本記事は日本オラクルが運営する下記Meetupで発表予定の内容になります。発表までに今後、内容は予告なく変更される可能性があることをあらかじめご了承ください。
Headroomとは?
LLMにテキストを入力する前に、様々な処理を行い、入力トークン数を減らす(≒入力文字数を減らす)ことでトークン課金を削減することができるライブラリ。これ以上説明しようがないほどシンプルな目的のライブラリです。
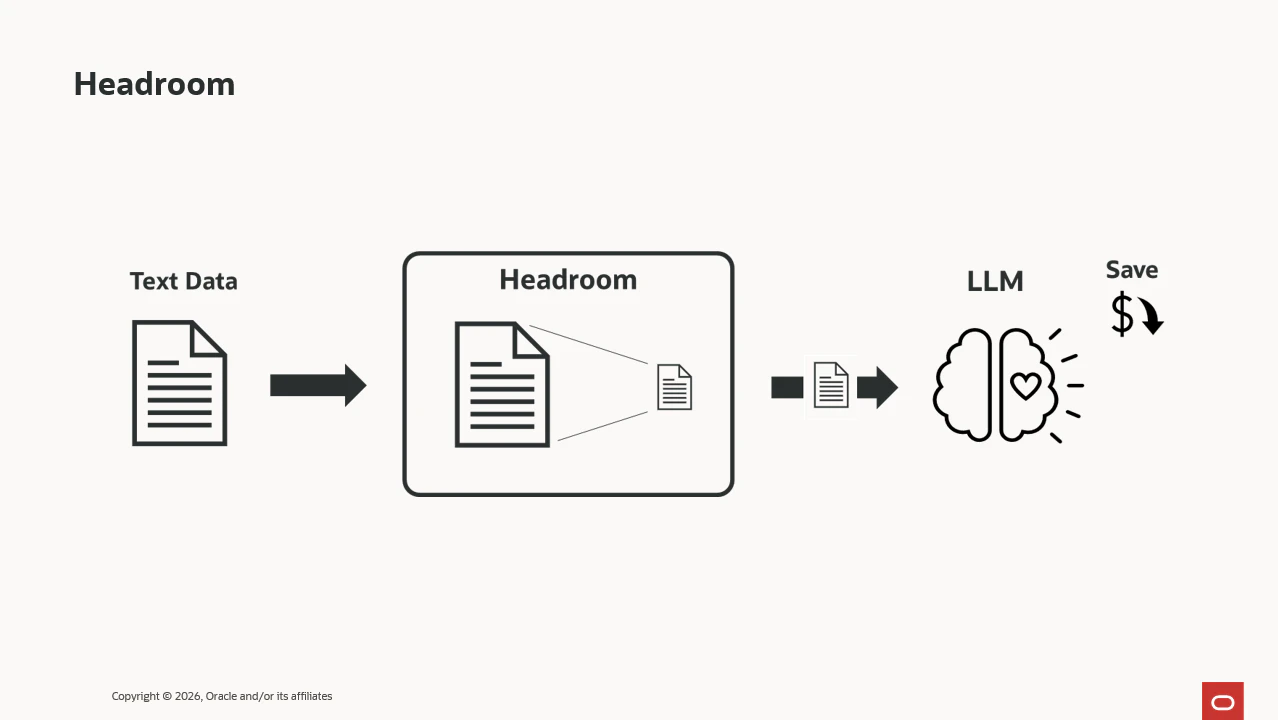
下記githubのリポジトリを見ると結構以前から公開されているものの、最近になってやたらXで共有されているので気になっていました。
Netflix社のエンジニアが開発し、githubで公開後、あっという間に大量のStarを獲得。最近は毎日 1k ほど増え、今やStarが50kという人気っぷりです。(githubでstarが50kはもう定番ツールです。)

仮にトークンの削減率が50%だとLLM課金が半額になるというとんでもないライブラリですから世界中の開発者が注目しているのも頷けます。
どうやってトークン数を削減している?
トークン数を節約するライブラリは様々なタイプがありますが、Headroomは入力テキストに「重複排除」、「構造圧縮」、「ノイズ削除」などの処理を施して、トークン数を削減するという機構がメインのようです。
よくある、LLMを使って入出力のテキストを要約するタイプ、ではないということですね。たしかにそれだとトークン課金の節約にはならない。
「重複排除」、「構造圧縮」、「ノイズ削除」とは、概ね以下のようなイメージです。
構造圧縮
構造圧縮は、データの形・繰り返し・冗長な表記を短くすることでトークンを減らす処理です。例えば下記のような入力データの場合です。
{
"id": 1,
"name": "Alice",
"role": "admin",
"created_at": "2026-06-22T10:00:00Z"
},
{
"id": 2,
"name": "Bob",
"role": "user",
"created_at": "2026-06-22T10:00:00Z"
},
{
"id": 3,
"name": "Carol",
"role": "user",
"created_at": "2026-06-22T10:00:00Z"
}
このJSONは、人間にもLLMにも読みやすいですが、毎回 "id", "name", "role", "created_at" というキーが繰り返されています。構造圧縮すると、下記のような形にすることができ、これにより文字数が少なくなるというイメージです。
columns: id, name, role, created_at
rows:
1, Alice, admin, 2026-06-22T10:00:00Z
2, Bob, user, 2026-06-22T10:00:00Z
3, Carol, user, 2026-06-22T10:00:00Z
別の例だと、下記のようなよくあるログデータも構造圧縮しやすいです。
[2026-06-22 10:00:01] ERROR service=auth user=123 message="timeout"
[2026-06-22 10:00:02] ERROR service=auth user=124 message="timeout"
[2026-06-22 10:00:03] ERROR service=auth user=125 message="timeout"
上記は、実質的には同じパターンのレコードが繰り返されていますので構造圧縮するとこんな感じ。
3 consecutive auth timeout errors:
- 10:00:01 user=123
- 10:00:02 user=124
- 10:00:03 user=125
重複排除
重複排除は、同じ内容が何度も出てきたときに、2回目以降を削除・まとめる処理です。例えば下記のようなログデータです。
ERROR timeout
ERROR timeout
ERROR timeout
まったく同じ文字列を3回入力する意味はほぼないので下記のようにまとめるイメージです。
ERROR timeout × 3
ノイズ削減
ノイズ削減は、LLMの回答にあまり役立たない情報を、入力前に削除したり、まとめたりする処理です。入力プロンプトのタスクに対して低価値、もしくは、むしろあると邪魔になるようなテキストを削除します。
例えば下記のようなシステムログから障害の原因を探したい場合です。
2026-06-22 10:00:01 INFO healthcheck ok
2026-06-22 10:00:02 INFO metrics flushed
2026-06-22 10:00:03 DEBUG cache hit key=user:123
2026-06-22 10:00:04 ERROR payment failed code=502
2026-06-22 10:00:05 INFO healthcheck ok
仮にこのデータと、「障害の原因を探して」というプロンプトをLLMに入力する場合、下記のように圧縮します。つまり、healthcheck ok や metrics flushed は、エラー調査には不要な情報ですので完全に削ったり、最低限の情報にまるめたりというイメージです。
Relevant log:
10:00:04 ERROR payment failed code=502
Suppressed:
- repeated healthcheck ok
- routine metrics flushed
- debug cache-hit logs
別の例として、APIレスポンスならこうです。
{
"id": "ord_123",
"status": "failed",
"error_code": "CARD_DECLINED",
"created_at": "2026-06-22T10:00:00Z",
"updated_at": "2026-06-22T10:00:01Z",
"request_id": "abc-xyz",
"trace_id": "trace-999",
"internal_metadata": {
"region": "ap-tokyo-1",
"worker": "worker-17"
}
}
このログからユーザー向けの失敗理由を説明したいだけなら、下記だけで十分という感じです。request_id や trace_id はサポート調査では重要かもしれませんが、ユーザー説明にはノイズとなる、ということが言えるからです。
order ord_123 failed: CARD_DECLINED
つまりノイズ削減は、入力プロンプトの目的に依存してノイズと判断された情報が削られます。
かなりシンプルなしくみのように感じますが、こようなデータが何千、何万行もあればその効果は大きくなりますよねという話なんだと思います。
効果的なユースケースは?
ここまでの説明でなんとなくわると思いますが、トークン数削減自体は上述したようなしくみがメインとなっているため、一般的なチャットラリーというよりも、下表に示したようなデータ分析処理などで大量のデータをLLMに食わせるときに一番効果を発揮するということになります。
-
システムログ障害解析
障害調査では、大量のログを LLM に渡して原因を探らせるケースがあります。ログにはタイムスタンプ、ホスト名、プロセス名、定型メッセージなど、繰り返し出てくる情報が多いため、Headroom による圧縮の効果が出やすい領域です。 -
データベース分析
SQL の実行結果やテーブルの行データを LLM に渡して分析させる場合、カラム名や JSON 風の構造、似たようなレコードが大量に並びがちです。このようなデータは冗長性が高いため、Headroom と相性がよいと考えられます。集計前の生データをある程度まとめて LLM に見せたいケースでは、特に効果が期待できます。 -
APIレスポンス調査
APIレスポンス(特にRESTやマルチエージェントでのエージェント間のメッセージなど)は、JSON のキー名やネスト構造が繰り返されるため、トークン数が膨らみやすいです。Headroom を使うことで、構造をある程度保ちながら冗長な部分を削減できるため、API の不具合調査やレスポンス比較に向いていそうです。 -
コードベース/リポジトリ解析
大きなコードベースを LLM に読ませる場合、import 文、型定義、定型的な関数、コメント、設定ファイルなどが大量に含まれます。Headroom はコードやファイル読み込みのようなコンテキスト圧縮も想定しているため、リポジトリ全体の調査、影響範囲の確認、バグ原因の探索といった用途で効果が出やすいと考えられます。
上述したワークロードではLLMに入力するデータを、JSON、Python dict/list、JavaScript object/array、ログ配列、検索結果リストのようなフォーマットで扱うことが多くなります。これらのフォーマットは似たような構造のエントリが繰り返されるデータセットですから、圧縮効果が高く、最も効果が期待できるユースケースということになります。
Headroomの説明では、圧縮対象として上述したようなデータ以外に、tool outputs、DB query、file read、RAG retrieval などが挙げられていますがそれぞれのワークロードによりトークン節約の効果は大きくバラつきがあるようです。
トークン節約効果を計測してみる
シナリオ
今回は、RDBに貯めこまれているECサイトのトランザクションログから、「何らかの障害により注文が失敗している状況を分析してみる」というシナリオで、これら一連の処理フローを実行するAIエージェントを実装します。(※上述した仕組みから、恐らくこのようなデータは節約効果が大きいはず。)
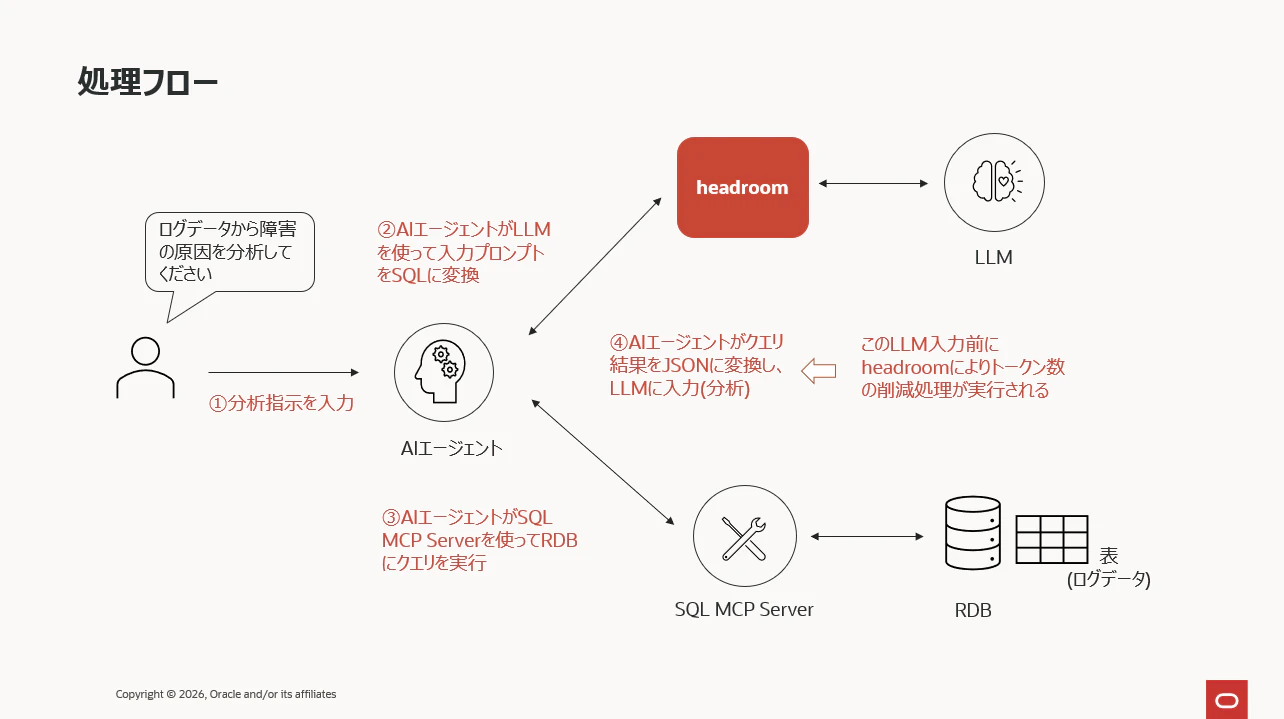
処理フローとしては、
①RDBに入っているログデータの分析指示を入力
②LLMを使って入力プロンプトをSQLに変換
③MCPでSQLをRDBに実行しクエリ結果を取得
④クエリ結果をJSON化し、分析指示とともにLLMに入力 ← この入力の手前でHeadroomの文字数削減処理が実行される
という流れ。
①、②、③はおまけで重要なのは④というこです。
構成
各パーツに使うサービスは以下の通り。今回Oracle Cloudに纏めましたが、他のハイパースケーラーでも概ね同じ構成になると思います。
- LLM : Oracle Cloud Infrastructure Generative AI Service
- RDB : Oracle Cloud Infrastructure Autonomous Database
- MCP : Oracle DBTools MCP Server (Oracle公式 github repositry)
※MCPはgithubに公開されているものを使いましたが、Autonomous Databaseにはクラウドの機能としてSQL MCP Serverが組み込まれていますのでそちらを使ってもいいと思います。)
ログデータ(RDBの表)
ECサイトの注文作成処理におけるトランザクションイベントを模したよくある項目で下記のようなサンプル表(sample_table)を作り、それっぽいサンプルレコードを50行ほど入れています。

この表にクエリを実行し、その結果をJSON化すると、下記のようなjsonキーのセットが何度も繰り返されるデータセットとなります。
{
"incident_id": "...",
"event_time": "...",
"service_name": "checkout-api",
"dependency_name": "payment-gateway",
"trace_id": "...",
"request_id": "...",
"error_code": "PAYMENT_GATEWAY_TIMEOUT",
"latency_ms": 1840,
"queue_depth": 11
}
↑このセットが何度も繰り返される
この繰り返される冗長なデータセットを、LLMに入力する前にHeadroomで圧縮し、トークンを節約するということになります。
Headroomの設定
まず、hearoomのインストールです。
$ pip install "headroom-ai[all]"
headroomのリポジトリを見ると下記のように様々な設定のパターンがあるようです。

上から順にいくつか見てみると、
- Libraryは普通にheadroomのライブラリの関数を使ってアプリを書くのでしょう。コード内でcompress(messages)関数を使って書くのだと思います。
- 二番目にProxyなるものがあります。コード変更不要と記載があるので、この使い方はなかなか惹かれます。
- Agent wrapはAIコーディングエージェントに組み込むことができるというところでしょう。今風ですね。
- そしてご丁寧にMCPサーバーも用意されている模様。
その他いろんなパターンがあり、いろいろと至れり尽くせりのライブラリのようで、これも人気の理由なのでしょう。
ということで、今回は何も考えずに使えそうな二番目のProxyパターンでHeadroomを動かしてみようと思います。
Proxyパターンは下記のようにheadroom proxyコマンドを実行するだけですが、最低限必要な2つの環境変数を設定しておきます。
- HEADROOM_COMPRESS_USER_MESSAGES=1
user messageを圧縮対象にする環境変数。今回SQLの結果セットをuser messageとして入力しますからこれは必須。 - OPENAI_TARGET_API_URL
OpenAI互換エンドポイントの環境変数。OCI Generative AI Serviceのそれをセットする必要があるのでこれも必須。
$ HEADROOM_COMPRESS_USER_MESSAGES=1
$ OPENAI_TARGET_API_URL=https://inference.generativeai.us-chicago-1.oci.oraclecloud.com/openai/v1
$ headroom proxy --port 8787
ようは、LLMのエンドポイントURLに対して、ローカルのheadroomを経由させるようにプロキシを立てるイメージです。
これにより、LLMに入力するデータは、事前にheadroomを通ることになり、そのタイミングでデータが圧縮されるということですね。
Headroomの設定はこれで完了。
驚くほど簡単に使えるように作られていることがわかります。
AIエージェントの処理フローを実行
次に、上述したシナリオ(ログデータの分析)の処理フローをコードにします。今回このコードはあまり重要ではありませんのでさらっと読み流してくださって大丈夫です。
最も重要なのは、このコードを実行したときに、Headroomによってどれだけトークンが節約できたのかという点です。
一応コードの概要を簡単に記載します。
必要なライブラリを読み込みます。
import importlib.util
import json
import os
import re
from pathlib import Path
from fastmcp import Client
from openai import OpenAI
MCPで使うローカルのOracle dbtoolsサーバーとDatabase Tools接続名を定義します。
BASE_DIR = Path("/home/opc/headroom/adb_analysis")
DBTOOLS_MCP_SERVER = BASE_DIR / "dbtools-mcp-server.py"
DBTOOLS_CONNECTION_NAME = "conn_demoadb01"
dbtools-mcp-server.pyを読み込み、FastMCPサーバーオブジェクトを取得します。
spec = importlib.util.spec_from_file_location("dbtools_mcp_server", DBTOOLS_MCP_SERVER)
dbtools_mcp_server = importlib.util.module_from_spec(spec)
spec.loader.exec_module(dbtools_mcp_server)
dbtools_mcp = dbtools_mcp_server.mcp
OCI Generative AIのOpenAI互換エンドポイントを定義します。
既にHeadroom proxyを起動しているので、LLM呼び出しをproxy経由にします。
COMPARTMENT_ID = "ocid1.compartment.oc1..xxxxxxxxxxx"
API_KEY = "sk-xxxxxxxxxxx"
BASE_URL = "https://inference.generativeai.us-chicago-1.oci.oraclecloud.com/openai/v1"
HEADROOM_PROXY_BASE_URL = "http://127.0.0.1:8787/v1"
os.environ.setdefault("OCI_GENAI_BASE_URL", HEADROOM_PROXY_BASE_URL)
MODEL = "openai.gpt-oss-120b"
SQL生成と分析に使うLLMクライアントを定義します。
client = OpenAI(
base_url=os.environ.get("OCI_GENAI_BASE_URL", BASE_URL),
api_key=os.environ.get("OCI_OPENAI_API_KEY", API_KEY),
default_headers={
"opc-compartment-id": os.environ.get("OCI_COMPARTMENT_ID", COMPARTMENT_ID),
"CompartmentId": os.environ.get("OCI_COMPARTMENT_ID", COMPARTMENT_ID),
},
timeout=120,
max_retries=2,
)
ユーザーの入力プロンプト(今回のシナリオである分析の指示)を定義します。
QUESTION = (
"operation_name が CREATE_ORDER かつ error_code が PAYMENT_GATEWAY_TIMEOUT のログを時系列で抽出し、"
"ECサイトの決済タイムアウト障害の原因、影響、初動対応、再発防止策を分析してください。"
)
LLMが正しいOracle SQLを生成できるように対象テーブルと列名を渡します。
SCHEMA = """
table: sample_table
columns:
incident_id, event_time, environment, region, service_name, dependency_name,
trace_id, request_id, order_id, customer_tier, customer_region, payment_method,
operation_name, status, http_status, error_code, retry_count, latency_ms,
queue_depth, db_wait_ms, connection_pool_wait_ms, message, investigation_note
"""
SQL実行結果JSONをLLMに分析させるときの分析ポイントを定義します。
ANALYSIS_PROMPT = """以下のOracle Database検索結果JSONを分析してください。
出力は日本語で、次の観点を簡潔に整理してください。
1. 何が起きているか
2. 主原因の推定
3. 影響を受けたサービスと依存先
4. 顧客プラン、地域、支払い方法の傾向
5. レイテンシ、キュー深度、接続プール待ちの傾向
6. 根拠となるtrace_id、request_id、error_code
7. 初動対応
8. 再発防止策
注意:
- JSONに含まれる情報だけを根拠にしてください。
- 推定は「推定」と明記してください。
"""
入力プロンプトとスキーマから、Oracle SQL生成用のプロンプトを定義します。
sql_prompt = f"""次の依頼に答えるためのOracle SQLを1つだけ生成してください。
{SCHEMA}
条件:
- SELECT文のみ
- sample_tableのみ使用
- 関連ログをevent_time順に並べる
- 依頼に書かれた文字列値は表記を変えずに使う
- コードフェンス、説明、末尾セミコロンは出力しない
依頼:
{QUESTION}
"""
LLMにSQLを生成させます。
sql_response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "あなたはOracle SQLを生成するアシスタントです。"},
{"role": "user", "content": sql_prompt},
],
temperature=0,
)
上記コードで作成されたSQLからコードフェンスや末尾セミコロンだけを取り除きます。
sql = sql_response.choices[0].message.content.strip()
sql = re.sub(r"^```(?:sql)?\s*", "", sql, flags=re.IGNORECASE)
sql = re.sub(r"\s*```$", "", sql).strip().rstrip(";")
MCPのexecute_sql_toolで、生成されたSQLをADBに対して実行します。
async with Client(dbtools_mcp, timeout=180, init_timeout=120) as dbtools_client:
dbtools_result = await dbtools_client.call_tool(
"execute_sql_tool",
{
"dbtools_connection_display_name": DBTOOLS_CONNECTION_NAME,
"sql_script": sql,
},
)
MCPのSQL実行結果から行データを取り出し、LLM分析用のJSONに整形します。
raw_dbtools_json = json.loads(dbtools_result.content[0].text)
rows = raw_dbtools_json["items"][0]["resultSet"]["items"]
table_result = {
"source": "oracle-dbtools-mcp-server.py",
"dbtools_connection": DBTOOLS_CONNECTION_NAME,
"generated_sql": sql,
"row_count": len(rows),
"rows": rows,
}
table_json = json.dumps(table_result, ensure_ascii=False, indent=2)
SQL実行結果JSONと分析指示をまとめて、LLMに障害分析を依頼します。
prompt = f"""{ANALYSIS_PROMPT}
ユーザー依頼:
{QUESTION}
Oracle Database検索結果JSON:
```json
{table_json}
```"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "あなたはSREとDB分析に詳しいアシスタントです。"},
{"role": "user", "content": prompt},
],
temperature=0.1,
)
print(response.choices[0].message.content)
上記コードの実行結果は下記のように出力され、シナリオ通り、ログデータがちゃんと分析されていることがわかります。
**1. 何が起きているか**
- `operation_name = CREATE_ORDER` のリクエストが、`error_code = PAYMENT_GATEWAY_TIMEOUT` で失敗しています。
- 取得した 5 件のレコードすべてで `status = FAILED`、HTTP ステータスは 503(サービス利用不可)です。
- タイムアウトは決済ゲートウェイへの呼び出しが完了せず、リトライを行った後でも応答が返らなかったことが原因です。
**2. 主原因の推定**
- **推定**:決済ゲートウェイ側の処理遅延/スロットリングが発生し、バックエンドの承認ジョブがキューに滞留している。
- `queue_depth` が 11〜16 と増加傾向にあり、`latency_ms` が 1.8‑2.3 秒と通常の決済フロー(数百ミリ秒)を大きく上回っている。
- `connection_pool_wait_ms` は数ミリ秒と小さいが、`db_wait_ms` が 120‑165 ms とやや高く、DB でも待ちが発生している可能性がある。
- `investigation_note` では「settlement initialization waited behind other gateway jobs」や「final authorization step failed」など、ゲートウェイ内部のジョブキューが飽和していることが示唆されています。
<中略>
**8. 再発防止策**
| カテゴリ | 対策 |
|----------|------|
| **決済ゲートウェイ側** | - ゲートウェイのジョブキュー監視と自動スケールアウトを導入。<br>- タイムアウト閾値を動的に調整し、バックプレッシャーがかかった際は即座にリトライ間隔を伸ばす。 |
| **アプリケーション側** | - `checkout-api` のタイムアウト設定を決済ゲートウェイの SLA に合わせて見直す。<br>- リトライ回数上限を緩和し、バックオフ戦略(指数バックオフ+ジッター)を実装。 |
| **観測・アラート** | - `queue_depth > 10`、`latency_ms > 1500` の組み合わせで即時アラートを発火。<br>- `payment-gateway` の内部メトリクス(ジョブ待ち時間、スレッドプール使用率)を SRE ダッシュボードに統合。 |
| **顧客体験** | - 決済失敗時に「別の決済手段へ変更」ボタンを UI に追加し、リトライによる顧客離脱を防止。<br>- 障害時のステータスページでリアルタイム障害情報を公開。 |
| **テスト** | - 決済ゲートウェイのスロットリングシナリオをシミュレーションし、システム全体の耐障害性を定期的にロードテスト。 |
---
**まとめ**
- `CREATE_ORDER` の決済タイムアウトは、決済ゲートウェイ内部のジョブキュー飽和が主因と推定されます。
- 影響は北米・標準プランのカード決済と、EMEA・エンタープライズの銀行振込に及び、`checkout-api` が直接障害を受けています。
- 初動では障害の可視化、決済プロバイダーへのエスカレーション、代替決済手段の提示を実施し、再発防止にはゲートウェイ側のスケーラビリティ向上とアプリ側のリトライ・タイムアウト調整を行うことが重要です。
これでログの分析処理完了です。
最も重要な確認はこの処理を実行した際、Headroomによってどれだけトークンが節約できたのかという点です。
Headroomのトークン節約効果を確認する
下記のようにhaedroomのproxyエンドポイントのstatusをcallすると様々な情報が得られますが、その中でも★マークを付けた下記3つを確認すると一目で効果がわかります。
- input_tokens_original : 圧縮前のトークン数
- tokens_saved : Headroomによって節約できたトークン数
- savings_percent : トークンの節約率
$ curl -s http://127.0.0.1:8787/stats | jq '.recent_requests[-2:]'
[
{
"request_id": "hr_1782298554_000001", <-------- 一回目のLLM入力時
"timestamp": "2026-06-24T10:56:01.219507",
"provider": "openai",
"model": "openai.gpt-oss-120b",
★"input_tokens_original": 176,
"input_tokens_optimized": 308,
"output_tokens": 321,
★"tokens_saved": 0,
★"savings_percent": 0.0,
"optimization_latency_ms": 2876.26576423645,
"total_latency_ms": 6578.337907791138,
"transforms_applied": [],
"waste_signals": null
},
{
"request_id": "hr_1782298561_000002", <-------- 二回目のLLM入力時
"timestamp": "2026-06-24T10:56:22.519528",
"provider": "openai",
"model": "openai.gpt-oss-120b",
★"input_tokens_original": 1702,
"input_tokens_optimized": 1300,
"output_tokens": 2616,
★"tokens_saved": 746,
★"savings_percent": 43.83078730904818,
"optimization_latency_ms": 4675.999879837036,
"total_latency_ms": 20840.35611152649,
"transforms_applied": [
"router:mixed:0.57"
],
"waste_signals": {
"json_bloat": 1566,
"html_noise": 0,
"base64": 0,
"whitespace": 0,
"dynamic_date": 0,
"repetition": 0,
"reread": 0,
"reread_compressed": 0
}
}
]
今回の処理コードではLLMが2回呼ばれます。
一回目は入力プロンプトをSQLに変換するためにLLMを使っています。このような入力には重複排除や構造圧縮の対象になるデータが存在しないので tokens_saved はゼロ、つまりトークン節約効果は全くありません。普段私達がChatGPTで何かを調べたり、質問したりする使い方はこちらのパターンと似た処理になり、このような処理では残念ながらトークン課金削減効果は期待できないということです。これは予想通り。
そして本命は二回目のLLMの処理です。RDBのクエリ結果をJSONに変換し、そのデータを分析するためにLLMに入力します。この入力の前に、各レコードに対して重複排除や構造圧縮の処理が施され、上記の結果としては tokens_saved が 746トークン。input_tokens_originalが1702トークン。ということで savings_percent にある通り、44%近いトークン節約となりました。
※因みに、出力トークンは節約対象にはなりません。
おわりに
今回はやや恣意的なサンプルデータを作りましたが、実システムのログデータでも似たような状態になるケースは十分ありそうです。実データをお持ちの方は、ぜひ試してみてください。
また、Headroom の GitHub repository では、RAG のようなシステムでも効果が期待できると説明されていますが個人的には少し懐疑的です。RAG では、セマンティック検索や全文検索によって LLM に入力されるコンテキストがかなり絞り込まれます。また、仮にコンテキストをあまり絞らなかったとしても、JSON のような冗長な構造を持つコンテキストを大量に扱うケースは、そこまで多くないように感じるからです。
また、マルチエージェントのアプリでは、エージェント間のメッセージはpython辞書型になる場合が多いですから、こちらはある程度の節約効果が期待できると思います。AIコーディングエージェントも同様です。
ですが、やはりHeadroom が特に活きるのは、LLM を使って大量データを入力し、分析するようなユースケースだと思います。