はじめに
データ基盤の選定で必ず名前が挙がる Databricks と Snowflake。機能比較の記事は多く存在しますが、「なぜその機能があるのか」「なぜそのアーキテクチャなのか」という 思想レベルの違い を理解している方は意外と少ないのではないでしょうか。
本記事では、両社の設計思想の違いにフォーカスし、それぞれが「データの世界をどう変えたいのか」を読み解いていきます。
本記事は2025年2月時点の情報をもとにしています。両社とも急速に進化しており、機能面の差は縮まりつつありますが、根底にある思想の違いは今なお色濃く残っています。
1. 生まれの違い ― 出発点が決定づけた思想
両社の思想を理解するには、まず「誰が、どんな課題を解決するために作ったのか」を知ることが重要です。
Snowflake ― 「DWHの再発明」から始まった
Snowflakeは2012年、元OracleのエンジニアであるBenoit Dageville氏とThierry Cruanes氏が創業しました。彼らは大企業のDWH統合案件を支援する中で、オンプレミスDWHの高額な初期費用やスケーリングの困難さに課題を感じていました。
当時のクラウドDWHは「オンプレミスの仕組みをそのままクラウドに載せただけ」であり、クラウドの本質的なメリットを活かしきれていませんでした。そこで クラウドにゼロから最適化したDWH を作ろうとしたのがSnowflakeの出発点です。
Snowflakeの原点 = 「DWHをクラウドネイティブに再発明する」
Databricks ― 「オープンソースの分散処理」から始まった
Databricksは2013年、UC BerkeleyでApache Sparkを生み出した研究者たち(Ali Ghodsi氏ら)が創業しました。彼らの関心は「膨大なデータを高速に分散処理し、機械学習やAIに活用すること」にありました。
Sparkというオープンソースの分散処理フレームワークを商用化し、誰でも大規模データ処理とAI開発ができる統合ワークスペースを提供しようとしたのがDatabricksの出発点です。
Databricksの原点 = 「OSSの分散処理でデータとAIを民主化する」
この出発点の違いが、以降のあらゆる設計判断に影響を与えています。
2. データの持ち方の思想 ― 「預ける」vs「手元に置く」
両社の思想の違いが最も端的に表れるのが、データをどこに・どのように保管するか という設計方針です。
Snowflake:「預けてくれれば最高の体験を提供する」
Snowflakeは、データを自社の管理する独自基盤に格納します。ストレージとコンピュートを分離した独自アーキテクチャにより、ユーザーはインフラの複雑さを意識する必要がありません。
この設計思想は 「フルマネージド」 という言葉に集約されます。データの格納方法、最適化、スケーリング――すべてをSnowflakeが引き受けることで、ユーザーは分析に集中できます。
Databricks:「データの主権は顧客にある」
Databricksは、データを顧客自身のクラウドストレージ(S3、ADLS、GCSなど)に オープンフォーマット で保存します。Delta Lake(Parquet形式ベース)というオープン規格を採用し、データが特定のベンダーにロックインされない設計になっています。
この設計思想は 「オープン性とコントロール」 に集約されます。顧客はデータの所在と形式を完全にコントロールでき、Databricks以外のツールからもアクセスできます。
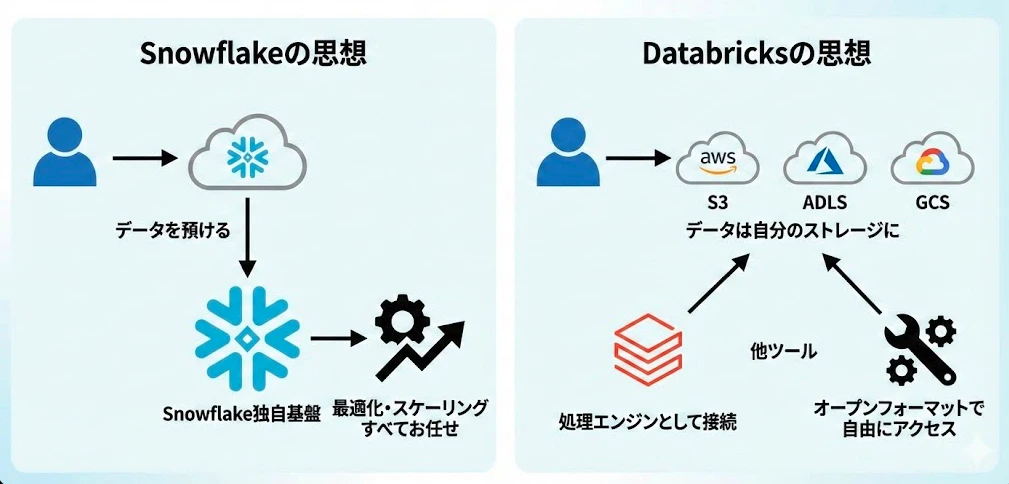
近年、Snowflakeも外部テーブル(External Tables)やApache Icebergのサポートを進めており、「預ける一択」ではなくなりつつあります。一方、Databricksもマネージドテーブルの利便性を高めており、両社の境界は徐々に曖昧になっています。
3. オープン vs プロプライエタリ ― エコシステム戦略の根本的な違い
Databricks:OSSを軸にコミュニティを巻き込む
Databricksの戦略の核心は 「オープンソースで業界標準を作り、その上に商用プラットフォームを乗せる」 というものです。
主要なOSSプロジェクトを見ると、この思想が一貫していることがわかります。
| プロジェクト | 役割 | OSS |
|---|---|---|
| Apache Spark | 分散処理エンジン | ✅ |
| Delta Lake | テーブルフォーマット | ✅ |
| MLflow | ML実験管理・モデル管理 | ✅ |
| Unity Catalog | データガバナンス | ✅ |
OSSとしてコミュニティに公開し、エコシステムを広げたうえで、エンタープライズ向けの付加価値(セキュリティ、パフォーマンス最適化、サポートなど)を商用機能として提供するモデルです。
Snowflake:独自技術で最高のUXを作り込む
Snowflakeは対照的に、独自技術で垂直統合的に最適化する アプローチを取ります。ストレージ、コンピュート、サービスレイヤーをすべて自社で設計・最適化することで、一貫した高品質な体験を提供します。
この思想はAppleのプロダクト哲学に近いものがあります。「オープンであること」よりも「最高のユーザー体験」を優先する設計判断です。
Apache Icebergを巡る攻防に見る思想の衝突
2024年、両社の思想の違いが鮮明に表れたのが Apache Iceberg を巡る動きです。
Snowflakeはオープンソースのカタログ実装 Polaris Catalog を発表し、「我々もオープンにやる」という姿勢を見せました。しかしその翌日、DatabricksはIcebergの創始者らが設立した Tabular社を買収 しました。
これは単なるビジネス上の駆け引きではなく、「オープン標準をどうコントロールするか」という思想レベルの攻防です。
4. ターゲットユーザーの違い ― 「誰の課題を解くか」
設計思想の違いは、そのまま 想定するメインユーザー の違いに直結しています。
Snowflake:「データを誰でも簡単に使える世界」
Snowflakeが第一に想定するのは、SQLを書くデータアナリストやBIユーザー です。
明快なUI、シンプルな構成、導入プロセスの簡素化、充実した自動化機能――これらはすべて「技術的な専門知識がなくてもデータを活用できる」という思想から来ています。SQLさえ書ければ、高度なインフラ知識がなくても大規模なデータ分析が可能です。
Databricks:「データとAIで何でもできる世界」
Databricksが第一に想定するのは、データエンジニアやデータサイエンティスト です。
インタラクティブなNotebook環境、Python・R・Scala・SQLの多言語対応、Sparkベースの柔軟な分散処理――これらは「技術者が自由に何でも実現できる」という思想から来ています。その分、学習コストは高めです。
| 観点 | Snowflake | Databricks |
|---|---|---|
| メインユーザー | アナリスト・BIユーザー | エンジニア・データサイエンティスト |
| 主要インターフェース | SQL | Notebook(Python/SQL/R/Scala) |
| 設計の優先順位 | シンプルさ・使いやすさ | 柔軟性・自由度 |
| 学習コスト | 低い(SQLスキルで始められる) | 高い(Spark・分散処理の理解が必要) |
| 導入のしやすさ | 簡単(フルマネージド) | やや複雑(構成の自由度が高い分) |
Databricksも近年 Databricks SQL やサーバーレス機能を強化し、SQLユーザーの取り込みを進めています。逆にSnowflakeも Snowpark やNotebook機能でエンジニア向け機能を拡充しています。ただし、それぞれの「得意分野」には今も明確な差があります。
5. AI時代における思想の進化
生成AIの台頭により、両社ともに「データ×AI」を全面に押し出していますが、そのアプローチには 根底の思想の違い が如実に表れています。
Databricks:「Data + AI カンパニー」― AI起点の進化
Databricksは自らを 「Data and AI カンパニー」 と称しています。Apache Sparkから始まり、MLflow、そしてMosaic AI(旧MosaicML)の買収を経て、データ処理からモデル学習・デプロイまでの AI開発ライフサイクル全体 をカバーする方向に進化してきました。
独自のLLM(DBRX)のリリースも象徴的です。Databricksにとって、AIはプラットフォームの中核機能であり、「データはAIのためにある」という思想が読み取れます。
Snowflake:「AI Data Cloud カンパニー」― データ起点の進化
Snowflakeは自らを 「AI Data Cloud カンパニー」 と称しています。堅牢なデータ基盤の上にAI機能を積み上げていく戦略で、Arctic LLMの発表やNVIDIAとのパートナーシップなどを進めています。
Snowflakeにとって、AI機能はあくまで データクラウドの拡張 であり、「AIがデータからより多くの価値を引き出す」という思想です。
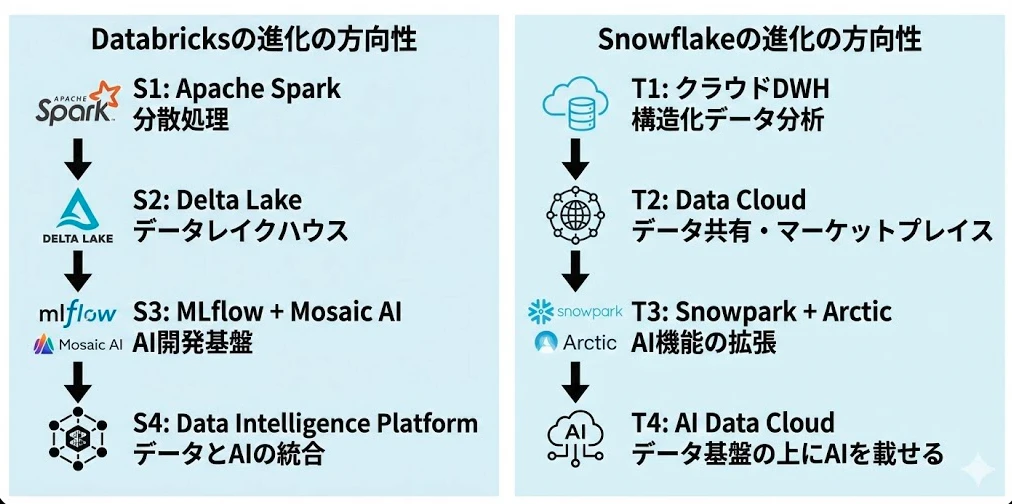
同じ「データ×AI」でもベクトルが逆 なのがポイントです。Databricksは「AI→データ」、Snowflakeは「データ→AI」という方向性で進化しています。
6. 思想の違いが現れる具体的なポイント
ここまでの内容を、比較表として整理します。
| 観点 | Databricks | Snowflake |
|---|---|---|
| 創業の原点 | OSS分散処理(Spark) | クラウドネイティブDWH |
| 設計思想 | オープン・自由・コントロール | フルマネージド・シンプル・統合 |
| データ保管 | 顧客のクラウドストレージ | Snowflake独自基盤 |
| データフォーマット | Delta Lake(オープン) | 独自(+Iceberg対応拡大中) |
| 技術基盤 | Apache Spark(OSS) | プロプライエタリエンジン |
| 得意ワークロード | ETL・ML/AI・ストリーミング | DWH・BI・アドホック分析 |
| AI戦略 | AI開発基盤そのもの | データ基盤の上にAIを追加 |
| エコシステム | OSSコミュニティ主導 | 自社プラットフォーム主導 |
| 例えるなら | Linux的(自由と選択肢) | Apple的(統合された体験) |
7. どちらを選ぶべきか? ― 思想で選ぶ判断軸
最後に、思想の違いに基づいた選定の判断軸を整理します。
Snowflakeが合う組織
- データ分析チームの中心がSQLベースのアナリスト
- できるだけ運用負荷を下げたい(フルマネージド重視)
- DWH・BIレポーティングが主要ユースケース
- 短期間で導入し、すぐに成果を出したい
Databricksが合う組織
- データエンジニアやデータサイエンティストが主力
- ML/AIのワークロードが重要な位置を占める
- ベンダーロックインを避けたい(オープン性重視)
- ETLからML開発まで一気通貫で管理したい
併用という選択肢
実際の現場では 両社を併用している企業も少なくありません。Snowflakeで構造化データのDWH/BI基盤を構築し、DatabricksでML/AIのワークロードを回す、という使い分けは合理的な選択です。重要なのは「どちらが優れているか」ではなく、「自社のデータ文化とユースケースにどちらの思想がフィットするか」という視点です。
おわりに
DatabricksとSnowflakeは、機能面では互いの領域に急速に進出しています。DatabricksはDatabricks SQLでDWH市場に切り込み、SnowflakeはSnowparkやNotebookでエンジニア向け機能を拡充しています。
しかし、それぞれの 創業の原点に根ざした設計思想 ――Databricksの「オープン性と自由」、Snowflakeの「統合された体験とシンプルさ」――は、プロダクトのあらゆる設計判断に今なお色濃く反映されています。
機能のチェックリストだけでなく、「この製品はどんな世界を目指しているのか」 という思想を理解した上で選定することが、長期的に正しいデータ基盤選びにつながるはずです。
本記事の内容に誤りや補足がありましたら、ぜひコメントでお知らせください。