本記事は日本オラクルが運営する下記Meetupで発表予定の内容になります。発表までに今後、内容は予告なく変更される可能性があることをあらかじめご了承ください。
セミナー実施時の動画はこちら。
はじめに
2022年末、ChatGPTの登場とともに始まった空前のAIブームは、 NL2SQL、RAG、AIエージェント、AIコーディングといった多様なトレンドソリューションを生み出してきました。それに伴い、これらを支える開発ツールも急速に進化し、OSSフレームワークやクラウドサービスなど、現在では数多くの選択肢が存在しています。 今後も新たなツールは増え続け、淘汰のプロセスを経ながらも、開発者にとっての選択肢はさらに広がっていくでしょう。
しかし、「運用」はどうでしょうか。残念ながら、現時点ではAIエージェントを前提とした標準的な運用ソリューションは確立されていません。 一般的に、新しい技術やソリューションが登場する際、それらはまず「開発」に焦点が当てられ、「運用」とセットで語られることは多くありません。そして多くの場合、市場で生き残った技術に対して、後追いで運用ツールやベストプラクティスが整備されていくものです。
そのため現在の開発者の関心も、依然としてAIエージェントの「開発」に偏りがちであり、「運用」は後回しになっているのが実情です。
本記事では、このギャップに着目し、AIエージェントの「運用」を見据えた設計と、その運用を前提とした「開発」をどのように進めるべきかについて解説します。本記事が、これからのAIエージェント活用における一助となれば幸いです。
AgentOpsとは
これまでも、「〇〇Ops」と呼ばれるキーワードは数多く登場してきました。代表的なものとしては、DevOpsに始まり、MLOps、そして近年ではLLMOpsなどが挙げられます。 これらはいずれも、特定の技術領域において開発から運用までのプロセスを体系化し、効率的かつ再現性の高い形で実践するための考え方です。
一般に、どのようなシステムにおいても、多くのユーザーが共通して行う設計・実装・運用のパターンが存在します。これらをフレームワークとして標準化することで、必ずしも専門家でなくても、一定のベストプラクティスに基づいた運用が可能になります。属人性を排除し、品質と効率を両立するための重要なアプローチと言えるでしょう。
さらに近年では、これらの仕組みをクラウド上で実現し、マネージドサービスとして提供する流れが加速しています。インフラの管理や運用の多くを自動化・抽象化することで、開発者は本来注力すべきアプリケーションロジックや価値創出に集中できるようになります。
こうした流れを踏まえ、AIエージェントの領域においても同様に、「開発」と「運用」を一体として捉え、体系化していく考え方が求められています。それが本記事で扱う「AgentOps」という概念です。
AgentOpsをOCI Generative AI Serviceで実装してみる
本記事ではOCI Generative AI Service(以下OCI GenAI)に追加されたEnterprise AI Agentと呼ばれる機能を中心にAgentOpsの仕組みを実装する手順と、具体的に何がうれしいのか? についてご紹介します。同サービスはもともとLLMのみを提供する単機能なクラウドサービスでしたが、エンハンスにより「エージェントを開発する機能」と「エージェントをホスティングする機能」が新たに追加されました。
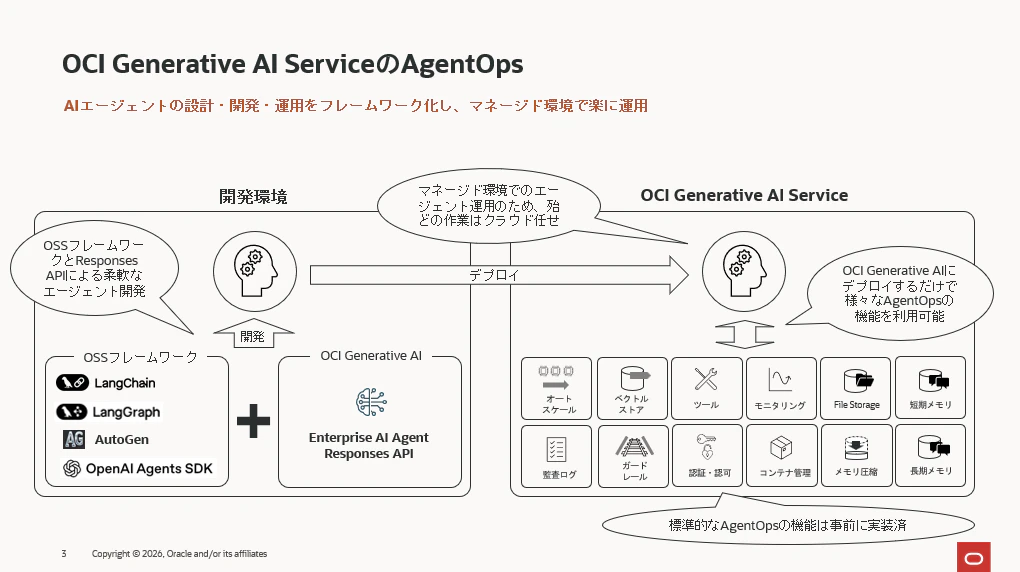
このエンハンスによりAgentOpsがマネージドのクラウドサービスで簡単に実現できるようになっています。エージェントの開発は著名なOSSフレームワークとOCI GenAIが提供するResponses APIで行います。開発したエージェントをOCI GenAIにデプロイすると、このエージェントはマネージドの環境で運用できるようになります。
この運用でのユーザーのメリットは主に下記3つです。
①エージェントの運用管理はクラウド任せ
開発したエージェントをIaaSレイヤーにデプロイした場合、その運用管理は全てユーザが行う必要があります。ですが、OCI GenAIのマネージド環境にデプロイすることでユーザーはエージェントの煩わしい運用・管理から解放され殆どの作業をクラウド任せにすることができます。
②AgentOpsのための豊富な機能が既に実装済です
同サービスには下記のようなエージェント開発・運用に必要とされる機能が既にクラウド上に実装済みです。従って、開発したエージェントをOCI GenAIにデプロイするだけでこれらの機能と連動させることができます。
AIエージェントの開発時に利用する機能
- 短期メモリ保持:最近の会話履歴を保持する機能とリソース
- 短期メモリの圧縮機能:なるべく沢山の会話を保持するためにる会話履歴情報を圧縮する機能
- 長期メモリ:将来の使用のために会話から重要な情報を抽出し、保持する機能
- ツール:MCP、Function Calling、NL2SQL、ベクトル検索、コードインタープリタなどのよく使われるツールを簡単に組み込めます
- コンテナ操作:コンテナを利用する処理を実行する場合のコンテナ管理機能
- ベクトルストア:セマンティック検索やNL2SQLツールを利用する際に必要となるベクトルストア機能
- File Storage : 同サービス内で利用するファイルを保存できるストレージ
- ガードレール:不適切なテキストの入出力の警告、ブロックを管理する機能
※一部の機能はこちらの記事でご紹介しています。
AIエージェントの運用時に利用する機能
- オートスケール:エージェントへの問い合わせ負荷に応じてインフラリソースをオートスケールする機能
- リソースモニタリング:エージェントの負荷状況、オートスケールの状況のモニター機能
- 監査ログ:エージェントの処理の監査ログ機能
- 認証・認可:クライアントからエージェントへのアクセスの認証認可機能
③多数の著名なOSSフレームワークをサポート
同サービスでは、著名なOSSフレームワークで開発したエージェントをクラウド環境にデプロイすることができます。具体的には下記をサポートしており、今後もこのリストは増えるでしょう。
- LangChain
- LangGraph
- AutoGen
- OpenAI Agents SDK
昨今はローコード開発ツールが好まれますが、細かいチューニングができなかったり、特定の処理を入れる場合にやりにくかったりと問題が発生する場合もあります。 そのため、エージェント開発はやはりローコードとフルコードの両方が利用できることが望ましいです。上記にリストしたものは全てフルコード開発のツールとなりますが、ローコードツールも今後リリースされる予定です。
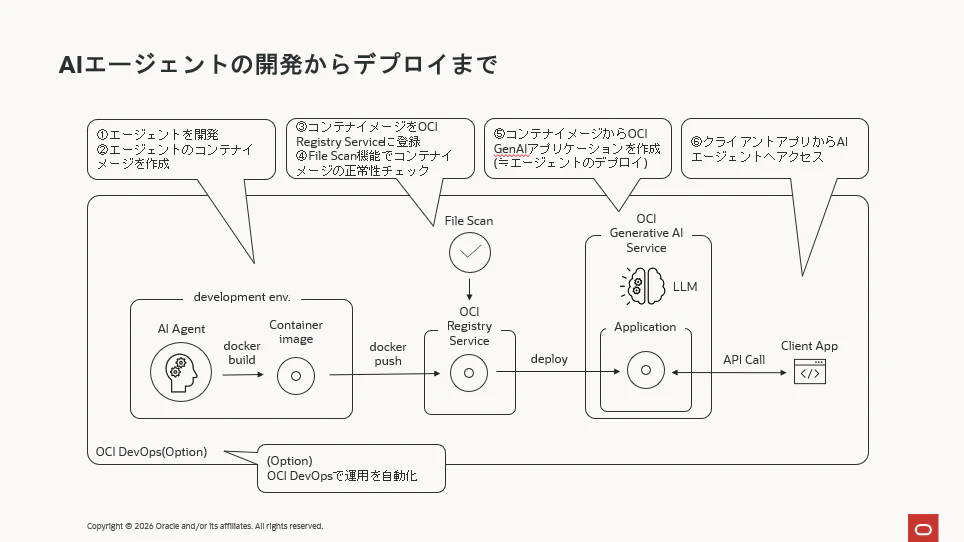
エージェントの開発からデプロイまで
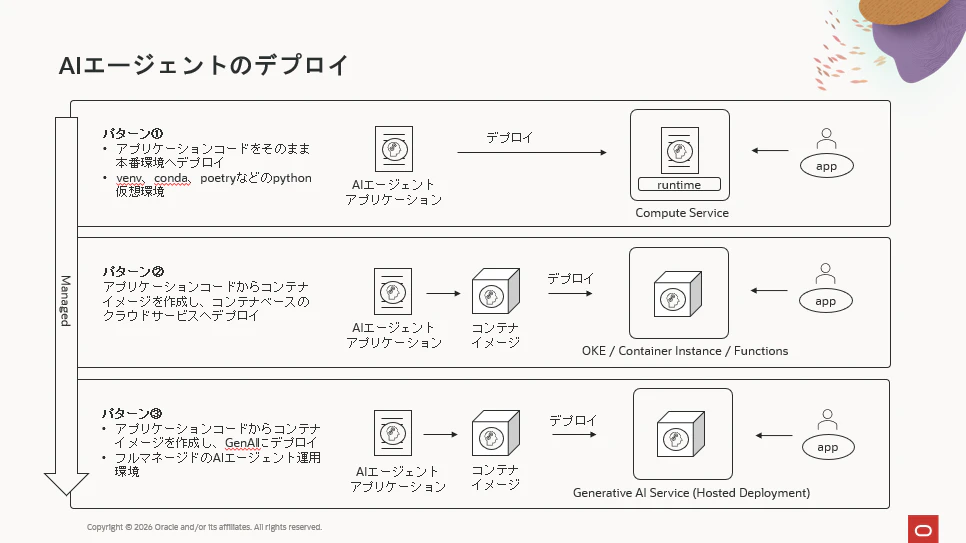
Oracle Cloudでは開発したAIエージェントのデプロイ先は主に下図のように3パターンあります。
-
パターン①
開発環境にあるAIエージェントのアプリケーションコードをComputeインスタンスに転送し、runtimeで動作させるというパターンです。Pythonなどの場合、venv、conda、poetryなどの仮想環境を利用することもできます。非常にプリミティブなデプロイ手法ですが簡単なアプリケーションであれば今でもこのやり方で運用しているユーザーはいます。 -
パターン②
開発環境で動作しているAIエージェントからコンテナイメージを作成し、コンテナ系のPaaSにデプロイするパターンです。Oracle Cloudのコンテナ系PaaSとしてはOKE、Container Instance、Functionsの3つがあります。- OKE:kubernetesのPaaSになり、kubernetesの全ての機能を利用したいユーザー向けです。本格的なマイクロサービスのアプリケーションを運用したい場合に利用します。
- Container Instanceはkubernetesのインフラレイヤーを抽象化し、自分で管理しなくてもよいPaaSです。バッチや軽量アプリ向けのサービスと言えます。
- Functions:更に抽象化のレベルが上がり、「コンテナ実行基盤 + スケーリング + イベント処理 + 実行ライフサイクル」などの管理が不要で完全なサーバレスのアプリケーション実行環境です。AIエージェントのようなステートフルなアプリケーションには不向きで、主にはバッチ向きということになります。
-
パターン③
パターン②と同じく開発環境で作ったコンテナイメージをOCI Generative AI Serviceの中にデプロイするというパターンです。同サービスにデプロイすることで、事前構築されているフルマネージドの様々な機能(モニタリング、監査、オートスケールなど)を利用することができます。
本記事では、サンプルのAIエージェントの開発から、上述したパターン③のデプロイ手法をまでをご紹介したいと思います。
具体的な手順は下図のようになります。
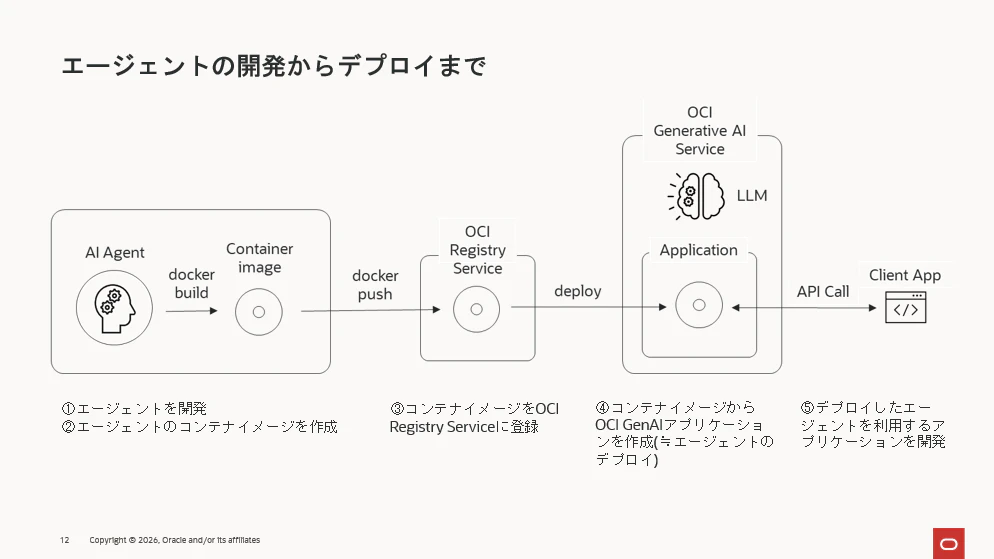
下記が簡単な概要の説明です。
- OSSフレームワークとOCI GenAIのResponses APIでエージェントを開発します。
- 最終的にエージェントのデプロイはコンテナ形式で行うことになります。従って、開発したエージェントの環境をからコンテナイメージを作成します。
- 作成したコンテナイメージをOCI Regisry Service(以下OCIR)に登録します。
- 次に、OCI GenAIアプリケーションを作成します。この処理によって、OCIRに登録されたエージェントのコンテナがOCI GenAIにデプロイされ、APIコールできるエンドポイントが付与されます。つまり、この時点でエージェントがマネージド環境で動作している状態になります。
- このエージェントにAPIコールするクライアントのアプリケーションを開発します。
以降の章は上記フローの具体的な内容となります。
エージェントの開発
まずはエージェントの開発です。先ほどの図の一番左の①です。今回はエージェントの処理内容はあまり重要ではなく、作成したエージェントを同サービスにデプロイする様子をご覧いただきたいので極力簡単なエージェントにします。
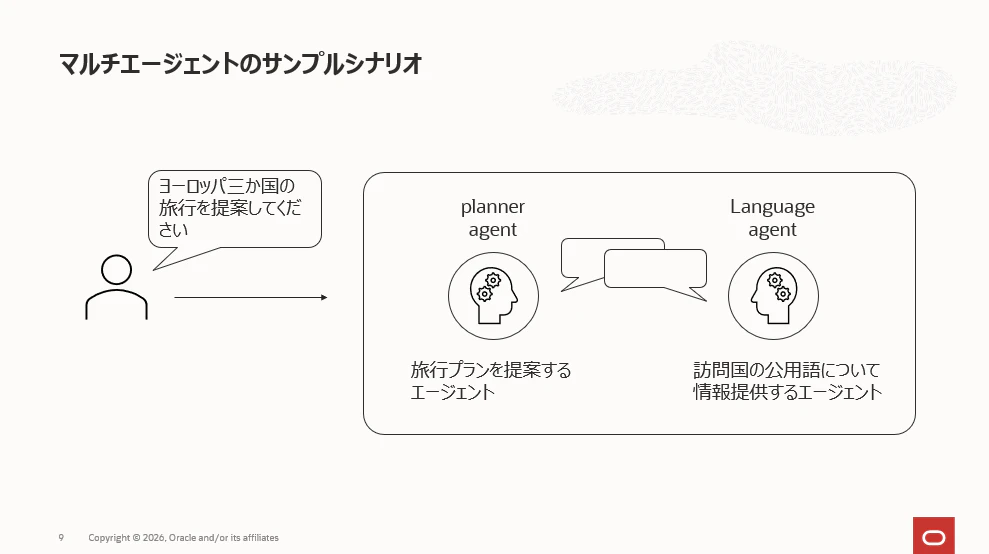
下記2つのエージェントが協力してユーザーのリクエストに応答するシンプルなマルチエージェントのコードです。
- Planner_agent:旅行プランを提案するエージェント
- Language_agent:提案された旅行プランの訪問国の公用語について情報提供するエージェント
OpenAI互換APIキーの作成
まず、OpenAI互換APIキーを取得します。GenAIのコンソールメニューを下記のように辿ってOpenAI互換APIキーを生成し、メモしておきます。
OCIコンソールの左上メニューから「アナリティクスとAI」-> 「生成AI」「API keys」->「APIキーの作成」ボタンをクリックしウィザードに従ってキーを生成すると下記のように"sk-"から始まるキーが生成されますのでこれをメモしておきます。
sk-wxxxxxxxxxBaiCS4f3mt
IAMポリシーを設定する
取得したOpenAI互換APIキーが利用できるようにIAMポリシーをセットします。
allow group Administrators to manage generative-ai-response in compartment agents where ALL { request.principal.type='generativeaiapikey', request.principal.id='sk-wxxxxxxxxxBaiCS4f3mt' }
OCI GenAIのプロジェクトを作成する
OCI GenAIで予め実装されている便利機能を使う場合は予めOCI GenAIの「プロジェクト」を作成します。そして、この「プロジェクト」のOCIDをエージェントのコードに埋め込むことでOCI GenAIの便利機能を使うことができるようになります。
この「プロジェクト」には冒頭にご紹介した便利機能の一部(メモリ関連のリソース)が配備されており、エージェントのコードにその機能を利用するコードを埋め込む
OCIコンソールの左上メニューから「アナリティクスとAI」->「生成AI」-> 「Project」-> 「プロジェクトの作成」ボタンをクリックするとプロジェクトの作成ウィザードが起動します。
まずは、プロジェクトの名前と説明を入力します。
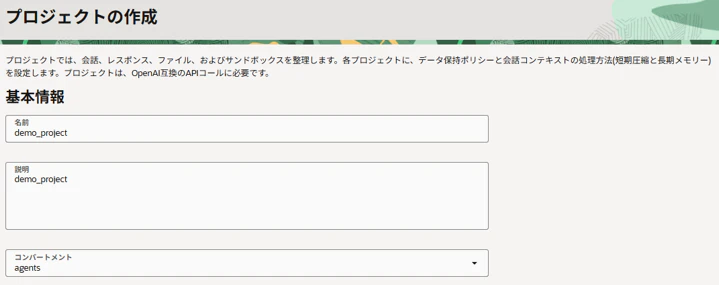
次に、会話の保存に関する要件を入力します。
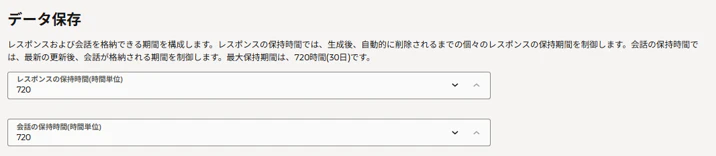
次に短期メモリの圧縮機能に関する要件を入力します。
短期メモリは圧迫される前に自動圧縮(要約)されるためその処理に使うLLMを選択します。
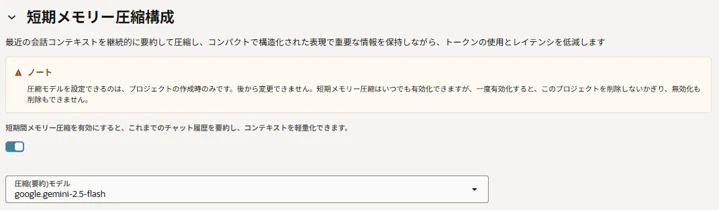
次に長期メモリの圧縮機能に関する要件を入力します。
こちらも会話内容の要約に使うLLMと、ベクトル検索のための埋め込みモデルを選択します。
「作成」ボタンをクリック。
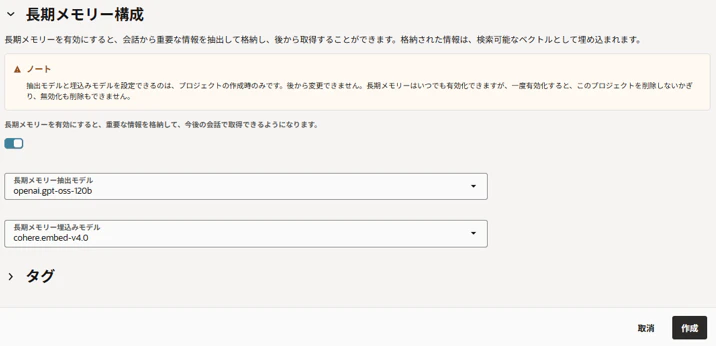
下図のようにプロジェクトの右にある「・・・」ボタンから「OCIDのコピー」をクリックしてこのプロジェクトのOCIDをメモしておきます。
下記のようなOCIになります。
ocid1.generativeaiproject.oc1.us-chicago-1.xxxxxxxx
これをすることにより、OCI GenAIに予め備わっているPaaSとしての一部の便利機能(主にメモリ関連)が簡単なコードで利用できるようになります。
コードの作成
マルチエージェントのフレームワークとして今回はLangGraphを使ってみます。(OCI GenAIがサポートしているライブラリであれば何でも大丈夫です。)
pip install openai langgraph
エージェントのコードを下記内容で作成しmain.pyというファイル名で保存しました。エージェントの処理は上述した内容の通りの非常にシンプルなマルチエージェントになります。このコードに上記で取得したOpenAI互換APIキーと、GenAIプロジェクトのOCIDを埋め込みます。
from contextlib import asynccontextmanager
from typing import Any, Dict, TypedDict
from fastapi import FastAPI
from openai import OpenAI
from langgraph.graph import StateGraph, END
OCI_OPENAI_API_KEY = "sk-wUrTaxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
project = "ocid1.generativeaiproject.oc1.us-chicago-1.amxxxxxxxxxxxxxxxx62syan3oha"
client = None
graph = None
# =========================
# LangGraph State定義
# =========================
class AgentState(TypedDict):
user_input: str
plan: str
final_answer: str
# =========================
# planner_agent
# =========================
def planner_agent(state: AgentState) -> AgentState:
prompt = f"""
あなたは旅行プランナーです。
ユーザーの要望に基づいて、訪問国を含む簡単な旅行プランを提案してください。
ユーザー入力:
{state['user_input']}
"""
res = client.responses.create(
model="xai.grok-4-1-fast-reasoning",
input=[{"role": "user", "content": prompt}]
)
return {
**state,
"plan": res.output_text
}
# =========================
# language_agent
# =========================
def language_agent(state: AgentState) -> AgentState:
prompt = f"""
あなたは言語ガイドです。
以下の旅行プランに含まれる国の公用語を説明してください。
旅行プラン:
{state['plan']}
"""
res = client.responses.create(
model="google.gemini-2.5-flash",
input=[{"role": "user", "content": prompt}]
)
final = f"""
【旅行プラン】
{state['plan']}
【公用語情報】
{res.output_text}
"""
return {
**state,
"final_answer": final
}
# =========================
# LangGraph構築
# =========================
def build_graph():
workflow = StateGraph(AgentState)
workflow.add_node("planner", planner_agent)
workflow.add_node("language", language_agent)
workflow.set_entry_point("planner")
workflow.add_edge("planner", "language")
workflow.add_edge("language", END)
return workflow.compile()
# =========================
# FastAPI
# =========================
@asynccontextmanager
async def lifespan(app: FastAPI):
global client, graph
try:
client = OpenAI(
base_url="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com/openai/v1",
api_key=OCI_OPENAI_API_KEY,
project=project
)
graph = build_graph()
yield
except Exception as e:
print(f"Startup error: {e}")
raise
app = FastAPI(lifespan=lifespan)
# =========================
# chatエンドポイント
# =========================
import re
def format_output(text: str) -> str:
text = text.strip()
# セクションを強調
text = re.sub(
r"【旅行プラン】",
"\n" + "="*40 + "\n🌍 【旅行プラン】\n" + "="*40,
text
)
text = re.sub(
r"【公用語情報】",
"\n" + "="*40 + "\n🗣️ 【公用語情報】\n" + "="*40,
text
)
# 余分な改行を整理
text = re.sub(r"\n{3,}", "\n\n", text)
return text
@app.post("/chat")
async def chat(body: Dict[str, Any]):
msg = body["message"]
result = graph.invoke({
"user_input": msg,
"plan": "",
"final_answer": ""
})
formatted = format_output(result["final_answer"])
return {"reply": formatted}
@app.get("/health")
async def health():
return {"status": "Healthy"}
@app.get("/ready")
async def ready():
return {"status": "Ready"}
作ったエージェントをデプロイする前に動作確認をしておきます。まずuvicorn(Python製Webアプリを動かすWebサーバー)でエージェントのコードをウェブサービスとして起動します。
$ uvicorn main:app --host 0.0.0.0 --port 8080
INFO: Started server process [17564]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
INFO: 127.0.0.1:51426 - "POST /chat HTTP/1.1" 200 OK
このサービスに対する、クライアントのコードを下記のように定義し、「ヨーロッパの3日間の旅行を計画してください。」というプロンプトを入力してみます。
import requests
url = "http://localhost:8080/chat"
payload = {
"message": "ヨーロッパの3日間の旅行を計画してください。"
}
headers = {
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json()["reply"])
出力は下記のようになりました。旅行プランするエージェントと、そのエージェントの出力から訪問地の公用語についての情報を提供するエージェントの2つが連動して応答テキストを生成していることがわかります。
========================================
🌍 【旅行プラン】
========================================
### ヨーロッパ3日間旅行プラン
**訪問国:フランス(パリ中心)**
**テーマ:パリのクラシック観光(コンパクトで効率的)**
**前提:日本からの直行便で到着。予算目安:1人あたり20-30万円(航空券・宿泊・食事・交通込)。**
**宿泊:パリ市内(エッフェル塔近くの3つ星ホテル、2泊)。**
#### Day 1: 到着 & パリの象徴巡り
- **朝/午前:** 日本からパリ・シャルル・ド・ゴール空港着(約12時間フライト)。空港からRER電車で市内へ(約1時間)。
- **午後:** エッフェル塔登頂(チケット事前予約推奨)。シャンゼリゼ通りを散策し、凱旋門へ。
- **夕食:** ビストロでエスカルゴやオニオンスープ。
- **宿泊:** パリ市内ホテル。
<中略>
#### Day 3: 自由時間 & 出発
- **午前:** 自由時間(オペラ座ガルニエやショッピング:ギャラリー・ラファイエット)。
- **午後:** 空港へ移動。夕方便で日本へ帰国。
- **Tips:** パリメトロパス購入で交通便利。ピックポケット注意。
このプランはフライト時間を考慮した現実的なものです。詳細調整(予算・好み)が必要なら教えてください!
========================================
🗣️ 【公用語情報】
========================================
この旅行プランに含まれる国はフランスのみですので、フランスの公用語である「フランス語」についてご説明します。
---
### フランスの公用語:フランス語
フランスの唯一の公用語は**フランス語 (français)** です。
#### 1. 言語の系統と国際的な地位
* **ロマンス語派**: フランス語は、ラテン語を起源とするロマンス語派に属し、イタリア語、スペイン語、ポルトガル語などと親戚関係にあります。
* **国際語**: 国際連合の公用語の一つであり、ユネスコ、NATO、EUなど数多くの国際機関で公用語として使用されています。また、世界中で約3億人が話す言語とされ、「フランコフォニー国際機関」を通じて多くの国・地域に広まっています。
#### 2. フランス(特にパリ)での使用状況
* **日常生活**: フランス国内、特にパリでは、日常生活のあらゆる場面でフランス語が使われています。行政機関、交通機関、商店、レストラン、カフェなど、ほとんどの場所でフランス語が基本となります。
* **英語の通用度**:
* **主要な観光地**: エッフェル塔、ルーブル美術館、主要なホテル、ギャラリー・ラファイエットのようなデパートなど、観光客が多く訪れる場所や施設では、英語が通じるスタッフがいることが多いです。
<中略>
#### 3. 旅行者へのアドバイス
パリ旅行をより快適に、そして深く楽しむために、以下の点を参考にしてください。
* **基本的な挨拶**: 「Bonjour(ボンジュール:こんにちは)」、「Merci(メルシー:ありがとう)」、「S'il vous plaît(シルヴプレ:お願いします/どうぞ)」、「Pardon(パルドン:すみません/ごめんなさい)」、「Au revoir(オゥルヴォワール:さようなら)」などの簡単なフレーズを覚えておくと、地元の人とのコミュニケーションが円滑になります。
<中略>
フランス語は美しい響きを持つ言語です。ぜひ、旅の準備としていくつか簡単なフレーズを覚えて、パリでの滞在を一層充実したものにしてくださいね。
これでエージェントの作成は完了です。
エージェントのデプロイ
ここから開発したAIエージェントをデプロイする手順です。下図の①から④までの手順を行います。
作ったエージェントをデプロイするには、まずエージェントのコンテナイメージを作成します。
コンテナイメージの作成(上図の①、②)
コンテナイメージは下記3つのファイルから作成します。エージェントのコードは作成済みのため、以降の手順で他の2つを作成します。
- エージェントのコード(main.py)
- requirements.txt
- Dockerfile
requirements.txtはエージェントを開発した環境で、下記コマンドを実行すると作成することができます。
pip freeze | grep -v "@" > requirements.txt
次に、下記内容でDockerfileを保存します。requirements.txtファイルを読み込み、必要なpythonライブラリをインストールし、uvicornを使ってポート8080でウェブサービスとして起動するという処理内容です。
FROM python:3.10-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8080
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8080"]
下記コマンドを実行すると、Dockerfileに記載した処理内容が順次実行されます。最後に「Successfully ...」が出力されれば成功です。
docker buildx build --platform linux/amd64 -t <イメージ名>:<タグ> --load .
実行すると下記のような出力になります。
$ docker buildx build --platform linux/amd64 -t myimage:latest --load .
Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg.
STEP 1/7: FROM python:3.10-slim
STEP 2/7: WORKDIR /app
--> Using cache 61edfddc1ec938c16d8712a6e6e63d0c080a3315cb18274a61f37f3529006222
--> 61edfddc1ec9
STEP 3/7: COPY requirements.txt .
--> 38135909a111
<中略>
STEP 6/7: EXPOSE 8080
--> b5a1249193c8
STEP 7/7: CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8080"]
COMMIT myimage:latest
--> aa5ee632704a
Successfully tagged localhost/myimage:latest
aa5ee632704afe0b00bff4ba03ce9ff70bc78d89845bfbfe6ea04497b2dbbd38
既にエージェントの動作確認は済んでいますが、コンテナでも同じように動作確認をしたい場合は下記のようにコンテナを起動します。
$ docker run -it --rm -p 8080:8080 myimage:latest
Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg.
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
INFO: 10.0.2.100:58824 - "GET /health HTTP/1.1" 200 OK
このサービスにアクセスするコードは上述したクライアントのコードと全く同じです。
コンテナイメージをOCI Registry Service(OCIR)に登録する(上図の③)
次はこのコンテナイメージをOCI Registry Service(OCIR)に登録する作業です。まずはOCIRのコンソールからこのコンテナイメージを登録するリポジトリを作成しておきます。
OCIコンソールの左上メニューから「開発者サービス」->「コンテナ・レジストリ」-> 「リポジトリの作成」ボタンをクリックしウィザードに従ってリポジトリを作成します。その際、リポジトリ名はコンテナイメージ名と同じ(今回の場合はmyimage)にします。
次にコンテナイメージを作成したdocker環境に戻り、下記コマンドOCIRにログインします
docker login <リージョンキー>.ocir.io
ログイン時のユーザー認証とパスワードは以下の通りです。
- ユーザー名:<テナント・ネームスペース>/<ユーザー名>
- パスワード:<認証トークン>
実際にログインすると以下のような出力となります。
$ docker login us-chicago-1.ocir.io
Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg.
Username: idqcucnenh88/kenichi.sonoda@oracle.com
Password:
Login Succeeded!
現状、下記のようにローカルに作成済のコンテナイメージがある状態です。
$ docker images
Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg.
REPOSITORY TAG IMAGE ID CREATED SIZE
localhost/myimage latest fa19558f1709 About an hour ago 632 MB
このコンテナイメージをOCIRに作成済のリポジトリにpushするために下記コマンドでtagを付けます。
$ docker tag myimage:latest us-chicago-1.ocir.io/idqcucnenh88/myimage:latest
Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg.
$ docker images
Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg.
REPOSITORY TAG IMAGE ID CREATED SIZE
us-chicago-1.ocir.io/idqcucnenh88/myimage latest fa19558f1709 2 hours ago 632 MB
localhost/myimage latest fa19558f1709 2 hours ago 632 MB
作成したコンテナイメージをOCIRにプッシュします。
$ docker push us-chicago-1.ocir.io/idqcucnenh88/myimage:latest
Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg.
Getting image source signatures
Copying blob af8e2cb9023a done |
Copying blob 60e70dddd9ea done |
Copying blob 39b3f7475ebd done |
Copying blob 2eb947da73b3 done |
Copying blob 842fe36b918c done |
Copying blob e35db0322204 done |
Copying blob cd1f8c6b75dc done |
Copying config fa19558f17 done |
Writing manifest to image destination
これでOCIRにエージェントのコンテナイメージの登録が完了しました。
Generative AI Serviceのアプリケーションを作成する(≒エージェントのデプロイ)((上図の④)
デプロイの際は、Generative AI Serviceの「アプリケーション」(以降「GenAIアプリ」と表記)を作成します。このプロセスの中でアプリケーションはOCIRからコンテナイメージをpullしてエージェントをホスティング環境にデプロイします。アプリケーション作成作業はコンソールウィザードで行いますが、UIの裏でこれら一連の内部処理が動作するために、下記のようにダイナミックグループとIAMポリシーを追加しておきます。
ダイナミックグループを任意の名前で作成
all {resource.type='generativeaihostedapplication',resource.compartment.id='<compartment_id>'}
all {resource.type='generativeaihosteddeployment',resource.compartment.id='<compartment_id>'}
IAMポリシーを作成
Allow service vulnerability-scanning-service to read repos in compartment <compartment_name>
Allow service vulnerability-scanning-service to read compartments in compartment <compartment_name>
Allow dynamic-group <dynamic_group_name> to read repos in compartment <compartment_name>
Allow dynamic-group <dynamic_group_name> to read container-scan-results in compartment <compartment_name>
Allow dynamic-group <dynamic_group_name> to read vss-family in compartment <compartment_name>
OCIのコンソールを下記のように辿って、GenAIアプリのウィザードを起動します。
OCIコンソールの左上メニューから「アナリティクスとAI」->「Applications」-> 「アプリケーションの作成」をクリック
下図のようなウィザードが表示されますので設定をしてゆきます。
まずはGenAIアプリの名前と説明を入力。
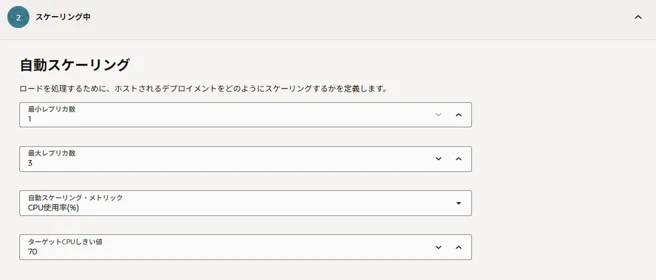
オートスケールのポリシーを設定。
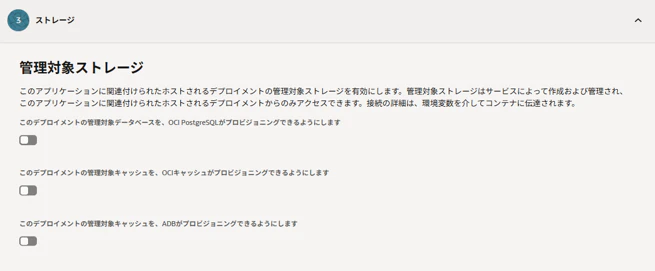
エージェントが使う短期的なメモリー、チェックポイント、キャッシュおよびコンテキスト・ストレージを設定します。OCI PostgreSQL、OCI Cache、ADBの3つから選択できます。
コンテナに渡す環境変数がある場合は設定します。
コンテナを配置するネットワークを設定します。
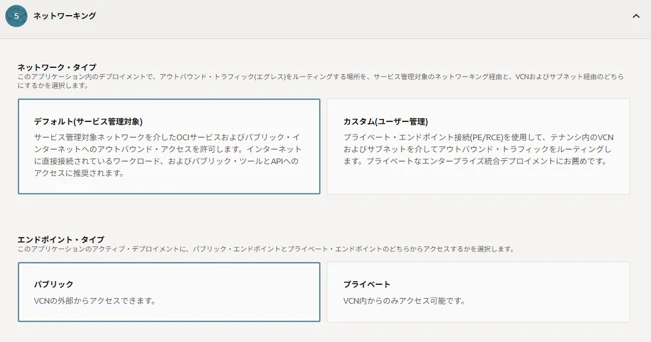
アイデンティティドメイン(事前に「機密アプリ」を作成)の情報を入力します。
最後に確認の画面です。
GenAIアプリが作成されると下図のようにエントリが増え、ステータスがアクティブになればAPIコールできる状態です。作成したGenAIアプリ(この図ではdemo_agent_trip)をクリック。
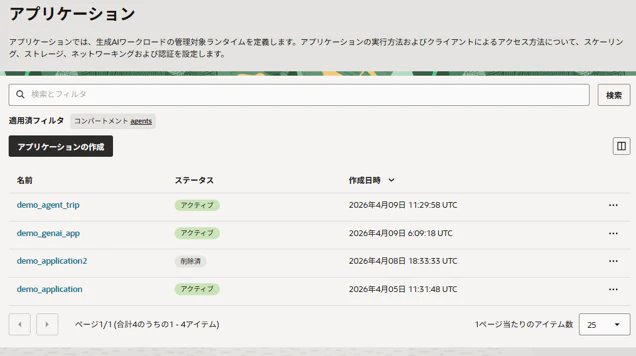
GenAIアプリの詳細画面です。使用方法の欄にあるURLがこのアプリのエンドポイントになります。後工程で実際にこのエージェントにAPIコールしますのでこのURLをメモしておきます。次に「デプロイメント」のタブに移動します。
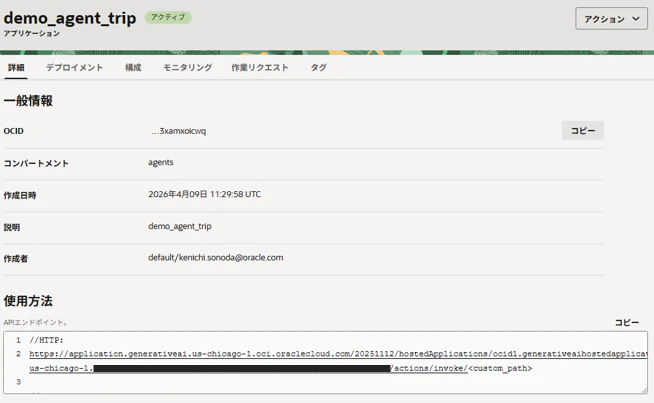
「デプロイメントの作成ボタン」をクリック。
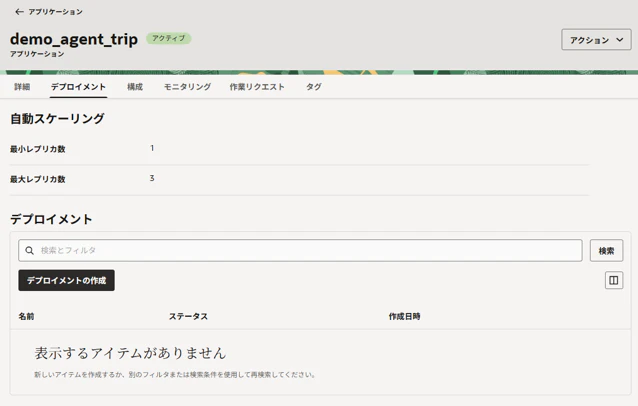
この画面でOCIRに登録済のコンテナイメージ(エージェントのコンテナ)を選択し、「デプロイメントの作成」をクリック。事実上、この処理がエージェントのデプロイということになります。
デプロイメントのステイタスがアクティブになれば完了です。続いてモニタリングの設定を行いますので「モニタリング」タブに移動します。
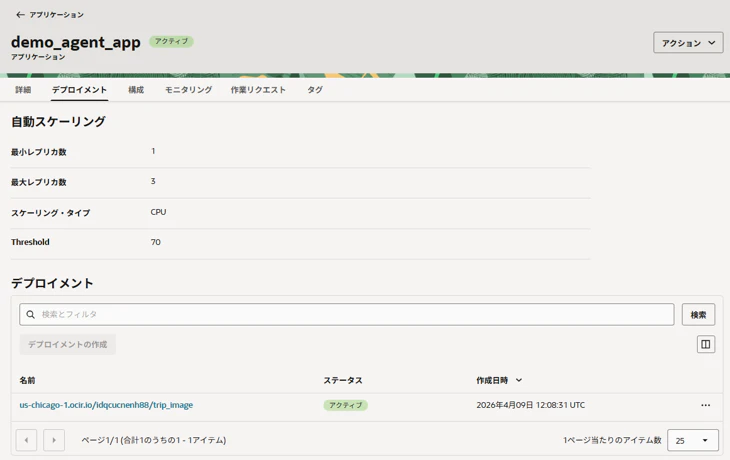
下図のLogsの項目の一番右「・・・」をクリックし「ログの有効化」をクリック。
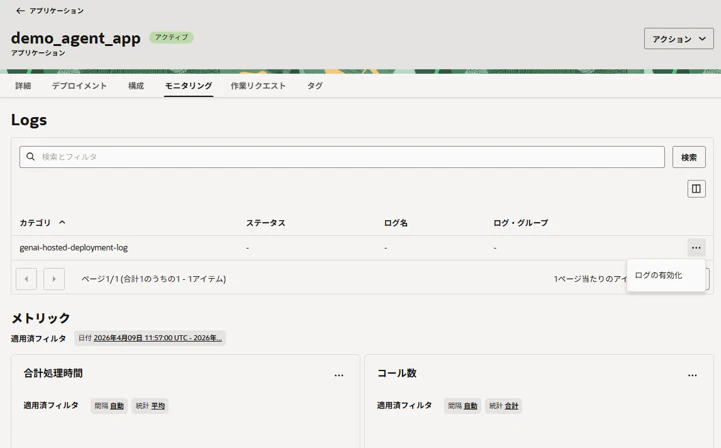
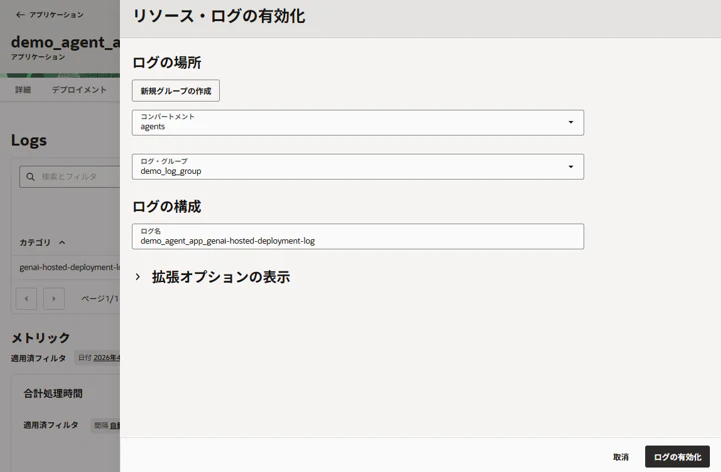
ログ・グループ(予め作成)を選択し「ログの有効化」をクリック。
ステータスがアクティブになればGenAIのモニタリング設定が完了です。
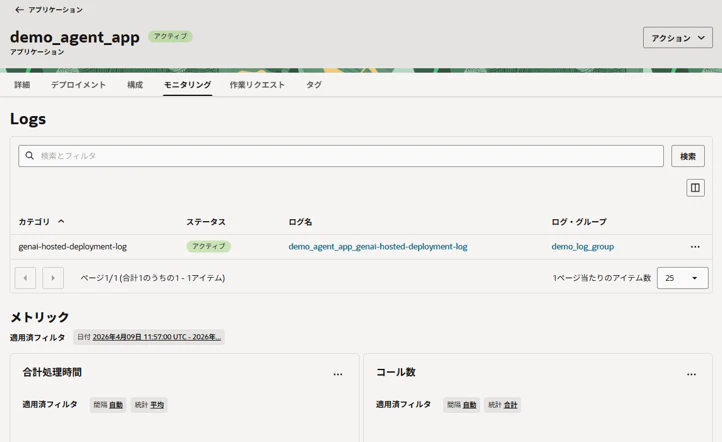
ここまでの作業でこのエージェントはOracle Cloud上でマネージドサービスとして動作しており、この後の運用は基本的にOracle Cloudに丸投げという状態になります。
デプロイしたエージェントを動作させてみる
ここからは、このエージェントを利用するクライアントのコードを作ります。下図の⑤です。
OAuth認証の設定を行う
OCI GenAIのアプリケーション(エージェント)にクライアントからAPIコールする際の認証はOAuthのみがサポートされています。OCIのアイデンティティドメインにはOAuth認証基盤がありますので下記手順で事前にこの設定を行い、OAuth認証トークンを生成すために必要な情報を取得します。
OCIコンソールの左上メニューから「アイデンティティとセキュリティ」->「ドメイン」-> OAuthの設定を行う任意のドメインを選択 -> ドメインの画面で「統合アプリケーション」のタブに移動 -> 「アプリケーションの追加」をクリック -> 「機密アプリケーション」を選択し「ワークフローの起動」ボタンをクリック -> 「名前」と「説明」のみを記載し他の項目はデフォルトで「送信」ボタンをクリック
- 作成した統合アプリケーションをクリック
- 「OAuth構成」ボタンをクリック
「このアプリケーションをリソース・サーバーとして今すぐ構成します」を選択
「プライマリ・オーディエンス」に任意のURL(例:https://ksonoda-myagent.com/)を入力
「スコープ」の「追加」ボタンをクリックし、任意の名前(例:invoke)を入力し「追加」ボタンをクリック - 「認可」の項目リストの「クライアント資格証明」にチェックを入れ「送信」ボタンをクリック
これでOAuthの事前設定は完了です。作成した統合アプリケーションの画面から下記情報をメモしておきます。
- クライアントID:456bfxxxxxxxxxxxxxxxxxxx486ac9da
- クライアント・シークレット:idcscs-xxxxxxxxxxxxxxxxxxxxxxxxxx
- プライマリ・オーディエンス:https://ksonoda-myagent/dev/
また、次のリンクを辿り、ドメインURLも記録しておきます。
OCIコンソールの左上メニューから「アイデンティティとセキュリティ」->「ドメイン」-> OAuthの設定を行う任意のドメインを選択
ドメインURLは下記のような値になります。
ドメインURL: https://idcs-xxxxxxxxxxxxxxxxxxxxxxxx.identity.oraclecloud.com:443
これらの値はこの後のクライアントコードの中で使います。
クライアントコードの作成
前の手順で取得した情報に加え、下記の手順でGenAIアプリケーションのOCIDと、アプリケーションのエンドポイントをメモしておきます。
アプリケーションのエンドポイント
OCIコンソールの左上メニューから「アナリティクスとAI」->「Applications」-> リストから対象のアプリケーションをクリック -> 「詳細」タブの「使用方法」の欄にあるURL
OCIコンソールの左上メニューから「アナリティクスとAI」->「Applications」-> リストから対象のアプリケーションの一番右にある「・・・」ボタンをクリックし ->「OCIDのコピー」をクリック
下記のようなOCIDになります。
- アプリケーションのOCID:ocid1.generativeaihostedapplication.oc1.us-chicago-1.xxxxxxxxxxxxxxxxxxxxxx
- アプリケーションのエンドポイント:https://inference.generativeai.us-chicago-1.oci.oraclecloud.com/20251112/hostedApplications/<アプリケーションのOCID>/actions/invoke/chat
ここからクライアントコードの作成です。ここまでの作業で取得した情報を環境変数として設定します。
import requests
import json # 追加
# =========================
# 1. 環境変数
# =========================
# ドメインURL
IDCS_DOMAIN_URL = "https://idcs-xxxxxxxxxxxx.identity.oraclecloud.com:443"
# クライアントID
IDCS_CLIENT_ID = "xxxxxxxxxxxxxxxxxxxxxxxx"
# クライアント・シークレット
IDCS_CLIENT_SECRET = "idcscs-xxxxxxxxxxxxxxxxxxxxx"
# プライマリ・オーディエンス
IDCS_SCOPE = "https://ksonoda-myagent.com/invoke"
# アプリケーションのOCID
APP_OCID = "ocid1.generativeaihostedapplication.oc1.us-chicago-1.xxxxxxxxxxxxxxxx"
# =========================
# 2. アクセストークン取得
# =========================
token_url = f"{IDCS_DOMAIN_URL}/oauth2/v1/token"
token_response = requests.post(
token_url,
headers={"Content-Type": "application/x-www-form-urlencoded"},
data={
"grant_type": "client_credentials",
"client_id": IDCS_CLIENT_ID,
"client_secret": IDCS_CLIENT_SECRET,
"scope": IDCS_SCOPE
}
)
ACCESS_TOKEN = token_response.json().get("access_token")
# =========================
# 3. Hosted Application呼び出し
# =========================
# GenAIアプリケーションのURL
invoke_url = f"https://inference.generativeai.us-chicago-1.oci.oraclecloud.com/20251112/hostedApplications/{APP_OCID}/actions/invoke/chat"
invoke_response = requests.post(
invoke_url,
headers={
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"Bearer {ACCESS_TOKEN}"
},
json={
"thread_id": "test-111",
"message": "ヨーロッパの3日間の旅行を計画してください。"
}
)
# =========================
# 4. レスポンスを見やすく整形
# =========================
reply_json = invoke_response.json()
print(reply_json.get("reply", "").replace("\\n", "\n"))
下記のように結果が出力されれば完了です。出力結果はもちろん、始めに動作確認をしたときと同じような内容になります。
========================================
🌍 【旅行プラン】
========================================
### ヨーロッパ3日間旅行プラン:フランス(パリ)
**訪問国:フランス**
**テーマ:パリの定番観光を満喫するコンパクトプラン**
**前提:成田/関空から直行便でパリ・シャルル・ド・ゴール空港へ。到着後、市内中心部(1区/2区)のホテル泊。交通はParis Visiteパス(地下鉄・バス無制限)推奨。予算目安:航空券除き1人10万円前後(宿泊・食事・交通込)。**
#### Day 1: 到着&パリのシンボル巡り(エッフェル塔エリア)
- **朝/午前:** パリ到着(飛行時間約12時間)。空港からRER電車で市内へ(約45分)。
- **午後:** エッフェル塔登頂(事前予約必須)。シャンゼリゼ通り散策&凱旋門。
- **夕方/夜:** セーヌ川沿いディナー(ビストロでエスカルゴやオニオンスープ)。ライトアップされたエッフェル塔鑑賞。
- **宿泊:** パリ中心部ホテル。
<中略>
このプランでパリのエッセンスを凝縮!詳細調整が必要なら教えてください♪
========================================
🗣️ 【公用語情報】
========================================
この素晴らしいパリ旅行プラン、お楽しみいただけること間違いなしです!
さて、この旅行プランの舞台となる**フランス**の公用語についてご案内いたします。
---
### フランスの公用語:フランス語 (Français)
フランスの公用語は**フランス語**です。
フランス語は、フランス共和国憲法第2条によって「共和国の言語はフランス語である」と定められており、唯一の公用語として位置づけられています。
#### フランス語の背景と特徴
* **ロマンス語族**: ラテン語から派生したロマンス語族に属し、イタリア語、スペイン語、ポルトガル語などと共通のルーツを持ちます。
* **国際語としての地位**: かつては外交の世界で最も重要な言語の一つであり、現在でも国連、EU、IOC(国際オリンピック委員会)など、多くの国際機関で公用語として採用されています。世界中で約3億人が話す言語とされています。
* **文化との結びつき**: 芸術、ファッション、料理、哲学など、フランスの豊かな文化と深く結びついています。フランス語を学ぶことで、これらの文化をより深く理解する手助けにもなります。
#### 現地でのコミュニケーションについて
パリのような主要な観光地では、特にホテル、主要な観光スポット、デパート、人気レストランなどでは、英語が通じるスタッフも増えています。しかし、以下のような点に留意すると、よりスムーズで心温まるコミュニケーションが期待できます。
<中略>
簡単なフランス語のフレーズを交えることで、現地の人々との交流がより豊かになり、旅の思い出も一層深まることでしょう。
どうぞ、素敵なパリの旅をお楽しみください!
OCI GenAIの中でマネージドとして動作しているエージェントへクライアントアプリからアクセスできるようになりました。
デプロイしたエージェントの運用・管理面の機能
再掲載になりますがAIエージェントを動作させるレプリカのオートスケールは下記プロジェクトを作成するウィザードで簡単に設定できます。
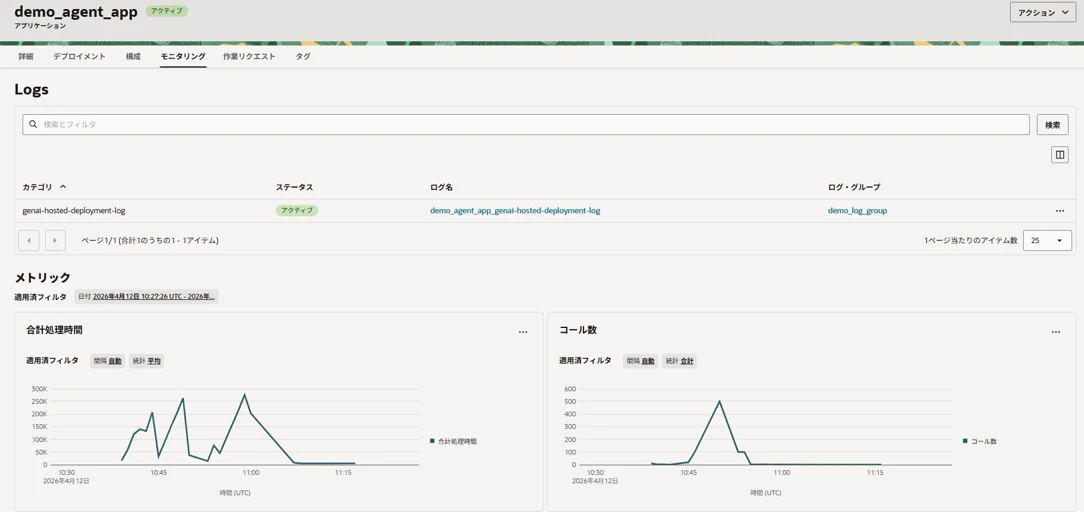
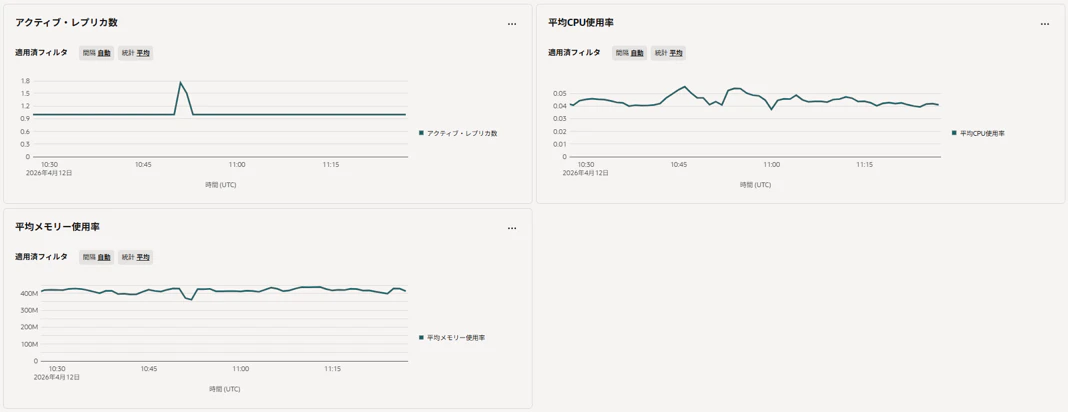
OCI Generative AI Serviceにデプロイしたエージェントの監視(Monitoring)画面が下図になります。リソースの使用率、アクセス数、オートスケールの状態などの統計情報がチャートで確認できます。
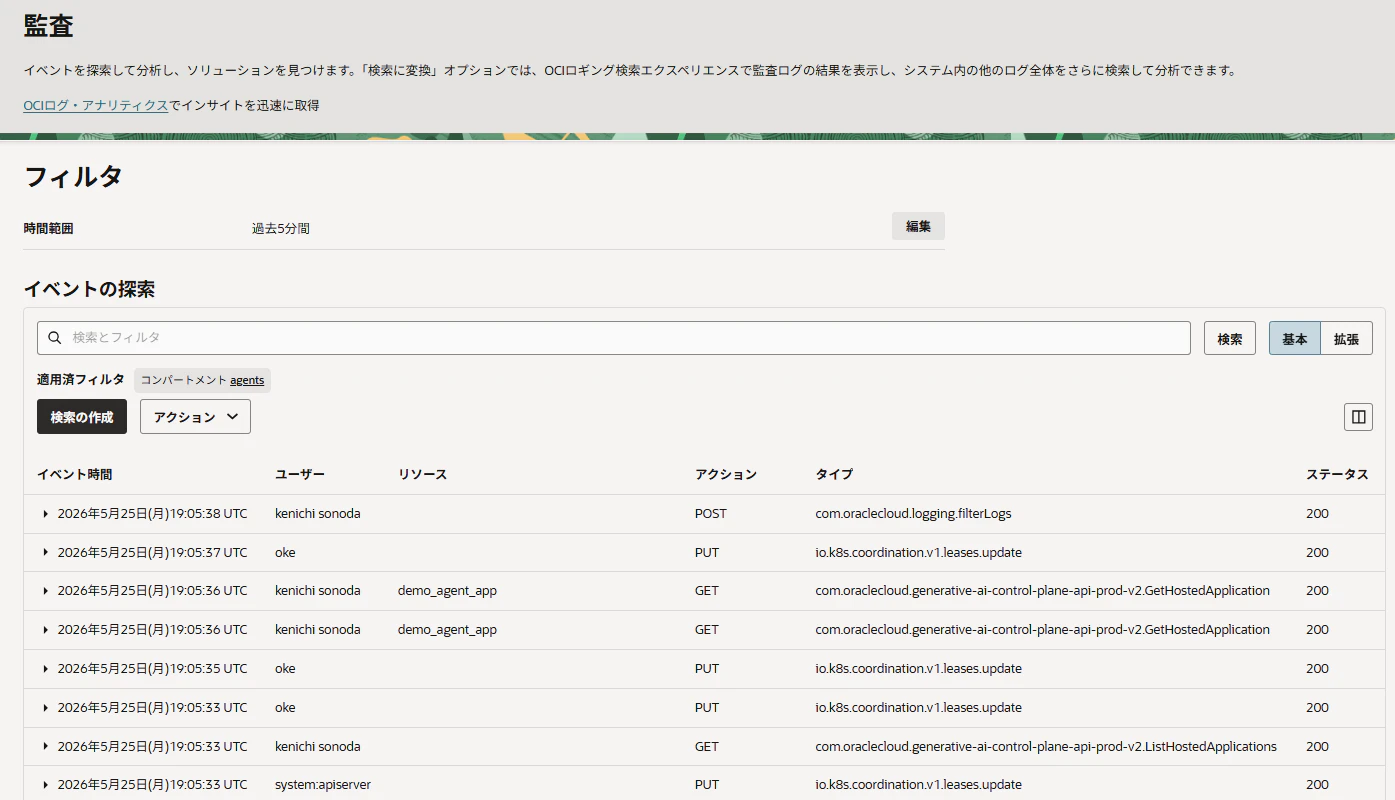
誰が、いつ、何の処理を行い、その処理の結果がどうだったのかなどの監査ログ(Audit Log)について下図の画面から確認できます。
また下図のように、エージェントの開発からデプロイまでのCI/CDをOCI DevOps Serviceを使って自動化することで更に便利に運用できるようになります。
さいごに
本記事ではOCI GenAIでのAgentOpsの仕組みと、同サービスの下記3つのメリットの主に「①エージェントの運用管理はクラウド任せ」についてエージェントのデプロイを中心に記載しました。
①エージェントの運用管理はクラウド任せ
②AgentOpsのための豊富な機能が既に実装済です
③多数の著名なOSSフレームワークをサポート
今後、②、③についても記事を作成し共有したいと思いますのでどうぞよろしくお願いいたします。