はじめに
Amazonで少し高めの買い物をするとき、多くの人がレビューを参考にすると思います。
でも、人気商品だとレビューが 数百件〜数千件 あるのは当たり前。
全部読むのは現実的に不可能です。
結果として、こんな経験をしたことはないでしょうか。
- 星の平均だけ見て買ったら、自分のユースケースには合わなかった
- 上位に表示されるレビューだけ読んで判断したが、下の方に重要な指摘があった
- 「サクラレビューっぽいな」と思いつつ、見分ける時間がなくてそのまま購入した
- 似た商品が複数あるが、レビューを横断して比較するのが面倒すぎて諦めた
レビューは購入判断で最も参考になる情報なのに、量が多すぎて活用しきれない。 これが本記事で解決したい課題です。

これを実現するのが RAG(Retrieval-Augmented Generation) です。Amazonの商品データとレビューをベクトルDBに格納し、LLMが必要な情報を検索・参照しながら回答を生成します。
ただし、ここで1つ大きな問題があります。 Amazonのデータ収集(Webスクレイピング)は法的にグレーな部分がある ということです。
本記事では、この法的な課題をクリアしながら、Bright DataのDataset APIを使ってAmazonの商品データを取得し、RAGで使える状態(ベクトルDB格納済み)にするまでの全工程を解説します。
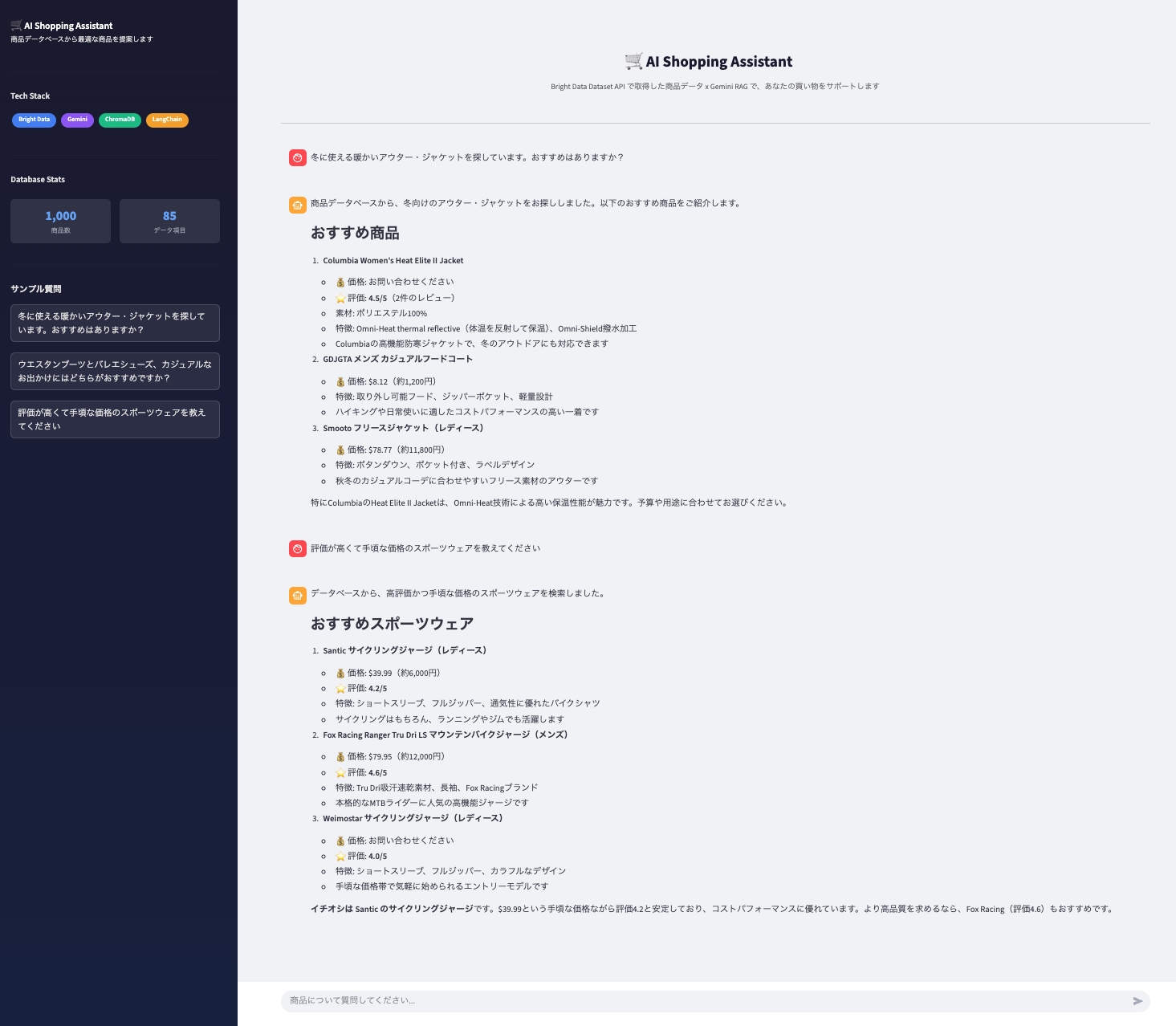
▲ 完成イメージ:数百件のレビューを踏まえて、LLMが商品の良い点・悪い点を要約し、おすすめを提案してくれる
本記事のゴール
Bright DataからAmazonの商品データ(レビュー含む)を取得し、 ベクトルDBに格納してLLMがレビュー情報を参照しながら回答できる状態 にするところまでをゴールとします。RAGのチューニング(Rerankerの導入、チャンク戦略の最適化等)は範囲外とします。
この記事ではRAGチャットボットの詳しい作り方は割愛しますので、
詳しくは下記の記事をご覧ください。
Webスクレイピングの法的整理
RAGのためにECサイトから商品データを集めたい。しかし、いきなりスクレイピングを始める前に、 法的な観点を整理しておく ことが重要です。「知らなかった」では済まされないリスクがあるからです。
本セクションは筆者の理解に基づく整理であり、法的助言ではありません。
日本における主な法的論点
① 著作権法
ECサイト上の商品説明文やレビューは著作物に該当する可能性があります。ただし、著作権法第30条の4では「情報解析の用に供する場合」の複製を認める規定があり、AI学習目的でのデータ利用はこの例外規定の対象となり得ます。とはいえ、収集したデータをそのまま公開・再配布するのは別問題です。
② 不正競争防止法
ウェブサイトがアクセス制限(ログイン必須、CAPTCHA等)をかけている場合、それを回避してデータを取得する行為は「技術的制限手段の回避」に該当する可能性があります。
③ 利用規約(ToS)
多くのECサイトは利用規約でスクレイピングを禁止しています。利用規約は契約としての拘束力を持つため、違反すると民事上の責任を問われるリスクがあります。
robots.txtを実際に確認してみる
法的リスクを判断する第一歩は、対象サイトの robots.txt を確認することです。robots.txt はサイト運営者が「どのページをクロールしてよいか」を示すファイルで、サイトのルートディレクトリに配置されています。
確認してみると分かりますが、主要なECサイトの多くは商品ページへのクロールを制限しています。つまり、 自前でスクレイピングすること自体がグレーゾーン になりやすいのが現実です。
グレーゾーンを避けるための3つのアプローチ
では、どうすれば合法的にデータを集められるのでしょうか。取れるアプローチは主に3つです。
- robots.txt / ToSが許可しているデータのみ収集する ― 最も安全だが、収集できるデータが限られる
- 公開APIがあればそちらを使う ― Amazon Product Advertising APIなど。ただし利用条件が厳しい場合が多い
- すでに合法的に収集・整備されたデータセットを使う ― 自分でクロールしないのでリスクが最も低い
本記事では 3のアプローチ を採用します。具体的には、Bright DataのDataset APIを使います。
Bright Dataは専任のコンプライアンス&倫理チームを持ち、公開データのみを対象とした収集を行っています。KYC(Know Your Customer)プロセスや厳格な利用規約によって、データ収集の合法性を担保する仕組みを整えています。「自分でクロールしない」という選択は、法的リスクの低減だけでなく、データ品質の面でもメリットがあります。
データ収集アプローチの比較
Bright Dataの話に入る前に、「なぜDataset APIなのか」をデータ収集の選択肢全体の中で位置づけておきます。
| 観点 | 自前スクレイピング | Bright Data Web Scraper API | Bright Data Dataset API |
|---|---|---|---|
| 法的リスク | 高(自己責任) | 中(プロキシ経由だが自分で収集) | 低(Bright Data側がコンプライアンス担保) |
| データ品質 | パース・クレンジング自分持ち | 構造化済み | 構造化・クレンジング済み |
| 運用コスト | サイト構造変更で壊れる | Bright Dataがアンブロック対応 | メンテナンス不要 |
| 柔軟性 | 何でもできる | カスタマイズ可能 | 用意されたスキーマに依存 |
| 導入コスト | 低(OSSで無料) | 中 | 中 |
自前スクレイピングは柔軟性が最大の強みですが、法的リスクと運用コストを考えると、個人開発やPoC段階ではBright Data Dataset APIが合理的な選択肢です。構造化済みのデータがAPIで取れるので、 スクレイピング基盤の構築ではなく、RAGパイプラインの設計に集中できる というのが最大のメリットです。
Web Scraper APIは「特定のサイトを自分の条件でクロールしたい」場合に有効です。Dataset APIでカバーされていないサイトや、リアルタイム性が必要な場合はこちらが選択肢になります。本記事では扱いませんが、発展的なユースケースとして覚えておくとよいでしょう。
Bright Dataのセットアップ
無料トライアル登録
まずはBright Dataの無料トライアルに登録します。以下のリンクから登録できます。
▲ 無料トライアルの登録画面。メールアドレスとパスワードを入力するだけで始められます。
ダッシュボードからDataset APIへアクセス
登録が完了したら、ダッシュボードにログインします。
▲ Bright Dataのダッシュボード。ここからDataset Marketplaceにアクセスします。
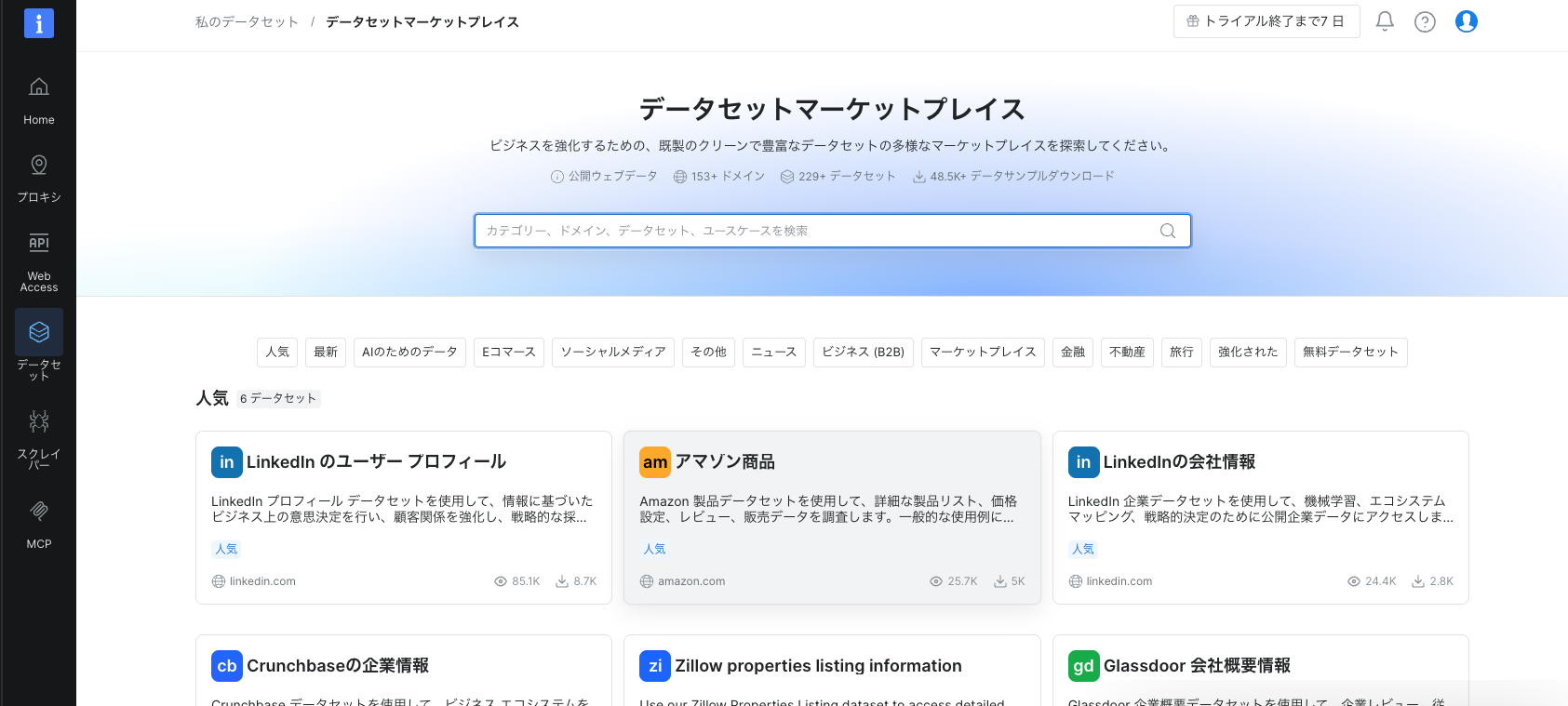
eCommerceデータセットを選ぶ
Dataset Marketplaceには、EC・SNS・不動産など100以上のドメインのデータセットが用意されています。今回はeCommerce(EC)カテゴリのデータセットを選びます。

▲ Dataset MarketplaceのeCommerceカテゴリ。Amazon、Walmartなど主要ECサイトのデータセットが並んでいます。
データセットに含まれる主な項目は以下の通りです。

商品名・価格・評価といった構造化データと、商品説明文・レビューといった非構造化データが両方含まれているのが特徴です。これはRAG構築にとって非常にありがたいポイントです。
サンプルデータを取得する
Dataset APIのデータセットは有料ですが、 購入前にサンプルデータをリクエストできます 。本記事ではこのサンプルデータを使ってRAGパイプラインを構築します。
サンプルデータでもデータ構造やスキーマはフルデータセットと同じなので、パイプラインの検証には十分です。本番環境で商品数を増やしたい場合は、フルデータセットを購入してそのまま差し替えるだけでOKです。
サンプルデータの取得は無料です。まずはサンプルでパイプラインを組んでみて、うまくいったらフルデータセットに切り替えるという進め方がおすすめです。
データの前処理とベクトルDBへの格納
サンプルデータが取得できたら、RAGで使える形に加工してベクトルDBに格納します。
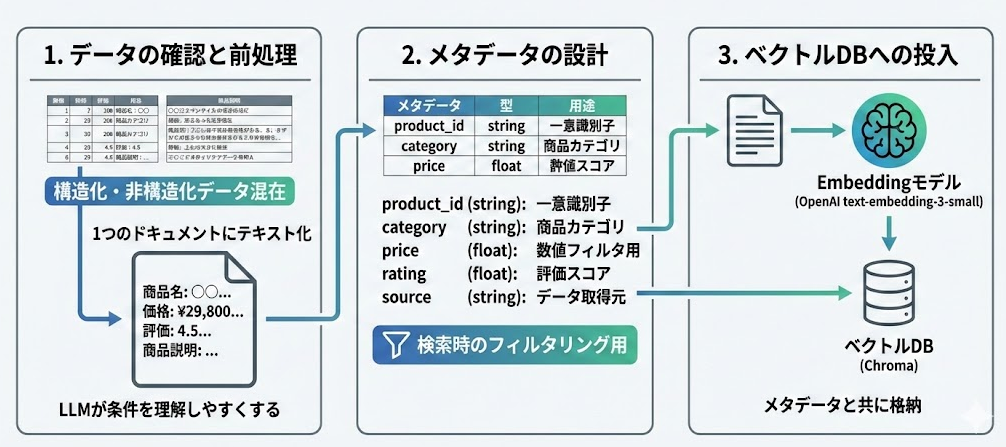
データの確認と前処理
取得したサンプルデータを確認すると、1つの商品レコードの中に 構造化データと非構造化データが混在 していることが分かります。
- 構造化データ: 価格、評価スコア、レビュー数、在庫状況 → 数値・カテゴリ値
- 非構造化データ: 商品説明文、レビューテキスト → 自然言語
RAGでは、これらをテキスト化してEmbeddingに変換する必要があります。本記事では、 商品ごとに1つのドキュメントとしてまとめる シンプルなアプローチを採用します。
具体的には、各商品について以下のようなテキストを生成します。
商品名: ○○○○
ブランド: ○○
価格: ¥29,800
評価: 4.5 / 5.0(レビュー数: 1,234件)
在庫: あり
商品説明: ○○○○○○○○○○...
構造化データもテキストとして埋め込むことで、LLMが「予算3万円以内」「評価4以上」といった条件を理解しやすくなります。
メタデータの設計
ベクトルDBに格納する際には、Embeddingだけでなく メタデータ も付与します。メタデータを使うことで、検索時にフィルタリングが可能になります。
| メタデータ | 型 | 用途 |
|---|---|---|
| product_id | string | 商品の一意識別子 |
| category | string | 商品カテゴリ(「椅子」「デスク」等) |
| price | float | 価格(数値フィルタリング用) |
| rating | float | 評価スコア |
| source | string | データ取得元のECサイト名 |
ベクトルDBへの投入
前処理したテキストをEmbeddingモデル(本記事ではOpenAIの text-embedding-3-small を使用)でベクトル化し、メタデータとともにベクトルDB(Chroma)に格納します。
動作確認:LLMが商品データを読めることを確認する
最後に、ベクトルDBからコンテキストを取得し、LLMに渡して回答を生成できることを確認します。
クエリ例:レビューを考慮したおすすめの商品検索
ユーザー: 「評価が高くて手頃な価格のスポーツウェアを教えてください」
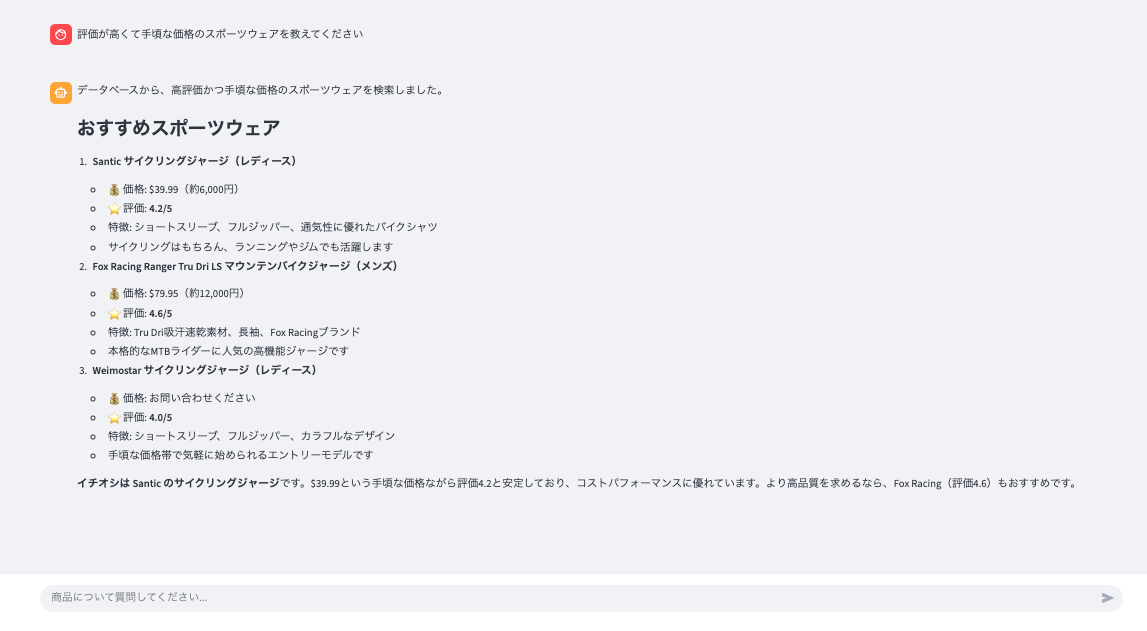
まとめ
Bright Dataを使って実感したこと
実際にBright Dataを使ってみて感じた価値は3つです。
「自分でクロールしない」安心感 ― 法的リスクを気にせずデータ収集ができるのは、精神的にも実務的にも大きなメリットでした。robots.txtの確認やToSの解釈に時間を費やすことなく、RAGパイプラインの設計に集中できます。
構造化済みデータのありがたさ ― スクレイピングで一番面倒なのはパースとクレンジングです。Dataset APIから返ってくるデータはすでにJSON形式で構造化されているので、前処理の工数が大幅に削減されました。
サンプルデータで気軽に試せる ― フルデータセットを購入する前にサンプルで検証できるのは、PoCフェーズではとても助かります。パイプラインが動くことを確認してからフルデータに切り替えればよいので、無駄なコストが発生しません。
Bright Dataの無料トライアルはこちらから登録できます。本記事の内容をぜひ手元で試してみてください。
https://get.brightdata.com/qiita50