原典: 本記事は Zenn に投稿した Pocket 代替を Next.js 15 + Supabase で作った — 日本語ファーストで端末本文保存にした理由 を Qiita 向けに調整したものです。canonical URL: https://zenn.dev/ktg/articles/readbox-pocket-alternative
0. はじめに
Pocket のサービス終了が決まりました。長年「あとで読む」の代名詞だったサービスがなくなるので、日本語ユーザーとしては移行先を決める必要があります。
主要な代替(Instapaper / Matter / Readwise Reader / Omnivore)を一通り試したのですが、日本語 UI が中途半端だったり、月額が為替で揺れたり、機能が過剰だったりして決め手に欠けました。
それで readbox という PWA を自分で作って 2026-05-22 にリリースしました。技術スタックは Next.js 15 (App Router) + Supabase + Stripe で、本文抽出は紆余曲折の末に Jina Reader (r.jina.ai) を採用しています。本文の HTML はサーバー DB に保存せず、端末側の IndexedDB (Dexie) に置く設計です。
この記事は、技術選定の理由、本文抽出で詰まったところ、日本語処理の小さい工夫を残しておくためのものです。
:readbox のランディング画面
1. なぜ作ったか — Pocket 終了で日本語ユーザーが置かれた状況
Pocket は長年「あとで読む」の代名詞でした。自分も 7-8 年使ってきて、保存件数は 3,000 件を超えていました。
サービス終了のアナウンスを見て、他社の代替を一通り試した結果、次の不満が残りました:
- UI が英語のみ(自分は問題ないが、家族や同僚に勧めにくい)
- Pocket の CSV エクスポートは取り込めるが、タグの
|区切りや日付の Unix timestamp の扱いに齟齬がある実装が多い - 月額が為替で揺れる
- 自分は AI 要約や Highlight 共有はそこまで使わない(オーバーキル)
「日本語 UI + Pocket CSV インポート + 日本円固定の月額 + シンプル」だけで十分なはずなので、作ることにしました。
: 受信トレイ(保存した記事の一覧、お気に入り・タグ・アーカイブで分類)
2. 技術スタック
確定スタックは次の通りです。
| 領域 | 採用 |
|---|---|
| モノレポ | Turborepo + pnpm workspace |
| フレームワーク | Next.js 15 App Router + TypeScript strict |
| BaaS | Supabase(Postgres + Auth + Storage) |
| 認証 |
@supabase/ssr の Magic Link |
| 課金 | Stripe Checkout + Customer Portal + Webhook |
| 本文抽出 | Jina Reader (r.jina.ai) を X-Return-Format: html で fetch |
| サーバー側 metadata 抽出 | regex のみ(DOM ライブラリは置かない) |
| サニタイズ | DOMPurify(クライアント側 Reader.tsx で実行) |
| 端末側ストレージ | Dexie v4(IndexedDB ラッパー) |
| PWA | Service Worker(最小限の cache 戦略) |
| デプロイ | Vercel |
避けたものも書いておきます:
-
@supabase/auth-helpers-nextjs— 非推奨化済、@supabase/ssrを使う -
@postlight/parser/ Mercury — メンテナンス停止 -
next-pwa(shadowwalker) — 停止 -
supabase.auth.getSession()をサーバー側で使う —getUser()を使う(公式推奨)
3. 本文抽出: Readability + jsdom で詰まって Jina Reader に切り替えた話
記事を「初めて開いたとき」にサーバー側で本文を抽出して、結果を端末側 (IndexedDB) に保存する設計です(保存先の話は次節)。
最初は @mozilla/readability + jsdom を Next.js の Route Handler で動かす想定でいました。Pocket / Mercury / Postlight Parser 時代から定番の構成で、特に疑問もなくこれで行けると思っていました。
結論から言うと、これは Vercel serverless 上で動かせず、最終的に Jina Reader (https://r.jina.ai/<URL>) を本番の primary 抽出経路に採用 しました。
3-1. Readability + jsdom が Vercel serverless で詰まった経緯
ローカル next dev では問題なく動きました。Mozilla Readability + jsdom + DOMPurify の組み合わせで、runtime = 'nodejs' の Route Handler を立てると Readability の parse() がそのまま返ってきます。
ところが Vercel に deploy すると、serverless 関数で同じコードが動かない。具体的には ERR_REQUIRE_ESM / nft.json の肥大化(依存解決ファイルが 10MB を超える)/ Vercel Serverless の関数サイズ上限抵触 のいずれかで毎回詰まります。
自分は 6 アプローチ を順に試しました(実装コードのコメント cases A-F 参照)。jsdom を dynamic import で逃がす案、bundle 除外設定、experimental 系の組み合わせ、Edge Runtime に寄せて軽量化する案、monorepo の hoisting 起因に絞った検証、等々。どれも本番デプロイの起動エラーを解消できず、別ルートを取る判断をしました。
3-2. Jina Reader を primary に昇格
Jina Reader は URL の前に https://r.jina.ai/ を付けてリクエストすると、本文を取得してくれるサービスです。LLM 学習用に整備されているせいか、SPA / JS レンダリング系サイトでも本文取得の安定度がかなり高いです。
X-Return-Format: html を付けると、clean な HTML が直接返ってきます(Markdown 変換のステップが不要になります)。
これを primary(最初に呼ぶ抽出器) に格上げしたら、Vercel serverless 上での ESM 制約とは完全に無縁になりました。サーバー側に DOM ライブラリを置かなくて済むので、deploy 後の nft.json は約 12MB から 50KB 程度まで縮みました。
公開エンドポイント r.jina.ai は 無認証で利用 できます(rate limit 内で)。JINA_API_KEY を投入すると alt-text の自動生成(X-With-Generated-Alt)が有効になりますが、必須ではありません。
Route Handler の骨子はこれです:
// app/api/extract/route.ts
export const runtime = 'nodejs';
export const maxDuration = 60;
const JINA_ENDPOINT = 'https://r.jina.ai';
export async function GET(req: Request) {
const url = new URL(req.url).searchParams.get('url');
if (!url) return Response.json({ error: 'no-url' }, { status: 400 });
const headers: Record<string, string> = {
'Accept': 'text/html',
'X-Return-Format': 'html',
};
if (process.env.JINA_API_KEY) {
headers['Authorization'] = `Bearer ${process.env.JINA_API_KEY}`;
headers['X-With-Generated-Alt'] = 'true';
}
const r = await fetch(`${JINA_ENDPOINT}/${url}`, { headers });
if (!r.ok) {
return Response.json({ error: 'extract-failed', url }, { status: 200 });
}
const html = await r.text();
// metadata は regex のみで抽出(サーバーに DOM ライブラリは置かない)
const titleMatch = html.match(/<title[^>]*>([^<]+)<\/title>/i);
const ogImageMatch = html.match(/<meta[^>]+property=["']og:image["'][^>]+content=["']([^"']+)["']/i);
const bylineMatch = html.match(/<meta[^>]+name=["']author["'][^>]+content=["']([^"']+)["']/i);
return Response.json({
title: titleMatch?.[1]?.trim() ?? null,
byline: bylineMatch?.[1] ?? null,
thumbnailUrl: ogImageMatch?.[1] ?? null,
contentHtml: html,
length: html.length,
url,
});
}
サニタイズは クライアント側の Reader コンポーネント (Reader.tsx) で DOMPurify を通してから描画しています。サーバー側で済ませる選択肢もあったのですが、上述の通り「server に DOM ライブラリを置かない」方針で揃えました。
3-3. 教訓
「ローカルで動く」と「Vercel で動く」の間には溝があります。jsdom のような Node 寄りの大きなパッケージは特に。抽出パイプラインの primary を、API として外部に任せたほうが運用が圧倒的に楽 だったというのが、自分の経験から得た一番の教訓です。
なお、独自で動かす場合は Cloudflare Workers + Browser Rendering のような選択肢もあります(Headless Chromium 経由で本文取れる)。コスト次第ではこちらも有力です。
: リーダーは light / dark / sepia の 3 テーマを切り替え可能、フォントサイズ・行間も調整可
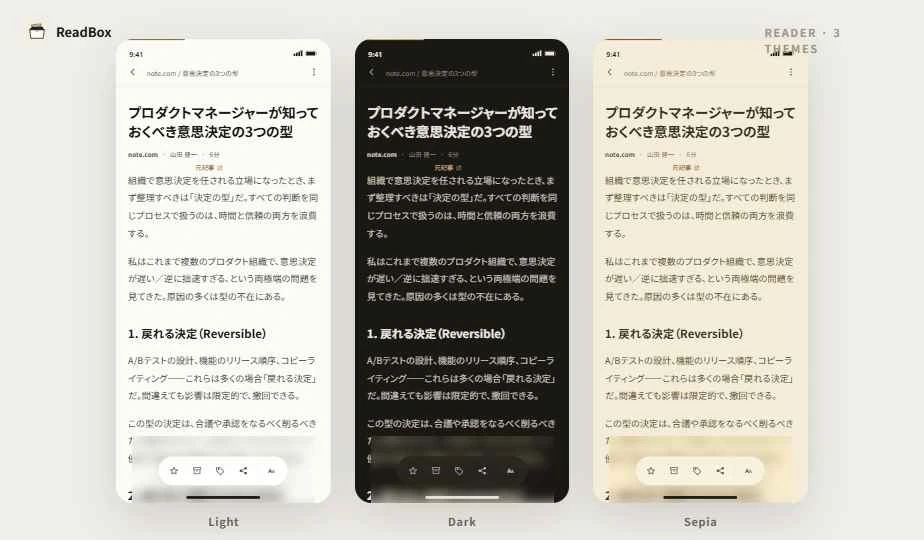
4. 端末本文保存: IndexedDB (Dexie) を選んだ理由
抽出した本文 HTML を Supabase に保存せず、端末側 IndexedDB に置く 設計にしました。理由は 3 つあります。
4-1. ストレージコストとプライバシー
Pocket からのインポート想定で、1 人あたり 1,000-5,000 記事 × 平均 50KB の本文 = 50-250MB が見込めます。Supabase Free の Storage 上限が 1GB なので、有料ユーザー 10 人で枯渇します。
それより重要なのは「ユーザーが何を読んでいるか」をサーバーが保持し続けないことです。記事のメタデータ(タイトル / URL / タグ / 既読フラグ / 読了率)は Supabase に置きますが、本文は端末から出ません。
4-2. 著作権上の配慮
抽出本文は他社サイトのコンテンツです。Pocket もユーザー私的利用の文脈で本文を持っていますが、サーバー側に恒久保存しない設計にしておくと、引用範囲やキャッシュの議論にも素直です。
4-3. オフライン読書が速い
オフライン時に開いても IndexedDB から即取得して描画できます。Service Worker のキャッシュより整理がしやすく、Dexie の API も素直です。
Dexie 側の宣言はこれだけで済みます:
// lib/dexie-db.ts
import Dexie, { type Table } from 'dexie';
interface ArticleBody {
articleId: string;
contentHtml: string;
savedAt: number;
}
export class ReadboxDB extends Dexie {
articleBodies!: Table<ArticleBody, string>;
constructor() {
super('readbox');
this.version(1).stores({
articleBodies: 'articleId, savedAt',
});
}
}
export const db = new ReadboxDB();
リーダーで開いた瞬間に db.articleBodies.get(articleId) を試して、ヒットしなければ /api/extract を呼んで結果を db.articleBodies.put(...) で書く、というシンプルなフローです。
5. 日本語固有の難所 3 つ
ここからが日本語ファーストを謳う以上、避けて通れないところです。抽出器を Jina Reader に切り替えた後も、後処理は自前で書く必要がありました。
5-1. excerpt(要約)の切り出し
Jina Reader が返す HTML をテキストに直してから先頭を切り出して excerpt にするのですが、日本語の場合「。」や「、」で切れずに途中で終わると不格好です。
自分は次のような後処理を入れました:
function trimJpExcerpt(raw: string, max = 160): string {
if (raw.length <= max) return raw;
const candidate = raw.slice(0, max);
// 文末記号で優先的に切る
const lastSentenceEnd = Math.max(
candidate.lastIndexOf('。'),
candidate.lastIndexOf('!'),
candidate.lastIndexOf('?'),
);
if (lastSentenceEnd > max * 0.6) return candidate.slice(0, lastSentenceEnd + 1);
// 読点で妥協
const lastComma = candidate.lastIndexOf('、');
if (lastComma > max * 0.7) return candidate.slice(0, lastComma + 1) + '…';
return candidate + '…';
}
5-2. 読了時間推定
日本語と英語で 1 分あたりの読書速度は違います。一般的には日本語 400 字/分 / 英語 250 語/分 と言われます。
抽出結果から得たテキストに対して、文字種から日本語か否かを簡易判定しています:
function estimateReadTimeSec(textContent: string, lang?: string): number {
const cjkChars = (textContent.match(/[ -鿿]/g) ?? []).length;
const isJp = cjkChars / textContent.length > 0.3 || lang?.startsWith('ja');
if (isJp) return Math.round((textContent.length / 400) * 60);
// 英語想定
const wordCount = textContent.split(/\s+/).length;
return Math.round((wordCount / 250) * 60);
}
完璧ではないですが、混在文章でも概ね妥当な値が出ます。
5-3. クライアント側サニタイズの後の見た目崩れ
Jina Reader からは clean な HTML が直接返ってくるので変換ステップは無いのですが、リーダー描画前にクライアント側で DOMPurify を必ず通します(XSS 対策の最終ラインを描画側に置く方針)。
DOMPurify はデフォルトで結構な数のタグ・属性を弾きます。<ruby> <rt> <rp>(ルビ)、<aside>(脚注に多い)、<pre><code>(技術記事)、<figure><figcaption> あたりは ALLOW しないと、日本語の技術ブログを保存したときに見た目が崩れます。
// components/Reader.tsx(クライアント側)
import DOMPurify from 'dompurify';
const clean = DOMPurify.sanitize(html, {
ADD_TAGS: ['ruby', 'rt', 'rp', 'figcaption', 'aside'],
ADD_ATTR: ['target', 'rel'],
});
外部のリンクには target="_blank" rel="noopener noreferrer" を後段で付け足しています。
6. やらないと決めたこと
機能を絞ったほうが続きます。
- AI 要約: API 費用が月額 ¥450 と整合しません。やるなら別料金 (Pro+) にする必要があり、初期は外しました。代わりに「本文は丸ごと端末に置く」「自分の目で読む」を主体に
- ハイライト + 共有: Matter / Readwise Reader の領域。自分の使い方ではほぼ使わないので外しました
- ソーシャル機能: 友達の保存記事を見る等。これも別のプロダクトの仕事
- 自動同期 (RSS / Twitter): 入口を増やすと収拾がつかなくなるので、まずは「URL を貼る」と「Pocket CSV インポート」と「ブックマークレット」だけにしました
: Pocket CSV インポート画面(バッチ取り込み、エラー行はログ保持)
7. おわりに
技術選定の話ばかり書きましたが、自分が一番大事にしたのは「日本語の記事を読むときに違和感がない」と「ユーザーが何を読んでいるかをサーバーが保持しすぎない」の 2 つです。
本文抽出は当初の Readability + jsdom 案が Vercel serverless で詰んで、Jina Reader に逃がしたことで一気に運用が楽になりました。「ローカルで動く ≠ 本番で動く」のラインを引き直すきっかけになった出来事です。
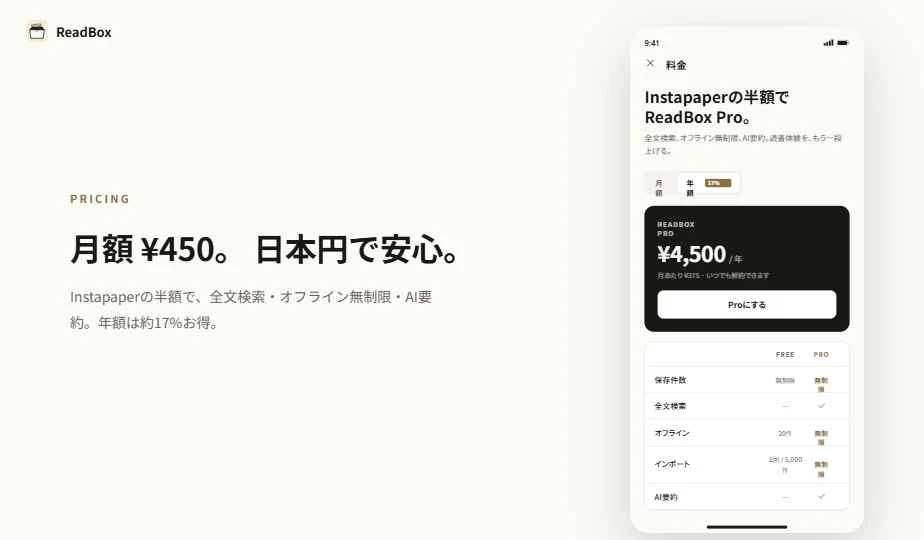
Pocket からの移行先を探している方は試してみてください。料金は月¥450(税込)、無料プランもあります。
: 価格プラン(Free 100 件まで / Pro 月額 ¥450 税込 / Pro 年額 ¥3,800 税込で 2 ヶ月分お得)
readbox: https://readbox.dev-tools-hub.xyz
質問や感想があれば Qiita のコメント、または自分の SNS でどうぞ。