本記事は日本オラクルが運営する下記Meetupで発表予定の内容になります。発表までに今後、内容は予告なく変更される可能性があることをあらかじめご了承ください。下記セッションでは、本記事の内容以外にデモンストレーションも実施する予定です。
※セミナー実施済の動画に関しては以下をご参照ください。
はじめに
2022年暮れ、ChatGPTの登場以降、あらゆる企業がDXの在り方を問われはじめ、大規模言語モデルの仕組みをどのように業務に取り入れるかを検討されていると思います。
その検討の一つとして、「GPT(LLM)が学習していない企業内のデータや最新のデータも有効活用すべき」 という点は非常に大きな論点なのではないでしょうか。
ご存じの通り、LLMとはインターネット上に存在するドキュメントデータをクローリングにより大量に収集し、それを学習データとして機械学習にかけたモデルです。
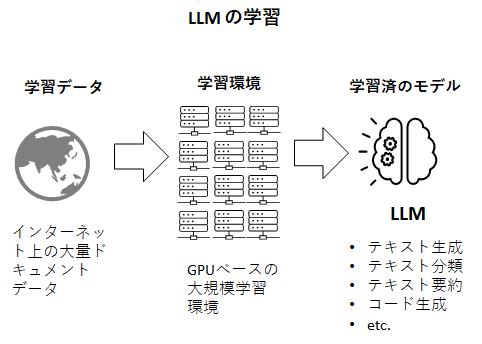
従って、至極当たり前の話ですが、LLMは学習したデータに入っていなかった情報に対する推論はできません。昨日発売されたばかりの新製品の市場での反応や、インターネットに公開されていない社内ドキュメントに関する情報を答えることはLLMプロバイダが提供するデフォルトのLLM(ファウンデーションモデル)ではできないのです。
LLMは深層学習の産物であり、その深層学習について知見のある方はファインチューニングと呼ばれる手法があることをご存じだと思います。ファインチューニングとは公開されている学習済のモデルに、独自のデータを追加で学習させ、新たな知識を蓄えたモデルを作り出す技術。LLM以外でも深層学習の世界では伝家の宝刀のように広く知れ渡っており非常に一般的なプラクティスです。
したがって、ファウンデーションモデルが学習していないデータについても答えてほしい場合はこのファインチューニングをすればいいということになりまs。が、実務レベルでファインチューニングを実装した方であれば、ある一つの疑問が必ず生まれるはず。OpenAI社に限らず、現在世界中のLLMプロバイダが提供しているモデルはインターネットから得られた大量のテキストデータを学習した数千億のパラメータを持つ超巨大推論モデル。いくらファインチューニングが定石手法と言っても、自分が作った独自データで、果たして、この超巨大モデルが持つ推論の方向性を適切に変えることができるのか?と。
この問いに対する答えとしては、「結局、機械学習はやってみないとわからない」となり、データを作り学習させるという膨大な時間を要する作業なしに、事前に何か確認する手法というものは残念ながらありません。
そしてファインチューニングが効いているかどうかを確認する作業は、例えるなら、砂場に砂金を投げ込み、再度その砂金を回収しようと試みるようなものです。他の深層学習ではいざ知らず、この“ちょっと変わった”LLMと呼んでいる推論モデルにおいて、この作業が常に効果的かどうかは疑問が残ります。
そんな中、やはりファイチューニング以外の数々の手法も模索されており、本記事ではその中でも、ベクトルストアを使い、LLMが学習していない社内データなどを処理対象にすることができる実装サンプルをご紹介します。
※ファインチューニングについてご興味ある方はこちら
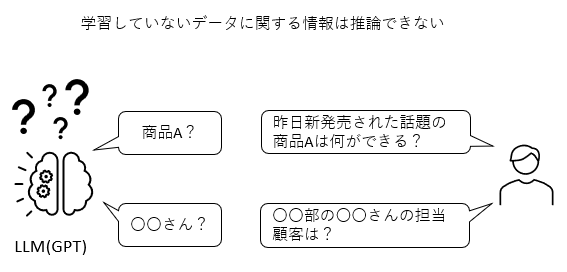
ChatGPTが知らないであろう質問をしてみる
ChatGPT(本記事の場合GPT3.5)が学習しているデータは2021年9月までのデータです。LangChainは2022年10月にリリースされたOSSですのでChatGPTに質問してみても当然以下のようにお馴染みのちょっとつれない回答。
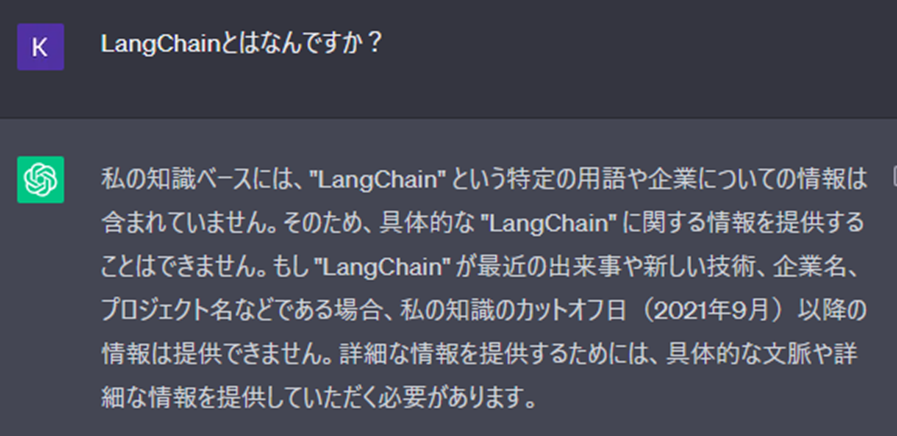
Wikipedia LangChain
もっとわかりやすい例はこちら。
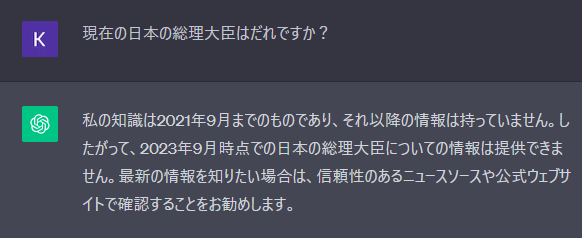
今回は、この状態からベクトルデータベースとの連携により、LangChainに関する知識を追加してみます。
ChatGPT(LLM)が知らない知識をベクトルストアで補完(RAG構成)
ファインチューニングとの違い
ファインチューニングでは、LLMが持っていない知識を、LLMに追加で学習させ、LLM自体を賢くするというアプローチでした。それに対し、ベクトルストア併用の構成では、LLMが知らない情報をベクトルストアにため込んでおいて、LLM単体ではなく、ベクトルストアとの合わせ技で最終的な回答を作れるようにします。
あまり専門用語は使いたくないのですがこれはRAG(Retrieval-Augmented Generation)と呼ばれる構成として非常に有名で、LLMが持っていない知識をLLM外部の情報ソースで補うことを目的としたものです。
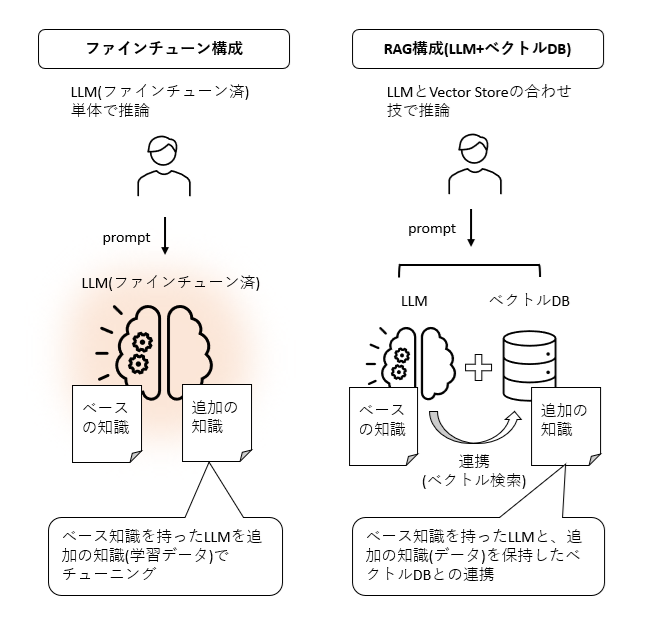
「追加の知識」とはどのようなデータなのか
となると、この「追加の知識」とは一体どういうものなのか?というところが重要になってきます。現在、ベクトルデータベースにため込むドキュメントデータとして主だったものは以下の3つです。
-
企業内のデータ
企業が持つ社内ドキュメントや、社員が日々作成しているドキュメントデータというものはインターネットに公開されていないものが多々あると思います。当然ながら、LLMプロバイダーが提供しているデフォルトのLLMはこれら企業内データを学習していませんので推論できないということになり、「追加の知識」の最有力候補となります。 -
専門性の高いデータ
基本的にTransformerタイプのLLMはファインチューニングやRAGを構成しなくても、なるべくLLM単体で推論ができることを目的として作られています。ですが、特に専門性の高いデータ(例えば、医療、法律、金融などなど)について言うと、現在一般的に提供されているLLMの推論精度はその分野の専門家が満足するレベルには至っていません。こちらは海外、国内の様々な団体や企業が業界特化型のLLMを開発する市場動向がありますが、まだまだ多くの企業がこのような取り組みを行える状況ではなく、簡単に専門性の高いデータを生成AIの対象にできる構成は需要が高いといっていい状況だと思います。 -
インターネットに公開されて間もない最新データ
LLMはあるインターネットから一定期間ため込まれた情報を使って学習処理を行った結果作られるものであり、インターネットに公開されて間もない最新データは学習していない可能性があります。最新の情報までをカバーしてタイムリーに精度高い推論ができることが求められるシステムも多々あります。
RAGの構成と処理フロー
このようなデータにも対応できるようにするために、RAG構成の一つとして、LLMとベクトルデータベースの合わせ技があります。その合わせ技の処理フローとしては以下の図のような感じで、前回同様にLangChainと呼んでいるフレームワークがLLMとベクトルストアを連携させる形でpromptから推論します。
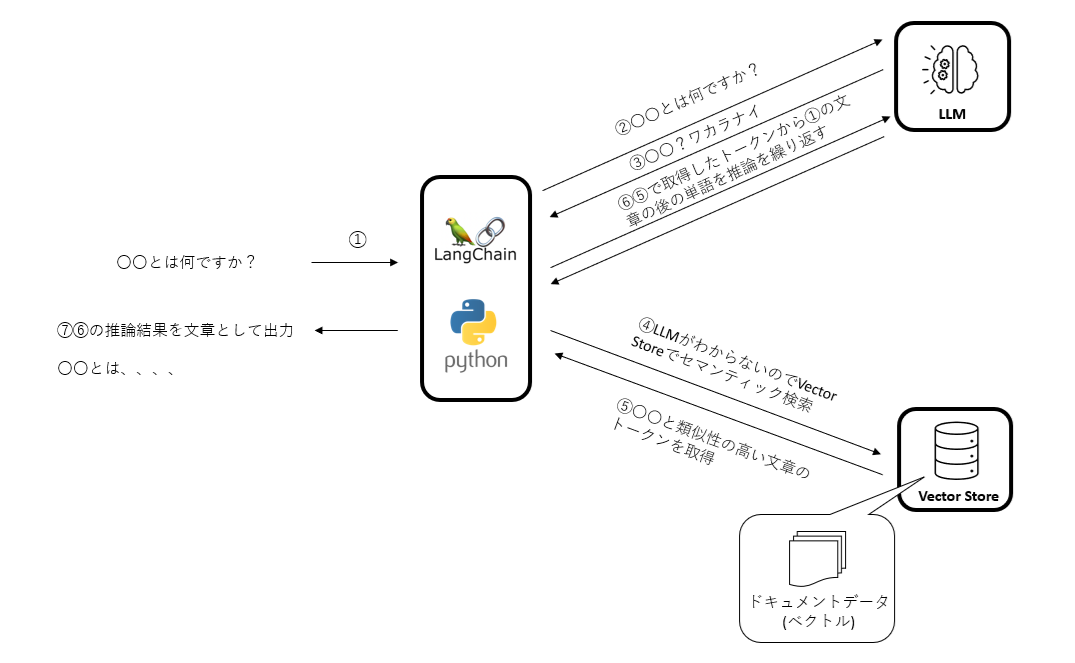
つまり、LLMが知らない情報が入力された際、ベクトルストアに、そのヒントをもらって、そのヒントをベースに最終的な文章をLLMが生成するという流れです。この構成では、ファイチューニングのようにLLMの再学習は必須ではありません。従って、学習用データを作る必要はないのですが、その代わりに、ベクトルストアを構築し、運用するという工数が発生します。
RAGの実装サンプル
この構成の主役は前回の記事でもご紹介したLangChainです。非常に広く使われおり、資金調達もうまくいっているライブラリなのでしばらくは安心して利用できそうです。ということで、上記フローの主だった登場人物としては以下3つとなります。
- LLM
- LangChain(とPython実行環境)
- Vector Store
そして今回も、Oracle Cloudをふんだんに使っていきたいと思います。(とは言え、コードや構成自体はOSSで構成したときと全く同じです。)
- LLM -> OpenAI社のGPT
- LangChain(とPython実行環境) -> Oracle CloudのData Science Service
- Vector Store -> Elasticsearch on OCI IaaS(marketplace)
つまり構成としては下図のようになります。
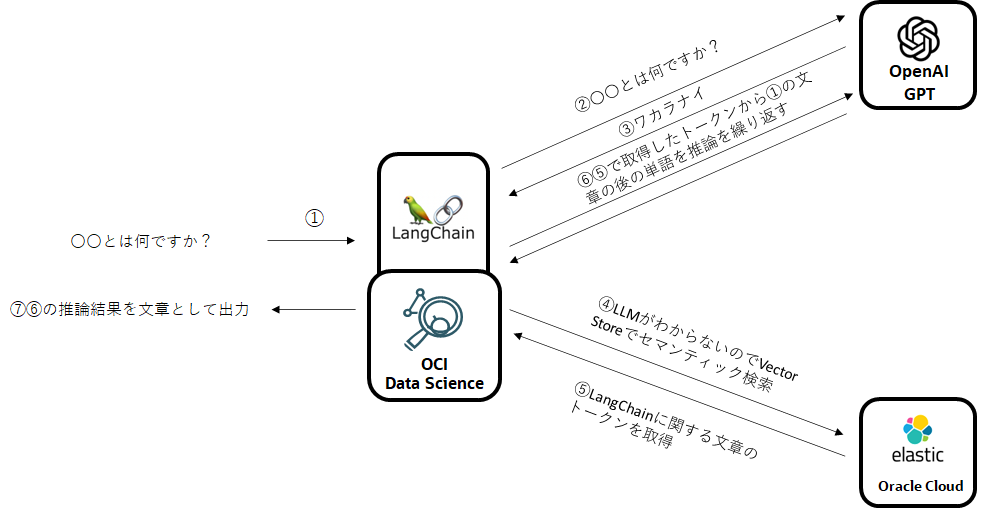
※ちなみに、LangChainがサポートするLLMやベクトルデータベースの一覧は下記から参照できます。
LLM(大規模言語モデル)
LLMは数値ではなく、自然言語という言葉を入力し推論するという少し変わったモデルです。とは言え機械学習で作られたモデルですから、学習データを用意して、統計処理にかけてモデルを完成させるという深層学習の作業はその他の機械学習と何ら変わりません。
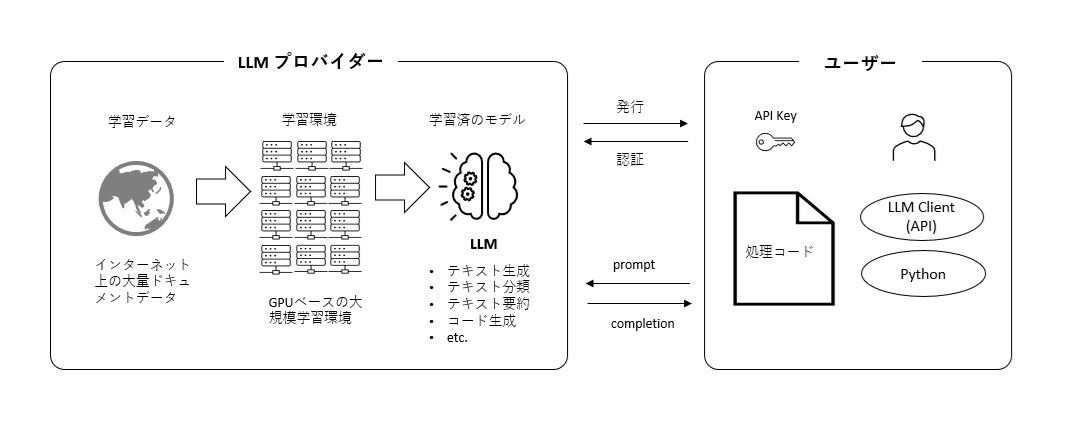
上図はLLMプロバイダーが提供しているクラウドサービスの利用イメージを記載しています。それ以外にオープンソースのLLMなどローカルにダウンロードして利用するパターンもあります。
他の機械学習と大きく違う点は、LLMの場合、ユーザーは学習処理はせず、OpenAIなど、既に学習されたモデルを利用するケースが多いという点です。その理由はLLMの学習データの性質に起因します。
LLM以外のモデルは自社で学習データを用意して学習処理から行い自社でモデルを開発しなければいけないケースが多くあります。それは、その学習データがその企業固有のデータだからです。
それに対してLLMはどうでしょうか。上述した通り、LLMは一般的な言葉が学習データとなるモデルです。言葉に「ある企業固有の言葉」というものは基本的にはありません。日本語はどこの企業でもどこの国でも同じ日本語です。
また言葉を学習データとする場合、そのデータの入手に困ることはないでしょう。インターネットに膨大なドキュメントデータが存在し、誰でも入手できるわけですから。
となれば、このデータを使って、優れたLLMを提供しようというLLMプロバイダーが沢山出現しても何ら不思議はなく、ユーザーはこれらプロバイダが提供するサービスを利用することで、学習処理を行う必要もないということになります。
そういう理由から現在この市場には沢山のLLMプロバイダーが存在し、巨額の投資マネーも手伝い、一大マーケットが形成されつつあるという状況で、その最先端にいるのがまさにOpenAI社ということになります。
もちろん、LLMをゼロから開発するという企業も沢山存在します。特に最近では日本語の精度を高くすることにフォーカスしたモデルだったり、法律関係など専門的な分野にフォーカスしたモデルを開発して公開している企業や研究機関はあります。その他、セキュリティの観点からLLMを自社開発する企業もあります。
ただ、LLMのモデル開発は大規模な学習環境が必要なため莫大なコストを要する点や、最新の学習手法(特に分散学習や学習パラメータ数を減らす手法)については数々のフレームワークがありそれぞれにpros/consがあるという状況で一般的には技術的な難易度が非常に高いと言われています。ですので、多くのユーザーは既に学習済のモデルを使ったり、そのモデルをベースとしてファインチューニングするという選択をとる傾向にあります。
LangChain
現在、LLM周辺には様々なフレームワークのライブラリが存在します。有名なところだと以下のようなものです。
- LangChain
- LlamaIndex
- Sementic Kernel
どのツールもLLMと、その他のサービスとの連携を主な目的としたフレームワークになっており、LLMからの連携先のサービスに応じて、様々な処理を抽象度の高い関数でシンプルにコーディングできる非常に多機能なライブラリとなっています。これらのフレームワークの一番の老舗であるLangChainの主だった連携サービスを見てみると以下のようなものになります。
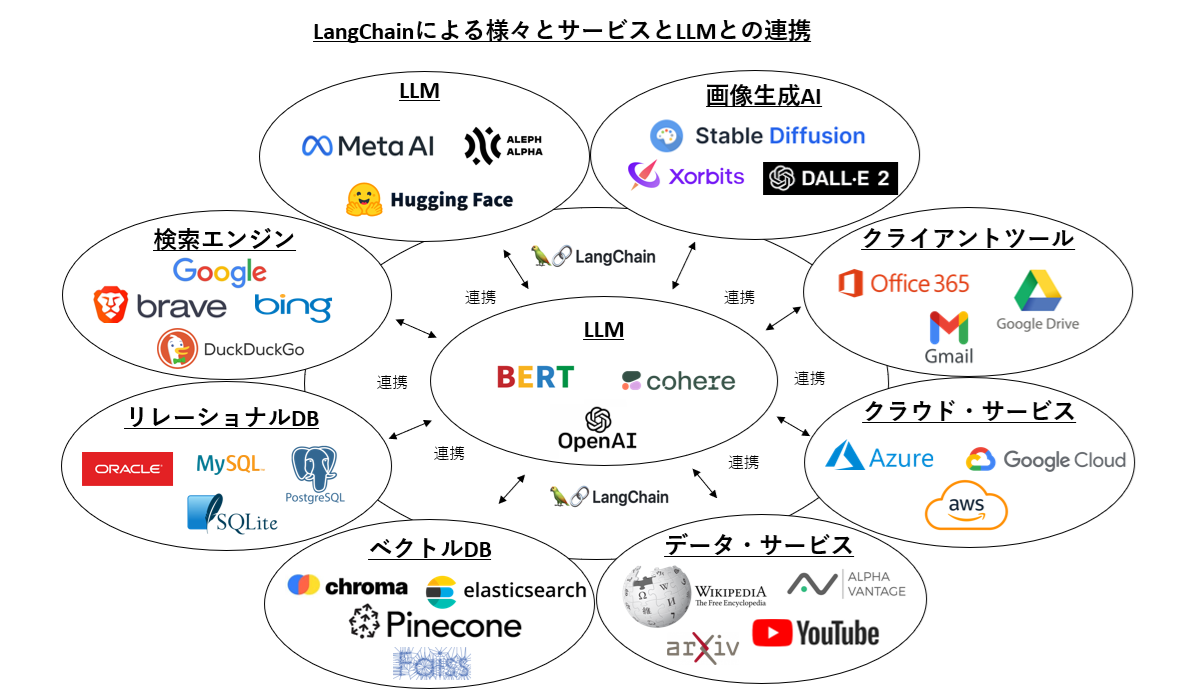
連携構造としては非常にシンプルで、LLMと、連携サービスとの間にLangChainが位置し、連携の司令塔となります。LangChainはLLMや、連携サービスとの接続を保持しており、処理したい内容に応じて、プロンプトをLLMに連携したり、LLMから得られた情報を、その他のサービスに連携したり(その逆も行います。)と、データフローとしてはLLMと連携サービスの間を行ったり来たりすることになります。このような処理を各サービスのAPIを使ってゼロベースで開発すると相当なコード量になりますが、LangChainはそこを抽象化し、数行のコードで実現できるようなライブラリになっています。
前回の記事(下記リンク)ではリレーショナルDBとの連携を取り上げましたが、今回はベクトルDBです。
ベクトルデータベース
RDBとの違い
ベクトルデータベースは呼称に「データベース」が付いていますので、もちろん、データを貯め、検索して必要なデータを取り出すことを目的としています。ただ、一般的なデータベース(いわゆるRDBなど)とは異なり貯めこむデータがベクトルデータとなり、それに付随して様々な違いがあります。
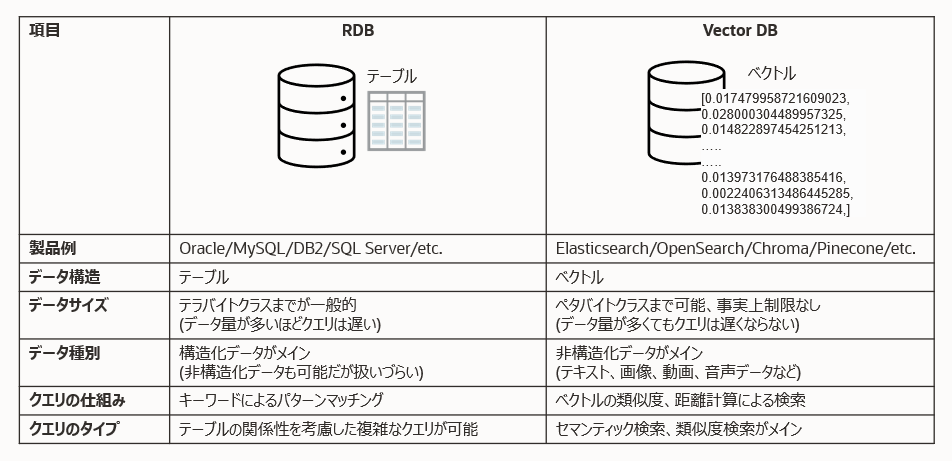
そしてこのベクトルデータベースは、LLMとは非常に相性がいいです。LLMでは文章はベクトルに変換して処理するからです。文章や単語はテキストデータの状態では統計関数に入力することができないため、必ず量的データに変換する必要があり、それがベクトルデータということになります。
文章を数値データに変換する処理:Embedding(埋め込み)
文章をどうやってベクトルに変換するのか?それはEmbeddingと呼ばれる処理を行うことで変換が可能になります。このEmbedding自体もLLMの機能で行いますし、Embeddingの処理だけを対象としたLLMなども世の中には沢山あります。
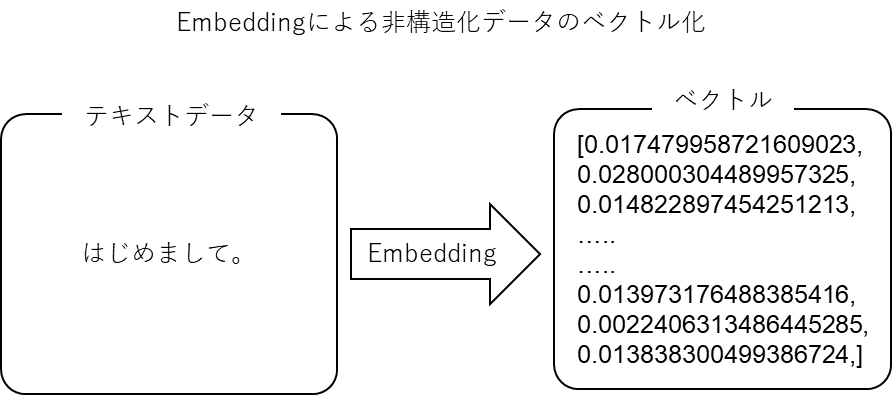
上図のように、Embeddingの処理によって文章がベクトル(ありていに言うと数値データ)に変換されるので計算する(様々な関数に入力する)ことができるようになります。
※GPTのEmbeddingについてより詳しく知りたい方はこちら
※Embeddingに使うモデルはOpenAIだけではありません。その他のLLMプロバイダーやオープンソースのLLMも十分に使えます。
ここでの本質は、このベクトルの値がどのように決まるのか?どいったロジックでベクトルに変換されるのか?ということだと思います。それに関連するキーワードが意味空間というものです。
意味空間
文章(や単語)をベクトル化することにより、文章を計算することができるようになるのは上述した通りです。ですが、もう少し厳密にいうと、「文章(や単語)」ではなく、「文章(や単語)の意味」を計算できるようになります。仮に、この意味空間が二次元だとした場合、下図のようなイメージです。意味の近い単語は近いベクトルを持ちます。
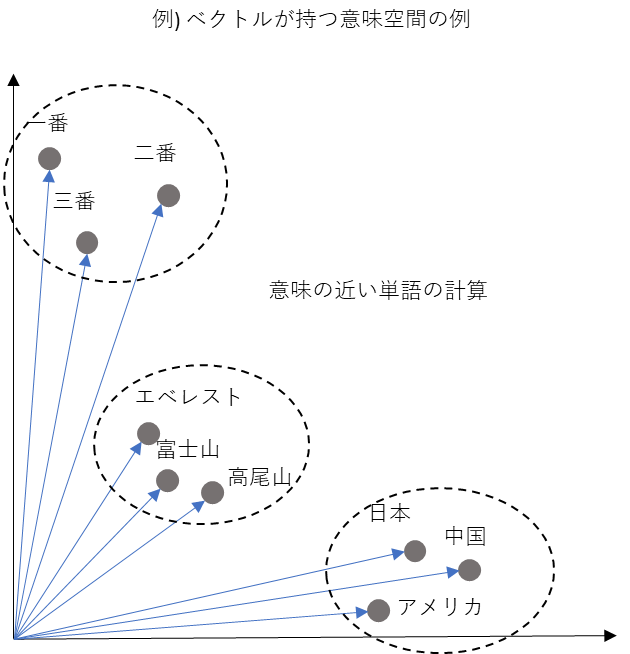
このベクトル化をすることで単語同士の意味の近さを計算したり、単語の意味自体を計算することができるようになります。単語の意味を計算する例として下記はあまりにも有名です。
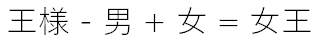
これは単純な四則演算の例ですが、LLMの推論処理やベクトルストアでのセマンティック検索、類似検索でも要領は同じです。これらは統計処理のようなもっと高度な演算処理を行います。
「ベクトル化」ではなく「埋め込み」と呼ぶ理由
Embedの処理は「埋め込み」、「埋め込みベクトル」、「埋め込み表現」なんて言われ方をします。初めて聞かれた方はこの「埋め込む」という表現がイメージし辛いのではないでしょうか。
上述の二次元の意味空間は、各単語の属性のようなものをベースに近しいベクトルになるように筆者が適当に絵を書いたものです。この中の、例えば、「富士山」という単語は「山」という意味合いを持ちますから、他の山と近しいベクトルの絵にしました。ですが、「富士山が位置する国は日本」という意味合いにおいては「日本」という単語のベクトルのほうに最も近くないといけないはず。そして、「富士山は日本で標高が一番高い」という意味合いにおいては「一番」という単語のベクトルと一番近くなければいけないはずです。このように単語は文脈の中で様々な意味をもちますので、実際は例示したような二次元ではとても表すことができず、現在市場に出回っているLLMのEmbedモデルはだいたい753次元~2048次元という高次元のベクトルを生成するものが主流です。
つまり、単語や文章をEmbedすると、下図のように、それらはLLMが事前学習した高次元の意味空間に埋め込まれるようなイメージが理解しやすいのではないかなと思います。
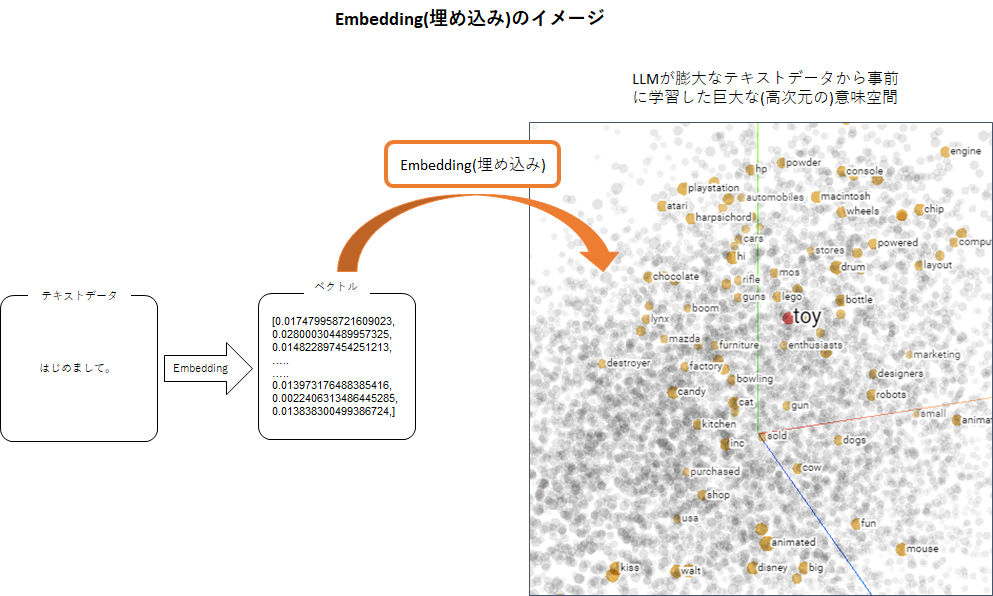
このようにして、文章データを変換したベクトルを大量にベクトルデータベースにため込んで検索ができるようにします。
RDBでは貯め込んだデータを検索するためにクエリを実行しますが、ベクトルデータベースの検索処理とはは、セマンティック検索ということになります。セマンティクスとは日本語で「意味論」を指し、セマンティック検索とはRDBのような単に検索キーワードの一致による検索ではなく、そのキーワードが持つ意味を考慮した検索を行うということです。これは成就y津したように文章データをベクトルデータに変換(意味空間にマッピングする)ことにより実現する機構です。
ベクトルデータベースのセマンティック検索、類似度検索
例えば、先ほどの二次元の意味空間を持ったベクトルデータベースに「東京」というトークンで検索した場合を考えてみます。
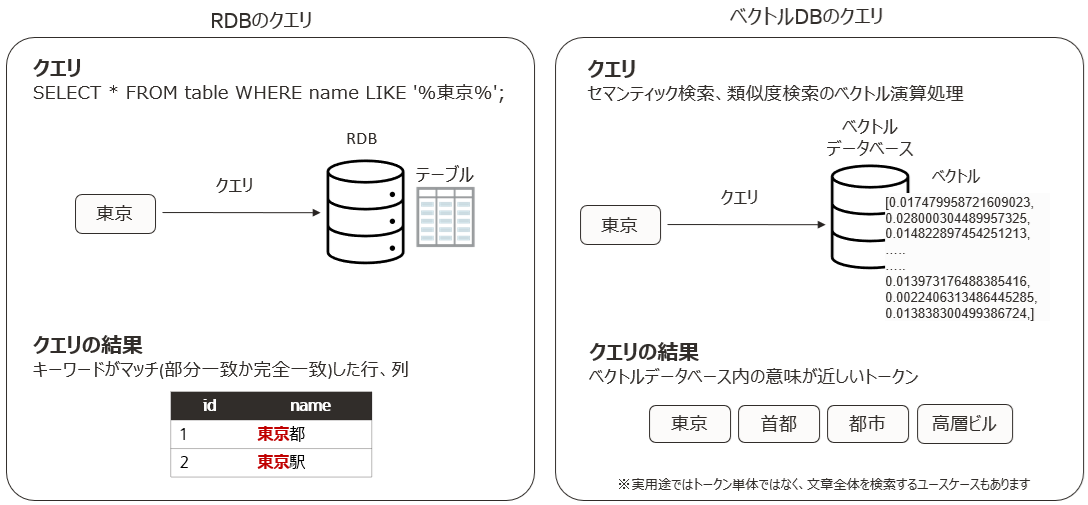
RDBではname列の「東京」という文字が一致した行を検索しその結果が得られることがわかります。これは単純に「東京」というキーワードが部分一致しているかどうかだけで検索をしているという状況です。
それに対してベクトルデータベースでは上述したように「東京」という単語が持つ意味を考慮したクエリ結果が得られるイメージです。「東京」という単語は日本の首都であり、都市であり、高層ビルが立ち並ぶエリア、という様々な意味合いがあります。これら意味合いの近い単語がベクトルデータベースに保存されている場合、セマンティック検索によって、これら近い単語の検索が可能になります。
ベクトルデータベースではどのようにベクトルの類似度を計算しているのか
Embeddingの処理では似た意味をもつ単語は近しい値のベクトル値が割り当てられます。したがって、セマンティック検索をすることによって、そのベクトル値がどれくらい近い値なのかを計算し、意味合いの似た単語を検索することができるようになります。
この際、ベクトル値が近いとは具体的にどういう状況を意味するのか?という点が重要です。私達は高校の代数・幾何学の授業でベクトルとは「向き」と「大きさ」を持つ量的データと習ったはずです。まあ実際には「量的データ」という単語は使っていなかったとしても「ベクトルとは向きと大きさ」と学習したはず。
ということは、ベクトルの「向き」と「大きさ」を計算しさえすればベクトルの類似度を測れるということになり、ひいては意味の近い単語を検索しているということになるわけです。
この向きと大きさの計算に使われる計算手法が以下のようなものです。
- ベクトルの「向き」
- コサイン類似度、ドット積
- ベクトルの「大きさ」
- ユークリッド距離
呼称から難解な計算をしている印象を受けますが、非常にシンプルな演算処理です。
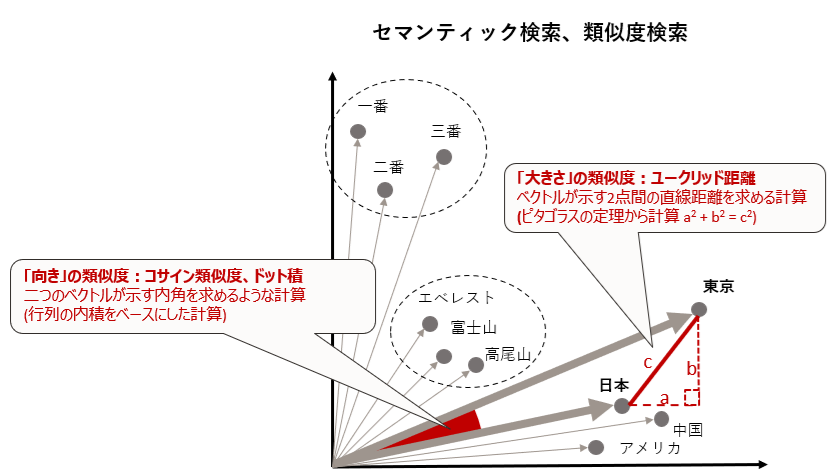
ざっくりいうと、やっていることは
- コサイン類似度やドット積
- ベクトルの内角に関係する計算をしている
- 内角が小さいほど似たような「向き」となり、近しいベクトルとなる
- ベクトル(行列)の内積をベースに計算
- ユークリッド距離
- ベクトルが示す2点間の直線距離を測る計算をしている
- 距離が近いほど似たような「大きさ」となり、近しいベクトルとなる
- ピタゴラスの定理から計算
という感じです。行列演算もピタゴラスの定理も私達が中高生の時に勉強した内容ですよね。そんなシンプルな計算で最終的に高度な処理ができるのはまさにその前工程でEmbeddingをしているからということになります。
ベクトルデータベースで行われるベクトル演算の効率化
ただし、シンプルな演算処理とは言え、クエリの度にベクトルデータベース内の全てのベクトルとの行列演算をするのは非常に非効率です。RDBに例えるとクエリを実行した際に全表捜査が実行されてしまうイメージです。RDBではそうならないようにするためにパーティショニングや、索引を作りますよね。ベクトルデータベースでも似たようなことをしています。それは、膨大な数のベクトルデータを、値の近しい集団に分類して、グループ単位で処理することにより演算処理を効率化するというものです。
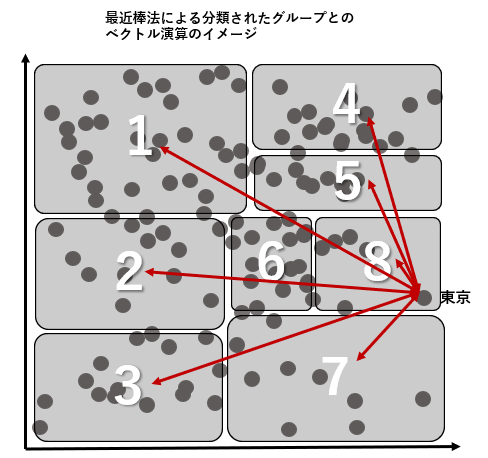
この分類処理には古典機械学習でお馴染みの最近傍法が使われてるケースが多いです。k近傍法(KNN)や近似最近傍法(ANN)などです。そのため、大抵のベクトルデータベースではこれらのアルゴリズムが実装されていたり、プラグインなどで追加できるようになっています。
ベクトルデータベースとしてのElasticsearch
世の中には沢山のベクトルストアがあり、特に最新のものは大変興味をそそられます。
ですが、筆者が普段対面する顧客はどちらかというと、Elasticsearchのような古参で実績のある技術を好む傾向があり、それらの顧客が運用しているElasticsearchの中には既に大量のドキュメントがベクトル化されため込まれている場合があります。そのため、今回はベクトルストアとしてElasticsearchを使ってみたいと思います。
Oracle CloudではMarketplaceにElasticsearchがあり、ボタンクリック数回でElasticsearchの分散処理環境が構築できますので是非お試しください。本記事でもこの環境を使っています。
CurrikiStudio - ElasticSearch
以上、LLM、LangChain、ベクトルストアという3つの登場人物の紹介が終わったところで実際のサンプルコードを紹介します。
因みに、現在市場に出回っているベクトルデータベースにはOSSから有償のものまでそれこそ数十を超える製品が存在します。それらの生い立ちは様々で、PineconeやChromaのように、もともとベクトルデータベースとして利用するために開発されたものについては特に海外のブログだと「ベクトルネイティブ」なベクトルデータベースと呼ばれることが多いようです。こちらの特徴としてはとにかく検索処理が早いというところが売りになっているようです。
それに対して、もともとRDBとして使われていたデータベースにベクトルデータを保持、検索できるようにした製品だと、OracleのOracle Database、MicrosoftのSQL Server、IBM DB2、PostgreSQLのベクトル拡張ツール pgvectorなどが有名です。これらはもともとはRDBであり、ビジネスアプリケーションから使われているケースが多いという性質上、たくさんのビジネスデータを保持している状態で運用されているケースが多いでしょう。そこにベクトルデータ(文章データ)を追加し、ビジネスデータと文章データを単一のデータベースに纏めて保持、クエリできることが大きな特徴になると思います。
その他、もとは全文検索エンジンでしたという製品にElasticsearchやOpenSearchがあります。これらの製品はテキストデータを扱うアプリケーションで利用されてきたということもあり、テキストデータをベクトルで扱えるようになった利点は非常に大きいのではないでしょうか。
このように、ベクトルデータベースには様々な種類がありますが、その製品の特性を見極めて製品選定をすることが重要かと思います。
コード概要
まずベクトルデータベースに入れるデータを用意します。本記事で利用するバージョンのGPTはLangChainについての知識を持っていませんのでそれを補完するためにLangChainについてのドキュメントを作ってみようと思います。実際の現場ではPDFやワードといったドキュメントからデータを読み込むような処理が多いと思いますのでそれに合わせてPDFで以下のような簡単なドキュメントをつくりsample.pdfというファイル名で保存しました。

以降、このドキュメントから、テキストデータの抽出、テキストデータのEmbedding処理、ベクトルストアへのデータロードを行い、実際にプロンプトを入力した際に、LLMと連携した推論ができるかを確認したいと思います。
まずはOpenAIのAPIキーを入力します。
!pip install langchain
!pip install openai
次に、LangChainのPDFローダーを使ってPDFファイルからテキストデータを抽出します。
import os
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
documentsを確認すると、余計な改行コードが入ってしまっていますが、PDFからテキストデータが抽出されていることが分かります。
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("/home/datascience/Langchain/sample.pdf")
documents = loader.load_and_split()
テキストデータをロードできました。ロードされたテキストデータをセパレータで区切り文章単位で扱えるようにします。OpenAIやその他様々なテキストスプリッターがありますが、今回はLangChainに実装されているCharacterTextSplitterを使います。恐らくこれが一番簡単なテキストスプリッターです。
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(separator="\n", chunk_size=4000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
print(docs)
出力がこちら。
[Document(page_content='LangChain とは、 ChatGPT などの大規模言語モデルの機能を拡張できるライブラ\nリです。言語モデルを使用したアプリケーションを開発する際に LangChain を使\nうことで、より高度な機能を実装することが可能です。\n一般的な言語モデルでは、長文のプロンプトの送信や、回答する内容に最新の情\n報を含めることが難しい場合があります。 LangChain を利用すれば、これらの機\n能を追加してアプリを開発できます 。\nLangChain は、機械学習スタートアップの Robust Intelligence に勤務していた\nHarrison Chase によって、 2022 年10 月にオープンソースプロジェクトとし\nて立ち上げられました。このプロジェクトは、 GitHub上の何百人もの寄稿者によ\nる改良、 Twitter上のトレンドの議論、プロジェクトの Discordサーバー上の活発\nな活動、多くの YouTube チュートリアル、そしてサンフランシスコとロンドンで\nのミートアップにより、すぐに人気を集めました。 2023年4月、LangChain は法\n人化し、ベンチマークから 1000万ドルのシード投資を発表した 1週間後、ベン\nチャー企業セコイア・キャピタルから少なくとも 2億ドルの評価額で 2000万ドル\n以上の資金を調達した。', metadata={'source': '/home/datascience/Langchain/sample2.pdf', 'page': 0})]
テキストデータが抽出できましたので、このテキストをベクトルに変換し、ベクトルストア(今回の場合Elasticsearch)にロードします。具体的にはテキストデータをGPTのEmbeddingモデルに連携してベクトル化し、そのベクトルをElasticsearchにロードします。
従って、この処理のコードでは、OpenAIのEmbeddingsのモデルを定義し、urlで指定したElasticsearchに接続後、indexをdemoとしてベクトルデータをロードします。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import ElasticVectorSearch
# Embeddingに OpenAIのEmbeddingモデルを定義
embeddings = OpenAIEmbeddings()
# ElasticSearchのアクセスポイントとユーザー、パスワードを定義
url = f"http://<user>:<password>@xxx.xxx.xxx.xxx:9200"
# テキストデータをベクトル化し、indexをlangchainとしてelasticsearchにロード
db = ElasticVectorSearch.from_documents(
docs, embeddings, elasticsearch_url= url, index_name="langchain"
)
ちゃんとElasticseachにロードされている確認してみましょう。Elasticsearchに接続し、indexを確認します。
from elasticsearch import Elasticsearch
indices = Elasticsearch(url).cat.indices(index='*', h='index').splitlines()
for index in indices:
print(index)
以下のように、デフォルトで作成されている.security-7というindex以外に、先ほどロードしたlangchainというindexが確認できます。
.security-7
langchain
実際にロードされたベクトルデータを以下のコードで確認してみます。
print(Elasticsearch(url).search(index="langchain"))
下記のvectorの項目が先ほどの文章のベクトルに相当します。GPTのデフォルトのembeddingモデルは1536次元となり、カンマで区切られたこの数値が1536個並んでいるという状況になっています。
{'took': 6, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 2, 'relation': 'eq'}, 'max_score': 1.0, 'hits': [{'_index': 'demo', '_type': '_doc', '_id': '5337f817-2daf-46fc-8cee-227420b67b1b', '_score': 1.0, '_source':
{'vector': [-0.0147464187139141, 0.01817330850056069, -0.017566183057582382, -0.028089701290861913, 0.014908318894129819, -0.0034353219809854503, -0.015178152838263532, 0.014665469089467514, 0.0065738268096883256, -0.01936057710969099, -0.016257488614798383, 0.012149268398610932, 0.022773974826601876, 0.013768271132090663, -0.002312138607624016,
・・・
中略
・・・
0.0037499468370202024, 0.006994055595685205, -0.012180582640426756, 0.02028748210162566, -0.013347382679390384, -0.030970783955615217, 0.008181089548938522, 0.015161655868430601, -0.003999493557149521, -0.01678033734663821, -0.020746110041611355],
'text': 'LangChain は、大規模言語モデル (LLM)を使用してアプリケーションの作成を簡素化するように設計さ\nれたフレームワークです。言語モデル統合フレームワークとしての LangChain のユースケースは、ド\nキュメント分析と要約、チャットボット、コード分析など、一般的な言語モデルのユースケースと大き\nく重複します。', 'metadata': {'source': '/home/datascience/Langchain/sample.pdf', 'page': 0}}}]}}
Elasticsearchにベクトルデータがロードされていることが確認できましたので、次は、入力されたLLMのモデルを定義し、ベクトルストアとの連携を定義します。
from langchain.chains import VectorDBQAWithSourcesChain
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo")
qa =VectorDBQAWithSourcesChain.from_chain_type(llm, chain_type="map_reduce", vectorstore=db)
そして、LangChainのAgentとToolsを定義します。この定義がまさにLLMとベクトルストアの連携の要になります。Agentとは入力テキストの内容に応じてどのToolを使えばよいかを考えてくれるロボットのようなものです。そしてそのToolは今回の場合、上述のコードで定義した、LLM(GPT)とベクトルストア(elasticsearch)となります。
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.agents import Tool
tools = [
Tool(
name = "elasticsearch_searcher",
func=qa,
description="Langchainの説明"
)
]
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
次に、LangChainのPromptTemplateを定義します。PromptTempleteはプログラムからLLMに入力するpromptを生成するための機能です。その際、プロンプトのテンプレートを定義することで、毎回同じフォーマットで回答を得ることができるようになります。下記のコードでは非常にシンプルなフォーマットにしていますが、その他、few-shot learningやチャットボットのようなフォーマットで出力するような定義も可能です。
from langchain.chains.qa_with_sources.map_reduce_prompt import QUESTION_PROMPT
from langchain import PromptTemplate
template = """
下記の質問に日本語で答えてください。
質問:{question}
回答:
"""
prompt = PromptTemplate(
input_variables=["question"],
template=template,
)
ここまでで全てのパーツが揃いましたので、最後に実際に質問をしてみたいと思います。下記コードにより、質問文章がPromptとして定義したフォーマットでAgentに渡され、Agentがどのtoolsで定義されたLLMとベクトルストアを使分けて最終的な回答を生成するという処理が実行されます。
query = "LangChainとは何ですか?"
question = prompt.format(question=query)
agent.run(question)
実行結果は以下のようになりました。

ChatGPTのようなつれない回答ではなく、ちゃんとElasticsearchの検索と連携し、LangChainに関する文章が生成されていることがわかります。
その他、様々な質問をしてみます。
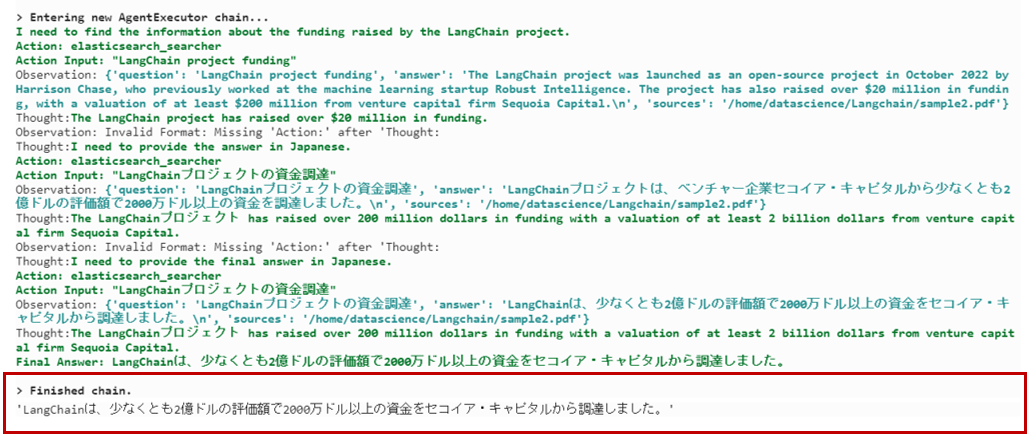
query = "LangChainプロジェクトはいくらの資金調達に成功しましたか?"
question = prompt.format(question=query)
agent.run(question)
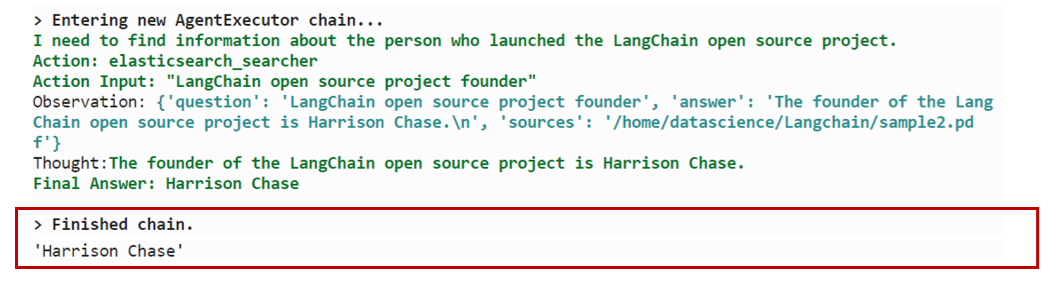
query = "LangChainのオープンソースプロジェクトを立ち上げた人は誰ですか?"
question = prompt.format(question=query)
agent.run(question)
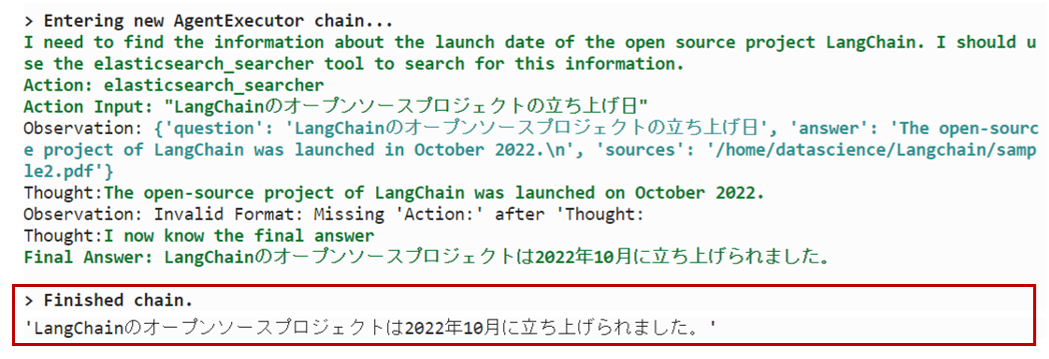
query = "LangChainのオープンソースプロジェクトが立ち上げられた日はいつですか?"
question = prompt.format(question=query)
agent.run(question)
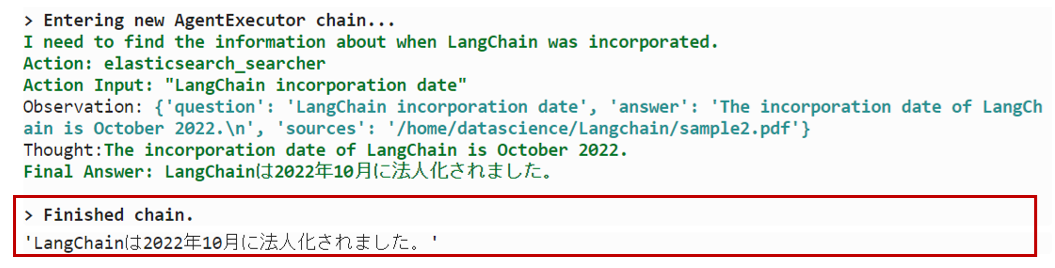
query = "LangChainが法人化された日はいつですか?"
question = prompt.format(question=query)
agent.run(question)
query = "LangChain が人気になった理由は何ですか?"
question = prompt.format(question=query)
agent.run(question)

さいごに
LLMの知らない知識を追加するという意味では、ファインチューニングもその手法の一つです。LLMを使った賢いアプリケーションを作りたいということであれば、どちらかと言わずベクトルストアもファインチューニングもやってしまえばいいとは思いますが、あえて両者を比較すると以下のようなpros/consがあると感じます。
まずベクトルストアの構成ではモデルの再学習(ファインチューニング)が不要です。(というかファインチューニングをしなくても知識が追加できるとい手法)
いつ実行されるか、どれくらいの時間がかかるかが不明瞭なファインチューニングという処理処理をする必要がなくなるということは一つのメリットだと思います。
そしてファインチューニングをしないということは学習データを作る必要がないということです。前回の記事:「【ChatGPT】ファインチューニングをわかりやすく解説」でご紹介した通り、ファインチューニングでは学習データを特定の形式で作りこむ必要があります。特にドメインナレッジがない場合のこの作業は大変な工数になり、この作業がなくなるというメリットは非常に大きいです。
ベクトルストアの場合、ドキュメントデータをロードする際はある程度定型のコードを実行して、ドキュメントを丸ごとデータベースにロードするような手法になり、学習データを作りこむような作業に比べると比較的工数は少ないのではないでしょうか。
しかしながら、ベクトルストアの場合はそもそもベクトルストアを構築、運用してゆくという作業コストが必要になります。
また、サービス利用のコスト面でいうと、ファインチューニングはそれ専用の課金が、そしてベクトルストアの場合、そのクラウドサービスの課金が必要となり、こちらはシステム要件によって差が出る点だと思います。
自然言語処理関連のその他の記事