はじめに
「ボット対策が厳しいWebサイトから、安定してデータを取得したい」
Webスクレイピングでは、単にHTMLを取得するだけでなく、プロキシ管理、CAPTCHA対応、IPブロック回避など、データ取得以外の課題に多くの時間を費やすことがあります。

本記事では、Bright DataのBrowser APIを使うことで、こうしたインフラ面の課題をどのように解決できるかを、従来のSeleniumによるアプローチとの比較を通じて解説します。
Webスクレイピングを行う際は、対象サイトの利用規約(Terms of Service)やrobots.txtを必ず事前に確認し、許可された範囲で実施してください。また、各国の法令(日本では著作権法や不正アクセス禁止法等)を遵守し、サーバーに過度な負荷をかけないよう配慮することが重要です。
Wikipediaのデータ取得について補足
本記事ではスクレイピングの比較題材としてWikipediaを使用していますが、Wikipediaのデータ取得にはMediaWiki APIという公式APIが用意されています。Wikipedia自体はボット対策も緩やかなため、実務でWikipediaからデータを取得する場合はAPIの利用を推奨します。Bright DataのBrowser APIが真価を発揮するのは、APIが提供されていないサイトや、ボット対策が厳しいサイトからのデータ取得です。
Seleniumでのスクレイピングにおける課題
Seleniumは長年Webスクレイピングに使われてきたツールですが、特にボット対策のあるサイトを扱う場合にはいくつかの課題があります。
【課題1】セットアップと初期設定
Seleniumでスクレイピングを始めるには、まず環境構築が必要です。
# ChromeDriverのインストール
pip install selenium webdriver-manager
webdriver-managerを使えばChromeDriverのバージョン管理は自動化されるため、手動でのバージョン合わせは基本的に不要です。ただし、CI/CD環境や特殊なOS環境では追加の対応が必要になることがあります。
ボット対策のあるサイトを対象にする場合、検出を回避するための設定が増えます。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import (
TimeoutException, NoSuchElementException, StaleElementReferenceException
)
import time
import random
# WebDriverの設定
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--disable-gpu')
# ボット対策が厳しいサイトでは以下のような検出回避設定が必要になることがある
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36...')
driver = webdriver.Chrome(options=options)
# navigator.webdriverプロパティの隠蔽
driver.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
Wikipediaのようにボット対策が緩いサイトであれば検出回避の設定は不要ですが、ECサイトやSNSなど対策が厳しいサイトでは、これらに加えてプロキシのローテーションやフィンガープリント対策も自前で実装する必要があります。
【課題2】要素の待機処理
Seleniumでは、ページの読み込みや要素の出現を明示的に待機する必要があります。
wait = WebDriverWait(driver, 10)
try:
wait.until(EC.presence_of_element_located((By.ID, 'content')))
wait.until(EC.presence_of_element_located((By.ID, 'firstHeading')))
wait.until(EC.presence_of_element_located((By.ID, 'mw-content-text')))
except TimeoutException:
print("タイムアウト!")
Playwrightなら自動待機が組み込み
後述のBright Data Browser APIはPlaywrightベースで接続します。Playwright自体に自動待機(auto-wait)機能があるため、この課題はPlaywrightに切り替えるだけでも大幅に軽減されます。
【課題3】エラーハンドリング
Seleniumでは発生しうる例外の種類が多く、個別に対応するコードが必要です。
try:
driver.get(url)
except TimeoutException:
print("接続タイムアウト")
except NoSuchElementException:
print("要素が見つからない")
except StaleElementReferenceException:
print("要素が古くなった")
except WebDriverException:
print("WebDriverエラー")
except Exception as e:
print(f"予期しないエラー: {e}")
finally:
driver.quit()
【課題4】プロキシ・CAPTCHA・IPブロック対策(Seleniumだけでは解決が難しい領域)
ここがSeleniumでのスクレイピングにおける最大の課題です。Seleniumはあくまでブラウザ操作のためのツールであり、以下のようなインフラ面の機能は含まれていません。
- プロキシローテーション: 外部プロキシサービスの契約と、ローテーションロジックの自前実装が必要
- CAPTCHA解決: 別途CAPTCHAソルバーサービスとの連携が必要
- IPブロック回避: プロキシの管理、リトライ戦略の設計が必要
- ブラウザフィンガープリント対策: サイトの検出手法に合わせた継続的な調整が必要
これらを個別に導入・管理するのは、コードの複雑化とメンテナンスコストの増大につながります。
Bright DataのBrowser APIとは
Bright DataのBrowser APIは、上記のようなインフラ課題をワンストップで解決するクラウドブラウザサービスです。
具体的には、以下がすべてサービス側で自動的に処理されます。
- プロキシローテーション
- CAPTCHA自動解決
- IPブロック回避
- ブラウザフィンガープリント管理
- リトライ処理
開発者はデータ取得のロジックだけに集中できます。
Bright Data Browser APIでやってみる
WebアクセスAPIはBright Dataのダッシュボード画面から取得できます。
エンドポイントが発行されるのでコピーします。
今回実際にスクレイピングしてみるサイトです。
流行りのClaude Codeにコードを書いてもらいます。
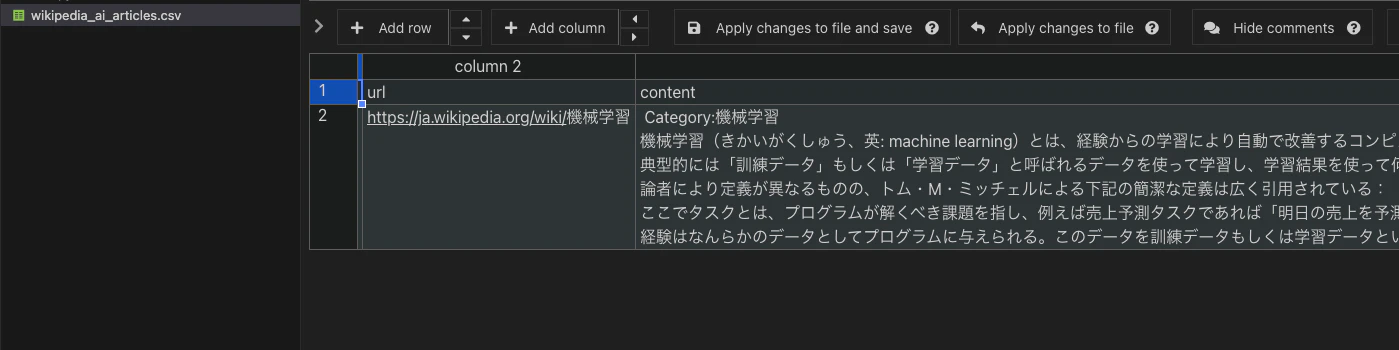
簡単にデータ取得することができました。
CSV形式になっているので加工しやすく取得できています。
比較:Selenium単体 vs Bright Data Browser API
公平に比較するために、「Playwrightの利点」と「Bright Data固有の利点」を分けて整理します。
Playwrightに切り替えるだけで得られる改善
| 項目 | Selenium | Playwright |
|---|---|---|
| 待機処理 | 明示的に記述が必要 | 自動待機(auto-wait)が組み込み |
| async対応 | 追加実装が必要 | ネイティブ対応 |
| APIの簡潔さ | やや冗長 | シンプルで直感的 |
| ブラウザ管理 | webdriver-managerで半自動 |
playwright installで完結 |
Bright Dataを追加することで得られる改善
| 項目 | Selenium / Playwright 単体 | Bright Data Browser API |
|---|---|---|
| プロキシ管理 | 自前で外部サービス契約+実装 | 自動ローテーション |
| CAPTCHA対策 | 別途ソルバーサービス契約+連携実装 | 自動解決 |
| IPブロック回避 | リトライロジックの自前実装 | 自動 |
| フィンガープリント | サイトごとに調整が必要 | 自動管理 |
| インフラ運用 | プロキシサーバーの維持管理 | クラウドで完結 |
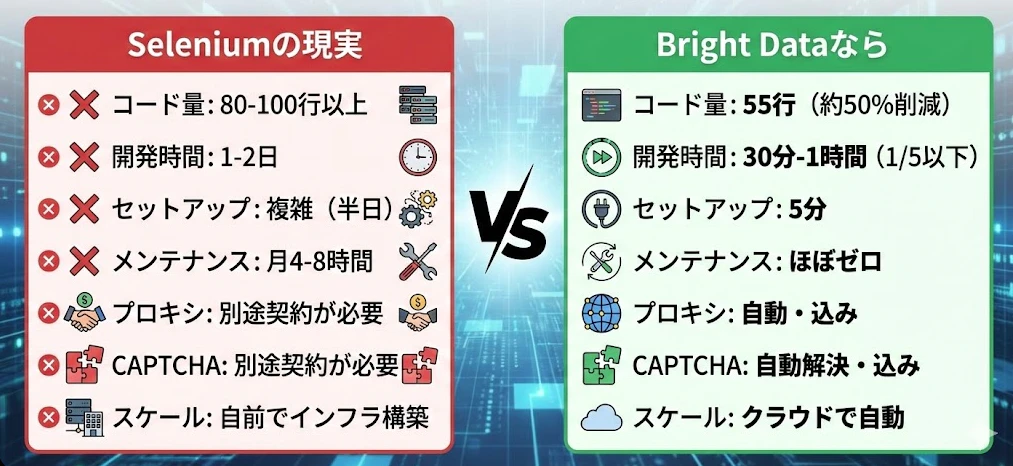
総合比較
| 項目 | Selenium + 各種外部サービス | Bright Data Browser API |
|---|---|---|
| セットアップ | ブラウザ設定 + プロキシ設定 + CAPTCHAソルバー設定 | エンドポイント接続のみ |
| メンテナンス | 各サービスの個別管理 | ほぼ不要 |
| スケーラビリティ | 自前でインフラ構築 | クラウドで自動スケール |
並列処理も簡単に実装可能
Bright Data + Playwrightの組み合わせなら、Playwrightのasync機能を活かして並列処理を簡潔に書けます。
async def scrape_parallel():
"""複数ページを並列でスクレイピング"""
async with async_playwright() as playwright:
browser = await playwright.chromium.connect_over_cdp(BRIGHT_DATA_ENDPOINT)
try:
tasks = []
for url in urls:
page = await browser.new_page()
task = scrape_wikipedia_page(page, url)
tasks.append(task)
# 全タスクを並列実行
results = await asyncio.gather(*tasks, return_exceptions=True)
return [r for r in results if not isinstance(r, Exception)]
finally:
await browser.close()
Seleniumで同等の並列処理を実現するには、スレッドごとにWebDriverインスタンスを作成し、ThreadPoolExecutorでリソース管理を行う必要があるため、実装量が増えます。ただし、これはSeleniumが同期ベースであることに起因する問題であり、Playwright単体でも同様の並列処理は可能です。Bright Dataの価値は並列処理の簡潔さではなく、並列でアクセスしてもIPブロックされにくい点にあります。
Bright Dataが特に有効なユースケース
すべてのスクレイピングにBright Dataが必要なわけではありません。以下のようなケースで特に効果を発揮します。
Bright Dataが向いているケース:
- ボット対策が厳しいECサイトやSNSからのデータ取得
- 大量ページへの定期的なアクセスが必要な場合
- プロキシやCAPTCHA対策の自前管理を避けたい場合
- 複数国・地域からのアクセスが必要な場合
Bright Dataが不要なケース:
- Wikipedia等、APIが提供されているサイトからのデータ取得
- ボット対策のない・緩いサイトへの小規模なアクセス
- ローカル環境で完結する単発のスクレイピング
まとめ
Bright DataのBrowser APIの最大の価値は、スクレイピングのインフラ課題(プロキシ、CAPTCHA、IPブロック、フィンガープリント)をワンストップで解決してくれる点です。
開発者がデータ取得のロジックだけに集中できるようになるため、ボット対策の厳しいサイトを対象にする場合には、開発効率とメンテナンスコストの面で大きな利点があります。
一方で、APIが用意されているサイトやボット対策の緩いサイトであれば、Selenium・Playwright単体でも十分です。ツールの選択は対象サイトと要件に合わせて判断しましょう。
無料トライアルで$5クレジットが使えるので、ボット対策のあるサイトへのスクレイピングで困っている方は試してみてください。