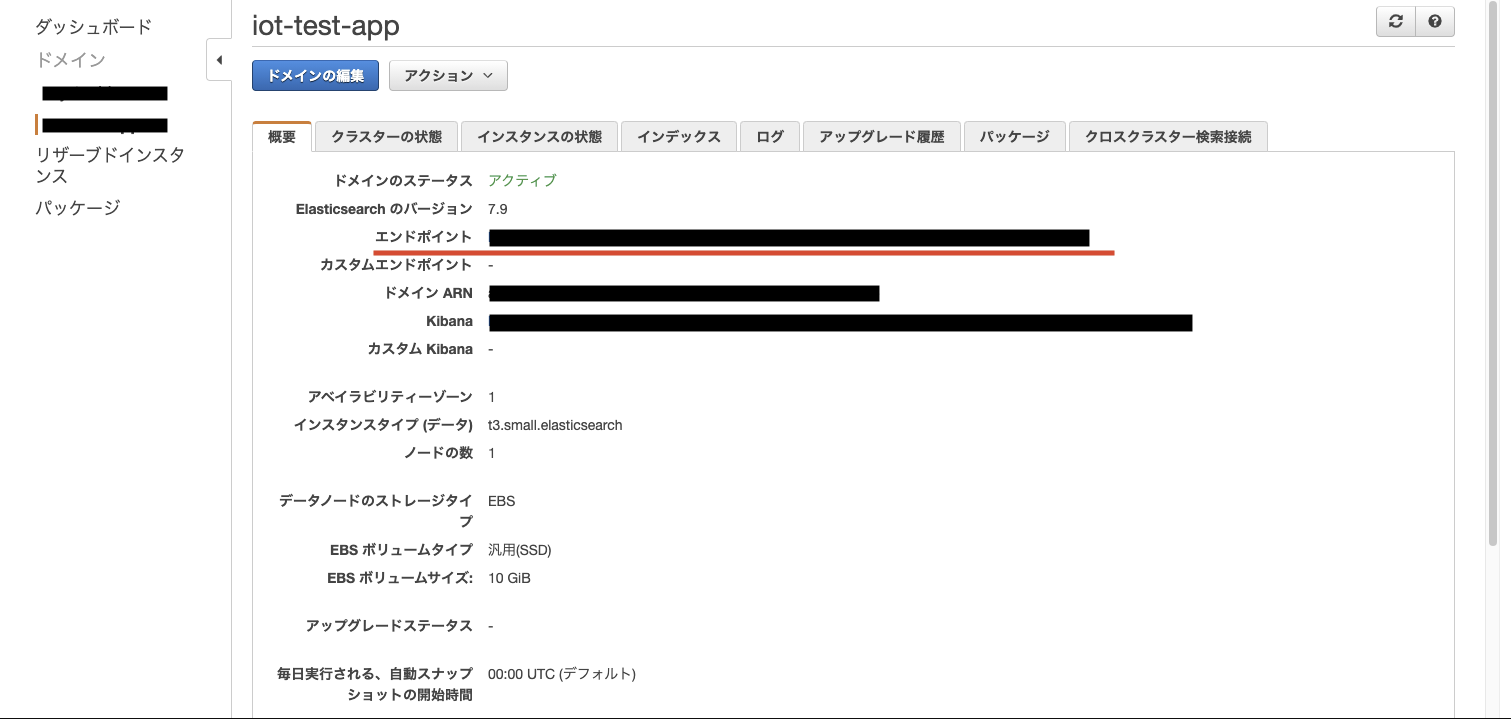
Lambda から ES への操作権限を設定する
Lambda を設定したら ES 設定に戻ります。まず Lambda から ES にデータ投入ができるよう2箇所で権限設定をします。
ES アクセス権限設定
アクセスポリシーの変更を開き、下記のように書き換えます。前半はユーザが Kibana にアクセスするための設定で IP アドレスでアクセス制限しています。後半は Lambda が ES にデータ格納することを許可しています。

{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "es:*",
"Resource": "arn:aws:es:ap-northeast-1:<AWSアカウントID>:domain/<ESインスタンス名>/*"
"Condition": {
"IpAddress": {
"aws:SourceIp": "<アクセスを許可するIPアドレス>"
}
}
},
{
"Effect": "Allow",
"Principal": {
"AWS": "<LambdaにアタッチしたIAMロールのarn名>"
},
"Action": "es:ESHttpPost",
"Resource": "arn:aws:es:ap-northeast-1:<AWSアカウントID>:domain/<ESインスタンス名>/*"
}
]
}
ES データ操作権限の設定
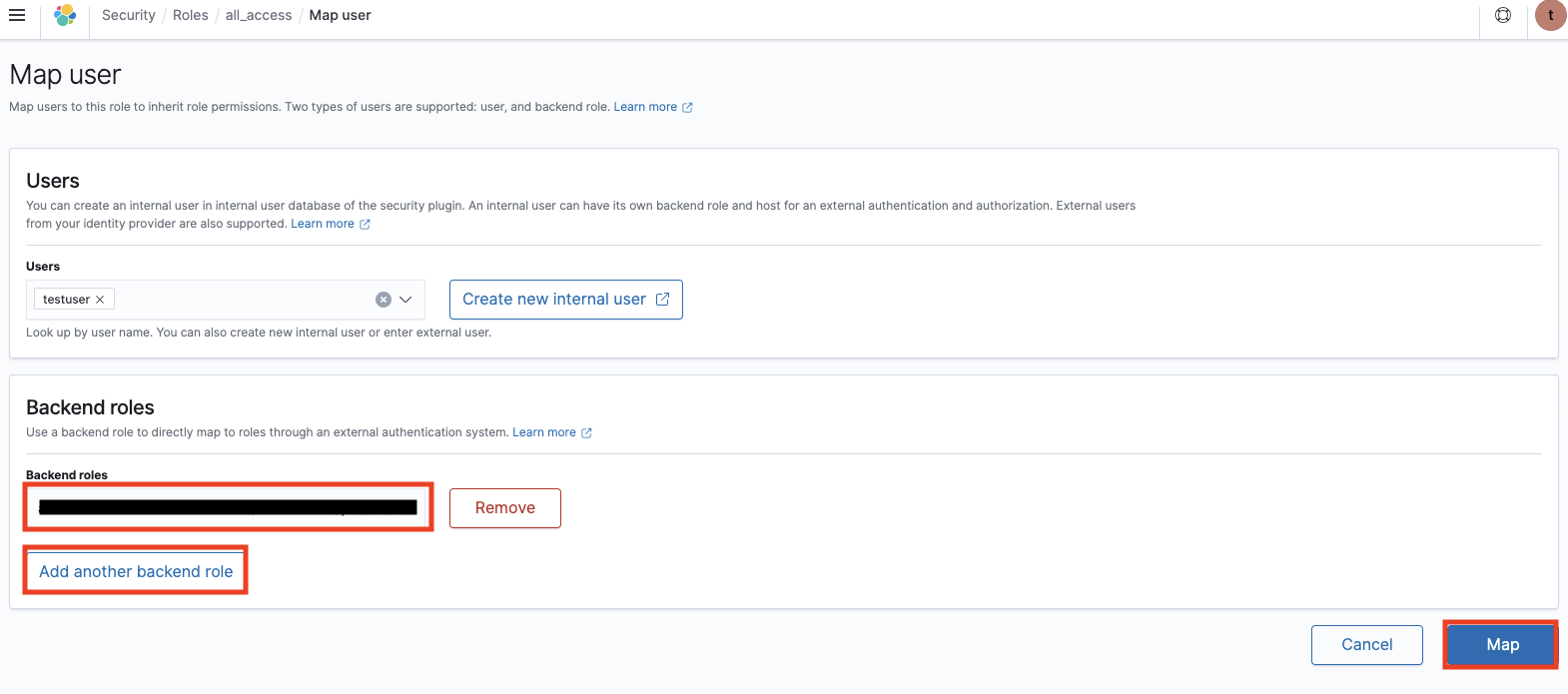
Lambda に付与する権限は上記では不十分です。ES ダッシュボードから Kibana の URL にアクセスしてログインします。id/password はインスタンス作成時に設定したものです。Security 、Explore existing roles、all_access、Mapped users、Manage mapping、 Add another backend role と選択し、Lambda にアタッチした IAM ロールの arn 名を記入して Map をクリックします。

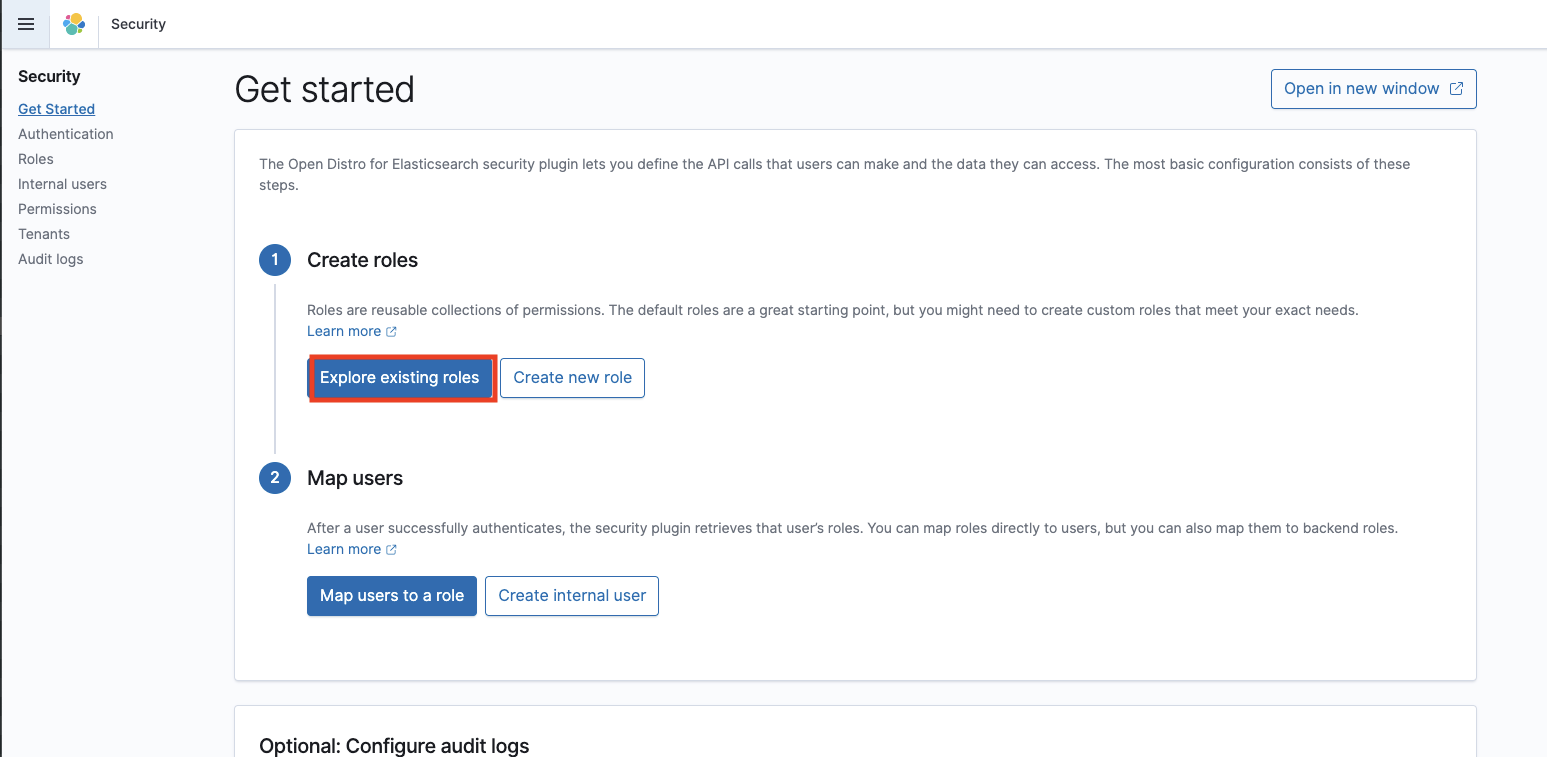

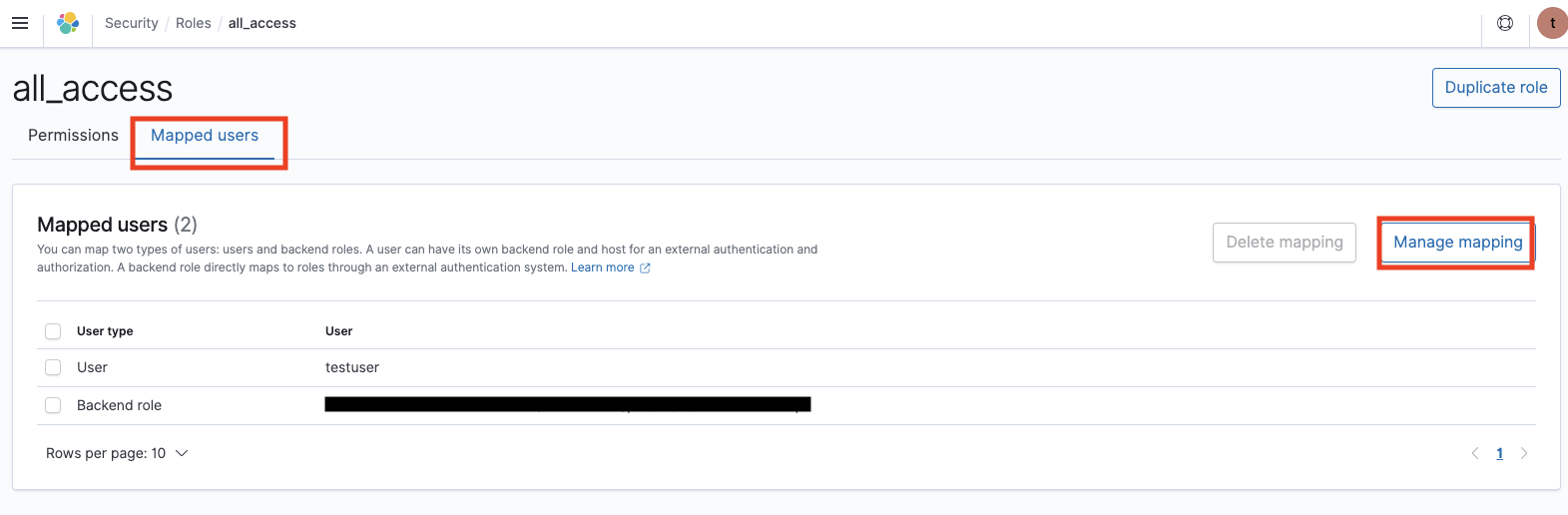
LambdaにアタッチしたIAMロールのarn名を Backend roles に追加する。
Index 作成とマッピング
サイドメニューから Dev Tools を開き、インデックスとマッピングを定義します。マッピングにより位置情報データを geo_point 型として扱うことができ、地図上に位置を表示することができます。下記コードを記入して実行します。この際、インデックス名は Lambda で定義した名前と合わせます。

PUT /iot-index
{
"mappings": {
"properties": {
"altitude": {
"type": "float",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"humidity": {
"type": "float",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"location": {
"type": "geo_point"
},
"temperature": {
"type": "float",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"timestamp": {
"type": "date"
}
}
}
}
Dev Tools で試行錯誤する際、こちらの記事が参考になりました。
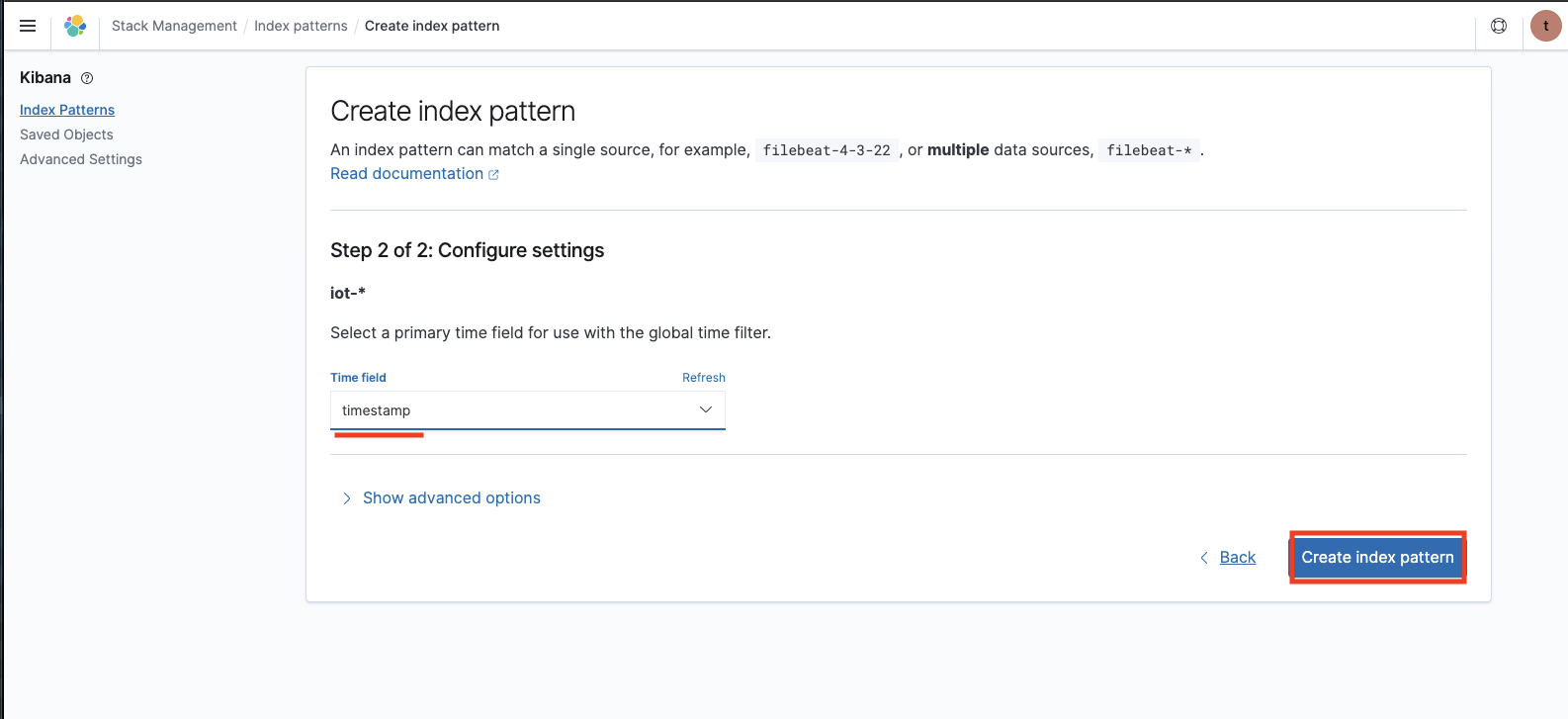
Index pattern 作成
Kibana のサイドメニューから Stack Management、Index patterns、Create index pattern を選択します。先程作成した Index がパターンマッチするような名前(iot-*)を記入します。Configure settings では timestamps を選択し Index pattern を作成します。



データアップロードの確認
ここまでくると準備完了です。Web アプリを立ち上げデータアップロードを開始します。Lambda がうまく動作しないときは Cloudwatch logs を見てデバッグします。例として、Cloudwatch logs で、次のように表示されていれば S3 から ES にデータが格納できていることを確認できます。
{
"_index": "iot-index",
"_type": "_doc",
"_id": "zfbLNnYBtgbOEvp0nxOK",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 4391,
"_primary_term": 1
}
データの地図表示
データを投入したら、Kibana のサイドメニューから visualize、Coordinate Map を開きます。作成した Index pattern を選択し、データアップロードした期間を選択し、下記のように表示設定すると高度に応じて色付けされた移動軌跡が表示されます。





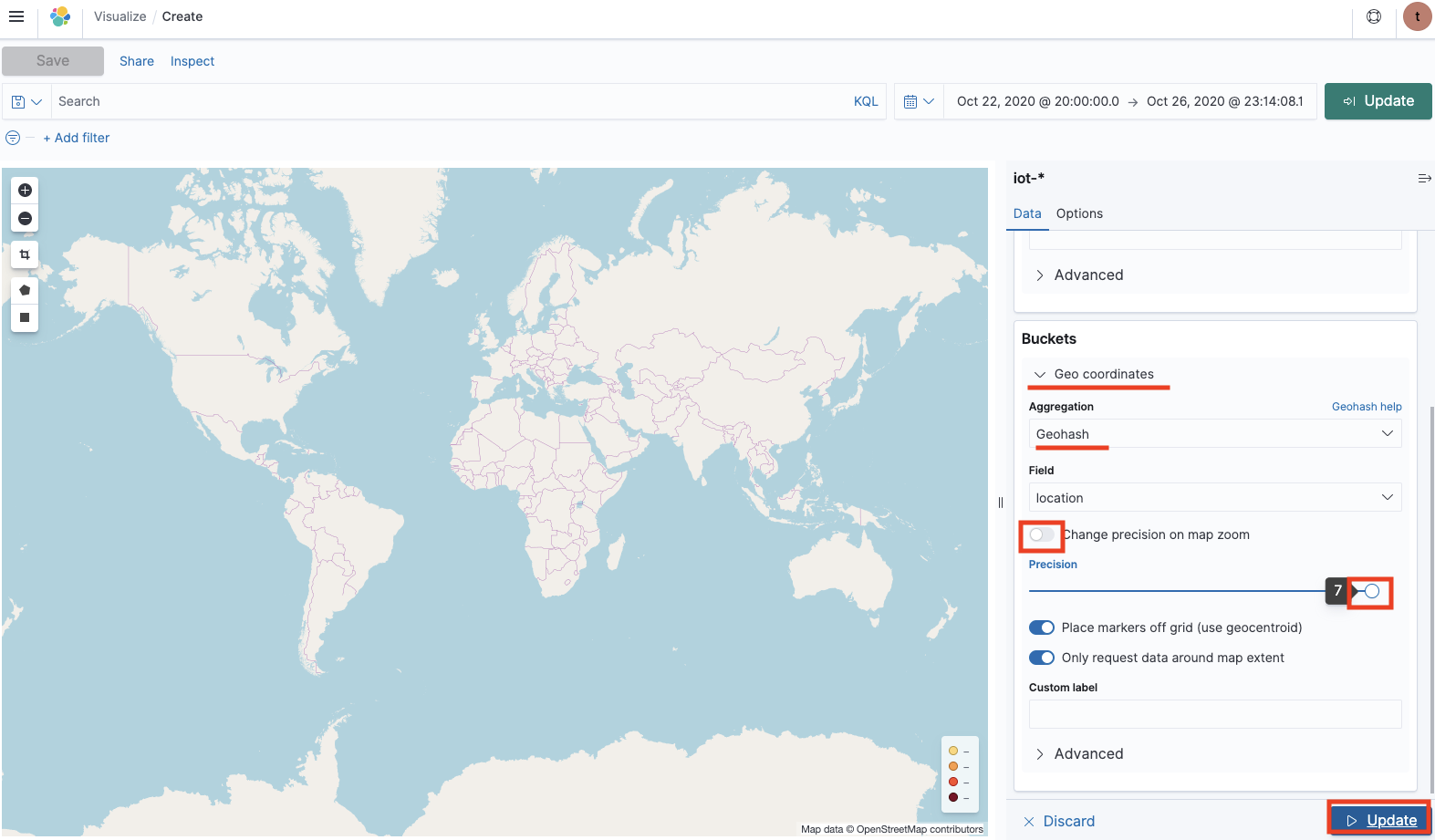
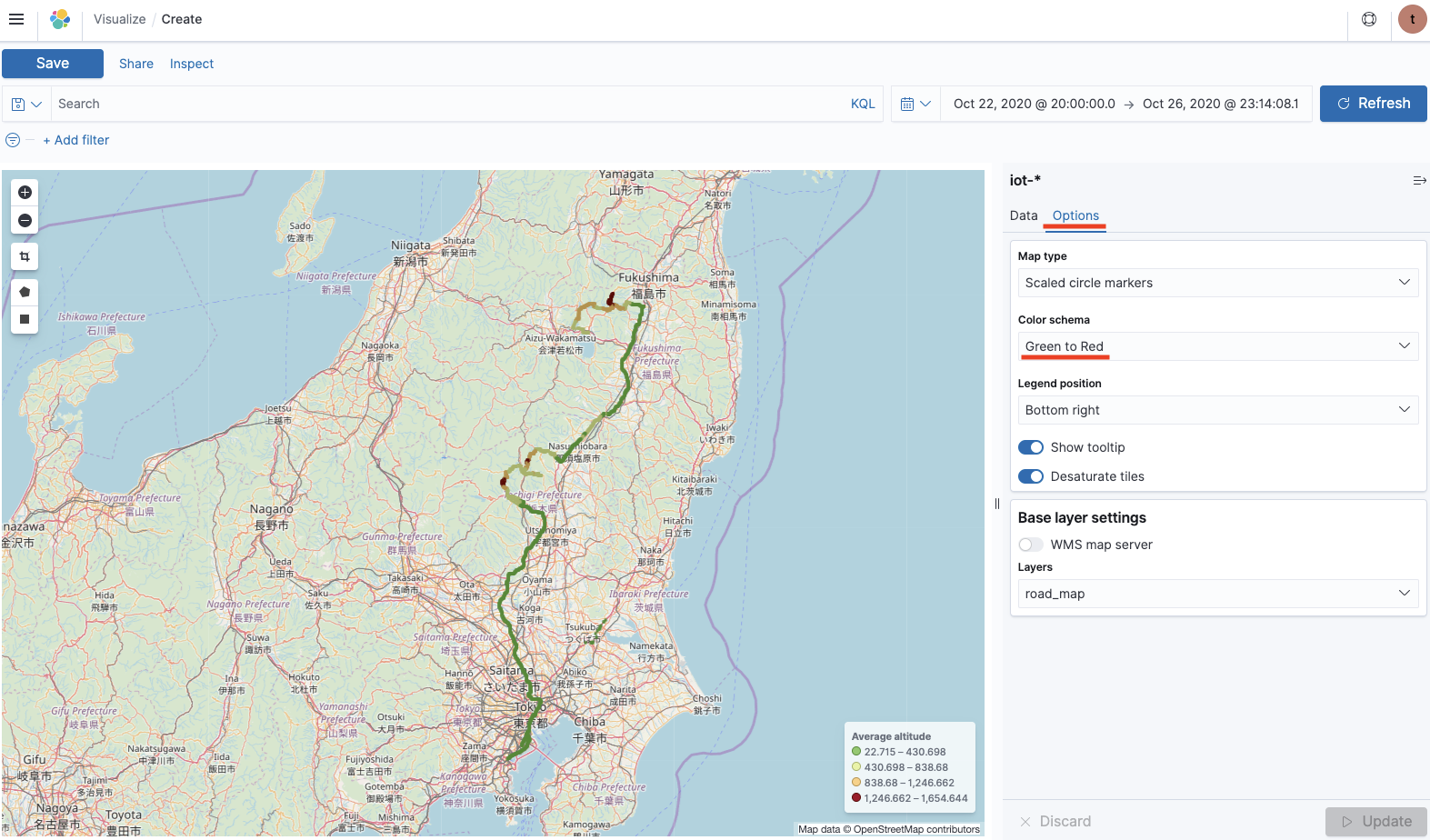
複数地点のデータがアップロードされていないと、高度などの数値表示がうまく表示されないかもしれません。
まとめ
IoT Web アプリから収集したセンサデータをデータレイクである S3 に格納し、データ分析のための Elasticsearch に投入して地図上に可視化しました。マネージドサービスを利用することで、地図表示の Web アプリをスクラッチ開発するより素早く可視化することができましたが、Elasticsearch には特有の設定(Lambda からリソース操作するためのロールマッピング、geo_point として扱うためのマッピング)が多い上に、バージョンアップに伴う後方互換性のない変更が多いように見受けられ、敷居が高いように感じました。今後は他の分析ツールも試して知見を増やしたいと思います。