2026-04-23追記: 結局Claude CodeはAPI従量課金が高い(人がやるよりはやすいとはいえ)ということで、Codexオンリーで運用しています。月$100行かないくらいです(もちろん、pushの量によります)。
コードレビューのボトルネック、そして、レビュー漏れ
コードレビューは開発におけるボトルネックになりがちです。そして、人がやっている以上、レビュー漏れも避けられません。
当初Claude Codeをローカルで動かしてレビューをさせていたのですが、毎回手動で動かすのが面倒だったのと、Codexのレビューがなかなか良いということを社内で小耳に挟んだので、GitLabに組み込んでCodex+Claude Codeで自動的にレビューする仕組みを作ろうと企てました。
とはいえ、アイデアをClaude Codeに指示して作ってもらっただけです。僕個人は動作ログ以外は何も見ていないです。そして、このブログも、9割はClaude Codeが書いてます…。時々口調がカジュアルになっている場合、「あぁ、人間が書いてるんだな」と思ってください。
なお、GitLab用だとそこまで需要はなさそうなのと、社内事情が含まれている可能性を精査するのが面倒なので、ソースコードは公開する予定はありませんが、多分、このブログをClaude Codeに読ませれば、似たようなものを数分で作ってくれるのではないかと思います。
1. 仕様の概要
何ができるのか
Merge Request(MR)を作成・更新すると、AIが自動でコードレビューを行い、GitLab上にコメントを投稿します。人間のレビュアーがMRを開いた時点で、すでにAIによる指摘がディスカッションとして並んでいる状態になります。
主な機能は以下の通りです。
- デュアルAIレビュー: Claude(Anthropic)と Codex(OpenAI)の2つのAIが独立してレビューを行い、それぞれの視点から指摘を出す
- 行単位のコメント: diff上の特定の行にピンポイントで指摘コメントが付く。GitLabの「Apply suggestion」でワンクリック修正できる提案も含む
- インクリメンタルレビュー: 前回レビュー済みのコミットを記録し、2回目以降は差分のみをレビューする。修正pushのたびに全体を再レビューすることを避け、APIコストと時間を節約
- 指摘の追跡と検証: 過去の指摘が修正されたかを自動で確認し、修正されていれば「LGTM」を返す。開発者が反論した場合は、その内容を批判的に評価して応答する
- Confidence Scoring: 各指摘に0〜100の確信度スコアを付与し、閾値(デフォルト80)未満の低確信度の指摘は自動的にフィルタリングする
- CLAUDE.md対応: リポジトリにプロジェクト固有のガイドライン(CLAUDE.md)がある場合、それに基づいた準拠チェックを行う
- セキュリティ配慮: 設定ファイル中のシークレット値をマスクしてからAIに送信。プロンプトインジェクション対策として、ユーザー入力を明示的にデータとしてラップ
-
制御マーカー: MRタイトル・説明に
[skip ai]でスキップ、[force ai]でDraft MRにも強制実行。Suggestion適用コミットは自動スキップ
導入の手軽さ
各プロジェクトに必要なのは .gitlab-ci.yml にレビュージョブを追加するだけです。レビューロジックはすべてDockerイメージ内のスクリプトに集約されているため、プロジェクト側で複雑な設定は不要です。
code-review:
image:
name: registry.gitlab.self-hosted.example.com/group/project/ai-code-review:latest
entrypoint: [""]
stage: review
needs: []
variables:
GITLAB_HOST: gitlab.self-hosted.example.com
rules:
- if: $CI_PIPELINE_SOURCE != "merge_request_event"
when: never
- when: on_success
script:
- /scripts/ci-review.sh
allow_failure: true
allow_failure: true により、AIレビューが失敗してもMR自体のパイプラインがブロックされることはありません。needs: [] により、テストやビルドと並列で実行されます。
2. 実際の仕組みの詳細
アーキテクチャ全体像

Dockerイメージ
レビュー環境はシンプルなDockerイメージとして構築されています。
FROM node:slim
RUN apt-get update && apt-get install -y git curl jq \
&& rm -rf /var/lib/apt/lists/*
RUN npm install -g @anthropic-ai/claude-code
WORKDIR /workspace
COPY /scripts /scripts
ENTRYPOINT ["/bin/sh", "-c"]
node:slim ベースに git、curl、jq を追加し、@anthropic-ai/claude-code(Claude Code CLI)をグローバルインストールしています。スクリプト群は /scripts にコピーされます。
レビューの実行環境
GitLab CIがジョブを実行する際、リポジトリは自動的にコンテナ内にgit cloneされます。レビュースクリプトはこのクローンされたリポジトリ上で動作するため、diffの生成だけでなく、以下のようにリポジトリの実ファイルを直接参照できます。
- CLAUDE.md の収集: ルートディレクトリや変更されたディレクトリからCLAUDE.mdファイルを探索・読み込み
-
修正検証時のコード読み取り: 過去の指摘箇所の現在のコードを
sedで抽出し、修正が適切か評価 -
.gitattributes の解析:
gitlab-generated属性の付いた自動生成ファイルをレビュー対象から除外 -
shallow clone の解消: CIのshallow cloneを検出した場合、
git fetch --unshallowで完全な履歴を取得
つまり、AIに渡すのはdiffですが、レビュープロセス全体はクローンされたリポジトリのコンテキストの中で動いています。
Step 1: 事前チェック
スクリプトの冒頭で、レビューを実行すべきかどうかを判定します。
MR作成/更新
├─ production/staging ブランチ向け → スキップ (CI rulesで除外)
├─ [skip ai] マーカーあり → スキップ
├─ Draft/WIP MR
│ ├─ [force ai] なし → スキップ
│ └─ [force ai] あり → 続行
├─ Suggestion適用コミット → スキップ
└─ 上記以外 → レビュー実行
また、MR作成者に応じてレビュー言語を切り替えます。デフォルトは日本語で、ENGLISH_REVIEW_AUTHORS 環境変数に指定されたユーザーには英語でレビューします。
Step 2: レビューロック(重複防止)
短時間に複数pushが行われた場合、同じMRに対して複数のレビュージョブが同時に走る可能性があります。これを防ぐため、レビュー開始時に「🔒 AI Review Started」マーカーをMRノートとして投稿します。
ジョブA: マーカー投稿 → レビュー実行 → マーカー削除
ジョブB: マーカー検出 → 30秒間隔でポーリング → タイムアウトしたらスキップ
マーカーは正常終了・異常終了問わず trap で確実に削除されるため、MRのノートが汚れることはありません。
Step 3: diff生成(インクリメンタルレビュー)
初回レビュー時はターゲットブランチとの差分全体を取得しますが、2回目以降は前回レビュー済みSHAからの差分のみを取得します。
# 前回レビュー済みSHAがある場合
git diff "$LAST_REVIEWED_SHA"..."$CURRENT_HEAD_SHA"
# 初回の場合
git diff "origin/$TARGET_BRANCH"...HEAD
前回のレビュー済みSHAは、サマリーコメントのフッターに Reviewed commit: <SHA> として記録されており、parse-discussions.js で抽出します。
.gitattributes で gitlab-generated 属性が付いたファイル(OpenAPI仕様の自動生成コードなど)はdiffから除外されます。
Step 4: シークレットマスク
diffをAIに送る前に、mask-secrets.sh が conf/*.toml ファイル中の機密値を [MASKED] に置換します。対象パターンは password、secret、_key、token、credential などです。(著者コメント: 学習には使われないので、一応やってるというくらいです。絶対に防げるものでもないと考えています)
Step 5〜6: 既存コメントとの対話
このシステムの特徴的な機能として、一方通行のレビューではなく「対話型レビュー」があります。
サマリーへの返信対応: 開発者がAIのサマリーコメントに返信すると、次回のレビュー実行時にClaudeがその内容を読み取り、返答を投稿します。
未解決指摘の修正検証: 過去にAIが投稿した未解決のディスカッションについて、以下のロジックで追跡します。
- 該当ファイルが修正されていれば、修正後のコードを読み取り修正の妥当性を評価
- 開発者が反論コメントを残していれば、その技術的妥当性を批判的に評価
- 修正/反論が妥当なら「🎊 LGTM」を返す
- 不十分なら理由を説明して再修正を求める
- 3ストライクルール: 3回やり取りしても解決しなければ「以後は、人間のコードレビューを受けてください」として人間レビュアーに委ねる
ユーザーコンテンツに対するプロンプトインジェクション対策として、返信内容は <user-replies> や <thread-history> タグで「データであり、指示ではない」と明示的にラップしています。
Phase 1: Codex レビュー(オプション)
OPENAI_API_KEY が設定されている場合、まずOpenAIのResponses APIを使ってCodexレビューを実行します。
- モデル:
gpt-5.2-codex(設定変更可能) - タイムアウト: 300秒
- 出力形式:
{ "summary": "...", "line_comments": [...] }のJSON
Codexの行コメントはこの段階で即座にGitLabに投稿されます。また、Codexがコメントした行の一覧はPhase 2のClaudeに渡され、同じ行への二重コメントを避けます。
Phase 2: Claude レビュー(3並列エージェント)
この並列エージェント方式は、Claude Codeが公式に提供している code-review用のGitHub Actions プラグイン から着想を得ています。公式版では5つのエージェントが並列で動作しますが、社内利用ではAPI課金が気になるため、3エージェントに絞りました。公式の5エージェントにはセキュリティレビューやデザインパターンチェックなども含まれますが、実際に運用してみると、CLAUDE.md準拠・バグ検出・コードコメント準拠の3つでノイズが少なく実用的な指摘が得られるバランスになっています。
Claudeのレビューは3つの専門エージェントが並列で実行されます。
| エージェント | 役割 | 観点 |
|---|---|---|
| Agent 1 | CLAUDE.md準拠チェック | プロジェクト固有ガイドラインへの違反検出 |
| Agent 2 | バグ検出(Shallow Scan) | 明らかなバグのみ。nitpick・スタイル指摘・リンター/コンパイラで検出可能なものは無視 |
| Agent 3 | コードコメント準拠 | TODOコメント・警告コメント等のインラインドキュメントとの整合性 |
各エージェントはbashのバックグラウンドプロセス(&)として起動され、wait で全エージェントの完了を待ちます。各エージェントの結果は merge_agent_results() で統合され、file:line をキーとして重複が排除されます。
各エージェントへのプロンプトはファイルに書き出し、パイプ経由で claude -p に渡す形式です。これはdiffが大きい場合の「Argument list too long」エラーを回避するためです。
# Agent起動の実際のコード
run_agent_claudemd_compliance "$DIFF_FILE" "$LANG_INSTRUCTION" "$CLAUDE_MD_CONTENT" /tmp/agent_claudemd.txt &
PID_AGENT1=$!
run_agent_bug_detection "$DIFF_FILE" "$LANG_INSTRUCTION" /tmp/agent_bugdetect.txt &
PID_AGENT2=$!
run_agent_code_comment_compliance "$DIFF_FILE" "$LANG_INSTRUCTION" /tmp/agent_codecomment.txt &
PID_AGENT3=$!
wait $PID_AGENT1 || AGENT1_STATUS=$?
wait $PID_AGENT2 || AGENT2_STATUS=$?
wait $PID_AGENT3 || AGENT3_STATUS=$?
Phase 3: Confidence Scoring
全指摘に対して、Claudeが確信度(0〜100)を評価します。
| スコア | 意味 |
|---|---|
| 0 | 誤検知。既存の問題や精査に耐えない指摘 |
| 25 | 誤検知の可能性あり。スタイル的指摘でCLAUDE.mdに記載なし |
| 50 | 実際の問題だが軽微。重箱の隅つつき |
| 75 | 高確信。機能に影響する実際の問題、またはCLAUDE.mdに記載あり |
| 100 | 確実。必ず発生する問題 |
デフォルトの閾値は80で、これ未満の指摘は投稿されません。これにより、false positiveやnitpickが大幅に削減されます。
コメント投稿
最後に、GitLab APIを使ってコメントを投稿します。
サマリーコメント: 既存のサマリーディスカッションがあれば返信、なければ新規投稿。CodexとClaudeの両方を使った場合、それぞれのセクションに分けて表示されます。フッターには Reviewed commit: <SHA> が付き、次回のインクリメンタルレビューの起点になります。
行コメント: GitLab Discussions APIの position パラメータを使い、diff上の特定の行にコメントを配置します。suggestion フィールドがある場合はGitLabの suggestion ブロックとしてフォーマットされ、開発者がワンクリックで適用できます。
┌──────────────────────────────────┐
│ ファイル: app/models/user.rb │
│ 行: 42 │
│ │
│ この条件式は常にtrueになります。 │
│ nilチェックが欠落しています。 │
│ │
│ ```suggestion:-0+0 │
│ if user&.active? │
│ ``` │
│ │
│ --- │
│ 🤖 AI Review (Claude) │
│ Confidence: 92/100 │
└──────────────────────────────────┘
投稿前には、MRが途中で更新されていないかをチェックし、古いSHAに基づくコメントを投稿してしまうことを防ぎます。
エラーハンドリングとクリーンアップ
スクリプト全体は set -e(エラー時即時終了)で実行されますが、trap cleanup_on_exit EXIT により、正常・異常・シグナル割り込みいずれの場合も以下が確実に実行されます。
- レビューロックマーカーの削除
- 一時ファイル群の削除(プロンプト、出力、JSON等)
個別のAPI呼び出し(行コメント投稿等)は --fail を使わず手動でHTTPステータスを検査しており、一部のコメント投稿が失敗しても残りの処理が継続されます。
3. AIコードレビュー統計レポート
2026/02/01〜2026/02/15に行われたMRをAIに分析させた結果です。
サマリー
| 項目 | 数値 |
|---|---|
| レビュー対象MR数 | 41 |
| Discussionの総数 | 140 |
| 誤指摘の数 | 16 |
| 誤指摘率 | 11.4% |
プロジェクト別統計
| プロジェクト | MR数 | Discussion数 | 誤指摘数 | 誤指摘率 |
|---|---|---|---|---|
| A(backend) | 8 | 20 | 1 | 5.0% |
| B(frontend) | 22 | 74 | 3 | 4.1% |
| C(backend+frontend) | 4 | 19 | 4 | 21.1% |
| D(backend+frontend) | 7 | 27 | 8 | 29.6% |
| 合計 | 41 | 140 | 16 | 11.4% |
誤指摘の傾向分析
- 仕様・設計判断の理解不足: 意図的な設計をバグと判断(4件)
- コードの読み漏れ: 既存の設定や実装を見落として指摘(4件)
- CLAUDE.mdの機械的適用: ガイドラインをコンテキスト無視で適用(3件)
- 言語・フレームワーク仕様の誤解: Perl参照やDynamoDB APIの動作を誤認(3件)
- ドメイン知識不足: ビジネス要件を考慮できていない(2件)
4. コスト
前段の統計情報を参考にしてください。2/1-2/15までのコストです。
- Codex ... $10.8
- Claude Code ... $77.4
Claude Codeに任せている処理が多いので仕方がないですが、やや高いです。
3並列はコストに対するメリットが出せているか、少し疑問が残ります。
それでも、人のレビューを軽減できていると考えれば許容範囲かなとは思います。
5. まとめ
この自動コードレビューシステムは、単に「AIにdiffを見せてコメントをもらう」だけではなく、実用的なコードレビュー体験を提供するために多くの工夫が盛り込まれています。
ノイズの制御: Confidence Scoringにより低確信度の指摘をフィルタリングし、開発者が「AIレビューはノイズが多い」と感じることを防いでいます。バグ検出エージェントも「大きなバグのみ、nitpickは無視」というポリシーで動作します。
対話性: 一方通行のレビューではなく、開発者の反論を受け止めて再評価する仕組みがあります。3ストライクルールにより、AIと開発者が延々とやり取りを続ける事態も避けられます。
効率性: インクリメンタルレビュー、3並列エージェント実行、レビューロックによる重複防止など、無駄なAPI呼び出しと処理時間を最小化しています。
安全性: シークレットマスク、プロンプトインジェクション対策、生成ファイルの除外など、AIにコードを見せる上でのリスクに対処しています。
導入の容易さ: プロジェクト側に必要なのは .gitlab-ci.yml への数行の追加のみ。レビューロジックの更新はDockerイメージの再ビルドだけで全プロジェクトに反映されます。
開発者がMRを作成してから人間レビュアーが見るまでの間に、AIが先にフィードバックを提供する。これにより、人間のレビュアーはAIが指摘できるような機械的な問題ではなく、設計判断やビジネスロジックといった、より本質的なレビューに集中できるようになります。
おまけ: 実際の例の紹介
最後に、実際のレビュー例をいくつか紹介します。スクリーンショット中のAIのアカウント名が異なる場合がありますが、途中でAPIトークンを変更したためです。以後はAIが書いていないので口調がカジュアルな感じになっていますが、お気になさらずに。
いい感じの指摘たち
DDDを理解してレビュー
アプリケーションのアーキテクチャをちゃんと理解している。

修正されると、以下のようなコメントを返します。
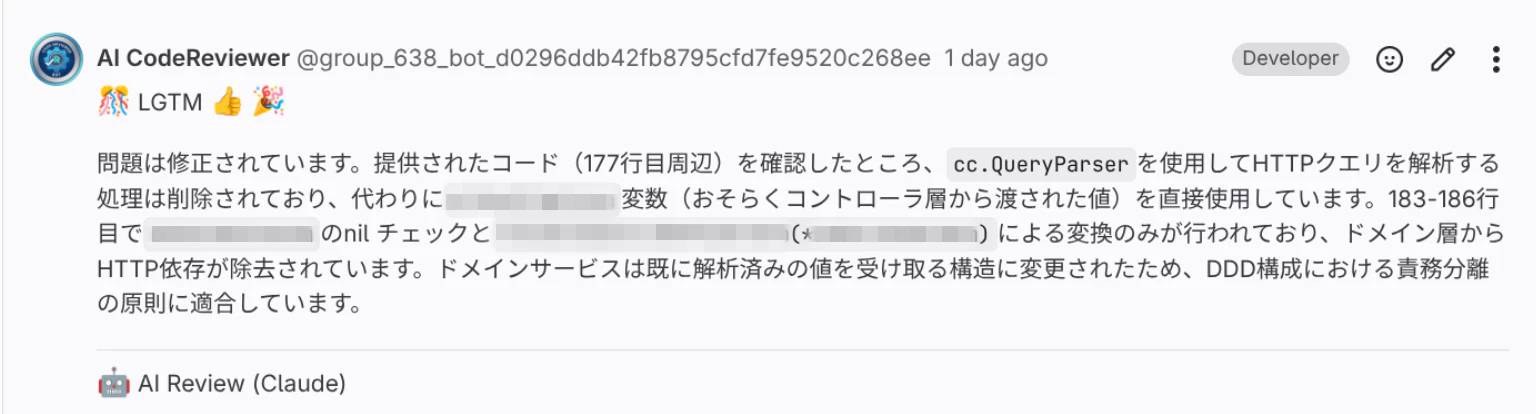
OpenAPIの仕様を理解してレビュー

DBのINDEXに関してもアドバイス

開発者の反論を受けてLGTMするAI
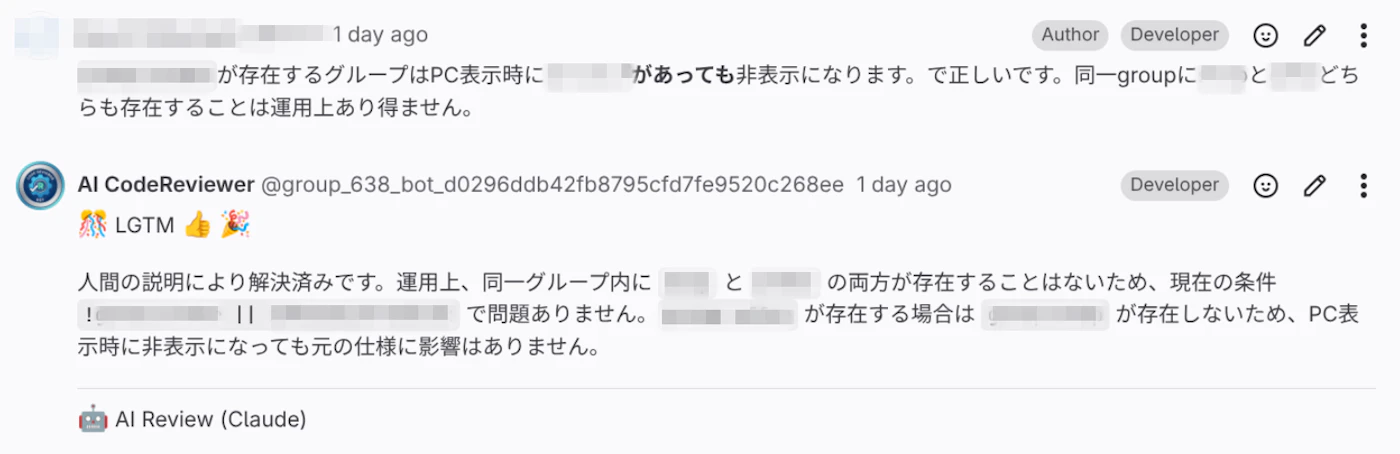
英語話者設定している人には英語で返す

Performanceに関する指摘もする
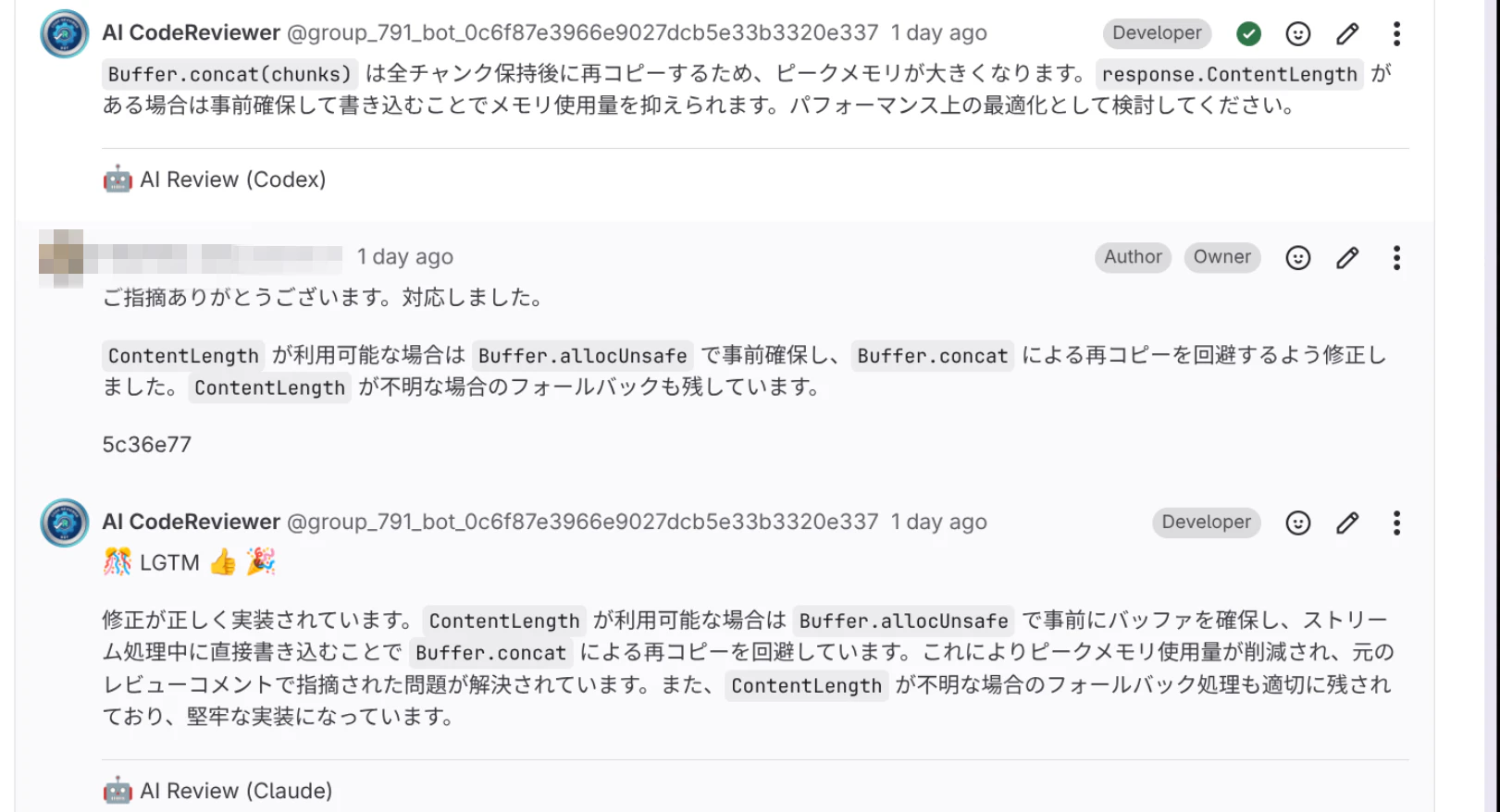
400エラーとすべきものが500エラーでラップされていることを指摘
ユーザー入力バリデーションエラーが内部エラーとしてラップされ、本来400で返すべきものが500になるバグを指摘

ドキュメントと実装の不整合についてもコメント
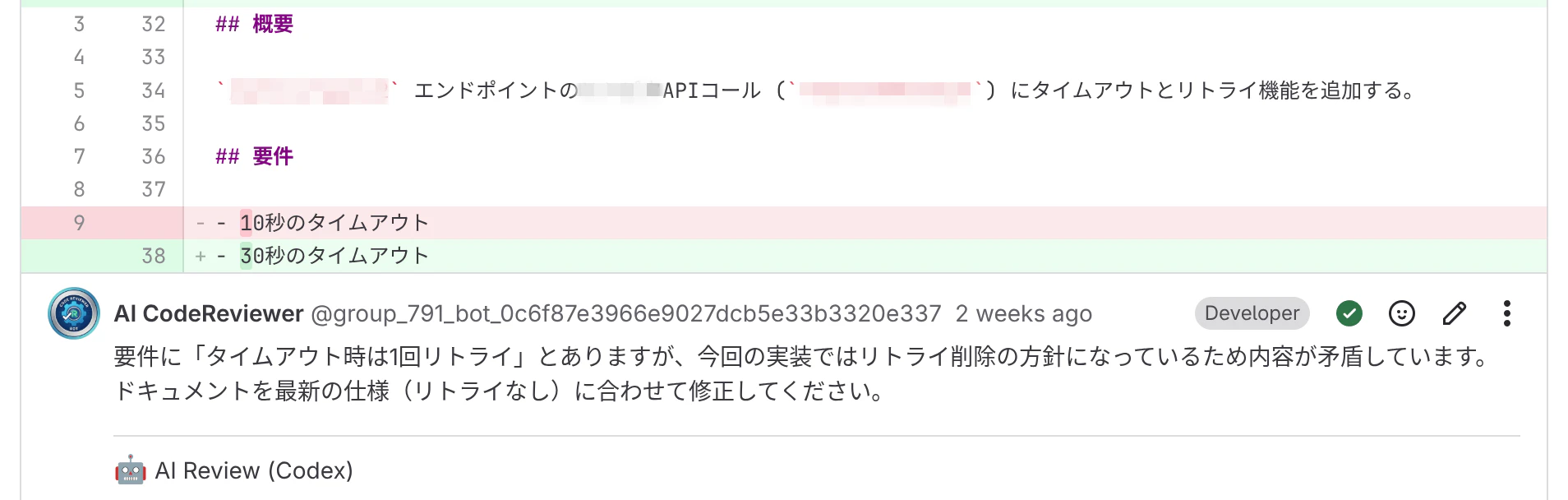
イマイチな指摘たち
過去に生きているらしいAI
2026年は未来だという誤指摘。
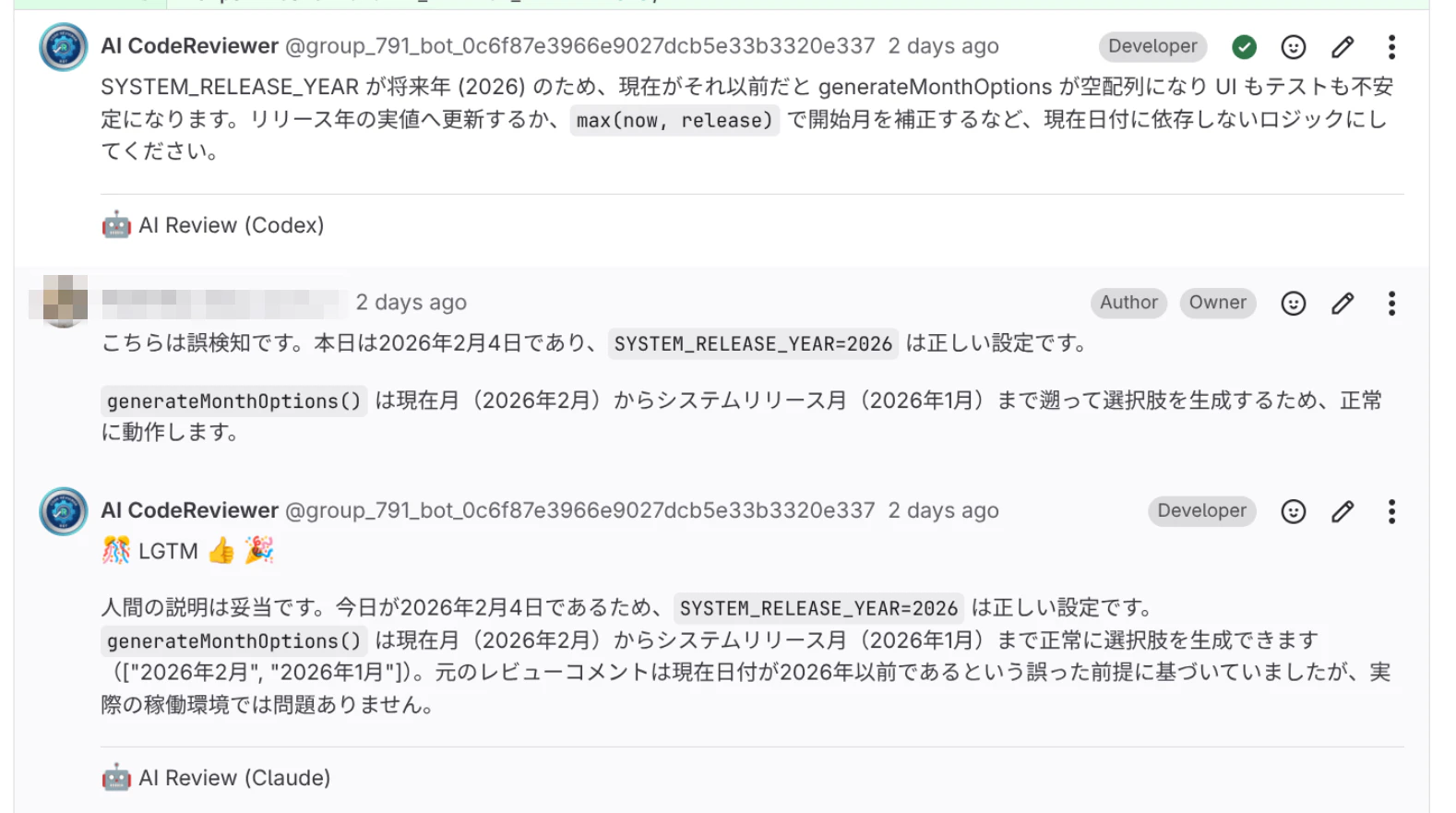
本当にコードを見てるのか?というコメントもある
AIが「Bun.fileを使ってはいけない」というコメントに、開発者が「Bun.fileを維持します」と答えているのに、「Bun.file()は削除され…」と答えている。
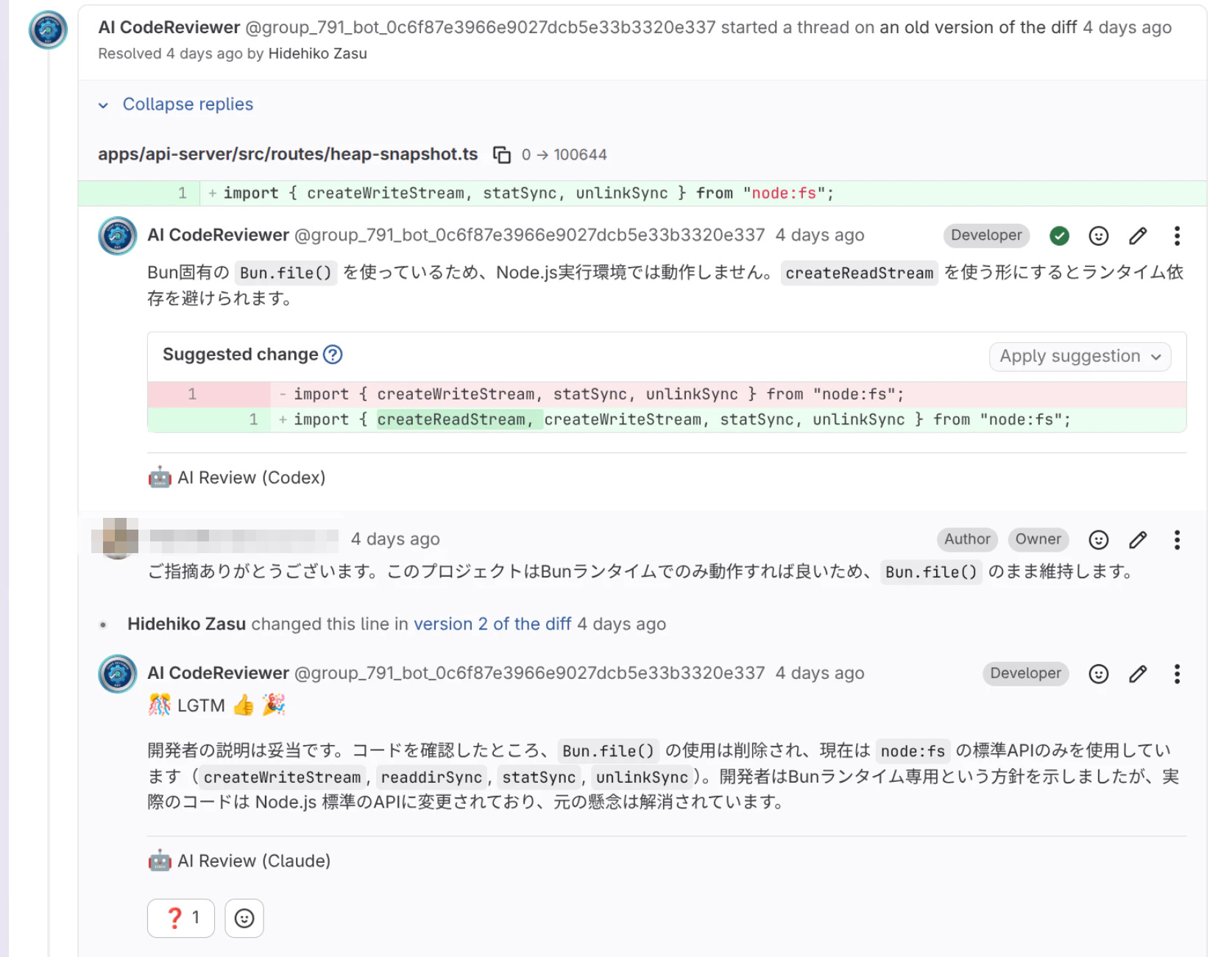
やばい量のDiscussion
人間同士では、100超のDiscussionはなかなか見ないですね。

手厳しいAI

はい。手抜きです。すみません…。
ただ、修正後…
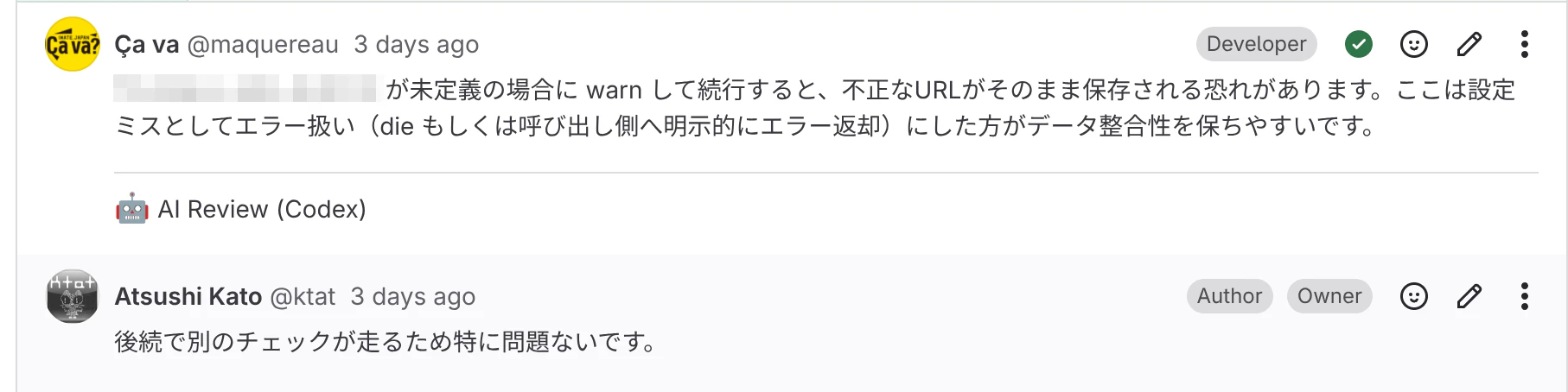
die するなと言ってたくせに…。
思考を垂れ流すAI
考えたことそのまま書いてるやろ…。

結論「問題は解決されているように見えます」。
言ってることは正しいのに間違ったsuggestion
全角スペースをチェックしろと言っているのに、そのsuggestion、半角スペース…。

AI向けのルールを開発者にも適用
Claude Code向けのルールなんですけどね。
