本記事は日本オラクルが運営する下記Meetupで発表予定の内容になります。発表までに今後、内容は予告なく変更される可能性があることをあらかじめご了承ください。
セミナー実施済の動画はこちら。
もくじ
1. はじめに
2. 仕組み
3. 構成
4. コード概説
5. 文章でRDBにクエリを実行してみる
6. その他のDML、DDLに相当する文章も試してみる
7. 番外編 CohereのLLMを使ってみる
8. さいごに
1. はじめに
2017年Google社がTransformerを世に送り出して以降、主に自然言語処理を専門としている一部のエンジニア界隈だけ?で水面下で盛り上がっていた大規模言語モデル(LLM)の技術エリアは、2022年暮れにリリースされたOpenAI社のChatGPTによって一気に花開き、世界中に知れ渡ることになりました。
そして2023年現在、世界は空前のAIブーム。LLMの将来性から、サービスをリリースしさえすればキャズム確定かのように同市場には巨額の投資マネーが流入し、巨大企業からスタートアップまで我先にと大量GPUの買い注文をかけ、皆がGPU納品の長い長い待ち行列に並んでいるという状況。
そんなご時世の中、ようやく産声を上げたLLMの利用用途を素人ながらに考察してみると、今後もChatGPTのような新規性のあるサービスはどんどん生まれてくるという方向性と同時に、既存の製品やサービスをLLMでエンハンスする方向性も大いに加速するのだろうと推測します。

特に、既存ITベンダーからすると技術的にはそちらのほうが圧倒的にやりやすく、例えば弊社オラクルは早速下記プレスのように、既にリリース済の人事系クラウドサービスをLLMによってエンハンスしています。今後ERP、SCM、CXなどのサービスも続々と続くことでしょう。
オラクル、人事部門の生産性向上に役立つジェネレーティブAI機能を発表
あまり話を大きくしすぎると本記事のタイトルと乖離してしまうので導入話はこの辺にして、ようは、Python、SQLなどのコンピュータ言語やBIなどの専門的なツールではなく、言葉(LLM)で様々なシステムやアプリケーションを操作できるようになると、プログラミングや難解な統計の知識がなくても、誰しもがデータ分析など高度な処理を、抽象的な言葉で実行できるようになる世界がくるのでは?という願いを込め、そのプリミティブなアイデアの一つとして、本記事では下図のようにデータベースを自然言語で操作・分析する処理サンプルをご紹介しようと思います。
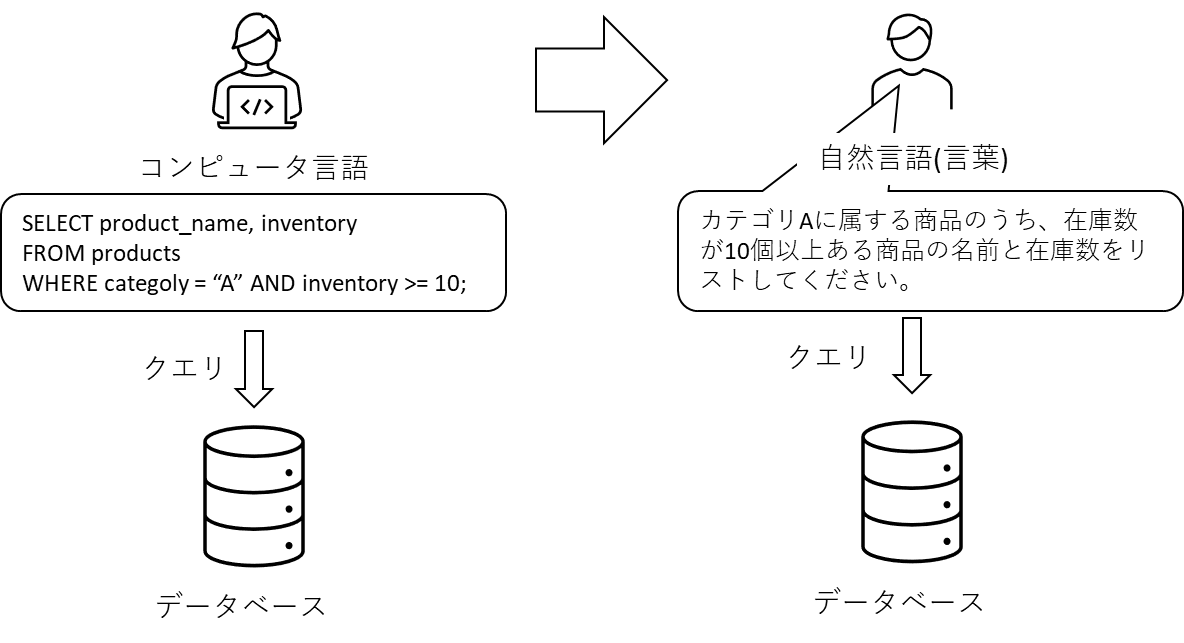
設定やコードには興味ないので結果だけ教えて、という方は 「文章でRDBにクエリを実行してみる」へどうぞ。
2. 仕組み
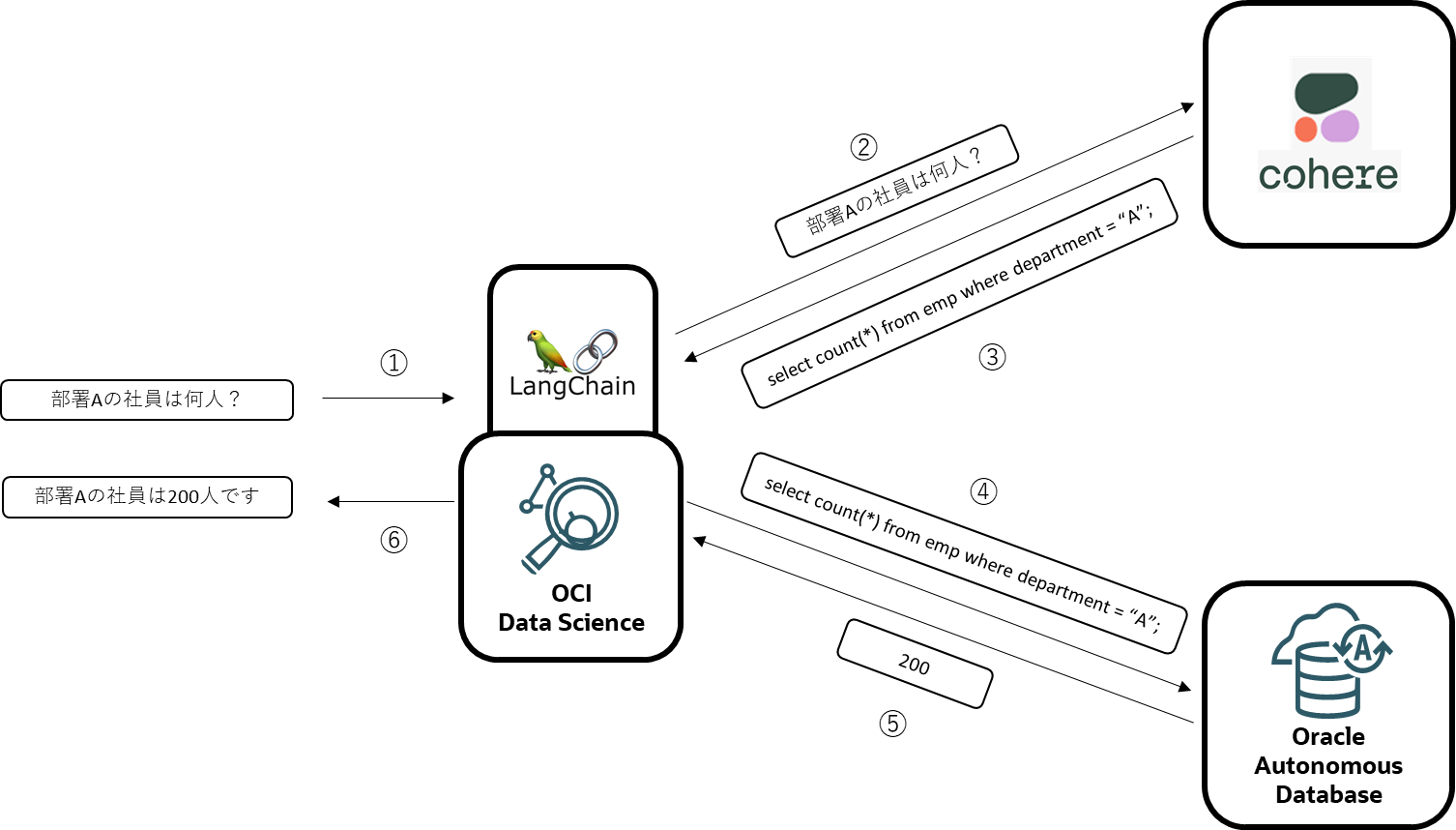
始めにネタバレしておくと、以降で解説するコードはLangChainを使ってLLMサービスやRDBを連携させるという仕組みで、概ね下記のようなフローで処理が行われます。
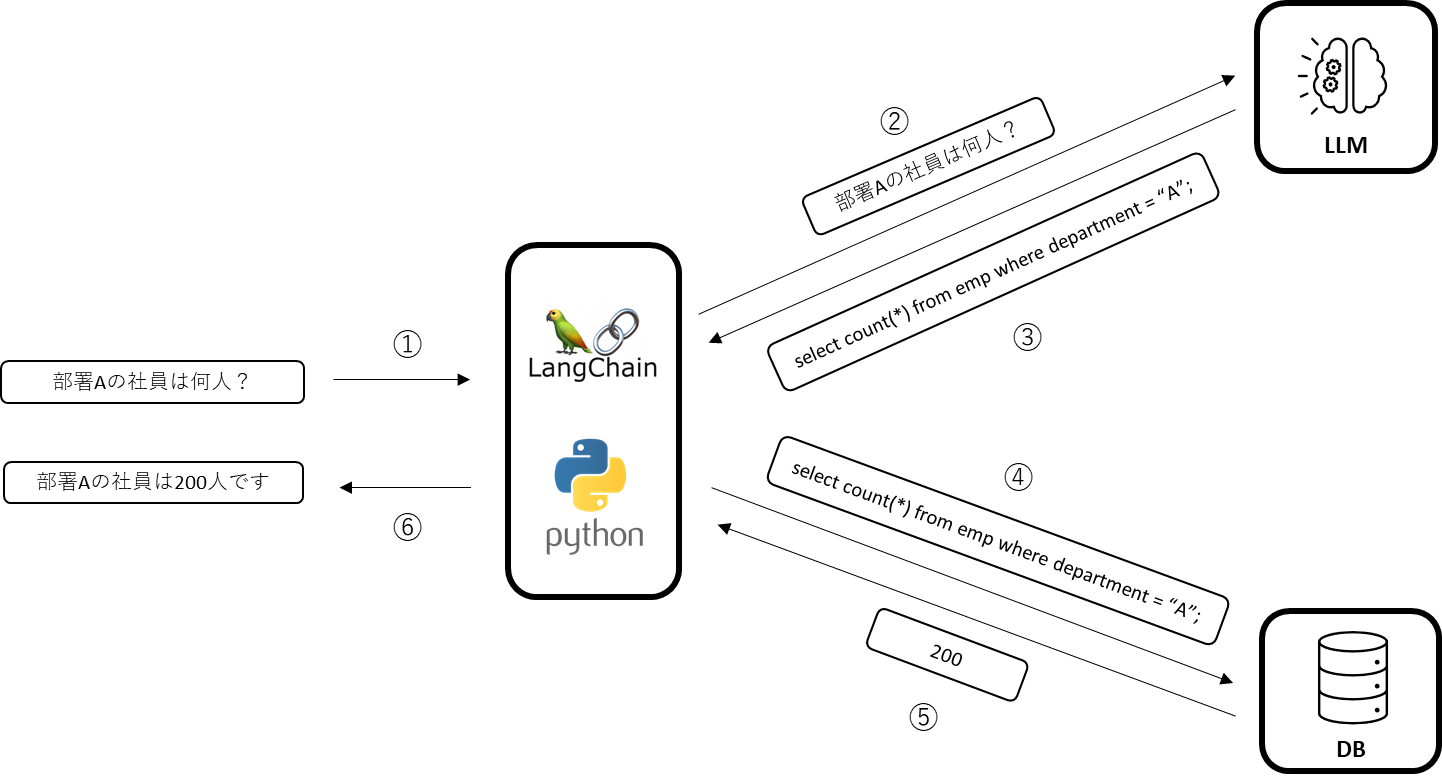
①文章をLangChainに入力
②入力文章をLLMに連携し
③LLMで文章解析、SQLに変換後
④RDBに接続し、クエリ実行
⑤クエリ結果を獲得
⑥クエリ結果をLLMで文章に変換し、出力する
PythonからLLMやDBとの連携は定型的な処理になりますから、LangChainで抽象化して処理され、結果、実質のコードはわずか数行、面倒なところは全てLLMとLangChainに丸投げという仕組みです。
3. 構成
従って、上記処理フローの主だった登場人物は下記3つ。
- LLM
- LangChain(とPython環境)
- Database
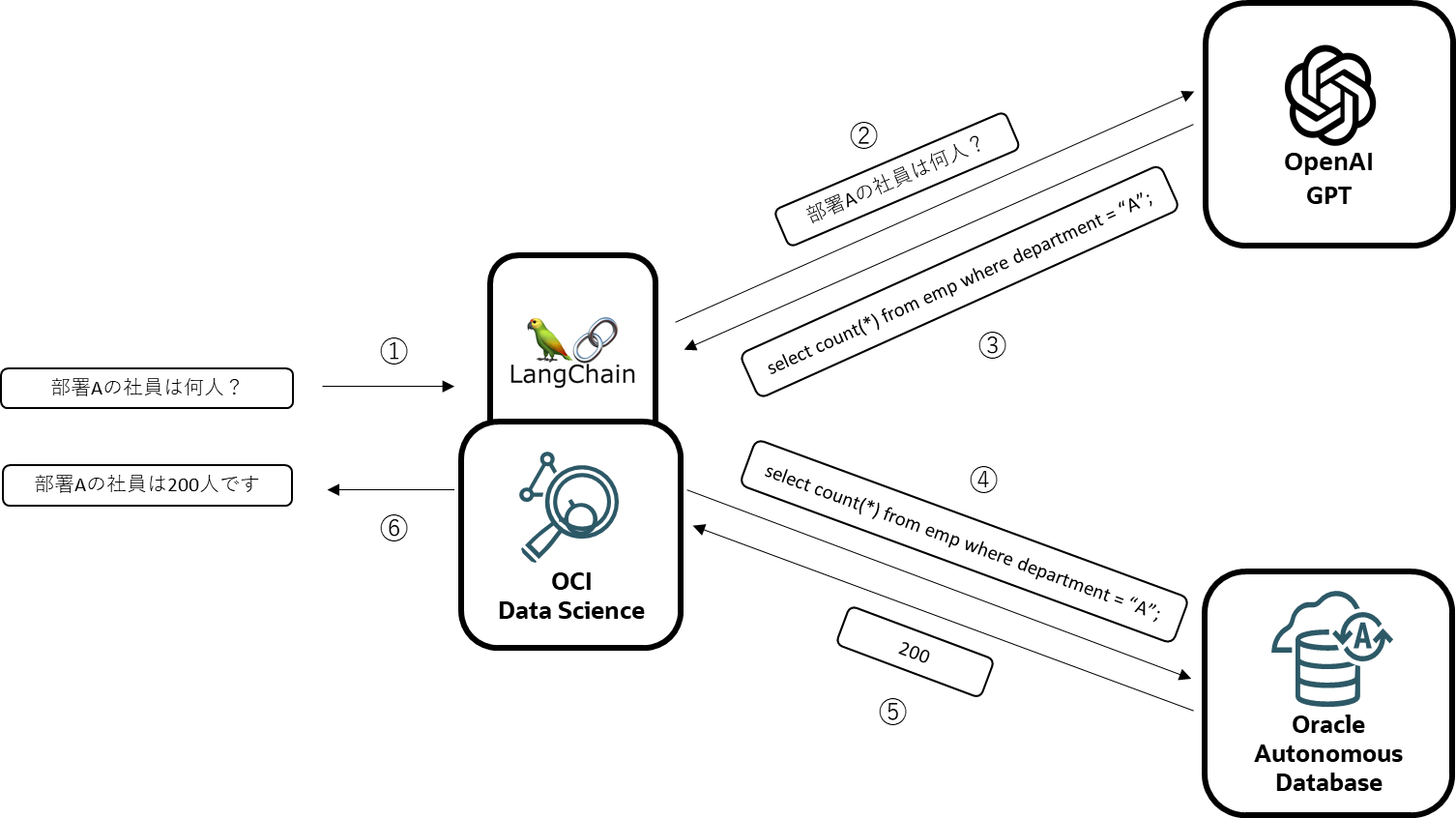
そして、今回はこの3つの要素に、下記のクラウドサービスを使ってみます。
- LLM -> OpenAI社のGPT
- LangChain(とPython環境) -> Oracle CloudのData Science Service
- Database -> Oracle CloudのAutonomous Database Service
先ほどの処理フローに各社のサービスをマッピングすると下図のようになります。
以降は、この3つのサービスと、それらの構築の概要手順になります。
設定やコードには興味ないので結果だけ教えて、という方は 「文章でRDBにクエリを実行してみる」へどうぞ。
LLM(大規模言語モデル)
LLMはLangChainから連携された入力テキストを解析しSQLに変換するという重要なタスクを担当します。今回、LLMにはChatGPTでお馴染み、OpenAI社のLLMであるGPTを使ってみます。まずは、GPTのサービスを利用するために、OpenAIのサイトにユーザー登録を行い、APIキーを入手します。
具体的な手順は下記サイトが非常にわかりやすいです。
作成したAPIキー下図のようにマイページのAPI Keysのメニューで管理できます。
Usageメニューで現在の課金状況を確認できます。プログラムを実行するたびに、この課金メーターが上がっていく様子がわかります。
GPTは世界で一番有名なLLMになりますが、OpenAI社以外にも様々なベンダーからLLMサービスがリリースされており、精度の話を抜きにするとLangChainがサポートしているものであればなんでも動きます。
LangChainがサポートするLLM
GPTの他、有名なLLMとしては、Google社のBERTがあります。こちらはGoogle社のチャットボットBardや、Google翻訳にも実装されている、オープンソースのLLMです。BERTについては本ミートアップで過去に扱いましたのでよろしければ下記をご参照ください。
自然言語と機械学習(BERTについて解説)
皆さんはCohere(コヒア)社のLLMをご存じでしょうか。昨年暮れから今年にかけて、多数の企業から巨額の資金調達に成功したスタートアップです。LangChainはCohereもサポートしているようなので今回は番外編でCohereのLLMも扱ってみたいと思います。
LangChain(とPython環境)
現在、LLM周辺には様々なフレームワークのライブラリが存在します。有名なところだと以下のようなものです。
- LangChain
- LlamaIndex
- Sementic Kernel
どのツールもLLMと、その他のサービスとの連携を主な目的としたフレームワークになっており、LLMからの連携先のサービスに応じて、様々な処理を抽象度の高い関数でシンプルにコーディングできる非常に多機能なライブラリとなっています。これらのフレームワークの一番の老舗であるLangChainの主だった連携サービスを見てみると以下のようなものになります。
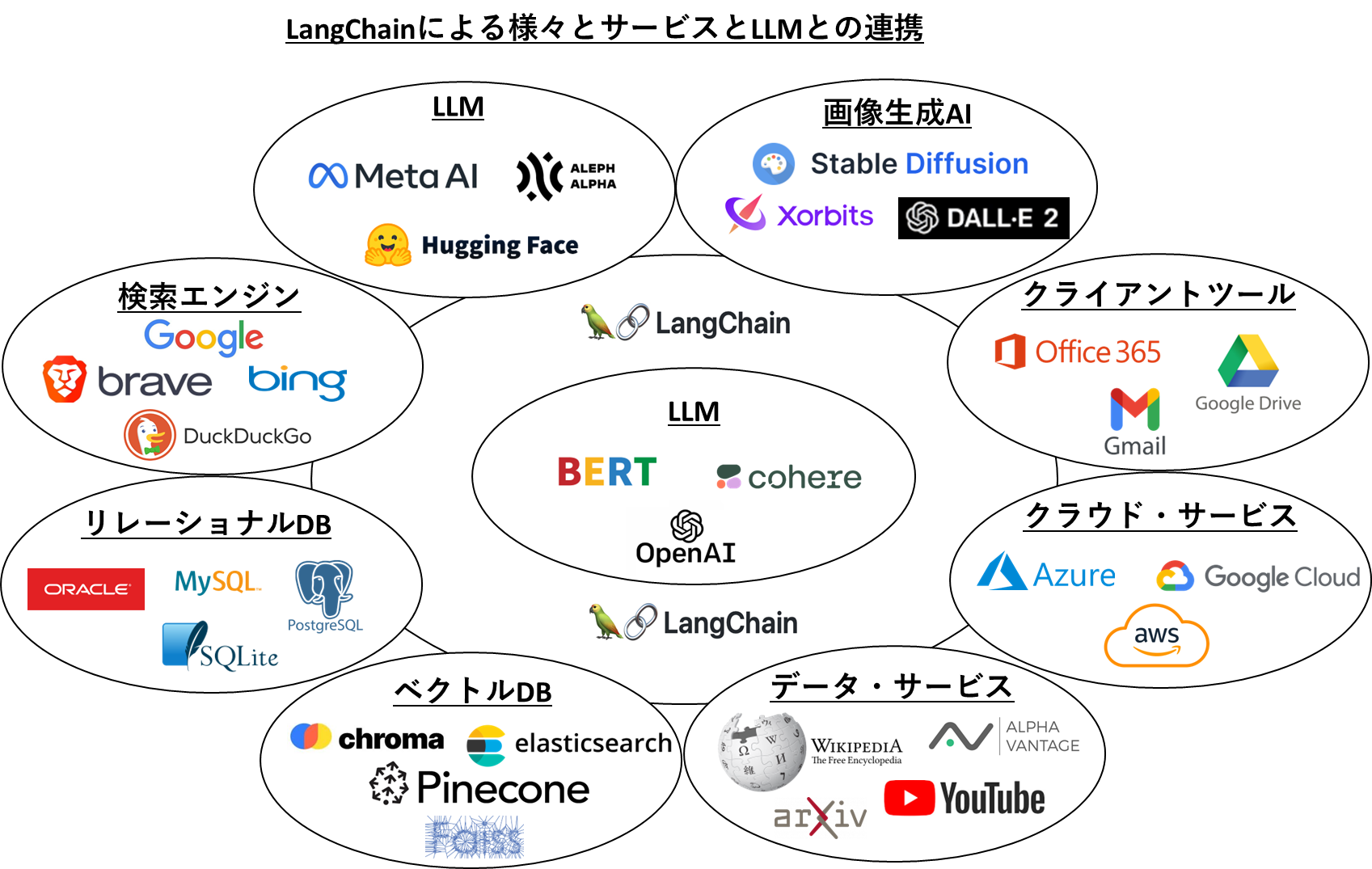
連携構造としては非常にシンプルで、LLMと、連携サービスとの間にLangChainが位置し、連携の司令塔となります。LangChainはLLMや、連携サービスとの接続を保持しており、処理したい内容に応じて、プロンプトをLLMに連携したり、LLMから得られた情報を、その他のサービスに連携したり(その逆も行います。)と、データフローとしてはLLMと連携サービスの間を行ったり来たりすることになります。このような処理を各サービスのAPIを使ってゼロベースで開発すると相当なコード量になりますが、LangChainはそこを抽象化し、数行のコードで実現できるようなライブラリになっています。
LangChainには複数のモジュールがあり、今回はRDB操作のためのSQLDatabaseChainを使います。また、Python環境として今回はOracle CloudのData Science Serviceを使ってみます。Jupyterノートブックベースの機械学習環境が簡単にプロビジョニングできてPaaSとしては無償というサービスです。と言っても、このあとご紹介するサンプルコードは通常のPython環境であればどこでも動きます。OracleのData Science Serviceにご興味がある方は是非下記をご参照ください。
Data Science Serviceを使ってみようかなと思われる方は、サービス概要をご紹介したブログおよび初期セットアップを下記からご参照ください。フリートライルもありますので是非!
データベース
LangChainを使って自然言語でRDBを参照するという記事は何番煎じになるのかわからないほと既に沢山ありますが、大抵の記事では簡易的にSQLiteを使っているケースが多いようなので、本記事ではOracle CloudのAutonomos Databaseを使って少しでもオリジナリティを出だせればと思います。
LangChainはDB接続やクエリ処理を実行してくれますが、内部ではお馴染みのORMライブラリSQLAlchemyが使われます。従って、SQLAlchemyがサポートしているDBであればなんでも動作します。
サクッと試したい方は、SQLite、MySQL、PostgreSQLなどLangChainがサポートしているDBをローカルにインストールするか、コンテナでいいと思います。
まずは下記手順に従ってAutonomous Databaseのインスタンスを作ります。
データベースインスタンスの作成が完了したら、次はスキーマ作成です。スキーマは本当に何でも構わないのですが、下記のような簡単なものを作成して少しだけデータを入れておこうと思います。Oracle DBのサンプルスキーマなどをインストールしていただいてもかまいません。
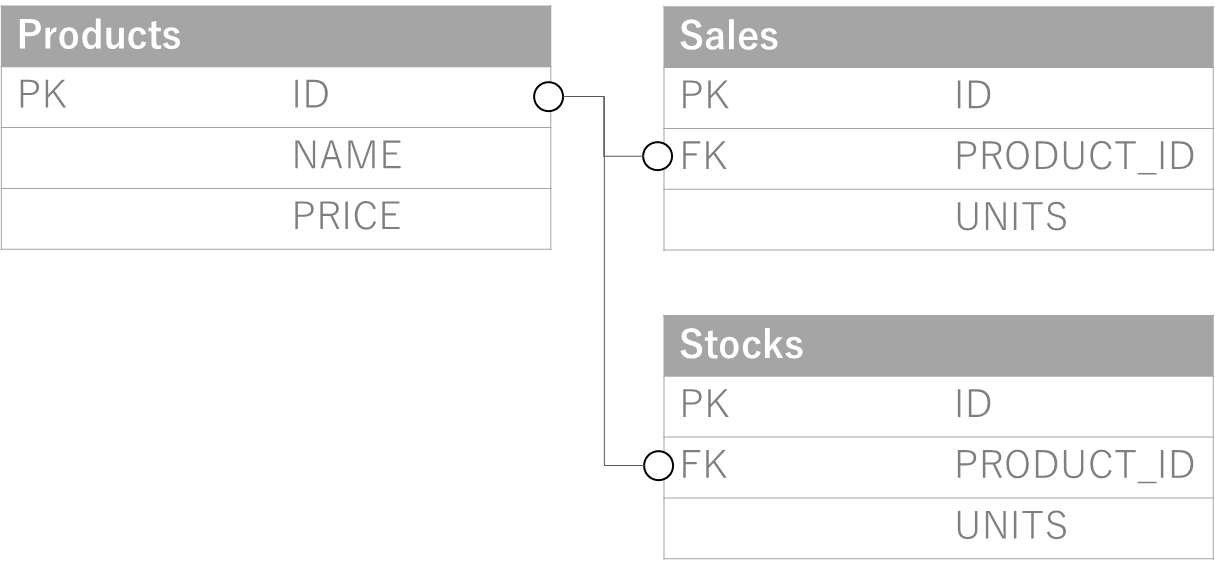
上記の表とレコードの作成SQLはこちら。Pythonから実行していただいてもかまいませんが、Autonomous Databaseは付属のコンソールからSQLが実行できますので是非使ってみてください。
drop table products;
create table products(
id INTEGER,
name VARCHAR2(255) NOT NULL,
price INTEGER NOT NULL,
primary key(id)
);
insert into products values(1,'商品A',100);
insert into products values(2,'商品B',200);
insert into products values(3,'商品C',300);
select * from products;
drop table sales;
create table sales(
id INTEGER,
product_id INTEGER NOT NULL,
units INTEGER NOT NULL,
primary key(id),
foreign key(product_id) references products(id)
);
insert into sales values(1,1,1500);
insert into sales values(2,2,1000);
insert into sales values(3,3,500);
select * from sales;
drop table stocks;
create table stocks(
id INTEGER,
product_id INTEGER NOT NULL,
units INTEGER NOT NULL,
primary key(id),
foreign key(product_id) references products(id)
);
insert into stocks values(1,1,100);
insert into stocks values(2,2,500);
insert into stocks values(3,3,1000);
select * from stocks;
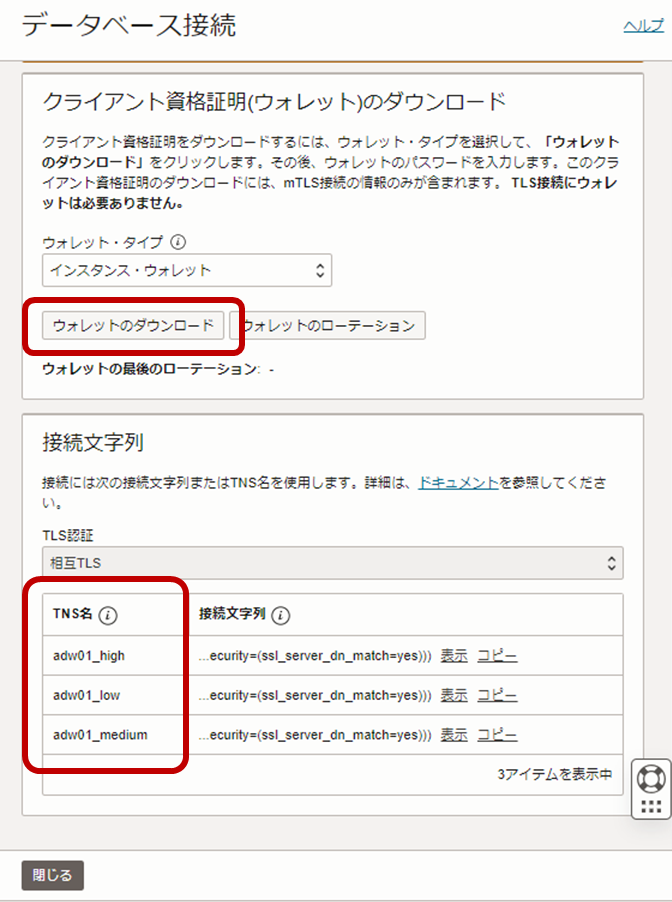
次に、LangChain(Python環境であるData Science Service)からDB接続(Autonomous Database Serviceへの接続)のために必要な設定を行います。Autonomous DatabaseはOracle Walletで接続認証しますので、Walletファイルをコンソールからダウンロードしセットする必要があります。下図の通り、コンソールの「データベース接続」から「データベース接続」の画面に移動します。
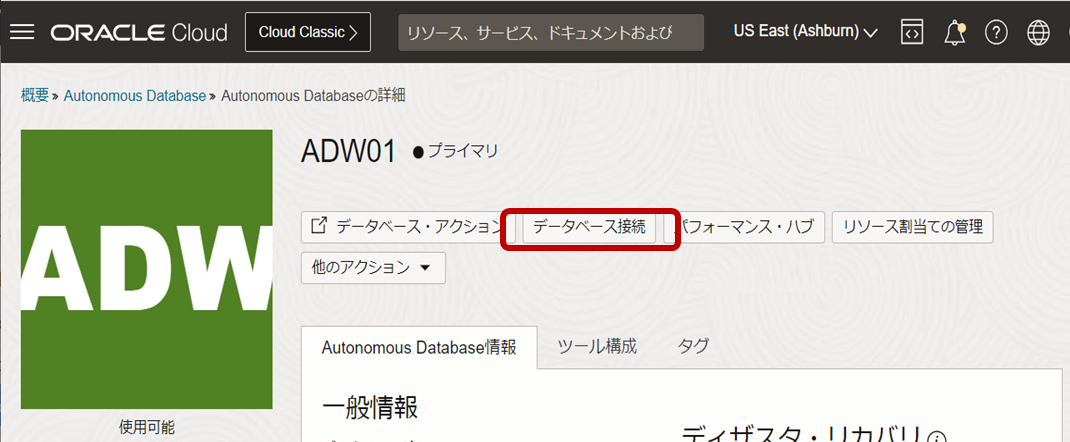
この画面の、「ウォレットのダウンロード」ボタンからまずはウォレットファイルをローカルにダウンロードしつつ、この画面でデータベースの接続文字列を確認しておきます。下図では「adw01_high」などになっていることがわかります。
ローカルにダウンロードしたWalletファイル(zipファイル)を、下図のようにData Science Serviceの任意のディレクトリにアップロードし解凍します。
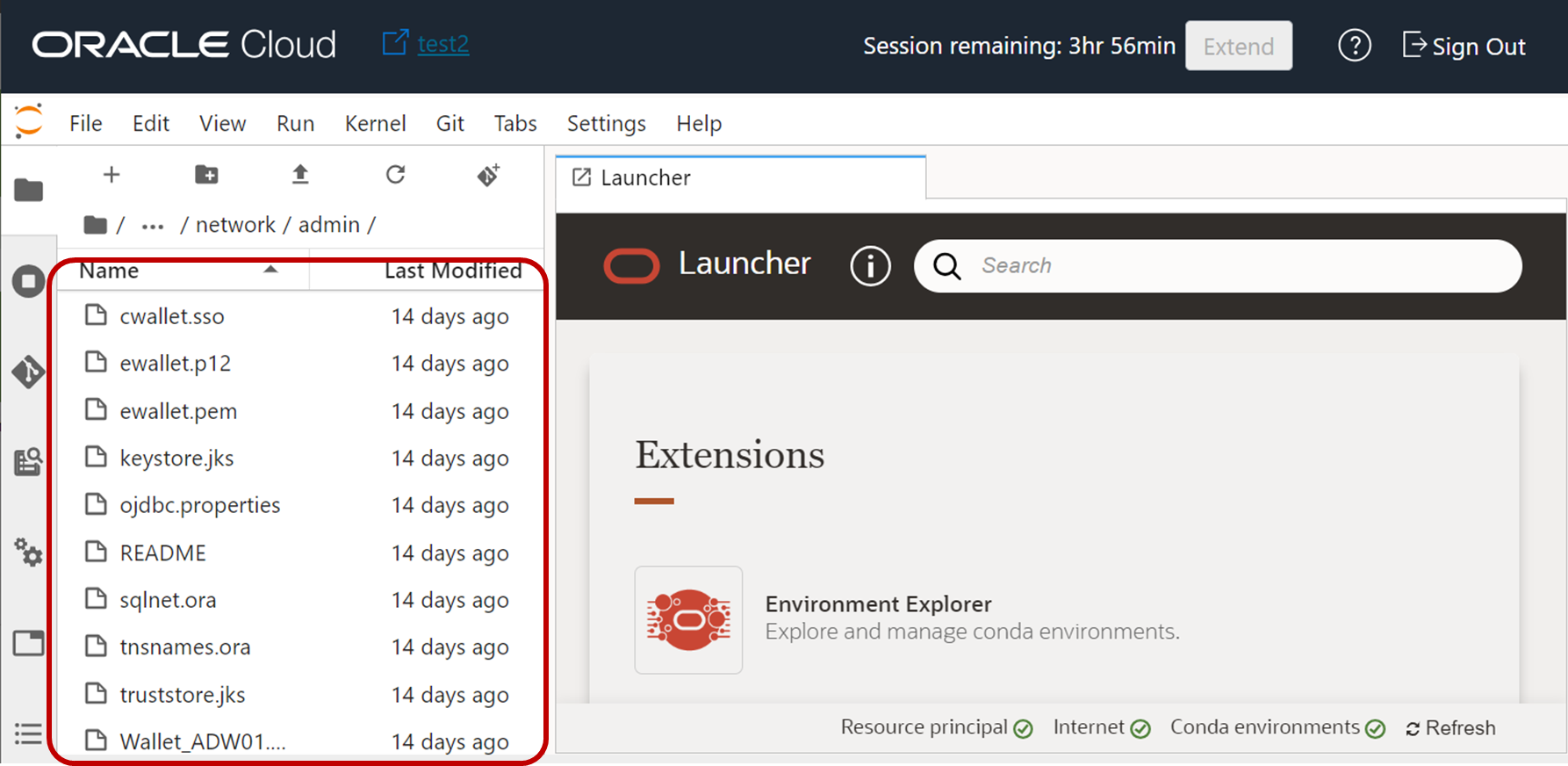
いくつかのファイルがあることがわかりますが、sqlnet.oraファイルをダブルクリックして開き、下図のようにこのファイルを配置したディレクトリ書き換え保存します。
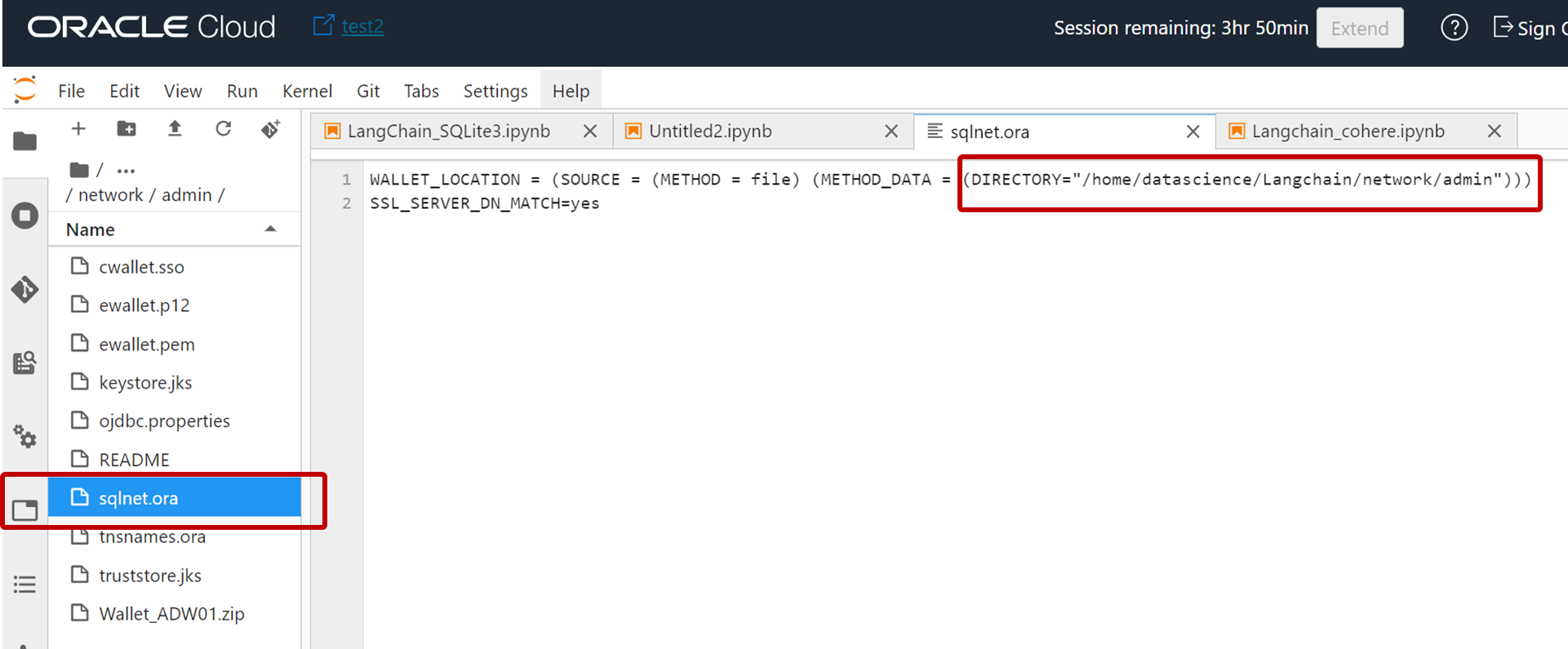
この例ではディレクトリ /home/datascience/Langchain/network/admin にファイルを配置していますが任意のディレクトリで大丈夫です。
以上で設定終了です。
この時点で、以下5つの項目が作成されており、これらを後のコード実行時に使用します。
LangChainからデータベースへの接続時に使用する項目
- データベースの接続名:本記事では「adw01_high」
- データベースユーザー名:デフォルトのadminでもいいですし新たに作成したユーザーでも大丈夫です。
- データベースのパスワード:インスタンス作成時にセットしたパスワード
- TNS関連ファイルのディレクトリ:本記事では「/home/datascience/Langchain/network/admin」
LangChainからLLM(GPT)への接続時に使用する項目
- OpenAIのAPIキー:OpenAIのサイトで生成
4. コード概説
ここから実行コードの概説になります。まずは必要なライブラリをインストールします。openaiはGPTを利用する際のAPIになり、LLMクライアントとして動作します。その他、必須のlangchainをインストールします。
!pip install openai
!pip install langchain
必要なライブラリをimportします。
import os
from langchain import OpenAI, SQLDatabase, SQLDatabaseChain
TNS関連ファイルを配置したディレクトリを環境変数TNS_ADMINSとしてセットします。Pythonから実行する場合は下記のように設定します。そして、データベースインスタンスを作成する際に設定したパスワードと、OpenAIのAPIキーを任意の名前の環境変数としてセットします。(実システムではパスワードなどの平文をコードに埋め込むことはもちろんやめましょう。)
%env TNS_ADMIN=/home/datascience/Langchain/network/admin
%env DB_PASSWD="xxxxxxx"
%env OPENAI_API_KEY=xxxxxxxxxxxxxxxxxxx
次に、実際にDBへの接続オブジェクトを作成します。接続するデータベースのTNS名(コンソールから事前に確認済の名前)、DBユーザー名、環境変数からデータベースユーザーのパスワードを定義し、下記のようにDBへの接続設定を行います。
dsn = "adw01_high"
username = "xxxxx"
password = os.environ.get("DB_PASSWD")
db = SQLDatabase.from_uri(f'oracle://{username}:{password}@{dsn}/?encoding=UTF-8&nencoding=UTF-8')
これでData Science Serviceに実装したLangChainからAutonomous Databaseへの接続ができるようになりました。
次に、LangChainからOpenAIのGPTに接続できるよう下記のようにコードを追加します
api_key = os.environ.get("OPENAI_API_KEY")
llm = OpenAI(openai_api_key=api_key,temperature=0)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
これで、LangChainからAutonomous DatabaseとLLM両方に接続できるようになりました。データベースにはもうデータが入っていますから、もう文章でDBにクエリが実行できる状態です。
5. 文章でRDBにクエリを実行してみる
例えば、下記のようなプロンプトを実行してみます。
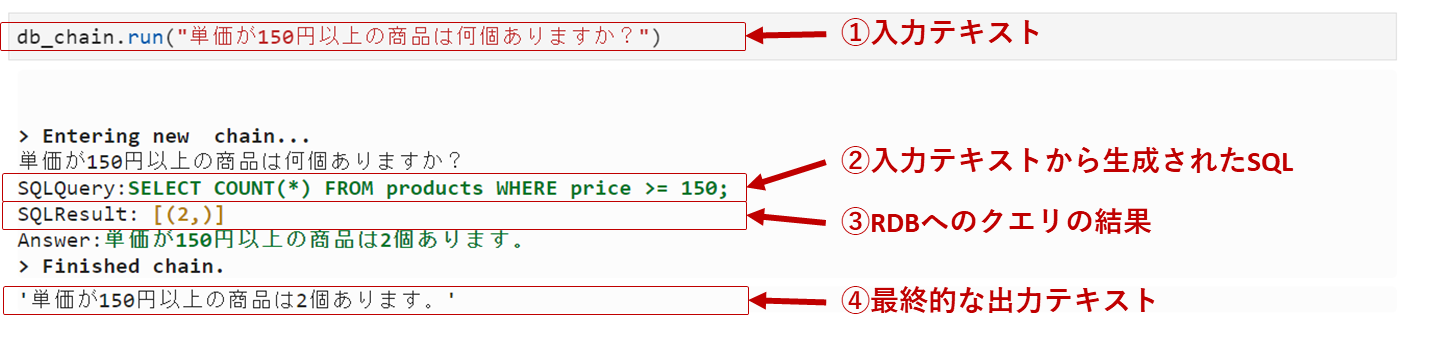
db_chain.run("単価が150円以上の商品は何個ありますか?")
結果は以下の通り。入力文章からSQLが生成され、RDBへクエリし、結果をまた文章で出力している状況がわかります。生成されたSQLも、最終的な出力文章も正確ですね。
もう少し複雑な文章も試してみます。
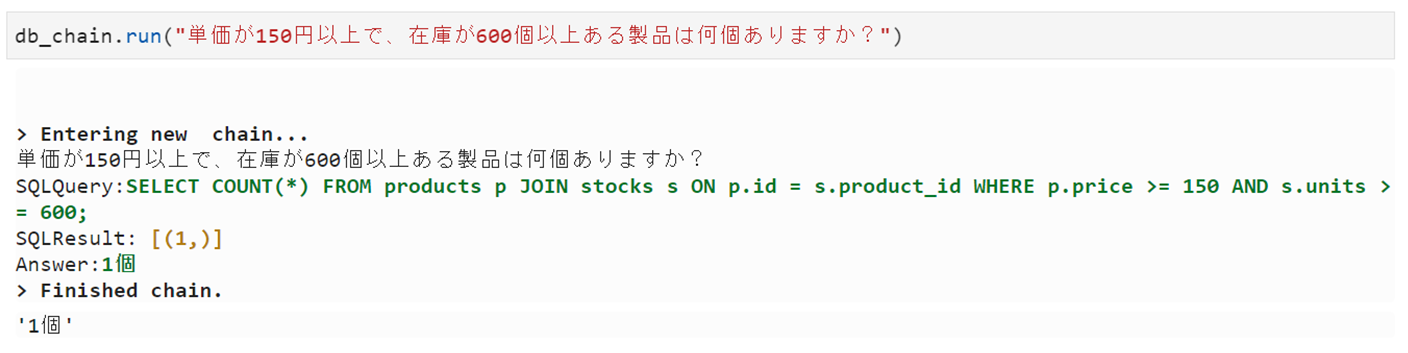
うーん、出力文章がやや寂しいけどちゃんとLLMの処理が実行されていることはわかります。
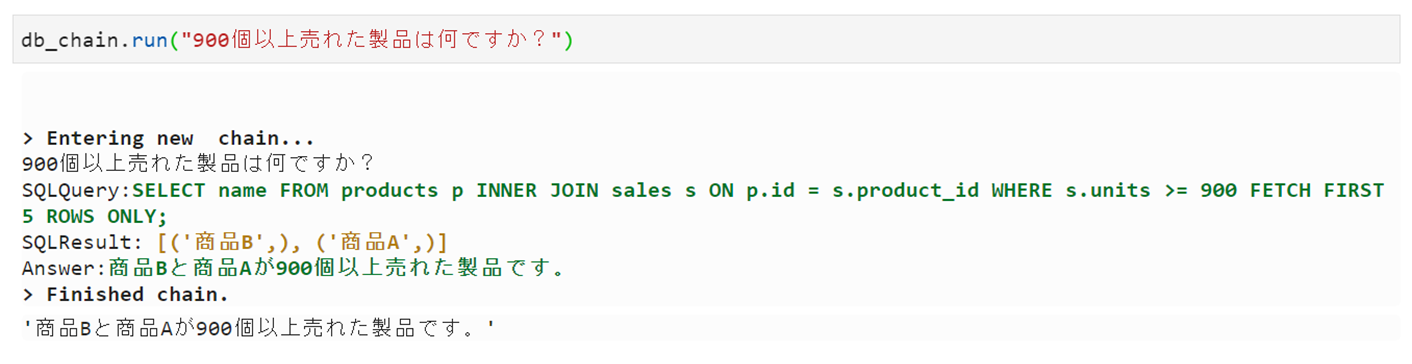
これくらい単純な文章だと難なくこなしてくれますね。ちゃんと表結合もできているし、集計関数やプロシージャなどまで使えるようであれば、シンプルなスタースキーマであればDWHの分析もできそうです。
6. その他のDML、DDLに相当する文章も試してみる
Selectだけだとつまらないのでその他のDML、DDLに相当する文章も試してみます。
Insert

Delete
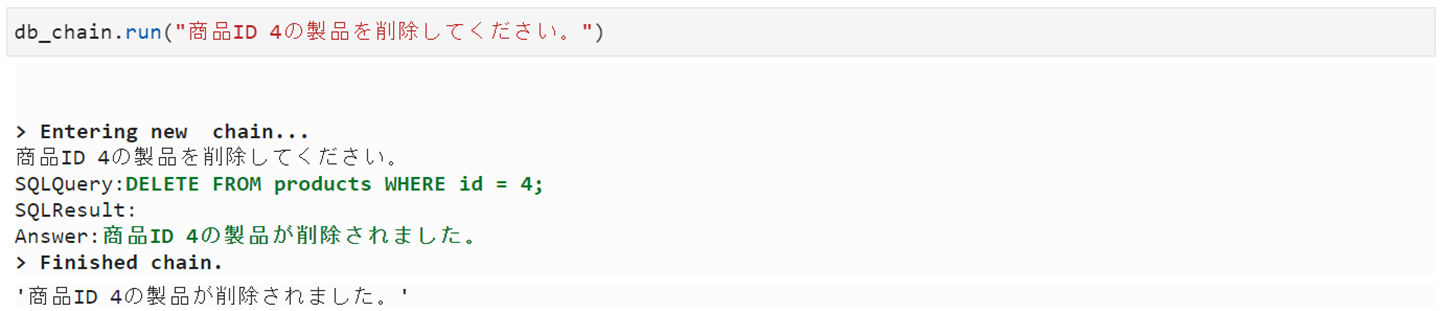
Update
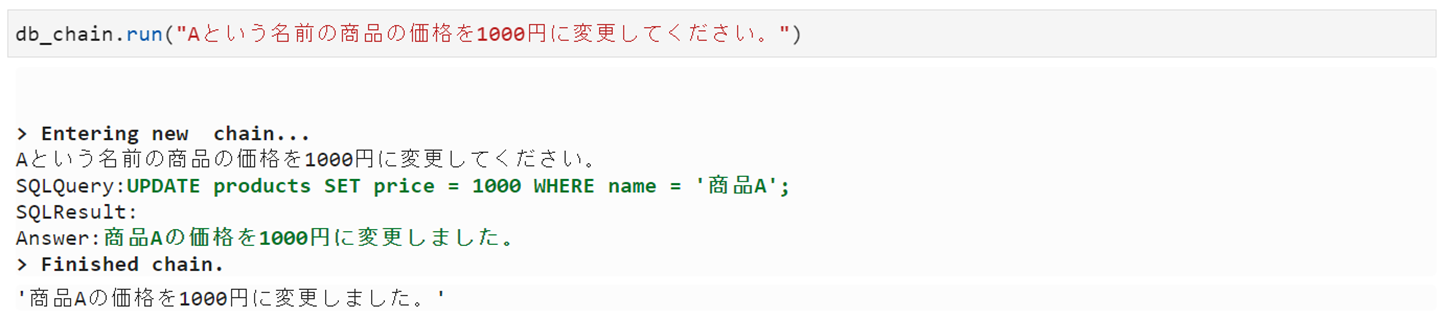
Create
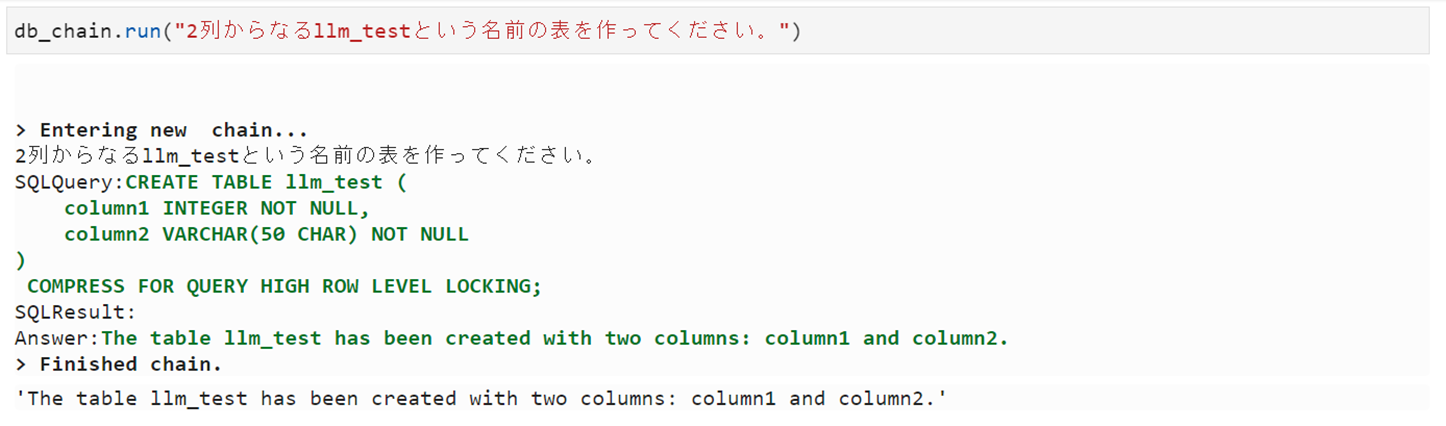
Drop
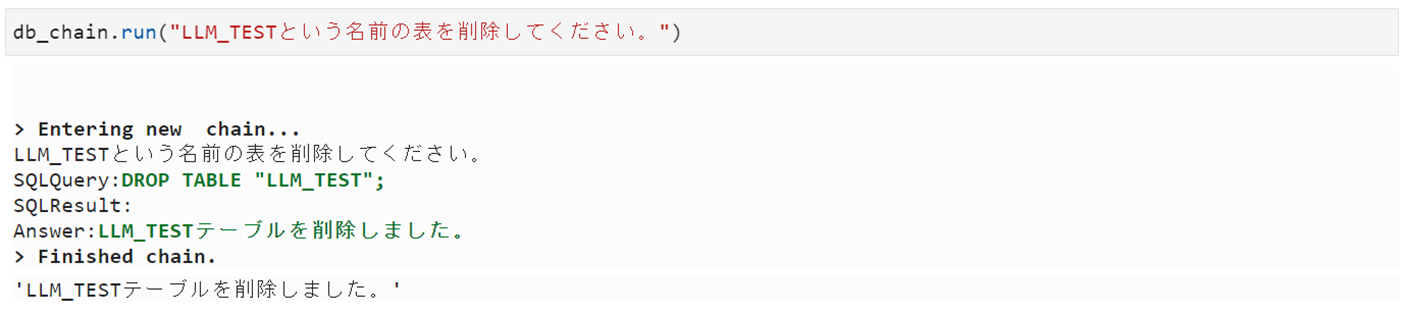
完璧。さようならSQL、今までありがとう。
と言いたいところですが、上記は成功例ばかりを掲載しており、複雑な文章を入力すると、どうしても意図しないSQLが生成されエラーになることが多々あります。結構気をつけてを入力文章を作らないと途端にエラー。上記入力文章が多少たどたどしいのはそれが理由です。
表名、列名などデータベース内の主要なオブジェクトの名前は、どのような文章が入力されるのかを推測して作っておかないとミスマッチが起きたりもしますし、日本語のハンドリングでエラーになることも多々あります。またデータベースをSQLiteやMySQLなど他のものに変えると異なる挙動になったりもします。(SQLiteは比較的安定している感じがします。)
今後、こういうSQL変換のシビアな部分をもっと適当に入力してもうまくこなしてくれるよう改良に期待したいところです。(LangChainには様々なモジュールがあるのでそれらを使って改善はできそうです。)
まだまだ、精度は微妙ですが、言葉でデータベースの操作やデータ分析、更には、機械学習などを実行できる時代はそう遠くないだろうなという印象で非常に将来性を感じます。
7. 番外編 CohereのLLMを使ってみる
冒頭でお伝えした通り、LLMをGPTからCohereに変更して試してみたいと思います。つまり、構成図でいうと下図のようにGPTをCohereに置き換えます。
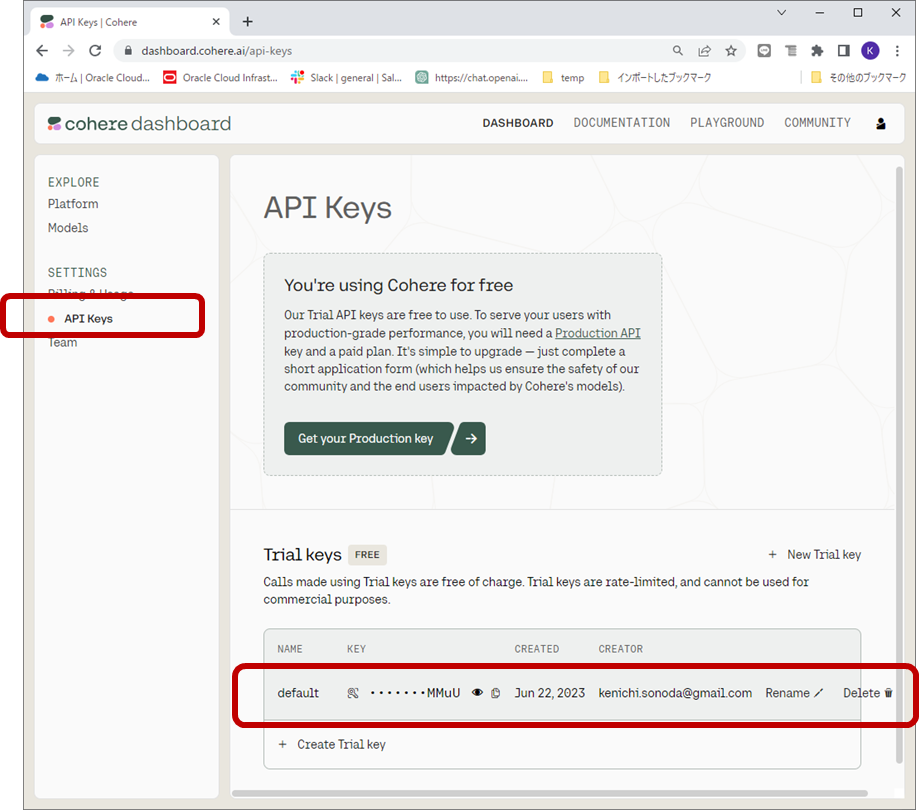
CohereのLLMの使い方は、GPTとあまり変わりません。Cohereのサイトでユーザー登録を行い、下図のようにAPIキーを作成し、管理します。
GPTと同じようにUsageの画面もあります。
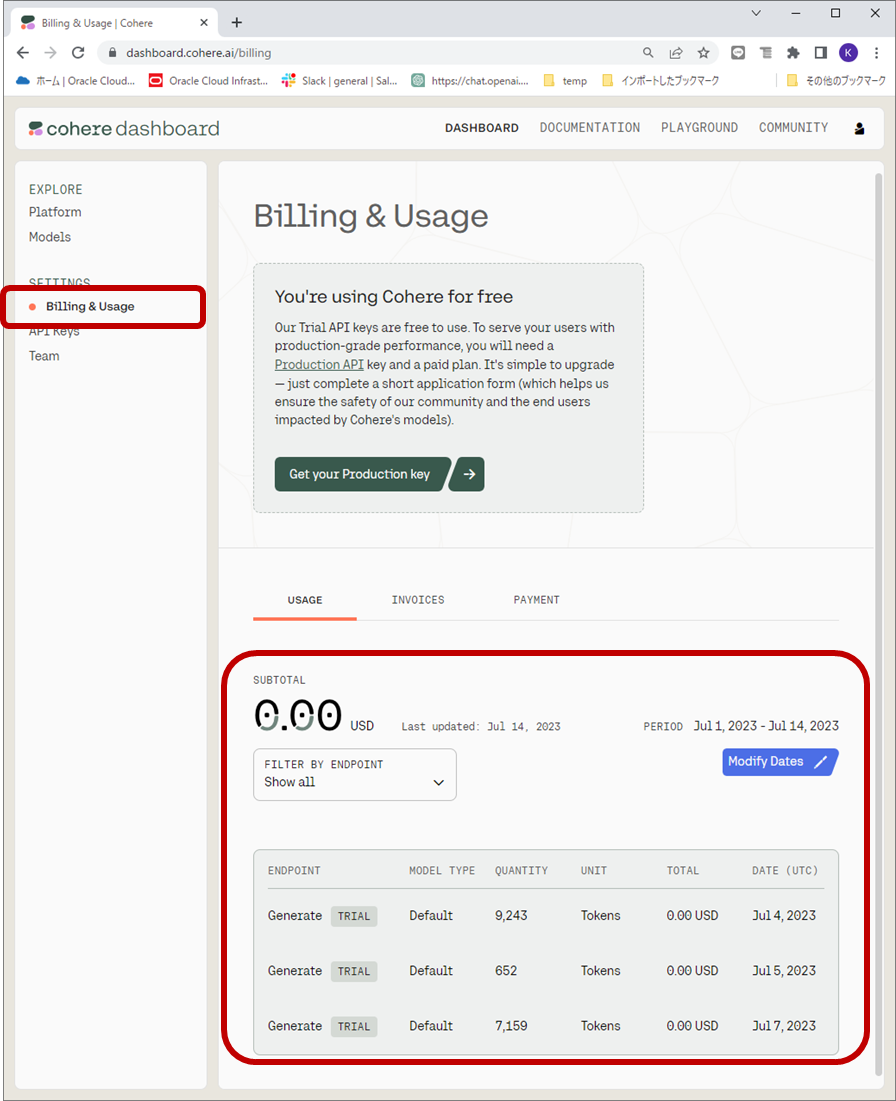
実行コードは、GPTの部分をCohereに挿げ替えているだけで、それ以外は全て同じです。(★の行)
★!pip install cohere
!pip install langchain
import os
★from langchain import Cohere, SQLDatabase, SQLDatabaseChain
%env TNS_ADMIN=/home/datascience/Langchain/network/admin
%env DB_PASSWD="xxxxxxxxxxxxxxxxxx"
★%env COHERE_API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxx
password = os.environ.get("DB_PASSWD")
username = "xxxxxxx"
dsn = "adw01_high"
db = SQLDatabase.from_uri(f'oracle://{username}:{password}@{dsn}/?encoding=UTF-8&nencoding=UTF-8')
★api_key = os.environ.get('COHERE_API_KEY')
★llm = Cohere(cohere_api_key=api_key,temperature=0)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
db_chain.run("単価が150円以上の商品は何個ありますか?")
実行すると下図のような感じです。
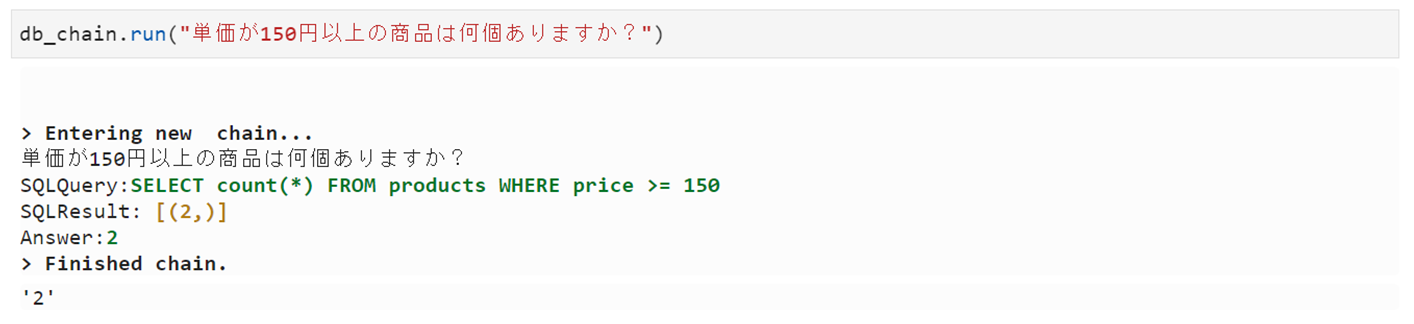
出力文章がちょっとぶっきらぼうな感じが否めない。。。クエリの結果がそのまま出力されていて、最終的な出力文章の生成処理が実行されていないように見えます。これはCohereというよりLangChain側のインテグレーションの問題なような気が。。。
さらに表結合を試してみると。。。エラー。。。
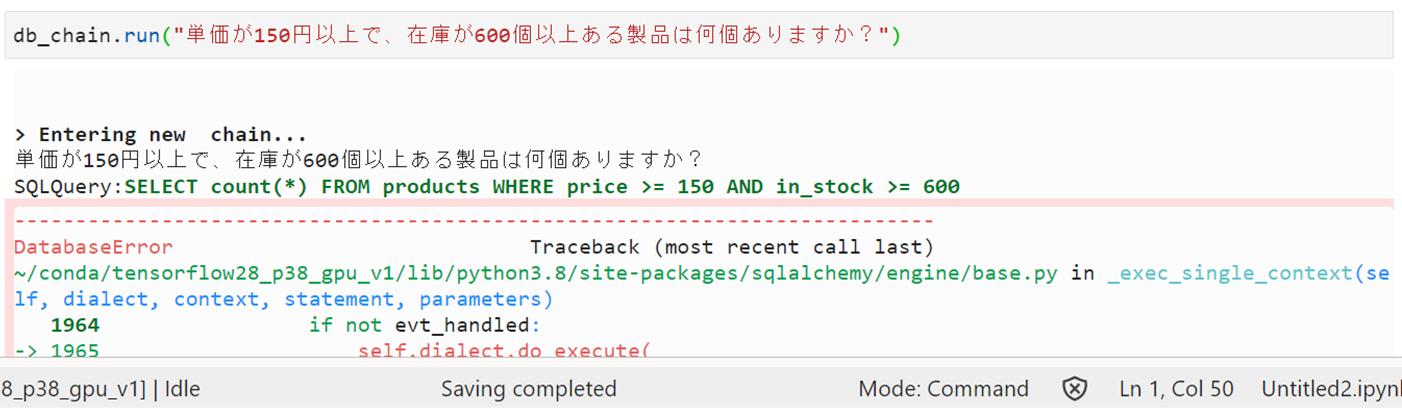
うーん、「在庫」という単語が「stock」ではなく「in_stock」という存在しない列名に変換されているうえ、stocks表を使っておらず、表結合してくれていない。。。
入力文章の「在庫」を「Stock」に変えてみると。。。
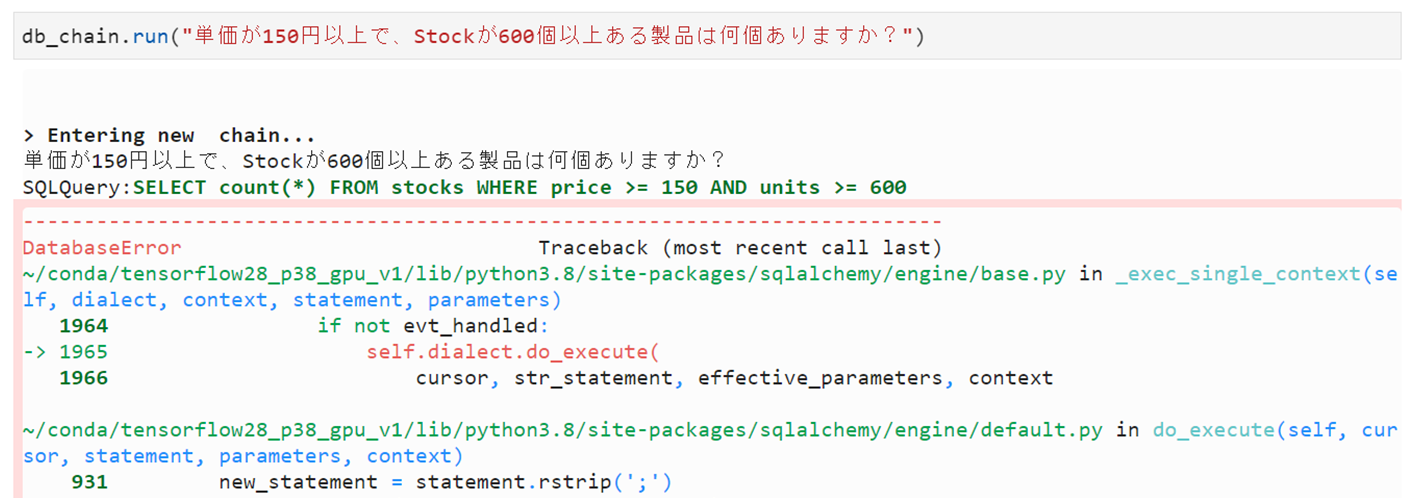
stocks表は使うも、表結合されず。。。
このさい、プロンプトを大幅に書きかえて。。。
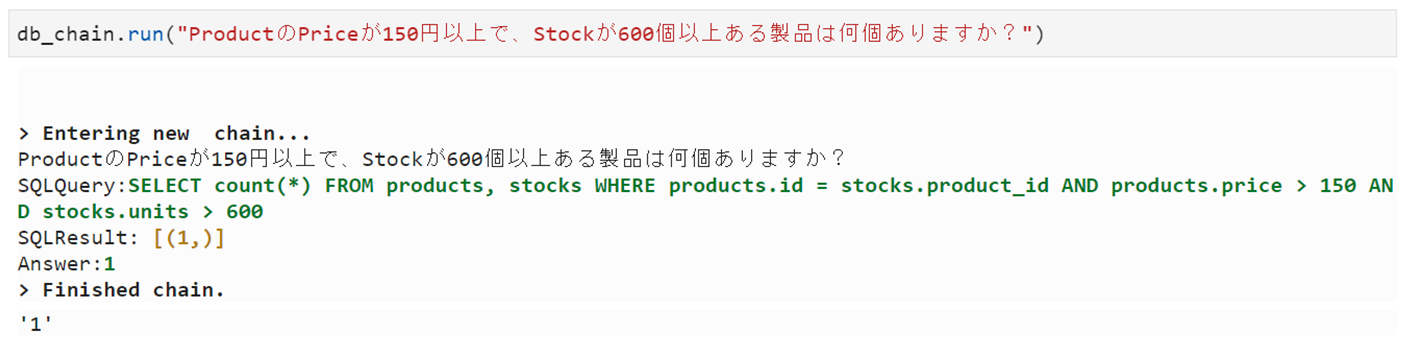
やっと成功。
ぶっきらぼうなところは変わらず。。。
今後は更にエンハンスされていくことでしょう。
8. さいごに
言葉で様々なアプリケーションを操作したりデータを分析したりできるようになるというインターフェースの在り方は、LLMの本質の一つというような気がします。
Python、Javaなど様々なコンピュータ言語、そしてJupyterなどのノートブックの仕組みや便利なライブラリはそれまでの開発環境や開発効率を大きく変革したことは言うまでもありません。が、それでもそれらは一部の人にしか扱えない「職人技」であることは恐らく今後も変わらないでしょう。
そんな一部の職人しか使えないツールだけではなく、「言葉」という誰しもが毎日当たり前のように使っているツールで、専門的な処理を実行できるようなサービスが開発されていくことは多くの人が望む至極自然な流れのように思います。
今回はデータベースの処理にフォーカスして記事を作りましたが、世の中のあらゆるシステムやアプリケーションを操作するためのコマンドやプログラムなどを、高精度で言葉に置き換えることができれば、AIに話しかけながら仕事を進めるような、昔見た映画のワンシーンは近い将来、オフィスでの日常の光景になるかもしれませんね。